
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Congratulations, my friends, we have finally come to the end of the series! Although… well, not quite (see below), but we have definitely reached the end of what I had planned originally. Last time, we discussed diffusion-based models, mentioning, if not fully going through, all their mathematical glory. This time, we are going to put diffusion-based models together with multimodal latent spaces and variational autoencoders with discrete latent codes, getting to Stable Diffusion and DALL-E 2, and then will discuss Midjourney and associated controversies. Not much new math today: we have all the Lego blocks, and it only remains to fit them all together.

We already know how diffusion-based models work: starting from random noise, they gradually refine the image. The state of the art in 2021 in this direction was DDIMs, models that learn to do sampling faster, in larger steps, but have generally the same final quality.
Then Stable Diffusion happened. Developed by LMU Munich researchers Robin Rombach et al., it was released in August 2022 and published in CVPR 2022 (see also arXiv). Their idea was simple:
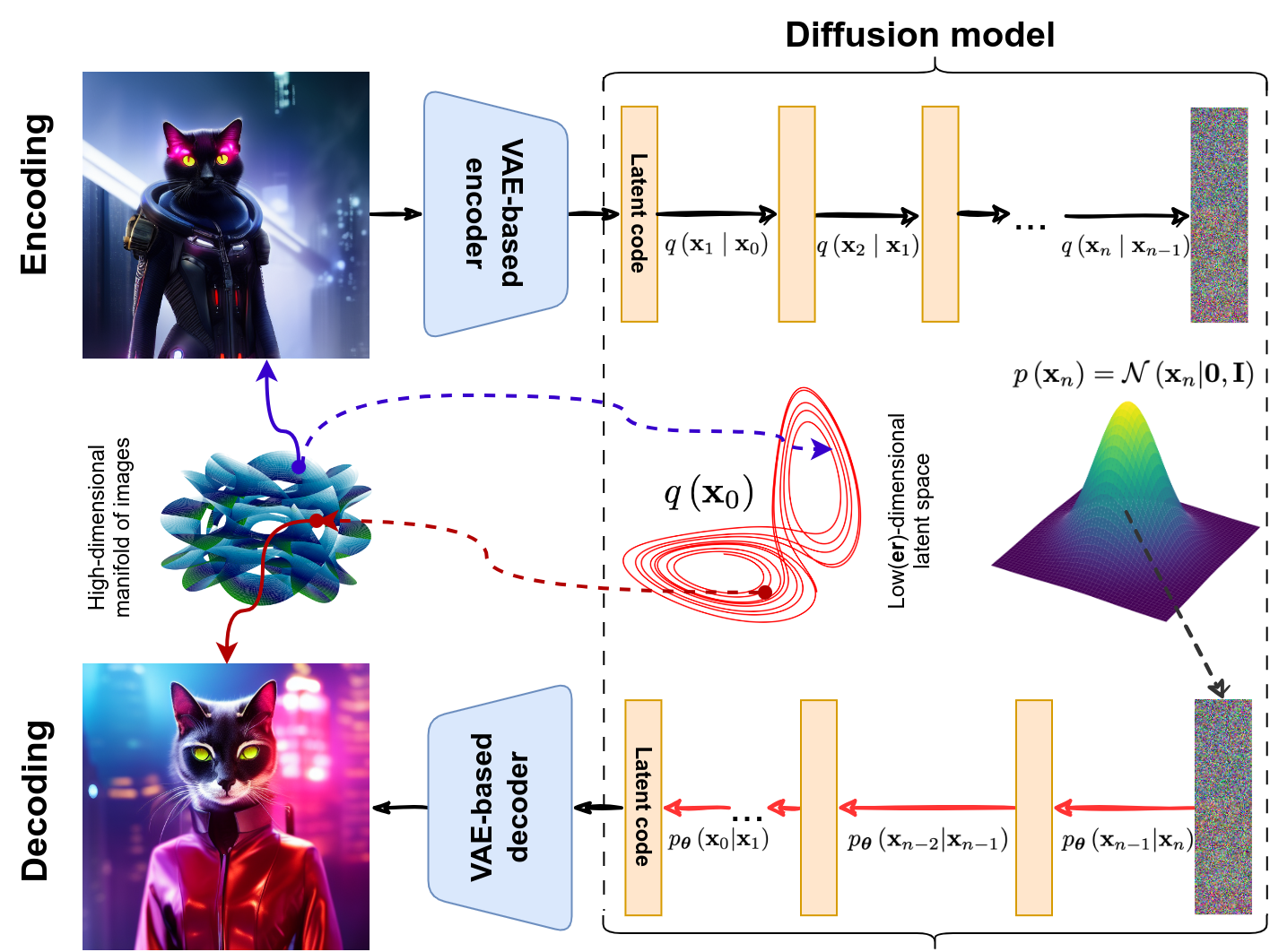
This is basically it: you can train an excellent diffusion model in the low-dimensional latent space, and we have seen that VAE-based models are very good at compressing and decompressing images to/from this latent space. The autoencoder here is the VQ-GAN model that we have discussed earlier.
Another novelty of the Stable Diffusion model was a conditioning mechanism. The authors used a U-Net as the backbone for the diffusion part, but they augmented it with Transformer-like cross-attention to allow for arbitrary conditions to be imposed in the latent space. As a result, the condition is introduced on every layer of the diffusion decoder and on every step of the denoising. Naturally, the main application of this is to use a text prompt encoded by a Transformer as the condition:
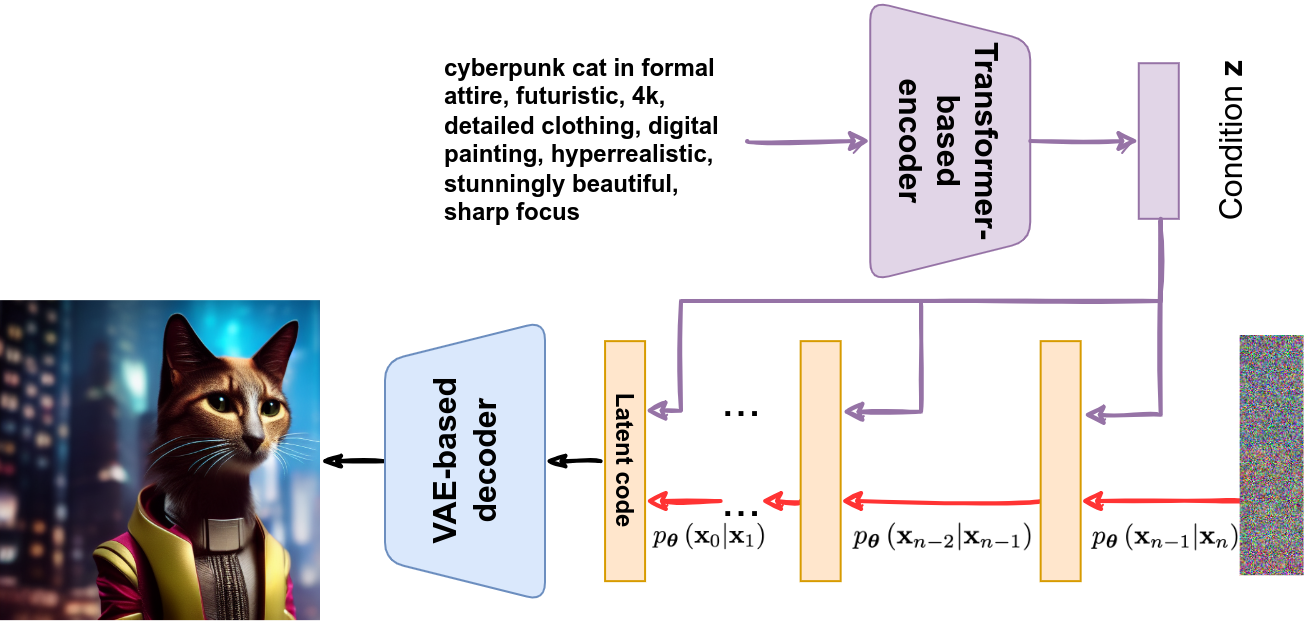
Stable Diffusion had been released by LMU Munich researchers but soon found itself as the poster child of the Stability AI startup, which recently led to a conflict of interests. The controversy with Stability AI is currently unfolding, and until it is fully resolved I will refrain from commenting; here is a link but let’s not go there now.
Whatever the history of its creation, Stable Diffusion has become one of the most important models for image generation because it is both good and free to use: it has been released in open source, incorporated into HuggingFace repositories, and several free GUIs have been developed to make it easier to use.
I will not give specific examples of Stable Diffusion outputs because this entire series of posts has been one such example: all cat images I have used to illustrate these posts have been created with Stable Diffusion. In particular, the prompt shown above is entirely real (augmented with a negative prompt, but making prompts for Stable Diffusion is a separate art in itself).
Stable Diffusion uses a diffusion model in the latent space of a VQ-GAN image-to-latent autoencoder, with text serving as a condition for the diffusion denoising model. But we already know that there are options for a joint latent space of text and images, such as CLIP (see Part IV of this series). So maybe we can decode latents obtained directly from text?
DALL-E 2, also known as unCLIP, does exactly that (Ramesh et al., 2022). On the surface, it is an even simpler idea than Stable Diffusion: let’s just use the CLIP latent space! But in reality, they still do need a diffusion model inside: it turns out that text and image embeddings are not quite the same (this makes sense even in a multimodal latent space!), and you need a separate generative model to turn a text embedding into possible matching image embeddings.
So the diffusion-based model still operates on the latent codes, but now the text is not a condition, it’s also embedded in the same joint latent space. Otherwise it’s the exact same multimodal CLIP embeddings that we discussed in an earlier post. The generation process now involves a diffusion model, which the authors of DALL-E 2 call a diffusion prior, to convert the text embedding into an image embedding:
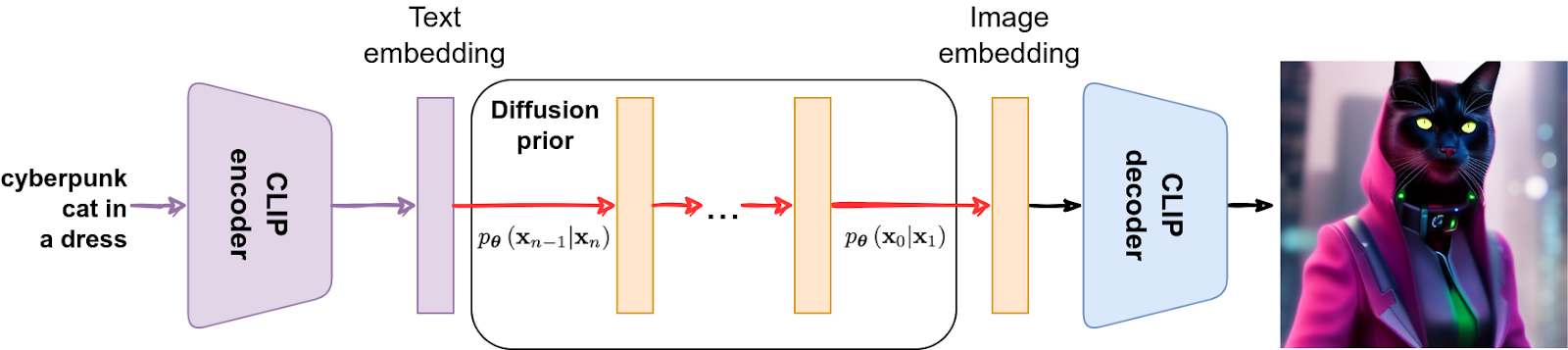
(This time, the prompt is a fake, it’s a Stable Diffusion image again.)
DALL-E 2 reports excellent generation results; here are some samples from the paper:

The combination of CLIP embeddings and a diffusion model in the latent space allows DALL-E 2 to do interesting stuff in the latent space. This includes highly semantic interpolations such as this one:

What’s even more interesting, DALL-E 2 can do text-guided image manipulation, changing the image embedding according to the difference between vectors of the original and modified text captions:

DALL-E 2 is not open sourced like Stable Diffusion, and you can only try it via the OpenAI interface. However, at least we have a paper that describes what DALL-E 2 does and how it has been trained (although the paper does appear to gloss over some important details). In the next section, we will not have even that.
So what about the elephant in the room? Over the last year, the default models for text-image generation have been neither Stable Diffusion nor DALL-E 2; the lion’s share of the market has been occupied by Midjourney. Unfortunately, there is little I can add to the story above: Midjourney is definitely a diffusion-based model but the team has not published any papers or code, so technical details remain a secret.
The best I could find was this Reddit comment. It claims that the original releases of Midjourney used a diffusion model augmented with progressive distillation (Salimans, Ho, 2022), a process that gradually combines short sampling steps into new, larger sampling steps by learning new samplers:
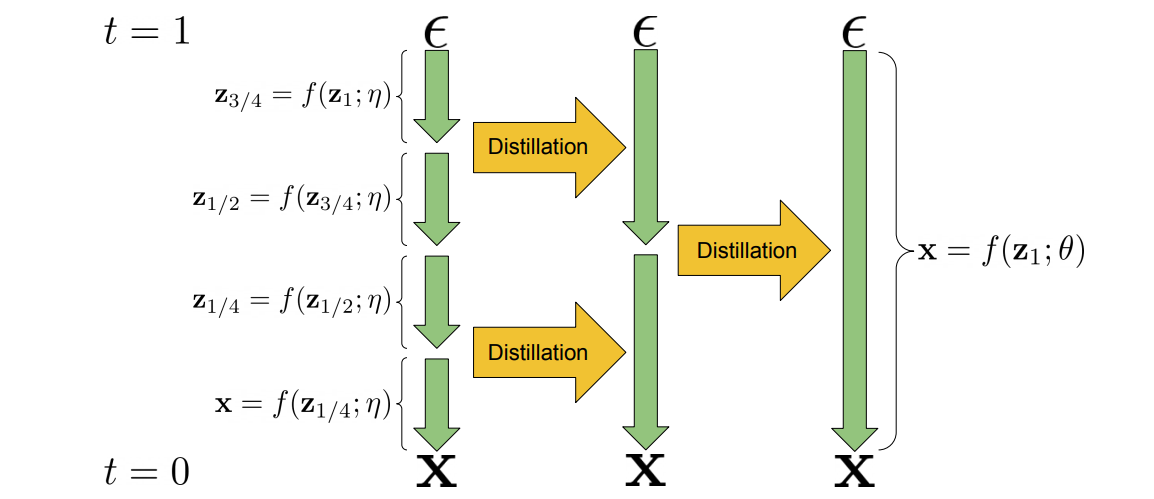
This approach can significantly speed up the sampling process in diffusion models, which we noted as an important problem in the previous post. However, this is just a Reddit comment, and its author admits that available information only relates to the original beta releases, so by now Midjourney models may be entirely different. Thus, in this section let us review the public milestones of Midjourney and the controversies that keep arising over AI-generated art.
One of Midjourney’s first claims to fame was an image called “Théâtre d’Opéra Spatial” (“Space Opera Theatre”) produced by Jason Allen:

This image won first place in a digital art competition (2022 Colorado State Fair, to be precise). Allen signed this work as “Jason M. Allen via Midjourney” and insisted that he did not break any rules of the competition, but the judges were unaware that the image had been AI-generated, so some controversy still ensued.
Later in 2022, Midjourney was used to illustrate a children’s book called “Alice and Sparkle“, very appropriately devoted to a girl who creates a self-aware artificial intelligence but somehow manages to solve the AI alignment problem so in the book, Alice and Sparkle live happily ever after:

The text of the book was written with heavy help from ChatGPT, and the entire book went from idea to Amazon in 72 hours. It sparked one of the first serious controversies over the legal status of AI-generated art. “Alice and Sparkle” received many 5-star reviews and no fewer 1-star reviews, was temporarily suspended on Amazon (but then returned, here it is), and while there is no legal reason to take down “Alice and Sparkle” right now, the controversy still has not been resolved.
Legal reasons may appear, however. After “Alice and Sparkle”, human artists realized that the models trained on their collective output can seriously put them out of their jobs. They claimed that AI-generated art should be considered derivative, and authors of the art comprising the training set should be compensated. On January 13, 2023, three artists filed a lawsuit against Stability AI, Midjourney, and DeviantArt, claiming that training the models on original work without consent of its authors constitutes copyright infringement. The lawsuit is proceeding as lawsuits generally do, that is, very slowly. In April, Stability AI motioned to dismiss the case since the plaintiffs failed to identify “a single act of direct infringement, let alone any output that is substantially similar to the plaintiffs’ artwork”. On July 23, Judge William Orrick ruled that the plaintiffs did not present sufficient evidence but allowed them to present additional facts to amend their complaint. We will see how the case unfolds, but I have no doubt that this is just the first of many similar cases, and the legal and copyright system will have to adapt to the new reality of generative AI.
In general, over 2023 Midjourney has remained the leader in the AI-generated art space, with several new versions released to wide acclaim. This acclaim, however, has also been controversial: users are often divided over whether new versions of image generation models are actually improvements.
Lately, generated images tend to make the news not as art objects but as fake photographs. AI-generated art has become good enough to pass for real photos, and people have been using it to various effects. In March, Midjourney generated a viral image of Donald Trump being forcefully arrested. On May 22, a Twitter account made to look like a verified Bloomberg feed published a fake image of an explosion near the Pentagon in Washington D.C. The result exceeded expectations: trading bots and/or real traders took the fake news at face value, resulting in a $500B market cap swing:
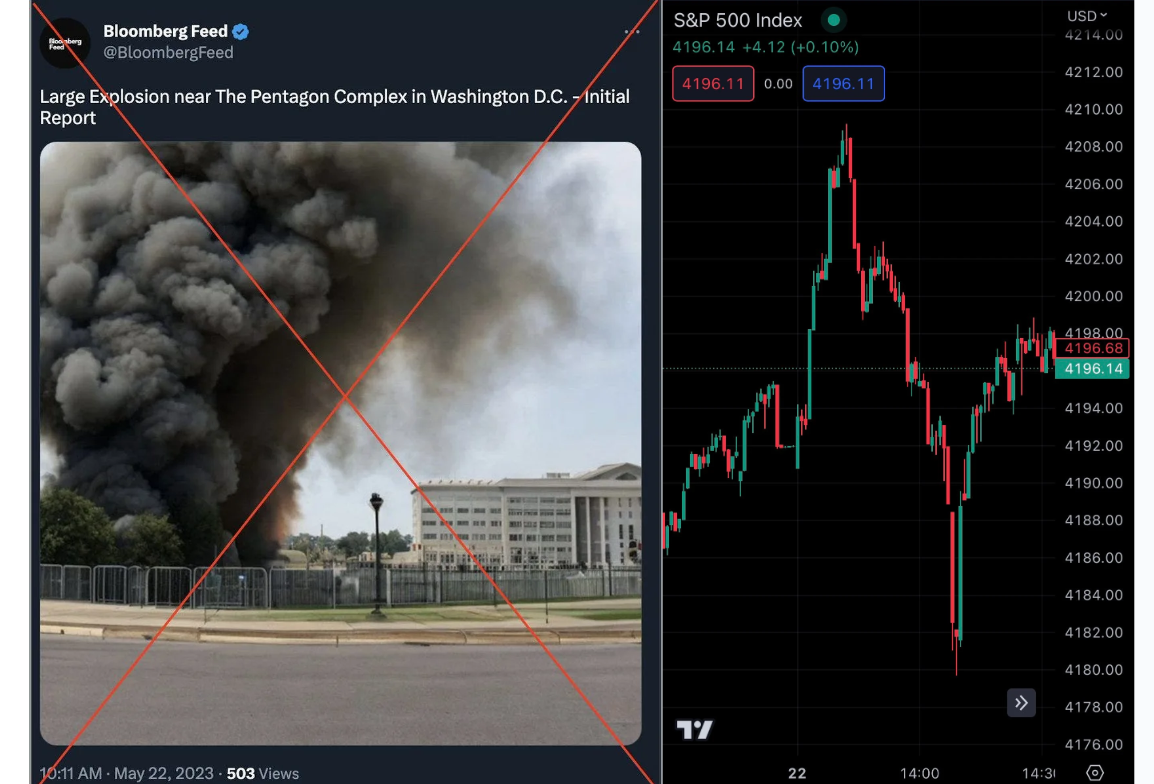
While this kind of news keeps attracting attention to generative AI, to be honest I do not really see a big new issue behind these “deepfakes.” Realistic fake photos have been possible to produce for decades, with the tools steadily improving even regardless of machine learning progress. A Photoshop expert could probably make the Pentagon explosion “photo” in a couple of hours; I am not even sure that fiddling with the prompts to get an interesting and realistic result takes significantly less time (but yes, it does not require an experienced artist). While generative models can scale this activity up, it is by no means a new problem.
Professional artists, on the other hand, face a genuine challenge. I have been illustrating this series of posts with (a rather old version of) Stable Diffusion. In this case, it would not make sense to hire a professional illustrator to make pictures for this blog anyway, so having access to a generative model has been a strict improvement for this series. As long as you are not too scrupulous about the little details, the cats just draw themselves:

But what if I had to illustrate a whole book? Right now, the choice is between spending money to get better quality human-made illustrations and using generative AI to get (somewhat) worse illustrations for free or for a small fee for a Midjourney subscription. For me (the author), the work involved is virtually the same since I would have to explain what I need to a human illustrator as well, and would probably have to make a few iterations. For the publisher, hiring a human freelancer is a lot of extra work and expense. Even at present, I already see both myself and publishing houses choosing the cheaper and easier option. Guess what happens when this option ceases to be worse in any noticeable way…
With this, we are done with the original plan for the “Generative AI” series. Over these seven posts, we have seen a general overview of modern approaches to image generation, starting from the original construction of variational autoencoders and proceeding all the way to the latest and greatest diffusion-based models.
However, a lot has happened in the generative AI space even as I have been writing this series! In my lectures, I call 2023 “the spring of artificial intelligence”: starting from the growing popularity of ChatGPT and the release of LLaMA that put large language models in the hands of the public, important advances have been made virtually every week. So next time, I will attempt to review what has been happening this year in AI; it will not be technical at all but the developments seem to be too important to miss. See you then!
Sergey Nikolenko
Head of AI, Synthesis AI
