
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Last time, we discussed DALL-E, a model that brings together text Transformers and a discrete VAE for images. While DALL-E was a huge step forward and generated a lot of buzz for generative AI back in 2021, modern generative models such as DALL-E 2 consist of different components. One of them is usually a multimodal encoder that maps different modalities (e.g., text and images) into the same latent space. Today, we discuss such encoders and then make an example of a specific practical problem where they have become instrumental over the last couple years: text-video retrieval, that is, searching for video content by text queries.

A model that has proven to be one of the most important for multimodal retrieval is CLIP, introduced by OpenAI in 2021. The basic motivation behind CLIP was to use the data freely available on the Web: text paired with images, i.e., captions of the form like “a black and white cat” or “Pepper the aussie pup” used in OpenAI’s illustrations (see below).
The question, of course, is how to use this huge data. The authors of CLIP reported that their first instinct was to train an image CNN and a text Transformer to predict a caption of an image. Transformers are famously good at generating text, but it turned out that the resulting recognition quality for ImageNet classes was no higher than from a bag-of-words baseline. The reason was that predicting the exact caption is very hard (basically hopeless), and it’s not really what we need in this model—we just need good multimodal embeddings.
Therefore, CLIP switched to the titular idea of contrastive pretraining: we want both text descriptions and the images themselves to map to the same latent space, so let’s use a loss function that brings positive pairs (correct descriptions) closer together and negative pairs (incorrect descriptions) further apart.
In the picture below, I show the “attractive and repulsive forces” (green and red arrows respectively) that should appear between two image-description pairs, with each pair used as negative samples for the other:
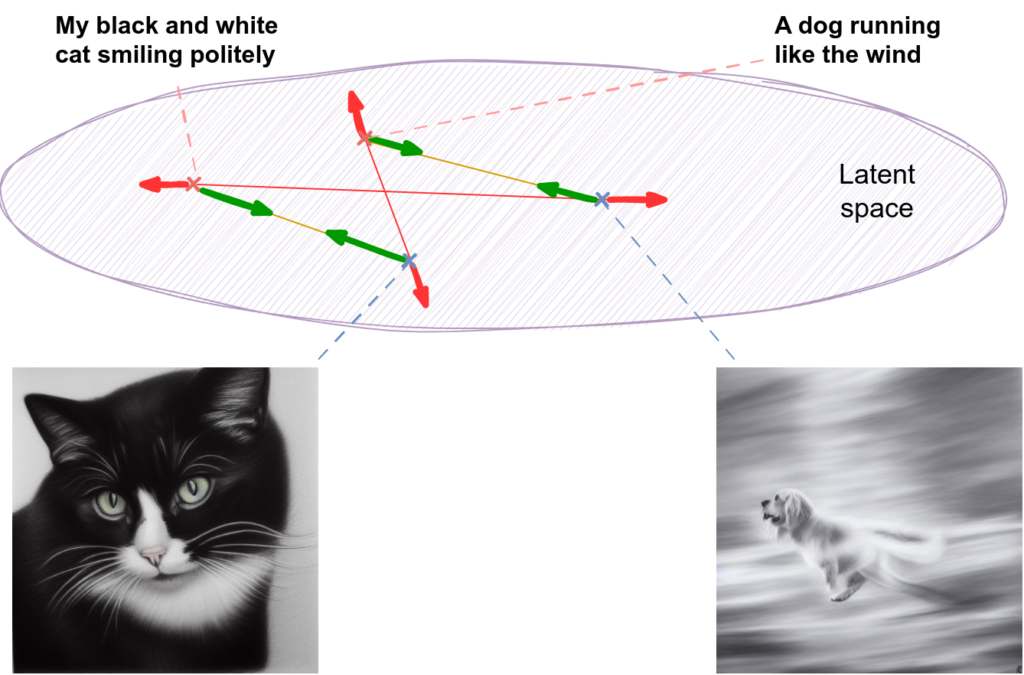
CLIP takes this idea and runs with it, constructing a whole matrix of similarities (dot products in the latent space) between the embeddings of N images and N corresponding textual descriptions. As a result, we get an NxN matrix where the diagonal corresponds to positive pairs (so diagonal elements should be made larger) and all other elements correspond to negative pairs (so off-diagonal elements should be made smaller).
Here is the main illustration for this idea from the CLIP paper:
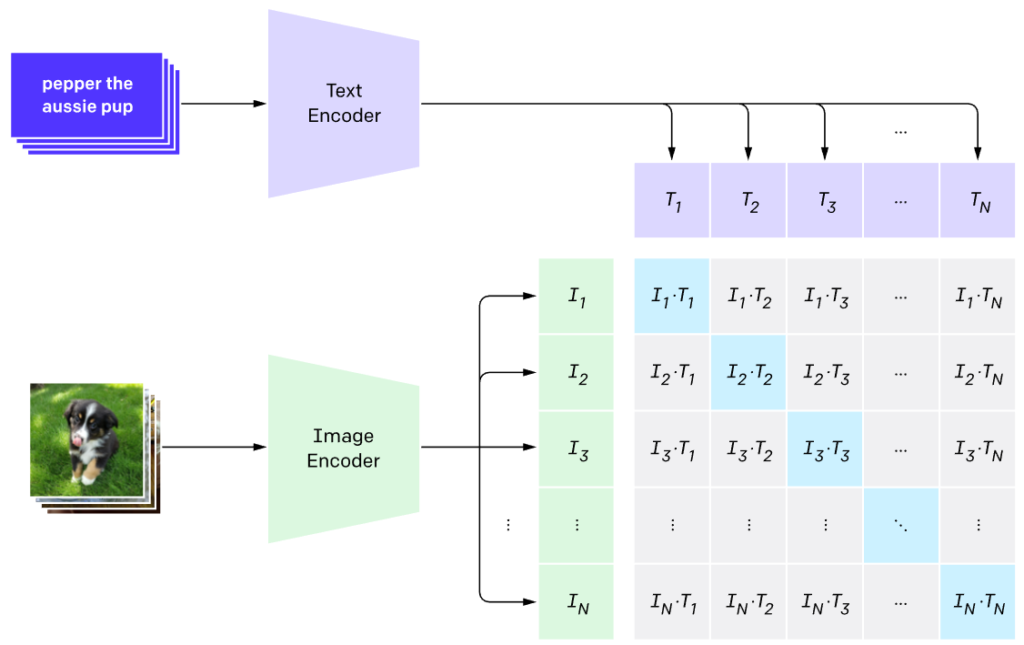
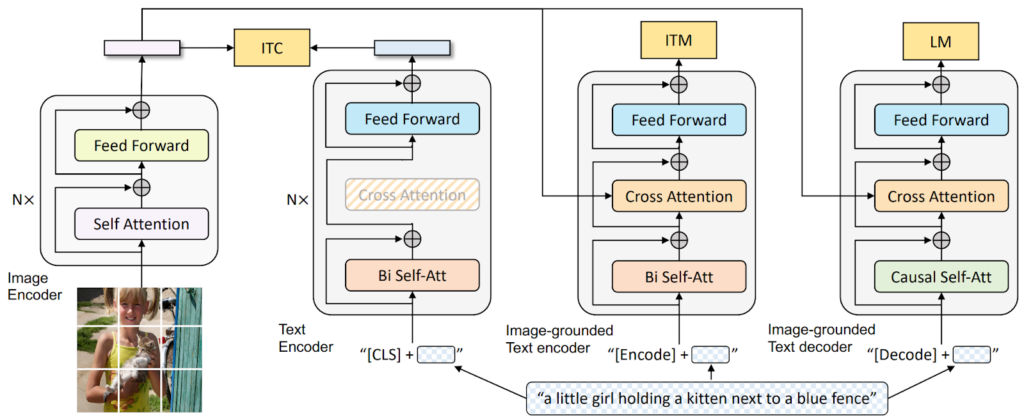
The encoders, of course, are Transformer-based architectures, specifically the Vision Transformer (ViT) that breaks an input image into patches and treats embeddings of patches as tokens for the Transformer architecture. The margins of this blog post are too narrow to explain Vision Transformers; maybe one day we will have a series about Transformers, what with them being the most important architecture of the last years and all. For now, let’s just assume that ViTs are good at converting images into embeddings, and ViT itself has been a key component of many multimodal architectures; see the original paper by Dosovitskiy et al. for details.
The original work shows that CLIP is very capable of zero-shot classification: you can turn a class label into a rudimentary query (e.g., “cat” becomes “a photo of a cat”) and get a reasonable classifier by finding nearest neighbors in the joint latent space (image by OpenAI):
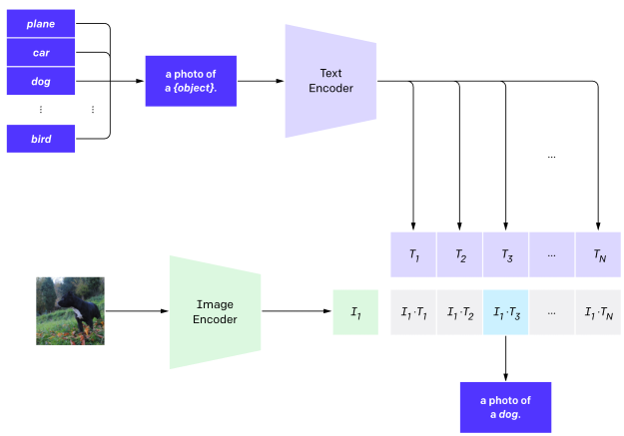
But the main use of CLIP has been for enabling text-image retrieval and generative AI models. Its multimodal latent space proves to be an excellent tool both for finding existing objects and generating new ones (provided you train a decoder for it, of course—the original CLIP has none). In the rest of this post, I will expand on the retrieval part, and we will leave the generative part for next installments. But first, let’s consider an interesting extension of CLIP that, a little unexpectedly, uses our local specialty: synthetic data.
There has been no lack of models that further extended and improved CLIP, although the basic CLIP itself is still very relevant. As a representative model that takes a few steps forward from CLIP let us consider BLIP (the similar acronym is no accident, of course), developed in 2022 by Li et al.
One of the central novelties in BLIP is… synthetic data. Yes, you heard right, large datasets of photos and their captions that one can download off the Web seem to be not enough, not because they are not large enough (the Web is huge) but rather because they are too noisy. In many cases, even a properly downloaded caption is not informative about the image.
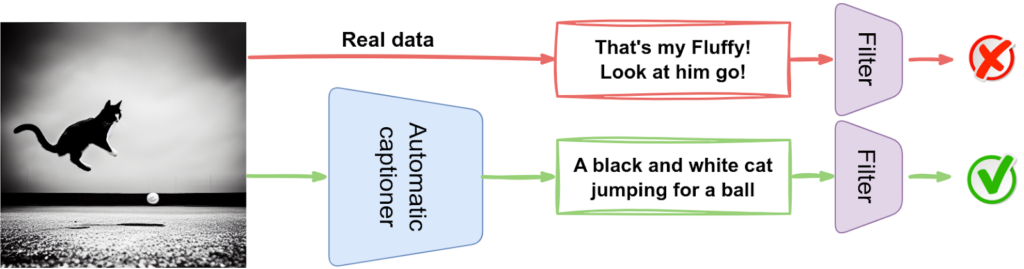
Therefore, BLIP authors used an automatic captioning model to generate synthetic captions. But you don’t want to just throw away all of your human annotations! Moreover, sometimes synthetic data wins clearly but sometimes the human annotation is much more specific; in the illustration below, Tw is the original human annotation and Ts is the synthetic one:

Thus, BLIP trains a separate filtering model to distinguish between good and bad captions. Here is how it might work:
Overall, the filtering process leads to a dataset with several parts, some of them human-annotated and some synthetic, with filtering used to choose the best version in every case:
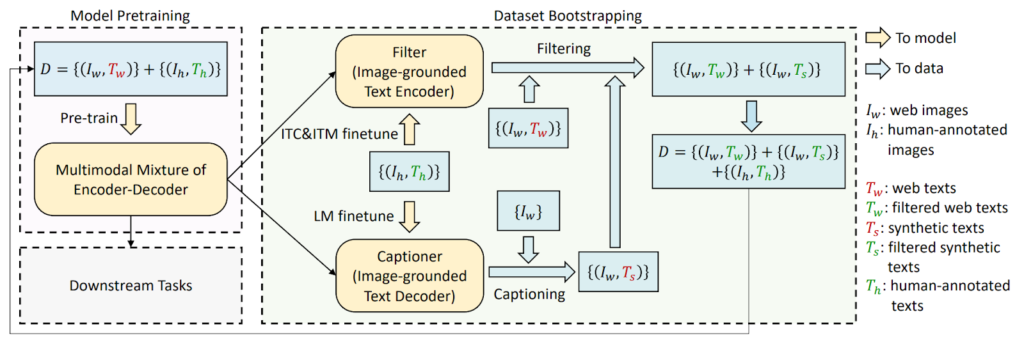
Apart from the data, BLIP also extends the model itself. CLIP had a text encoder and an image encoder, and used contrastive pretraining only. BLIP expands on it with multitask pretraining via three different encoders:
Here is an illustration from the BLIP paper:
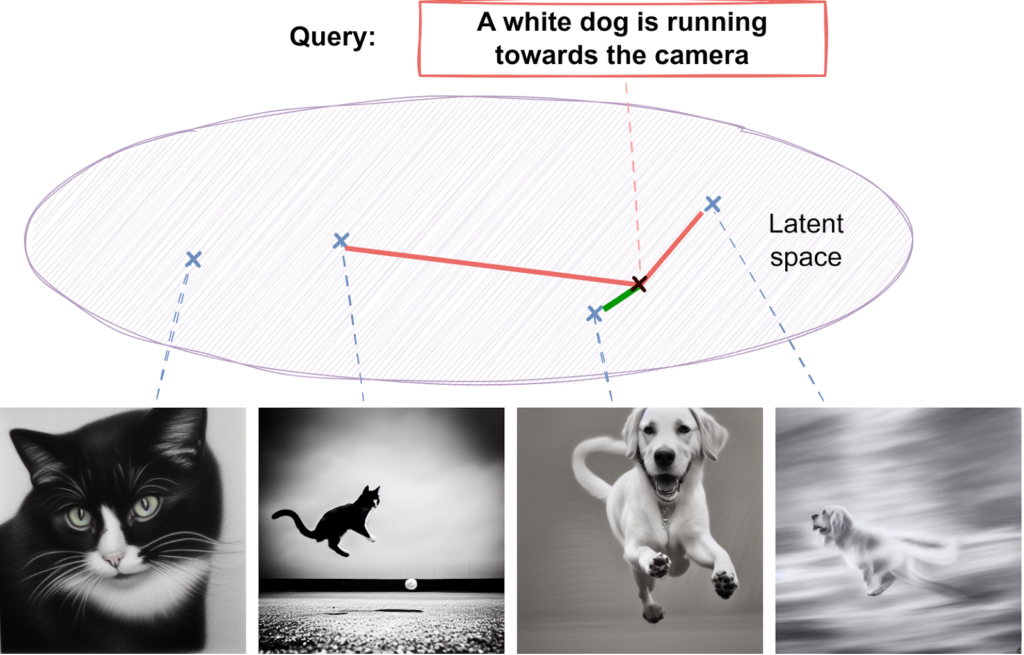
So how do we use all of these models for retrieval? The basic idea is very simple: once you have good multimodal embeddings, you can map the query to the same space and find nearest neighbors. Something like this:
But this is only the very first inkling of an idea, and it needs a lot of fleshing out to get real. In this post, I cannot hope to review the entire field of multimodal retrieval so to make a relevant and practical example let us work through some of the models for text-video retrieval, i.e., searching for videos by text prompts.
As a first example, now probably only of historical interest, let’s consider the S2VT model, originally developed for video captioning (producing text descriptions for video) but also possible to use for retrieval: this is a common trend for many models that simply map everything into a common latent space. Here is what S2VT looks like:
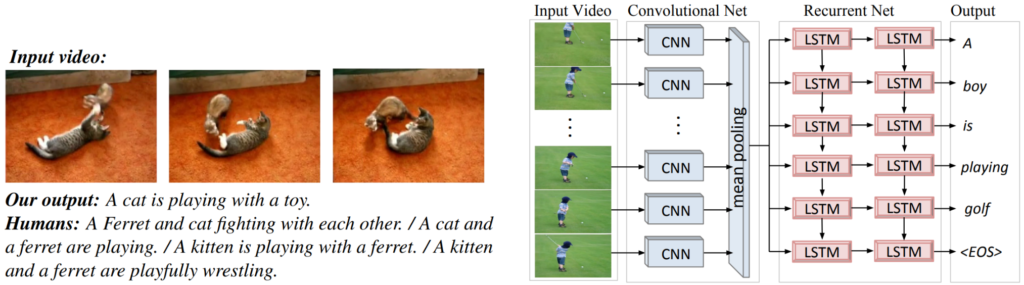
This is the archetypal “early deep learning” approach, similar to, e.g., “Show and Tell”: you have a recurrent network for text and a convolutional network for video frames, they extract features and map everything into a common latent space.
Another important trend that started quite early is considering hierarchical representations for both text and video. Both modalities are hierarchical in nature: a (detailed) text caption can be broken down into paragraphs, and the latter into sentences, while a video naturally consists of scenes and/or frames, and one can find objects on these frames.
An early example of this approach was shown by Zhang et al. (2018). Their hierarchical sequence embedding (HSE) model includes separate intermediate loss functions that align sentence-level embeddings for text and clip-level embeddings for videos:
But the whole field changed when Transformers were introduced, or, to be more precise, when Transformers were applied to images in Vision Transformers. Let’s see how!
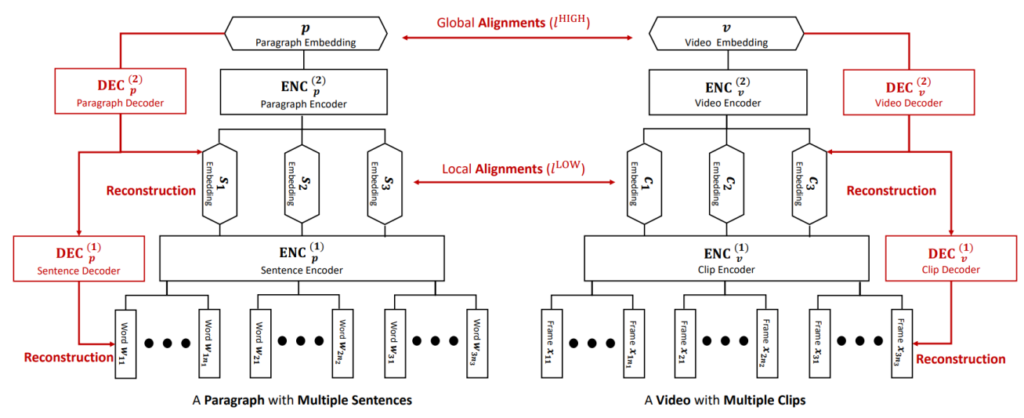
How can Transformers help retrieval? First, there is the direct approach: we have CLIP that maps text and images into the same space; let’s just extend CLIP to videos by representing them as a sequence of frames. This simple idea has been implemented in one of the first but already quite strong modern baselines for video retrieval, the CLIP4Clip model (Luo et al., 2022).
The only question here is how to break a video down into frames. Naturally, we don’t need all frames; in fact, CLIP4Clip and similar models usually sample just a few frames, like 4 or 8, and almost none of them try anything fancy to find representative frames, it’s usually just uniform sampling (in my opinion, this is a natural place for a potential improvement). After sampling, we still have a sequence of frame embeddings (albeit a short one), and one can unite these embeddings in different ways. CLIP4Clip studies several such possibilities:

And with that, we are basically at the state of the art level. It only remains to combine all of the ideas we have already discussed.
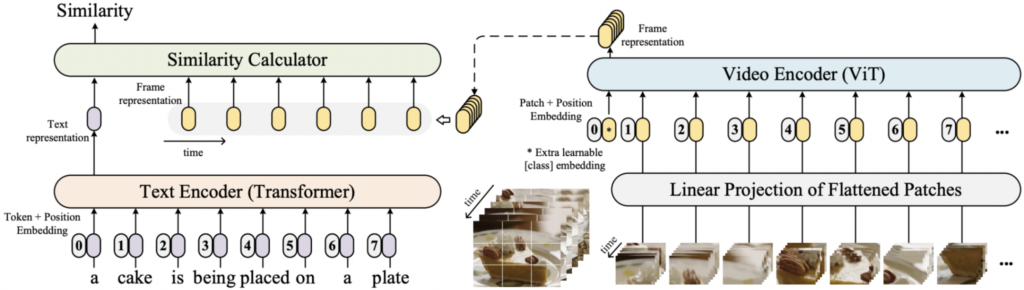
LiteVL (Chen et al., 2022) does approximately the same thing but replaces CLIP with BLIP that we also discussed above. The main novel idea here is to use additional temporal attention modules and text-dependent pooling that allow to adapt to video-language tasks starting from a pretrained image-text BLIP. As a result, it has more loss functions:
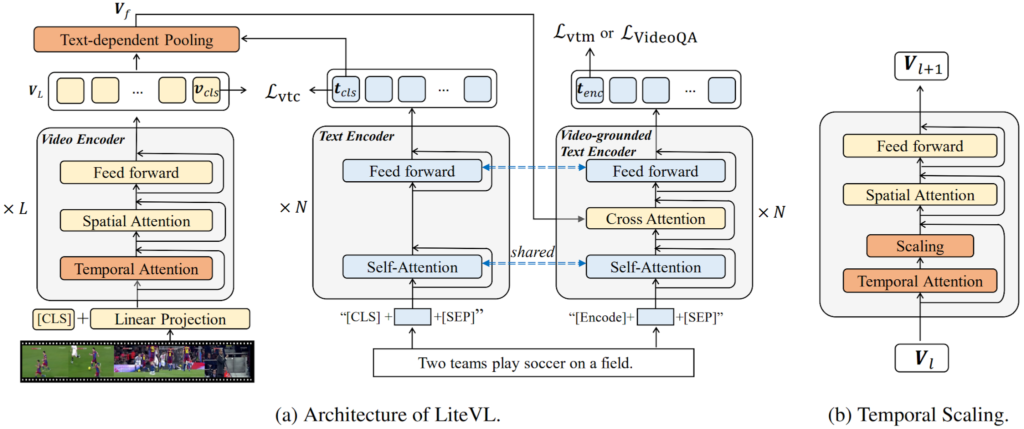
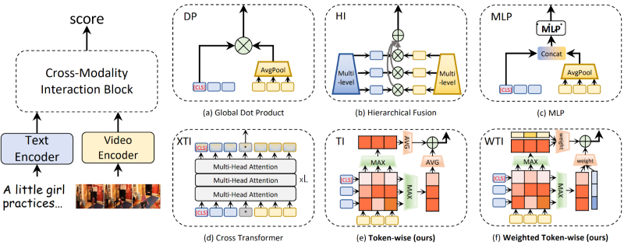
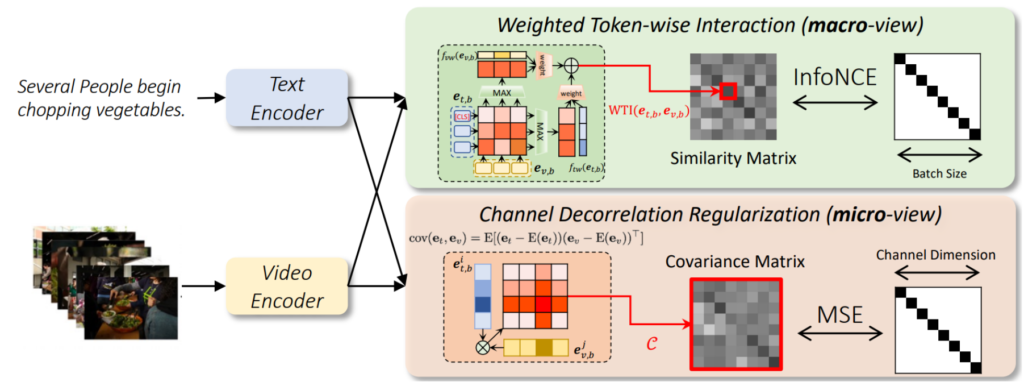
DRLTVR (Wang et al., 2022), where DRL stands for “disentangled representation learning”, is interesting in its very detailed study of different forms of cross-modal interaction in text-video retrieval. They consider six different ways to combine text and video representations to obtain a relevance score for retrieval and propose two new important ideas. First, a more fine-grained cross-modal interaction mechanism based on (possibly weighted) token-wise interactions, i.e., basically a cross-attention matrix between sentence tokens and video frame tokens:
Second, a channel decorrelation regularization mechanism that minimizes the redundancy in learned representation vectors and thus helps to learn a hierarchical representation:
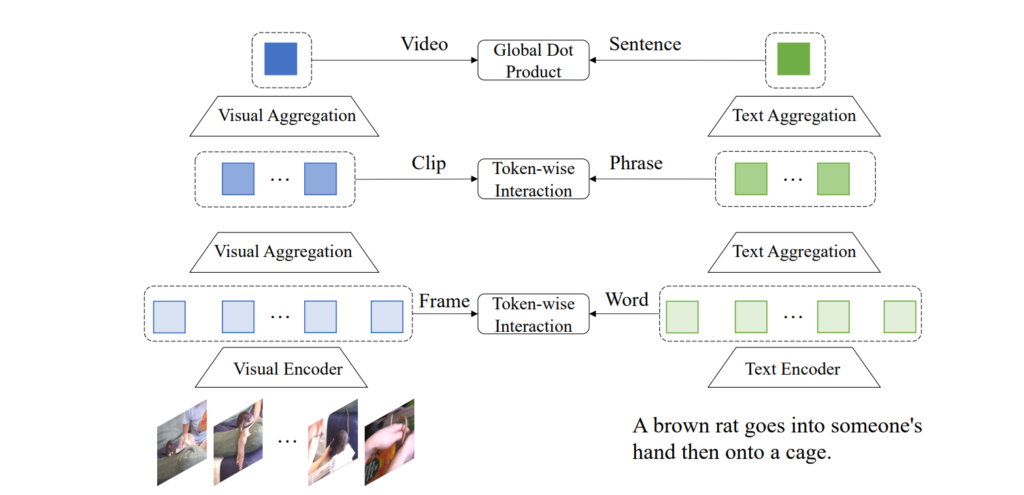
And finally, everything comes together in the very recently published Tencent Text-Video Retrieval (Jiang et al., 2022). It has a hierarchical representation structure with frame-word, clip-phrase, and video-sentence alignments:
Combined with a few more tricks related to adaptive label denoising and marginal sample enhancement (choosing the hardest text sample for a video), this has allowed Tencent Text-Video Retrieval to produce state of the art results.
I also want to note that this improvement in text-video state of the art is far from squeezing the last 0.1% out of beaten datasets. For example, let us consider the Recall@1 metric on the classical MSRVTT-7K dataset, that is, how often in its test set the model retrieves a correct result at the very top:
Even the most recent improvements are huge, and there is still a lot of room for improvement!
Today, our main intention has been to discuss multimodal encoders such as CLIP and BLIP that map different objects—mostly text and images—into the same latent space. However, after that we have taken a detour into text-video retrieval as a very practical sample task where such models are used almost directly: using CLIP directly with a few reasonable tricks has led to huge improvements.
Next time, we will consider another key component of modern generative AI: diffusion-based models. In the next installment, we will discuss its main ideas and some of the underlying math (but definitely not the whole thing!), and then it will be just one more step to Stable Diffusion and its kin.
Sergey Nikolenko
Head of AI, Synthesis AI
