
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Synthetic data is computer-generated data that models the real world. Synthetic data and generative artificial intelligence (AI) datasets have emerged as a disruptive new approach to solving the data problem in computer vision (CV) and machine learning (ML). By coupling visual effects (VFX) and gaming technologies with new generative artificial intelligence (AI) models, companies can now create data that mimics the natural world. This new approach to training machine learning models can create vast amounts of photorealistic labeled data at orders of magnitude faster speed and reduced cost.
Collecting, labeling, training, and deploying data and datasets is difficult, costly, and time-consuming for users. Multiple surveys have uncovered that artificial intelligence teams spend anywhere from 50–80% of their time collecting and cleaning data, which is a significant challenge.
On average, individual organizations spend nearly $2.3 million annually on data labeling. Additionally, real-world datasets raise ethical and privacy concerns. Examples of applications and use cases that require human images include ID verification, driver and pedestrian monitoring, metaverse, security, and AR/VR/XR. In these areas privacy challenges are pronounced.
Synthetic data is a tool that also enables customers to build machine learning (ML) models in a more ethical and privacy-compliant way. Researchers and developers can deploy models and bring new AI-driven products to market faster than ever before by using techniques that harness synthetic data.
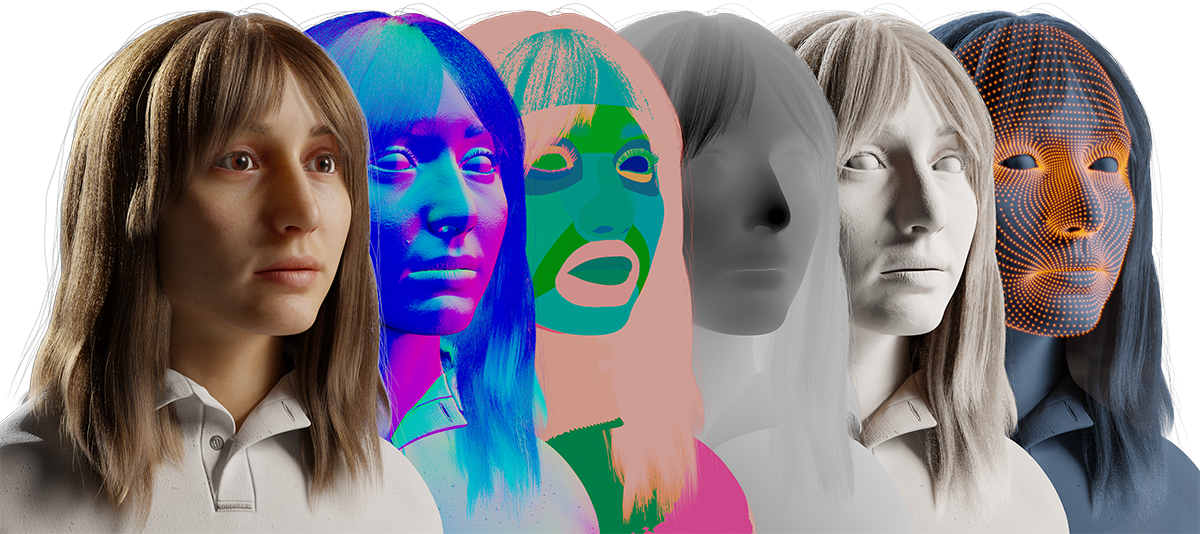
Gartner research predicts that the vast majority of businesses that seek to scale digital efforts will fail in the coming years. The few customers that succeed will do so by taking a modern approach to data and analytics governance, including the use of artificial data techniques.
In fact, Gartner believes that 60% of the data used for the development of artificial intelligence and analytics solutions will be synthetically generated. MIT Tech Review has called synthetic data one of the top breakthrough technologies of 2022. Synthetic data will dwarf the use of real data by 2030.
The increasingly sophisticated machine learning models being developed today require ever larger amounts of diverse and high-quality training data. The use of cheaper, easier, and quicker-to-produce synthetic data is rapidly emerging as a key driver of innovation.
Synthetic data is propelling ML models to new heights of performance and ensuring they perform robustly in a variety of situations and circumstances, including edge cases.
In addition to requiring vast amounts of data for training machine learning models, customers have complex regulatory, safety, and privacy challenges that can be addressed by replacing real data with synthetic training datasets.
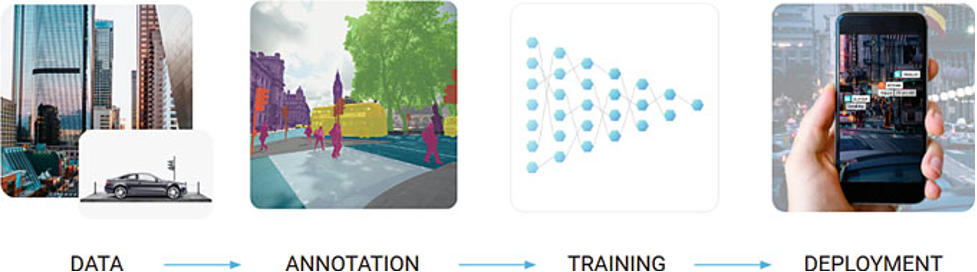
The data acquisition and annotation phases can consume 90%+ of a project’s resources.
Most computer vision applications and use cases apply the same basic technique for preparing data to train models. First, raw data is collected. It could be images of cats, videos of cars driving down the street, pictures of humans engaged in a broad set of activities, or any other alternative training dataset related to a specific problem and domain.
Often specialized hardware (e.g., autonomous vehicles, 360° camera setups, etc.) must be developed to support data acquisition. This is a long and expensive process. The data must then be labeled by human annotators. Image labeling may involve drawing bounding boxes on ears and tails, identifying pixels associated with pedestrians and stop lights, or completing more complicated tasks.
Whatever the specifics, labeling data manually is expensive and labor-intensive. To get a sufficiently large dataset, huge numbers of images must be labeled. Even with AI and a partially automated process, more complicated tasks could still take several minutes of labeling per image in a dataset that includes millions of images. This is a process that would take many years and millions of dollars to complete.
Once the data is assembled and labeled, machine learning models train on it. After training on the dataset, the models’ performance is validated on subsets of data specifically set aside for testing purposes. Finally, the trained model is deployed for inference in the real world.
The human annotation and labeling phase can account for upward of 80% of a project using real data. Consider a set of dominoes. At first glance, it seems like a fairly straightforward exercise to train a computer to count the number of pips on each tile. However, the lighting may be different in different situations or the dominoes themselves could be made of a different material.
Computers must learn that a wooden domino with three red pips in a vertical orientation in low light is the same as a horizontally oriented plastic domino with three blue pips in direct sunlight. This diversity must be reflected in the training dataset: if the model has never seen wooden dominos during training it will likely fail when they appear.
When extrapolated to self-driving cars or facial recognition, the level of complexity, and thus the level of manual labeling needed, is astronomical. To identify the value of a domino or a playing card, as challenging as it may be, is one thing. To identify a child chasing a ball into the middle of a busy street is quite another.
Collecting enough images of real human faces can be difficult due to privacy issues. It is also very difficult for researchers to capture diverse datasets across all desired parameters, leading to model bias. In the case of human data, this may lead to differential model performance with respect to demographics.
Humans may even be unable to provide the complex annotations needed for new use cases and edge cases. The metaverse and virtual reality, for example, require annotations in three dimensions. The computer needs to know the depth of an object and the distance between landmarks. This can be achieved in real life with expensive specialized hardware, but even humans cannot accurately label the third dimension (distance to camera) on a regular photo.
Even if these complex interactions could be calculated using human labels, there still remains the problem of human fallibility. As errors inevitably creep into any human endeavor, it is no surprise that existing datasets are known for having less-than-perfect accuracy. This is especially true for complex labeling such as segmentation. With segmentation, human labeling typically proves to be semantically correct but quite rough in the actual shapes.
As noted, the traditional computer vision model development process starts with the capture of data. In the case of autonomous vehicles, this results in many months of data capture. Capturing rare events and edge cases may require driving hundreds of thousands of miles. The need to deploy expensive hardware to acquire the data leads to incredible costs.
The massive amounts of data are then labeled by institutions with a small army of human annotators. In stark contrast, synthetic data technologies are able to deliver labeled data on-demand. By simulating cars, pedestrians, and whole cities, customers can now drive millions of miles virtually, reducing costs and increasing time-to-market for developing models.
Synthetic data tools are able to provide annotations that weren’t previously available through human annotation. Examples of complex labels include dense 3D landmarks, depth maps, surface normals, surface and material properties, and pixel-level segmentation characteristics. Such annotations are enabling machine learning engineers and developers to create new and more powerful computer vision models.
Capturing diverse and representative data is difficult, often leading to model bias. In the case of human-centric models, this may result in differential model performance with respect to age, gender, ethnicity, or skin tone. With synthetic data approaches, the distribution of training data is explicitly defined by the machine learning developer, ensuring class-balanced datasets. A broader and more uniform training data distribution reduces model bias.
Using traditional human datasets presents ethical and privacy issues. The use of real-world and free, publicly available datasets is only becoming more complicated as individual countries and trading blocs regulate data collection, data storage, and more. By its nature, synthetic data is artificial, enabling customers to develop models in a fully privacy-compliant manner. HIPAA applies only to real human data; no such federal regulations exist for synthetic data.
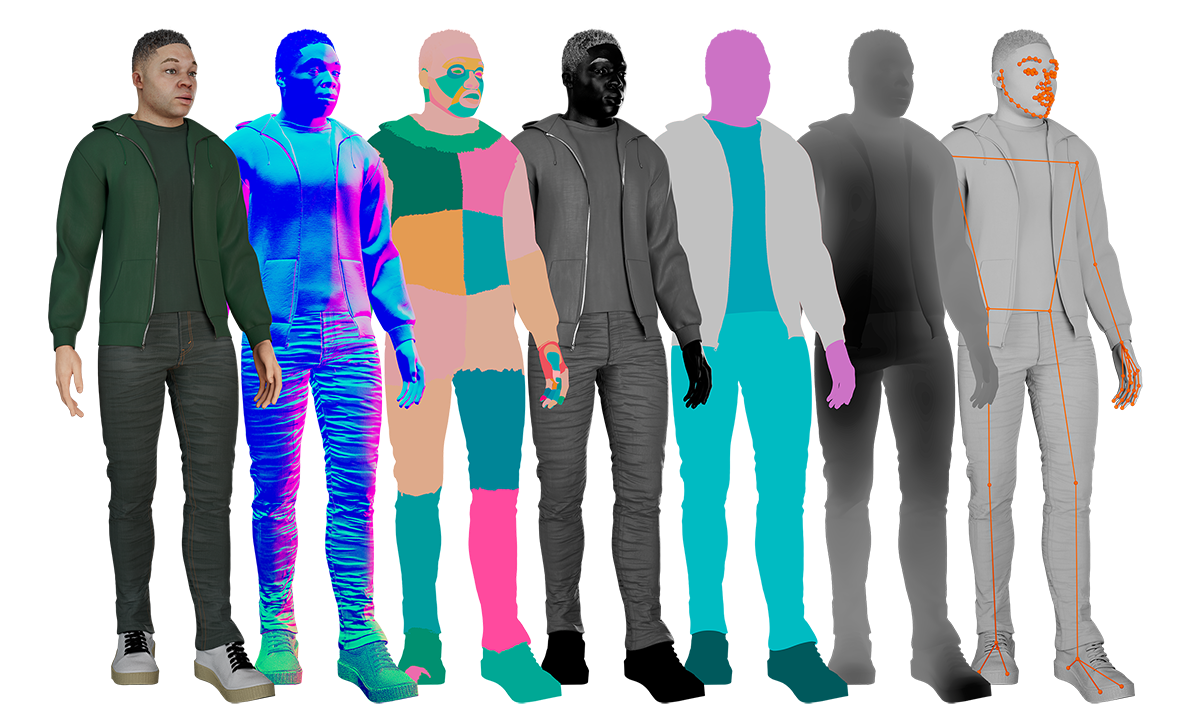
The metaverse requires a detailed understanding of users in a wide variety of actions and situations. People can laugh and dance, or withdraw and cry, or any other combination of emotions and actions. The diverse set of movements and expressions is beyond the capabilities of any artificial intelligence team, no matter how large, to annotate manually.
Avatar systems also need to work for all potential consumers. To achieve this, a diverse set of training data is required for age, skin tone, ethnicity, facial appearance, and other human qualities.
With synthetic data, it becomes feasible to create every possible combination of faces, body types, clothing, and poses. Views can be created from any camera angle using a pixel-perfect set of rich labels created in a synthetic generator, including detailed segmentation maps, depth, surface normals, 2D/3D landmarks, and more.

On the heels of EU regulations to monitor driver state and improve automobile safety, synthetic data is now being used to approximate diverse drivers, key behaviors, and the in-cabin environment to reduce car-related accidents, injuries, and fatalities all over the world. Developers are making similar progress with machine learning models for pedestrian detection systems with external sensors outside the cabin itself.
Models trained on synthetic data can detect head pose, emotion, and gestures, even with confounding elements like hats, glasses or other accessories. Synthetic datasets can be used to train models on real-world scenarios without putting human beings in dangerous situations such as looking away from the road while behind the wheel.
Synthetic data can also be used beyond the cabin. A whole new ecosystem of software providers, OEMs, and manufacturers is evolving quickly, with synthetic data providing a tool to help CV systems understand and react to the immediate environment outside the vehicle. Autonomous vehicles and their embedded CV systems need to account for pedestrians, animals, and environmental factors across a broad range of real-world conditions.
Enterprises and institutions large and small are increasingly using facial recognition as a form of identity verification, from unlocking mobile phones to getting access to a secure facility. Synthetic datasets can represent any possible user to train machine learning models for ID verification. Synthetic data can create inter- and intra-subject variability across a wide range of indoor and outdoor environments and lighting conditions.
When creating synthetic data for computer vision, the basic computer generated imagery (CGI) process is fairly straightforward. First, developers create 3D models and place them in a controlled scene. Next, the camera type, lighting, and other environmental factors are set up, and synthetic images are rendered. Finally, modern procedural generation techniques and VFX pipelines enhance the resulting images.
CGI and VFX technologies provide added realism, either to make more realistic objects or to make more capable sensors. With the former, complex objects (e.g., humans) and environments (e.g., city scenes) can be created at scale with photorealistic quality. In the case of the latter, simulated sensors, including stereo RGB, NIR, or LIDAR, enhance the realism of outputs, including simulating the noise and distortions found in the natural world.
Technology and algorithms from the gaming industry has also enabled the development of complex and dynamic virtual worlds, which the autonomous vehicle industry is using to train more robust perception models. The ability to simulate edge cases (rare events) like accidents, children running into the street, or unusual weather has improved the safety and performance of self-driving cars.
The world of animation and video games has produced great advances in 3D graphics data generation. Universal Scene Description (USD), a technology first developed by Pixar and made open source in 2016, has made it possible to collaborate with non-destructive editing, enabling multiple views and opinions about graphics data.
This framework for procedural world-building makes 3D models interoperable across a number of file formats. The growing ecosystem of interoperable 3D assets is making it easier for companies to simulate complex environments (e.g., home, retail environments, warehouses) that may be filled with any number of unique items.
New generative artificial intelligence (AI) models such as DALL-E 2, Stability AI, and Midjourney have helped artificial intelligence enter the mainstream. You have probably seen samples of these text-to image models, whose prompts can range from the prosaic to the fantastical to the whimsical, such as “Teddy bears working on new AI research underwater with 1990s technology.”

Today’s the day the teddy bears have their… underwater research!
Modern text-to-image models encode text into some compressed representation—think of it as translating the text into a different artificial language—and then use a decoder model to convert this representation into an image. The secret sauce in the latest models is a process called “diffusion.”
With diffusion, a model learns to iteratively work backward from random noise to create realistic images while also taking into account the “translated” text. It turns out that replacing the decoder part with a diffusion-based model can drastically improve the results. Text-to-image models with diffusion-based decoders can combine concepts, attributes, and styles to create images from natural language descriptions.
More than that, diffusion models can inpaint within an existing image. The face of another woman—or man, or animal—could be placed on the shoulders of the Mona Lisa, for example. Or they can outpaint, so that we can now discover what is to her left and right, and what lies beyond the hills in the background of the image. The algorithm will decide if it is a bird, a plane, or Superman flying above her as the focus zooms out.
Most of the current applications are focused on generating art and media. However, these models will soon be used in synthetic data generation pipelines to enable the scalable generation of novel textures for 3D objects, help compose complex scenes, refine rendered scenes, and even create 3D assets directly.
Recent advancements in Neural Radiance Field research
A photograph is essentially a 2D rendering of the 3D world. With neural radiance fields (NeRF), a 3D simulation can be recreated with accuracy from photographs of the same object or location taken from different angles. Whether creating a virtual world, a digital map, or an avatar in the Metaverse, NeRF needs only a few camera angles and information about where the cameras are placed.
The NeRF does the rest, filling in the blanks with synthetically generated data using its neural network’s best guess about what color light will be radiating out from any given point in physical space. It can even work when a view of a given item is obstructed in some angles, but not others. Artificial intelligence speeds this process up from hours to milliseconds, making possible accurate depictions of even moving objects in real time.
For synthetic data, NeRF-based models can help cut manual labor that goes into creating 3D models. After we have a collection of 3D scenes and 3D object models, the rest is more or less automatic: we can render them in varying conditions with perfect labeling, with all the usual benefits of synthetic data. But before we can have all these nice things, we need to somehow get the 3D models themselves.
Currently it is a manual or semi-automated process, and any progress toward constructing 3D models automatically, say from real-world photographs, promises significant simplifications and improvements in synthetic data generation.
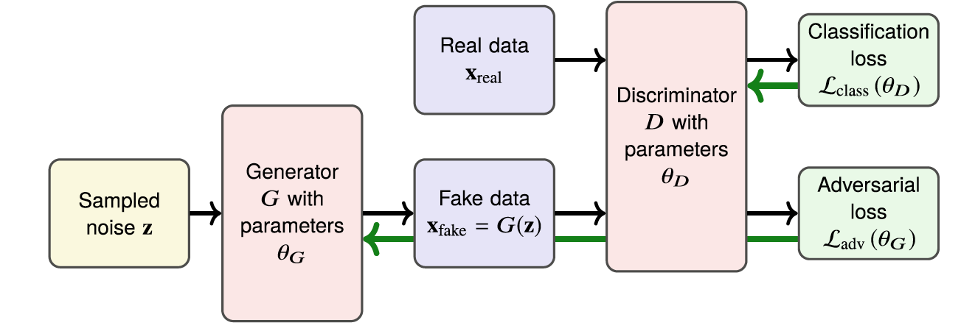
Basic architecture of GANs
Generative AI, CGI and VFX technologies are able to produce high-quality photorealistic images. However, machine learning models are often able to distinguish between real and generated data through subtle differences in sensor noise and complicated textures like skin. Regardless of how good the generated data is, there remains a domain gap between the real and synthetic data.
Enter generative adversarial networks (GANs). First developed by Google engineer Ian Goodfellow in 2014, GANs are based on a novel idea for determining whether an AI-generated image is realistic. One model, a generator, creates data.
A different model, a discriminator, attempts to distinguish AI-generated images from real ones. By pitting the two models head-to-head in adversarial training, GANs are capable of producing stunning results, and have been at the frontier of image generation in deep learning over the past several years.
Other models are beginning to complement GANs in terms of generation from scratch, but they are still unsurpassed in applications such as style transfer: converting a landscape photo into a Monet painting or coloring a black-and-white image. And this is exactly what is needed to improve synthetic data outputs: touching up CGI-generated data to make it more realistic both to the eye and to the model training on it.
Another important direction where GANs can help is the generation of textures for synthetic data: even regular CGI rendering can produce photorealistic results if the textures on 3D objects are good enough.
Making a texture sample more realistic looks like a much easier task than touching up a whole rendered scene, and the resulting textures can be reused to produce new images with no need to run large-scale GAN models.
Different types of GANs perform different types of work in this area. A mask-contrasting GAN can modify an object to a different suitable category inside its segmentation mask; e.g., replace a cat with a dog. Likewise, an attention-GAN performs the same feat, except with an attention-based architecture. Finally, IterGAN attempts iterative small-scale 3D manipulations such as rotation from 2D images.
Refining synthetic data is an important component of creating more realistic synthetic images, but domain adaptation at the feature- or model-level is also important. These methods make changes to the weights in the models, without making any changes to the data itself.
Domain adaptation is a set of techniques designed to make a model trained on one domain of data, the source domain, work well on a different, target domain. The problem we are trying to solve is called transfer learning, i.e., transferring the knowledge learned on source tasks into an improvement in performance on a different target task. This is a natural fit for synthetic data: in almost all applications, the goal is to train the model in the source domain of synthetic data, but then apply the results in the target domain of real data.
Model-based domain adaptation has to force the model not to care whether the input image is artificial or real. This is another problem where GANs can help: many such domain adaptation approaches use a discriminator that tries to determine whether the inner representation of an input image (features extracted by the model) has come from a synthetic image or a real one. If a well-trained discriminator fails to make this distinction, all is well: the model now extracts the same kinds of features from synthetic and real data and should transfer well from synthetic training into real use cases.
Far too much effort is spent developing machine learning models without considering the datasets that train them. Hundreds of hours can be wasted fine-tuning a model that could be improved more efficiently by improving data quality.
The move to data-centric artificial intelligence and machine learning is a paradigm shift from the way software has been developed historically. Ensuring good data becomes paramount, as opposed to upleveling the code. Such approaches are highly iterative and typically driven in a closed-loop fashion based on model performance.
Given the time required to manually label data, however, this makes the long cycles of manually collecting and preparing real data impractical for use in a data-centric machine learning training environment.
Using synthetic data, which can be produced quickly, cheaply, and with pixel-perfect accuracy, is a solution, but generating quality synthetic data at scale is extremely challenging for even the largest and most sophisticated technology companies and the world, and completely out of reach for most machine learning practitioners. The generator must simulate real-world conditions accurately.
To help educate the broader machine learning and computer vision communities on this emerging technology, Synthesis AI is an active member of OpenSynthetics. This open-source platform for synthetic data, the first of its kind, provides computer vision communities with datasets, papers, code, and other resources on synthetic data.

Synthesis Scenarios can help train ML models that need to account for more than one person.
We are sitting on a revolution: an unlimited supply of artificial data. Synthetic data is the renewable fuel that powers growth in generative AI — cheap, abundant and ethical. Any time using real data would take too long or cost too much to collect and annotate, or would subject individuals to harm or invasions of privacy, synthetic data can step in.

