AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
It is time to discuss some applications. Today, I begin with using LLMs for programming. There is at least one important aspect of programming that makes it easier than writing texts: source code is formal, and you can design tests that cover at least most of the requirements in a direct and binary pass/fail way. So today, we begin with evaluation datasets and metrics and then proceed to fine-tuning approaches for programming: RL-based, instruction tuning, and others. Next, we will discuss LLM-based agents for code and a couple of practical examples—open LLMs for coding—and then I will conclude with a discussion of where we are right now and what the future may hold.

Over the last couple of months, I have been getting plenty of post and video recommendations with bloggers all saying the same thing: coding is dead. AI is taking over programming, there is no point learning to code, humans should move from coding to biology, farming, or videoblogging — you’ve heard the sentiment, no doubt.
These bloggers are if anything late. Jensen Huang said it back in February 2024: at the World Government Summit in Dubai, he said that while for many years every tech person had considered it “vital” for young people to learn computer science, to learn how to program, “in fact, it’s almost exactly the opposite. It is our job to create computing technology such that nobody has to program. And that the programming language is human. Everybody in the world is now a programmer. This is the miracle of artificial intelligence.” This sentiment has been around ever since at least OpenAI Codex, a coding model published back in 2021.
Today, as 2024 is turning into 2025, where are we with AI for coding? Is coding really dead? This is the main question I want to consider today.
Another motivation for this post is that over the last months (actually, almost two years already!), we have been discussing modern generative AI and in particular large language models (LLMs). Lately, we have seen several directions of improving and extending fundamental Transformer-based LLMs, including fine-tuning methods, RAG, extending the context, and Mamba-like models. But how do these and other methods come together in real applications? To answer this, I want to make a couple of case studies in specific fields where LLMs are being actively applied. We have already had such a post before, devoted to AI in mathematics, but it was significantly more general, and did not feature modern LLMs too much.
For today’s case study, I have chosen programming and other code-related tasks, a field where, first, we can discuss fine-tuning approaches in a rather straightforward way, and second, some research directions are familiar to me personally (Lomshakov et al., 2024; Sedykh et al., 2024; Lomshakov et al., 2023). This post is partly based on a survey of LLMs for code we have recently done together with Vadim Lomshakov, so big thanks to him too.
Our plan for today is simple but quite extensive:
Naturally, I cannot hope to give a full overview in this post; that would require a huge paper or even a whole book, so for a more comprehensive treatment, I refer to, e.g., (Jiang et al., 2024; Zan et al., 2023; Joel et al., 2024) and other surveys. But for every direction, I give a couple of representative examples that, I hope, will provide a good intuition for coding applications of LLMs.
However, all of this content, while interesting, will not answer the main question: is coding dying? So in the final part, we will discuss the current state of top models for coding, where we often don’t really know how these models work but we can definitely see some great examples.
Enjoy!
Source code is a rather special field compared to other text generation tasks. In text writing and answering open-ended questions, there can be a million ways to formulate the answer, it is hard to establish which of these ways are equivalent, and often one has to resort to asking people (like in RLHF that we discussed in a previous post). Sometimes you can get by with multiple choice questions with well-defined answers, but often multiple choice cannot get you all the way to a real application.
In coding, there are still a million different ways to write a program but often you can define formally verifiable ways—simply speaking, tests—that can tell you if the function is correct better than any human supervision (although still not perfectly: it is usually impossible to have full test coverage). In this section, we discuss existing ways to evaluate code models, including the metrics and open datasets available for their fine-tuning and evaluation. We will refer to the test sets from this section many times below since they are the sets where models get compared with each other.
This benchmark, published by OpenAI researchers Chen et al. (2021), is one of the most popular datasets for code models. The main task considered in HumanEval is evaluating the quality of Python functions generated by a given description, documentation style. The dataset contains 164 programming tasks designed by hand and covering Python understanding, algorithms, and basic math and computer science; these tasks are similar to easy questions on an interview for a software developer position.
The primary evaluation metric is pass@k, computed as
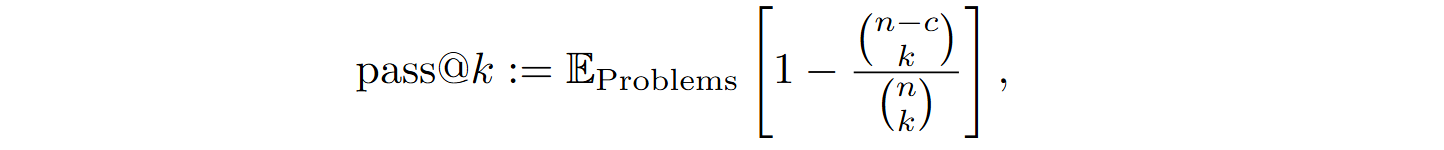
where n is the total number of generated solutions, c is the number of solutions that have successfully passed all tests, k is the number of chosen solutions, and brackets denote the binomial coefficient.
The pass@k metric has an intuitive combinatorial meaning: it shows the probability that at least one out of k randomly chosen solutions turns out to be correct. Note how this corresponds to good practice in using LLMs: since running an LLM is cheap anyway, it is usually best to ask it for several solutions and/or regenerate the answer several times, choosing the best one. Naturally, this applies not only to coding but to all tasks, but in coding, it is especially easy to choose the best out of k even for a relatively large k.
Mostly Basic Programming Problems (MBPP) is another popular dataset for generating individual functions in Python, this time published by Google Research (Austin et al., 2021). MBPP contains 974 short Python programs collected with crowdsourcing among people with some Python experience.
Each entry in the dataset contains a description of the problem, its solution as a Python function, and three tests to check correctness. The tasks are again relatively small and interview-like: 58% of the problems are mathematical in nature, 43% are related to list processing, and 19% to string processing; the average solution length is 6.8 lines. After manual verification and refinement, the authors chose 426 guaranteed clear and correct questions for the final dataset. The primary evaluation metric is the proportion of solved problems, and a problem is, again, considered solved if at least one of the K solutions passes the tests successfully; Austin et al. (2021) used K=80.
Extended versions of HumanEval and MBPP have been released as HumanEval+ and MBPP+ respectively; in these extensions, the authors added more tests and clarified some ambiguous problem statements (Liu et al., 2023).
The next benchmark, Automated Programming Progress Standard (APPS), contains 10000 programming problems collected from open platforms such as CodeForces and Kattis. It is designed to evaluate both programming and problem-solving skills; it includes natural language problem descriptions and over 130K test cases to verify solutions. The dataset also contains over 230K reference solutions written by humans, with problem difficulty ranging from beginner to university-level competitions.
This time the problems are significantly more complex: the average problem description length in APPS is 293.2 words. The dataset is evenly divided into 5000 problems for training and 5000 for testing, with test problems averaging 21.2 modular tests per problem, so the coverage can be assumed to be quite good.
All problems are divided into three difficulty levels: beginner, interview-level, and competition-level. APPS uses two main evaluation metrics:
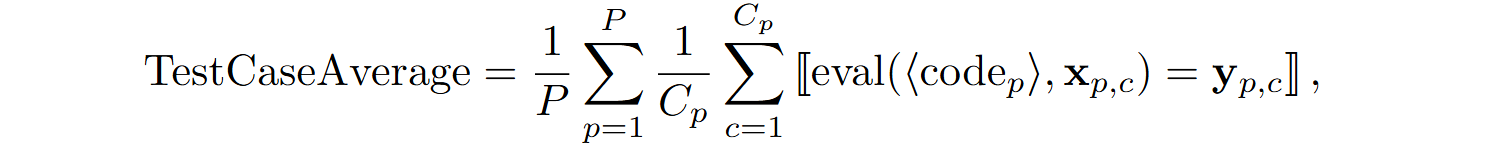
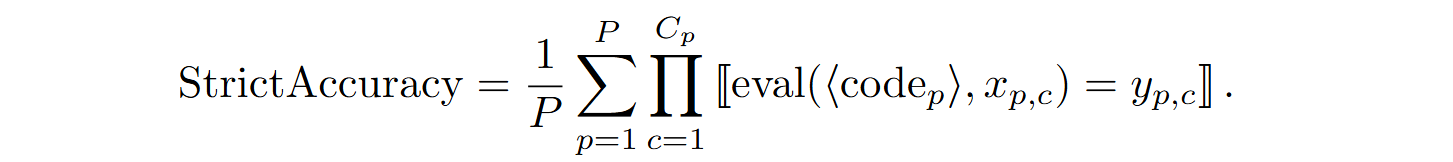
As you can see, the average number of tests passed is a less demanding metric; it captures improvements even in models that cannot yet solve problems completely. “Strict accuracy”,’ on the other hand, reflects a model’s ability to solve problems entirely, including complex edge cases, which is crucial for real-world applications.
This is another commonly used Python benchmark that aims to address certain issues with its predecessors (Jain et al., 2024). The main problem that the authors tried to avoid is the risk of contamination, i.e., leaking test data into the training set. To this end, they collected 511 competitive programming problems from platforms such as LeetCode, AtCoder, and CodeForces, published between May 2023 and May 2024.
Besides, for a more comprehensive comparison of code models, the authors introduced three additional task categories beyond function generation from documentation:
Here is the illustration from LiveCodeBench:
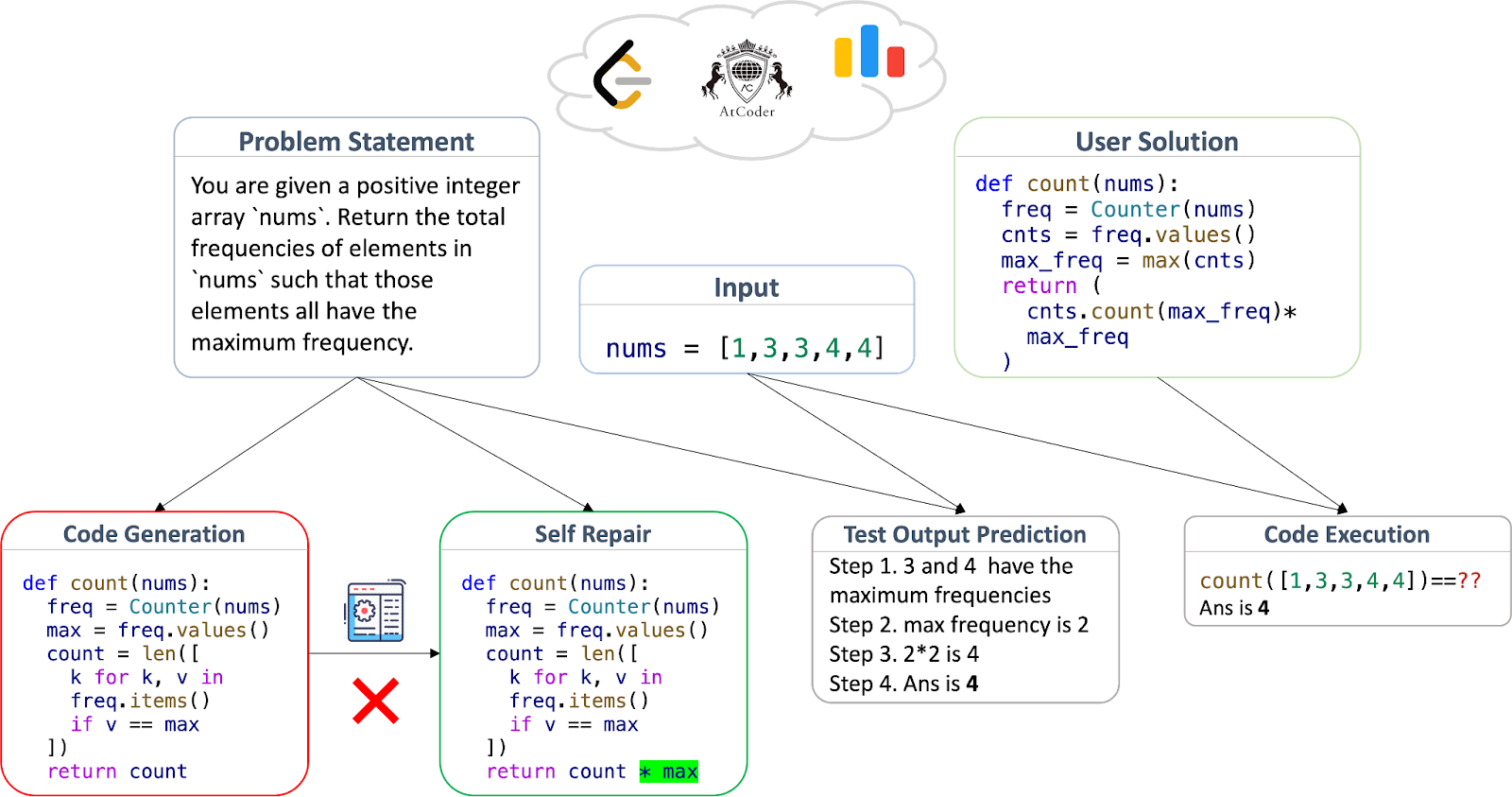
For program generation and debugging, LiveCodeBench uses the pass@k metric defined in HumanEval; there are about 17 tests per task on average so coverage is again quite good. For program execution and output prediction tasks, it uses a binary metric comparing the result to the reference answer. Moreover, the authors classified all tasks by difficulty level (easy, medium, hard) and balanced their distribution, allowing for a more detailed comparison of models with the same average metric value.
The “Live” part of LiveCodeBench deserves special attention. It might seem that contamination should not be a serious problem for LLMs: they are trained on trillions of tokens, and even the code-related part used for fine-tuning is usually quite large, so even a very large model definitely cannot memorize its training set. However, experiments have shown that depending on the release date of the model, a sharp decline in performance indeed happens even for top models such as DeepSeek, GPT-4o, or Codestral: if problems are not part of the datasets available for (pre)training at the time of the model release, some models perform noticeably worse on them.
Therefore, to get a more realistic quality assessment one has to select more recent problems, published after the release of the model. The LiveCodeBench leaderboard compared models only on problems added after the cutoff date of their training and fine-tuning sets. For example, here are some top rows from the LiveCodeBench leaderboard on problems submitted after January 1, 2024:
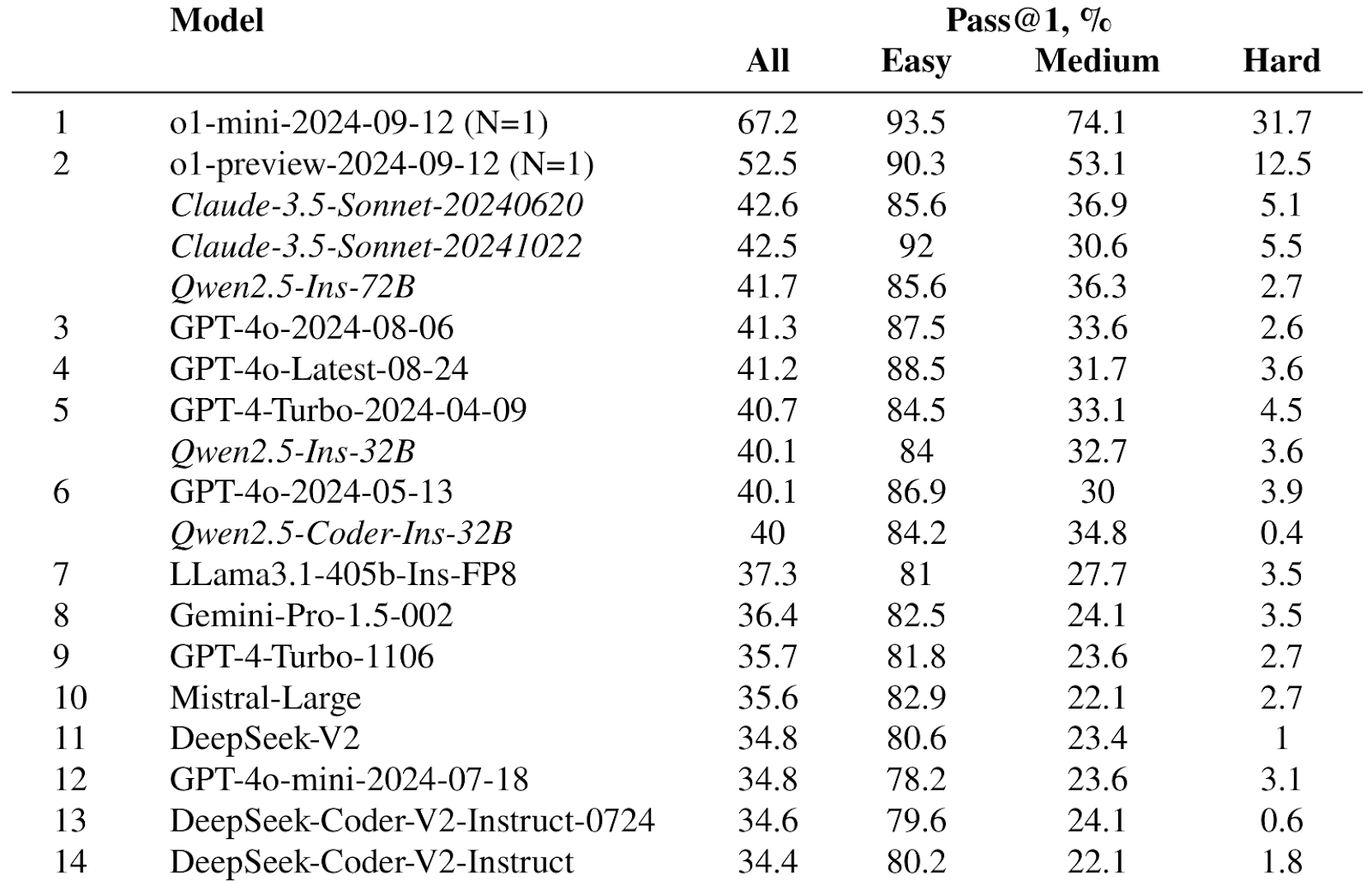
As you can see, some top entries are italicized and not assigned a rank; these are exactly models that might be contaminated by having some test problems in their training sets, and while metrics are still computed it is easy to distinguish such models. Here is a sample leaderboard for the bugfixing part of LiveCodeBench:
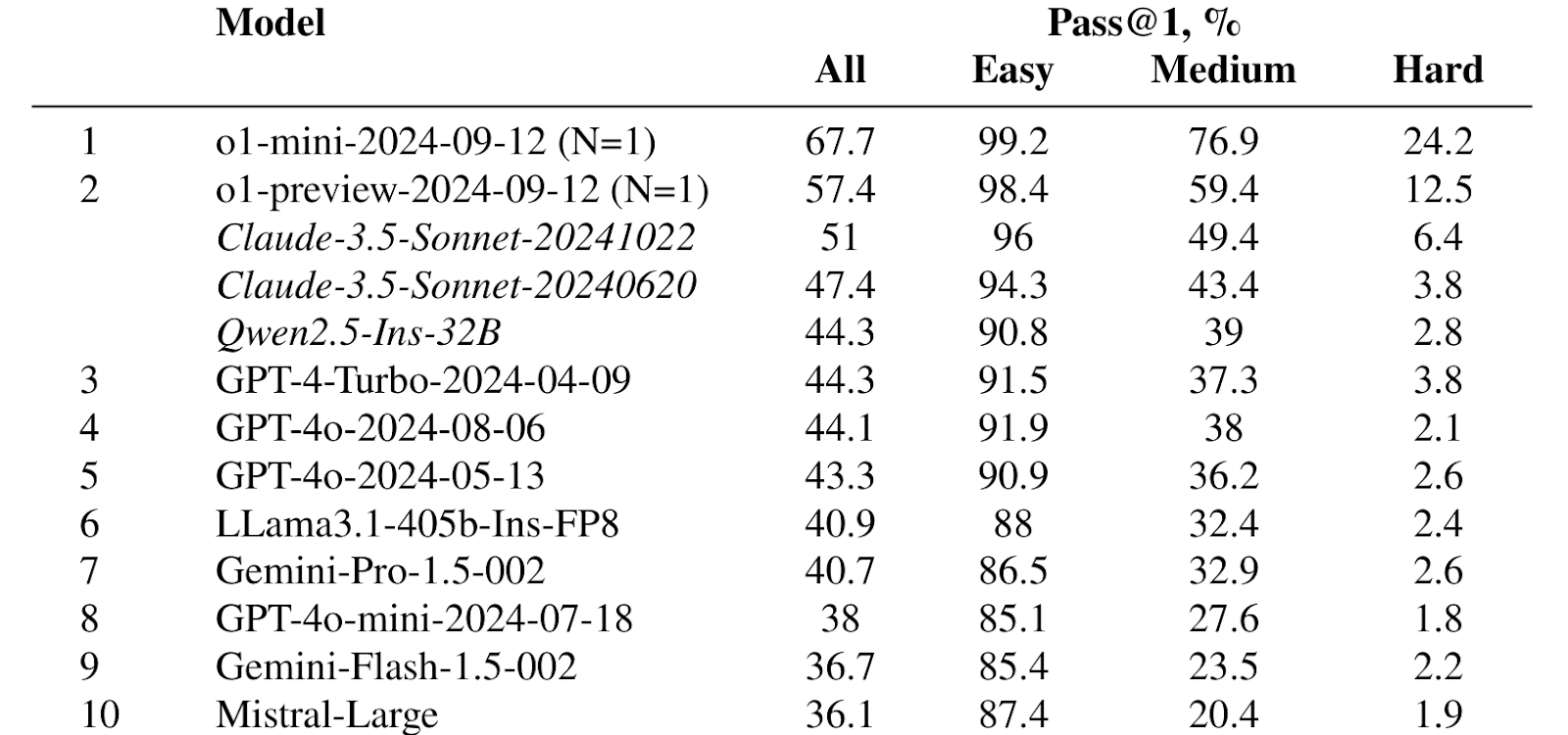
I took these samples from the LiveCodeBench leaderboard in early December; by the time I’m publishing this post, another champion has already been crowned, but let’s hold off this discussion until the end.
The CodeContests dataset was compiled for fine-tuning and evaluation of DeepMind’s AlphaCode model (Li et al., 2022). It contains competitive programming problems taken from the CodeForces platform, with a small set of open tests. Each problem has an average of 203.7 hidden tests, and the test subset of CodeContests contains 165 problems. For evaluation, it uses the standard pass@k metric, which in this case is simply the percentage of solved problems in a protocol where the model generates k solutions for each problem, they are tested on hidden tests, and if any one of the k solutions passes the problem is considered solved. But it also includes an interesting variation, 10@k, which is the percentage of solved problems in a protocol where the model generates k solutions for each problem but can only run hidden tests on 10 of them. This reflects the difference between relatively “cheap” additional generations from the model and the relatively “expensive” process of re-evaluating and testing them. If the model can choose the best among its generations, it would be easy to ask it to generate more. In the same vein, CodeContests allocates a fixed amount of time for running tests on each problem, requiring some efficiency.
The next benchmark, introduced in the work on the TransCoder model (Sun et al., 2023), was created to evaluate the quality of program translation from one programming language to another. For this purpose, the authors collected examples from the GeeksforGeeks website of implementations of the same function in C++, Java, and Python. In total, they collected about 460 functions for each language, with 10 tests for every function. The quality metric used is the percentage of solutions that successfully pass the modular tests.
The tldr benchmark (Zhou et al., 2022) goes from programming to command-line scripting characteristic of sysadmin and devops work: it contains pairs of human queries in English and the corresponding bash commands with the necessary combination of flags. It includes 9187 pairs that span 1879 unique bash commands, and is intended to evaluate bash command generation based on user instructions. It uses several straightforward evaluation metrics:
The SWE-bench benchmark (Jimenez et al., 2023) was also developed to evaluate LLMs for coding tasks but this dataset concentrates more on real-life problems with repositories; it includes 2294 pairs of problem descriptions (issues) and their corresponding solutions (pull requests) from 12 popular Python repositories. Models are provided with the codebase and a problem description, and they are required to generate a patch that resolves the specified problem.
SWE-bench evaluates whether models can understand and coordinate changes across multiple functions, classes, and even files simultaneously, requiring complex reasoning and interaction with the programming environment. The evaluation is conducted using modular tests: if the proposed fix passes both new and existing tests, it is considered successful.
Some model comparisons also include a more general-purpose benchmark Super-NaturalInstructions (Wang et al., 2022), designed to evaluate the generalization capabilities of models. In this benchmark, models are asked to solve various tasks based on instructions written in natural language. The dataset contains 1616 distinct tasks from 76 unique task types, including classification, text editing, summarization, and others, as well as programming-related tasks such as code description and program generation from textual descriptions.
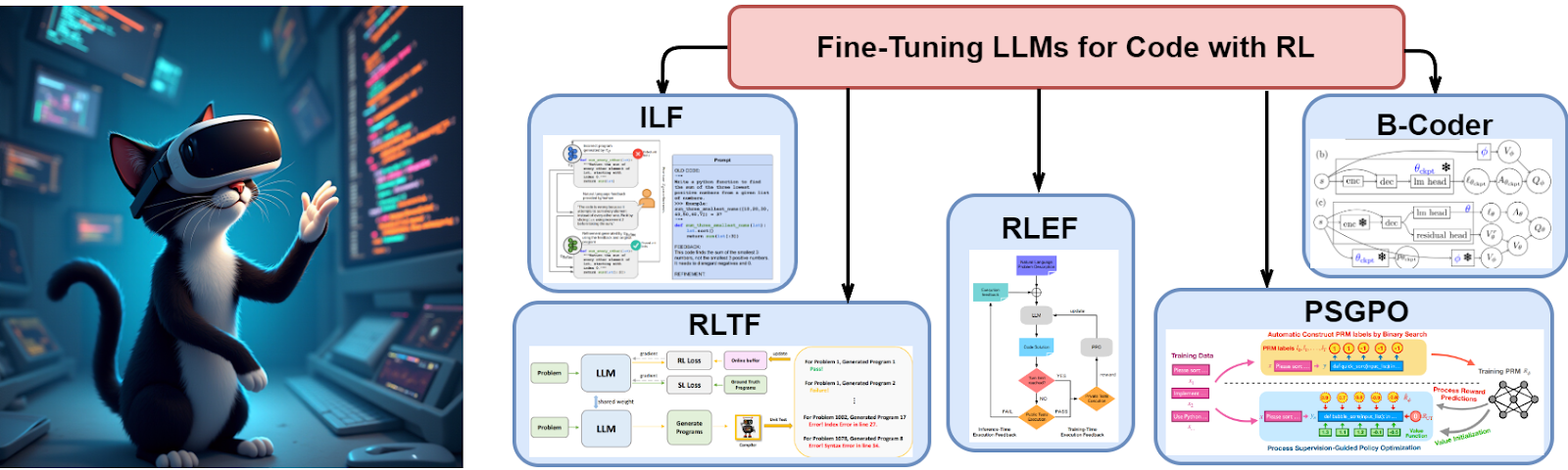
We have already discussed applications of reinforcement learning (RL) for LLM fine-tuning in the context of RLHF. For LLMs for code, the main concepts remain the same: code generation is treated as a sequential decision making problem formalized via a Markov decision process (MDP) defined as a quintuple
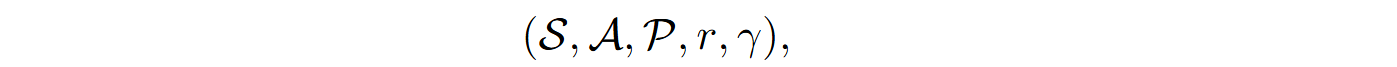
where S is the state space, with a state st = (y<t, x) consisting of a prefix of tokens y<t and problem description x, A is the set of actions corresponding to choosing the next token yt, P(s‘|s, a) is the transition function that defines the probability of passing to a state s‘ after performing action a in state s, r(s, a) is the reward function for action a in state s, and γ is a discounting coefficient for future rewards, a number from 0 to 1.
The goal of reinforcement learning is to maximize the total expected reward
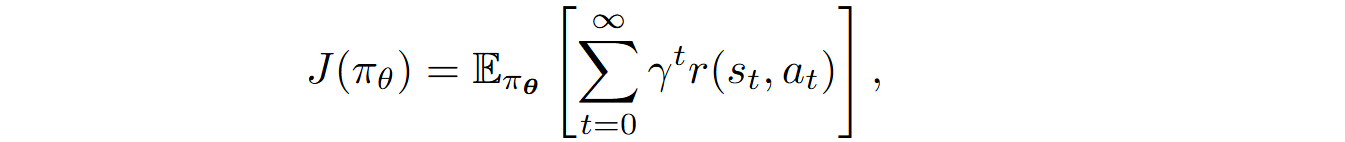
where πθ(a|s) is a policy (parameterized by θ) that defines the probabilities of taking certain actions in each state.
Other key notions in RL are the state value functions V and state-action value functions Q, defined as
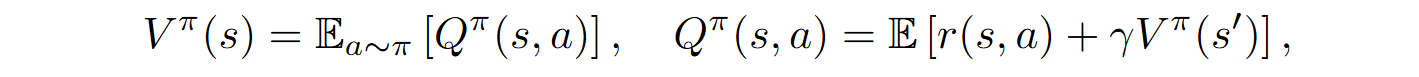
where s‘ is the next state.
Reinforcement learning is usually done in one of two ways:
Each of the methods considered below uses one of these approaches; I cannot go into a detailed exposition of reinforcement learning here and recommend classical books and surveys (Sutton, Barto, 2018; Zheng et al., 2023; Schulman et al., 2017).
Liu et al. (2023) propose a method called reinforcement learning from unit test feedback (RLTF) to improve the quality of code generation using pretrained language models (LLMs). The core idea of RLTF is to integrate a real-time data generation mechanism with multi-level feedback from unit tests that would enable the model to learn more effectively through more diverse and relevant examples. Here is an illustration:
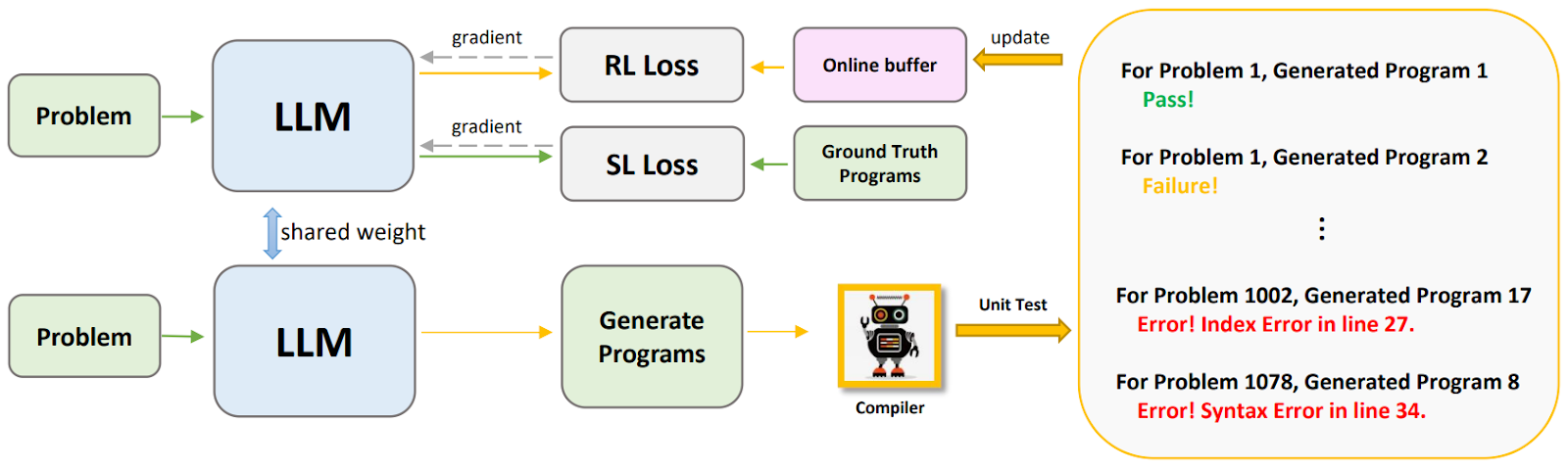
Here, the source code generation task is formalized here as sequential generation of the code W that satisfies a high-level problem description D. The goal is to maximize the conditional probability
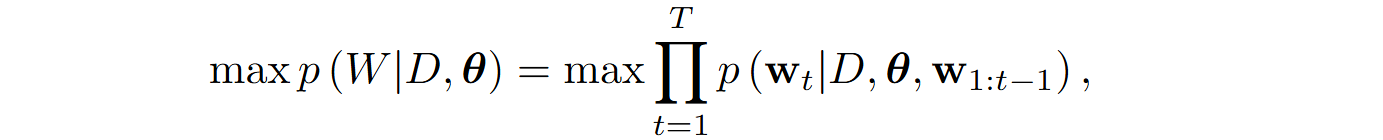
where θ are model parameters, T is the sequence length, and wt is the t-th token of generated code.
RLTF uses an online buffer which is updated dynamically during training. The buffer contains data pairs consisting of a problem description D, generated code W’, and feedback from the compiler FB(W’). Optimization uses the following loss function that combines standard reinforcement learning and feedback of varying granularity:
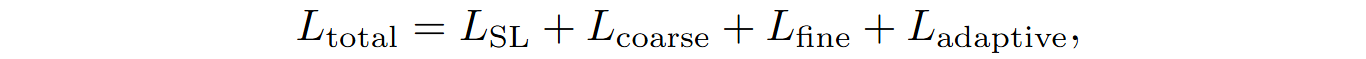
where LSL is the standard supervised learning loss, and Lcoarse, Lfine, and Ladaptive are reinforcement learning components.
Liu et al. (2023) distinguish three types of feedback mechanisms:
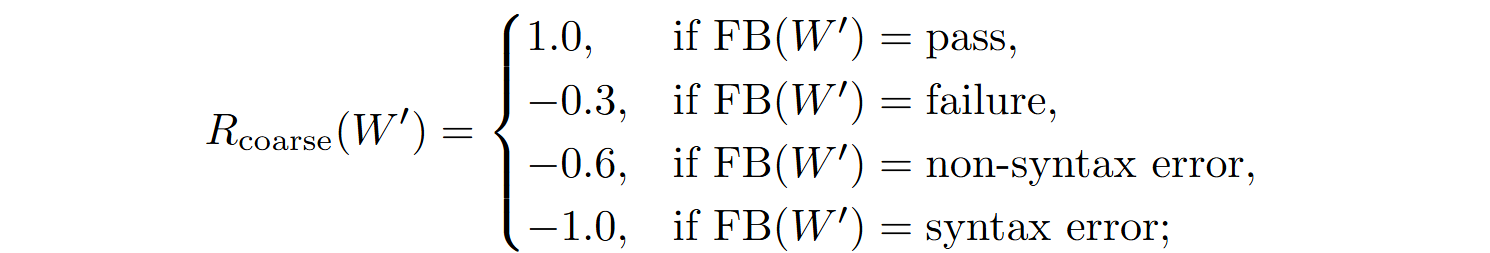

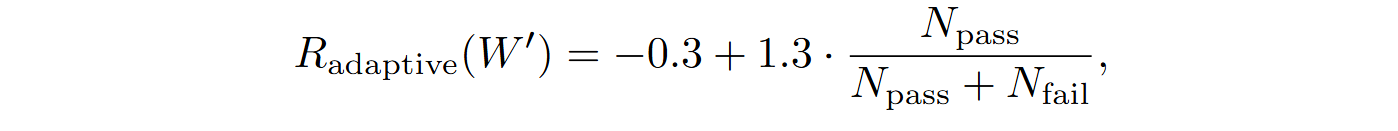
The overall loss function combines all levels of feedback:
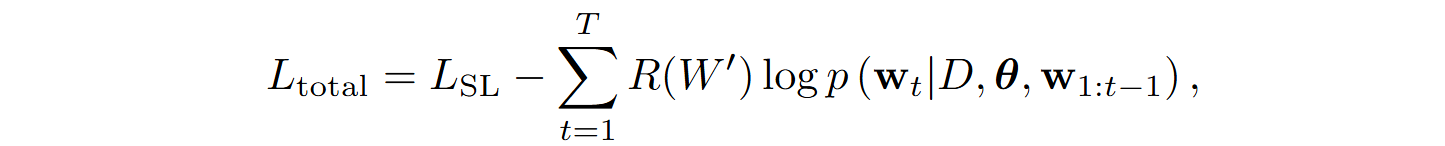
where R(W’) integrates Rcoarse, Rfine, and Radaptive.
Experiments on the APPS and MBPP benchmarks showed that RLTF improves code generation results, outperforming other approaches such as CodeRL and PPOCoder both in the quality of generation and versatility across different models, including CodeT5 and CodeGen. Ablation studies also confirmed the importance of online learning and the proposed feedback mechanisms.
Gehring et al. (2024) introduce reinforcement learning with execution feedback (RLEF), which uses feedback obtained during code execution instead of feedback from the compiler or unit tests. The main idea is to frame the problem as a partially observable Markov decision process (MDP), where actions correspond to sequential code generation and observations include feedback on the test results. This enables the LLM to not only generate solutions but also iteratively correct errors based on provided feedback, as illustrated below with the general flowchart on the left and a sample “inner dialogue” on the right:
RLEF optimizes a policy π using the proximal policy optimization (PPO) algorithm. The reward is defined as follows:

The overall reward function also includes regularization in the form of KL divergence between the current policy π and the initial policy ρ:
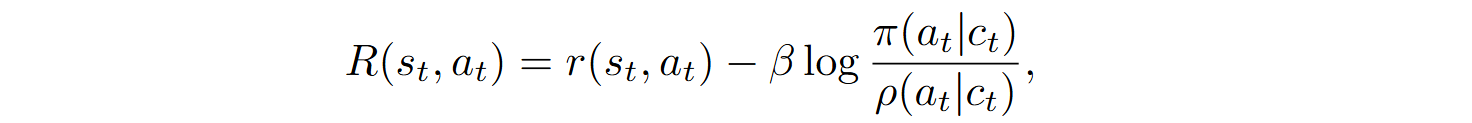
where ct is the sequence of previous observations and actions, and ꞵ is the regularization coefficient.
Optimization is based on the advantage function
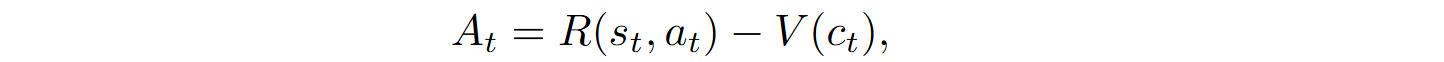
where V(ct) is the value function. To minimize the loss, RLEF uses the clipped objective function from PPO:
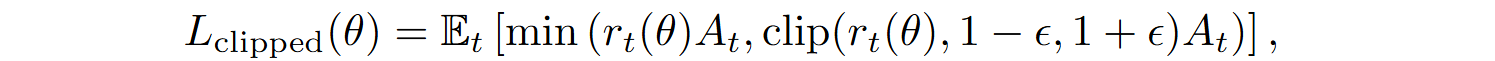
where
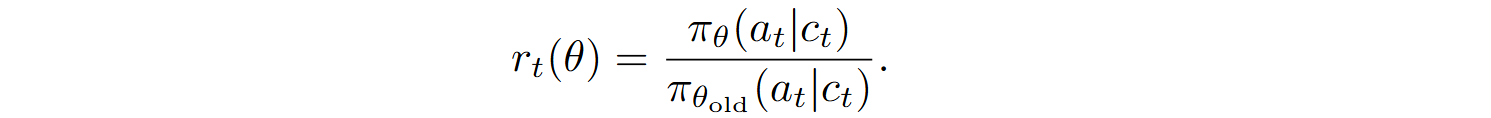
Experiments on challenging benchmarks such as CodeContests, HumanEval+, and MBPP+ showed that RLEF improves results with significantly lower computational costs. The method provided improvements for both small models (8B parameters) and large models (70B parameters), showing their ability to effectively fix errors and adapt to feedback in iterative code synthesis. The experimental study by Gehring et al. (2024) indicates that RLEF not only enhances first generation accuracy but also significantly improves the quality of subsequent fixes. This opens up opportunities for automatic iterative correction and enhancement of generated code.
Introduced by Yu et al. (2024), this is another reinforcement learning based architecture for program synthesis, but unlike most other methods we discuss today, B-Coder uses value-based RL approaches instead of policy-based RL algorithms such as the frequently mentioned PPO. B-Coder focuses on optimizing the functional correctness of programs with minimal reward function design costs.
The task of program synthesis is again formalized as the sequential generation of a program W = (w0,w1,…,wT) based on a textual problem description D. Generating each token wt is interpreted as taking an action at in a state st = (w<t, D). Thus, the training process is defined as a Markov decision process (MDP) characterized by the tuple (S, A, P, r, γ), where

The RL objective is to maximize the discounted cumulative rewards
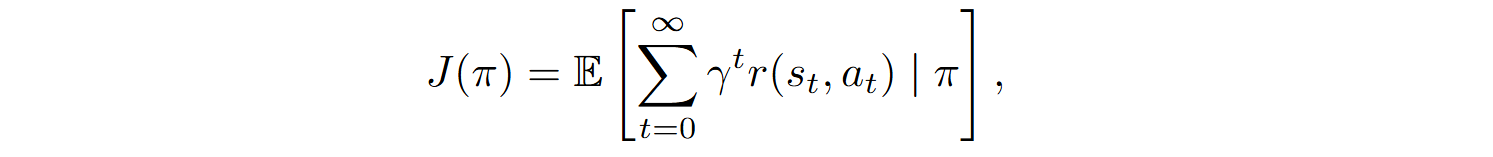
where π is the policy for selecting actions.
Unlike other methods, Bl-Coder uses Q-learning to estimate the state-action value function:
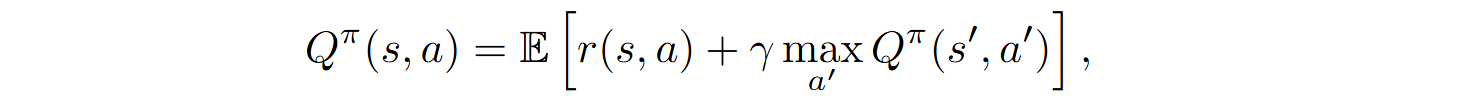
where s‘ is the next state obtained after taking action a in state s.
One of the main problems of RL in general and Q-learning in particular is training instability: policies and value functions tend to overfit, quickly get into local maxima, and so on. For example, the whole point of TRPO and later PPO compared to standard policy gradient is to restrict how far a single training step can go, limiting updates to a trust region with explicit constraints in TRPO or by clipping the reward in PPO. To stabilize training, B-Coder uses the following tricks:
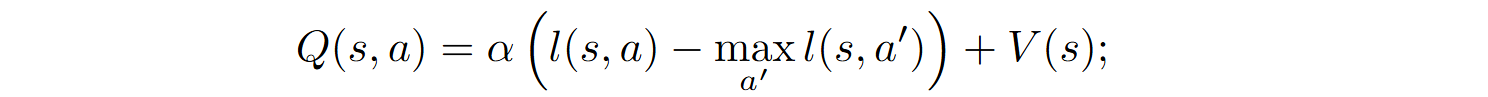
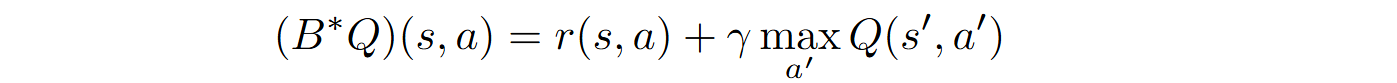
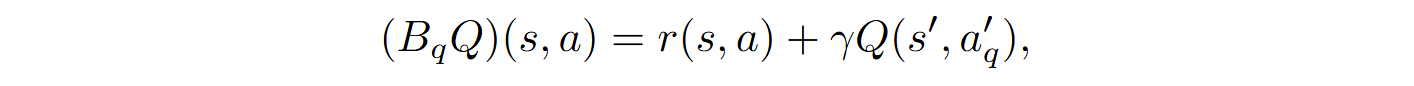
Training in B-Coder proceeds in two stages:
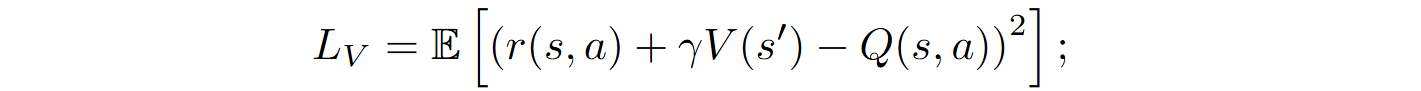
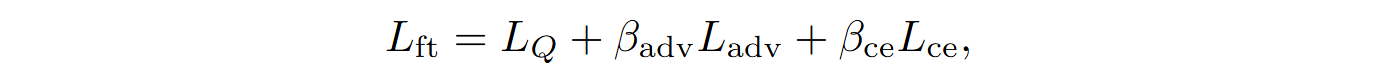
Yu et al. (2024) conducted experiments on the APPS and MBPP benchmarks; they showed that Bl-Coder outperforms prior approaches such as CodeRL, PPOCoder, and RLTF in terms of code generation quality. The conservative Bellman operator improves training stability, and the use of off-policy data ensures high sampling efficiency.
A rather recent work by Dai et al. (2024) introduces a variation of policy optimization methods called process supervision-guided policy optimization (PSGPO). Its main motivation is to address the issue of sparse reward signals in RL-based code generation tasks: usually the model only gets a reward based on the entire code project passing or failing tests or raising errors. The key innovation of PSGPO is the process reward model (PRM) that provides detailed feedback at line level, enabling the model to improve its solutions incrementally during code generation.
The code generation problem is again formulated as the sequential generation of tokens y = (y1, y2, …, yT) based on the input task description x. A pretrained language model pθ(y|x) estimates the conditional probability distribution
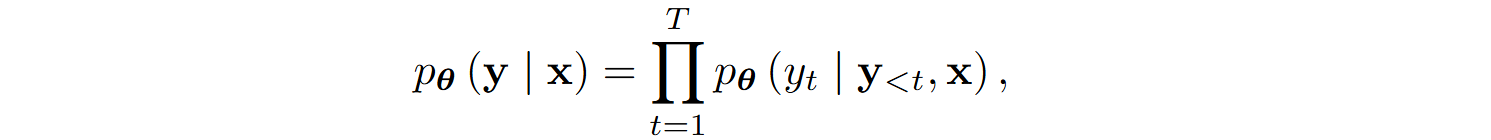
where y<t = (y1,…,yt-1).
The reinforcement learning objective is to maximize the expected reward
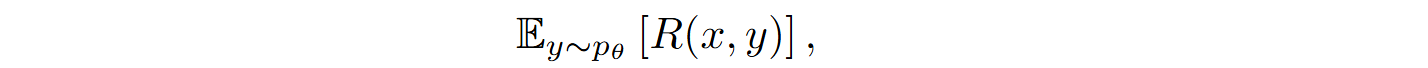
where R(x, y) is the reward function based on passing tests.
The PRM provides detailed feedback by evaluating the correctness of every line in the generated code. PRM is trained using labels automatically derived through binary search. The label for a prefix y<m is defined as
PRM is trained to minimize the squared error
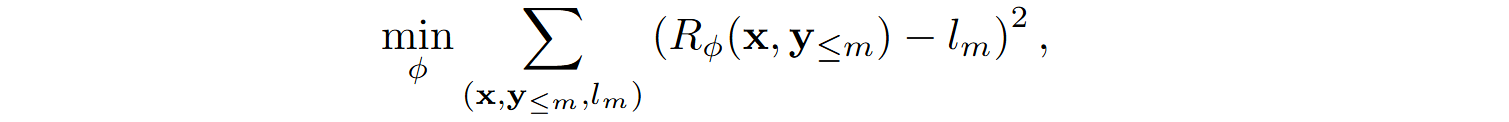
where Rɸ is the PRM’s prediction.
During reinforcement learning, PRM is used in two ways:
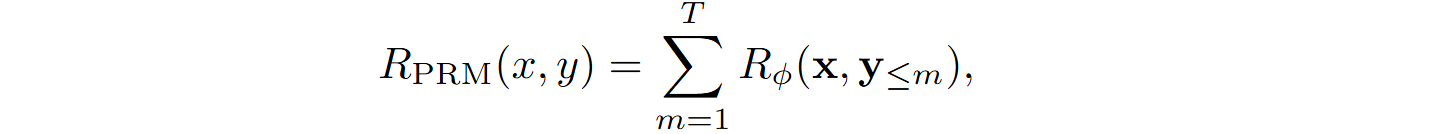
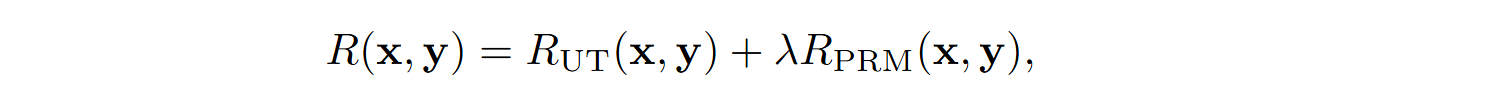
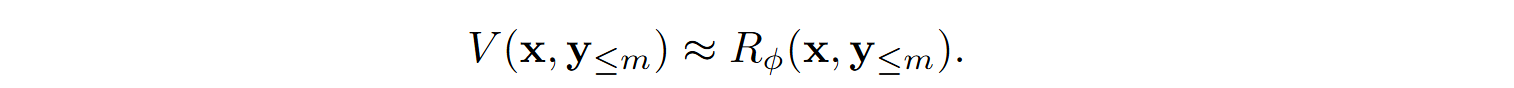
The process of automatic labeling by PRM and its integration with reinforcement learning is illustrated below (REF):
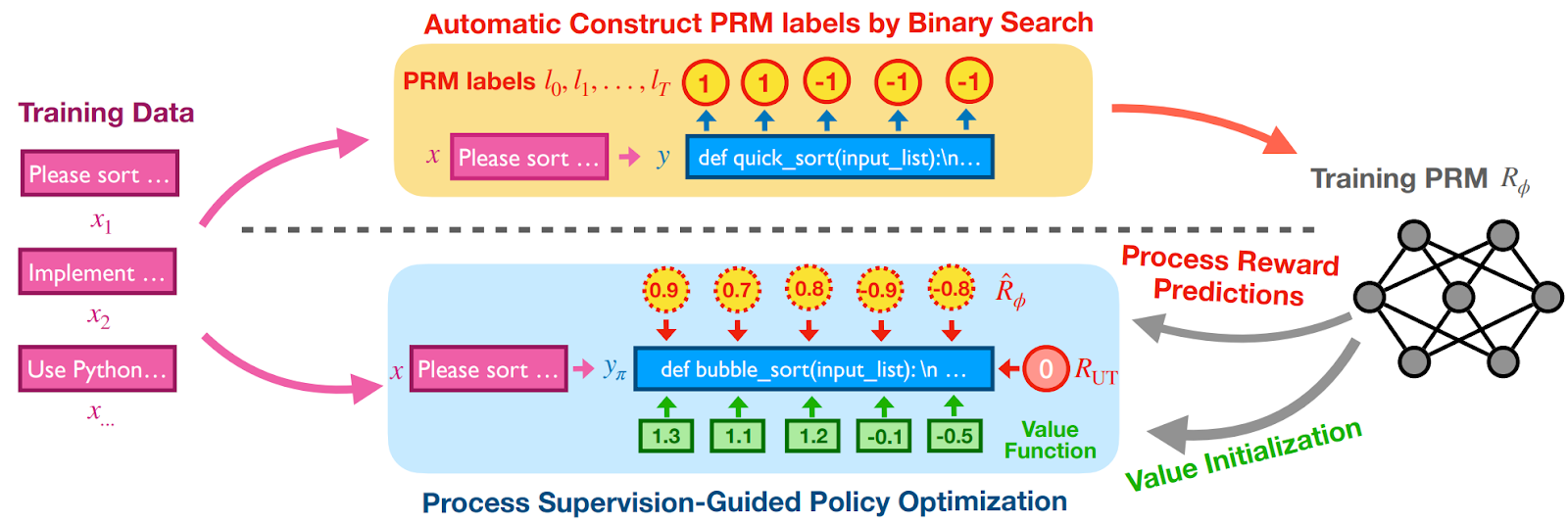
Experimental results by Dai et al. (2024) on LiveCodeBench and InHouseBench (a proprietary benchmark by ByteDance) showed that PSGPO with PRM improves the pass@1 metric for long solutions (over 100 tokens) by 9% compared to the baseline RL approach. The combination of dense rewards and value initialization improves learning through additional feedback signals, better stability, and also provides significant advantages in tasks with long planning horizons.
Chen et al. (2023) apply an approach called imitation learning from language feedback (ILF; Scheurer et al., 2023) to code generation. ILF uses relatively few human annotations to train a model for both generating and refining programs, aiming for a data-efficient and user-friendly approach. Below we see the general framework on the left and a sample query with language feedback on the right:

The task of program synthesis is formalized as training a probabilistic model πθ, parameterized by θ, to generate a program x from a task description t. The generation probability is defined as
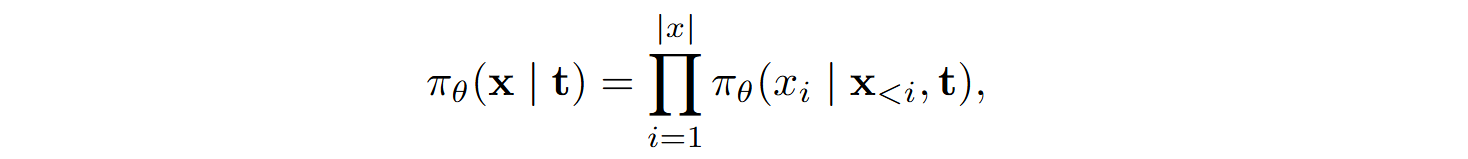
where x<i is the prefix of length i-1.
The ILF objective is to minimize the Kullback-Leibler divergence between the current model πθ and the target distribution πt*:
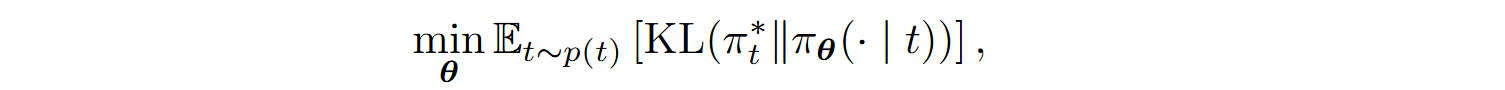
where πt*(x) is proportional to exp(βR(x, t)), and R(x, t) is the reward function based on passing unit tests.
The ILF algorithm proceeds in several steps:
The proposed distribution qt(x1) that approximates πt* is formalized as

where pF(f | t, x0) is the feedback distribution, and δ is the delta function that defines the constraint of passing the tests.
Chen et al. (2023) tested ILF on the MBPP benchmark, where it achieved a significant improvement in the pass@1 metric: +10% in absolute terms and +38% in relative terms compared to baseline approaches. Analysis revealed that the quality of human feedback is critical, while automatically generated feedback is much less effective. The authors conclude that ILF is an effective approach for training program generation models, achieving significant improvements with limited manual annotations.
To sum up, there can be many different RL-based approaches and modifications that help LLMs learn to code, but in any case the point is usually to define special rewards based on how well the model passes tests. This is the key characteristic feature of the coding domain—tests that provide automatic, easy to get feedback—and this feature can also help us with supervised instruction tuning, which we will discuss in the next section.
We have discussed instruction tuning in the same post on LLM fine-tuning; it is one of the main techniques for fine-tuning LLMs where the model is trained on a dataset where tasks are represented as natural language instructions with correct answers also provided as text. The purpose of instruction tuning is to improve the model’s generalization abilities for a wide range of problems that can be posed as text rewriting; naturally, code generation, bugfixing, and other code-related tasks also fall into this category. Instruction tuning is a special case of supervised fine-tuning (SFT), and it is, of course, already a huge field with thousands of works (Zhang et al., 2024).
One of the key works in this domain is the OpenAI study on InstructGPT (Ouyang et al., 2022), which was also foundational for RLHF, and we already discussed it in detail before. The fine-tuning procedure in InstructGPT combined instruction tuning and RLHF in three stages:
Reward modeling is needed to scale the training data because human labeling is, naturally, far more expensive than reward modeling and RL.
Before proceeding to code-related works, we note the Self-Instruct approach (Wang et al., 2023) that significantly improved instruction tuning in general. We also discussed it in a previous post, so let me just remind that it is a semi-automatic iterative process as illustrated below:
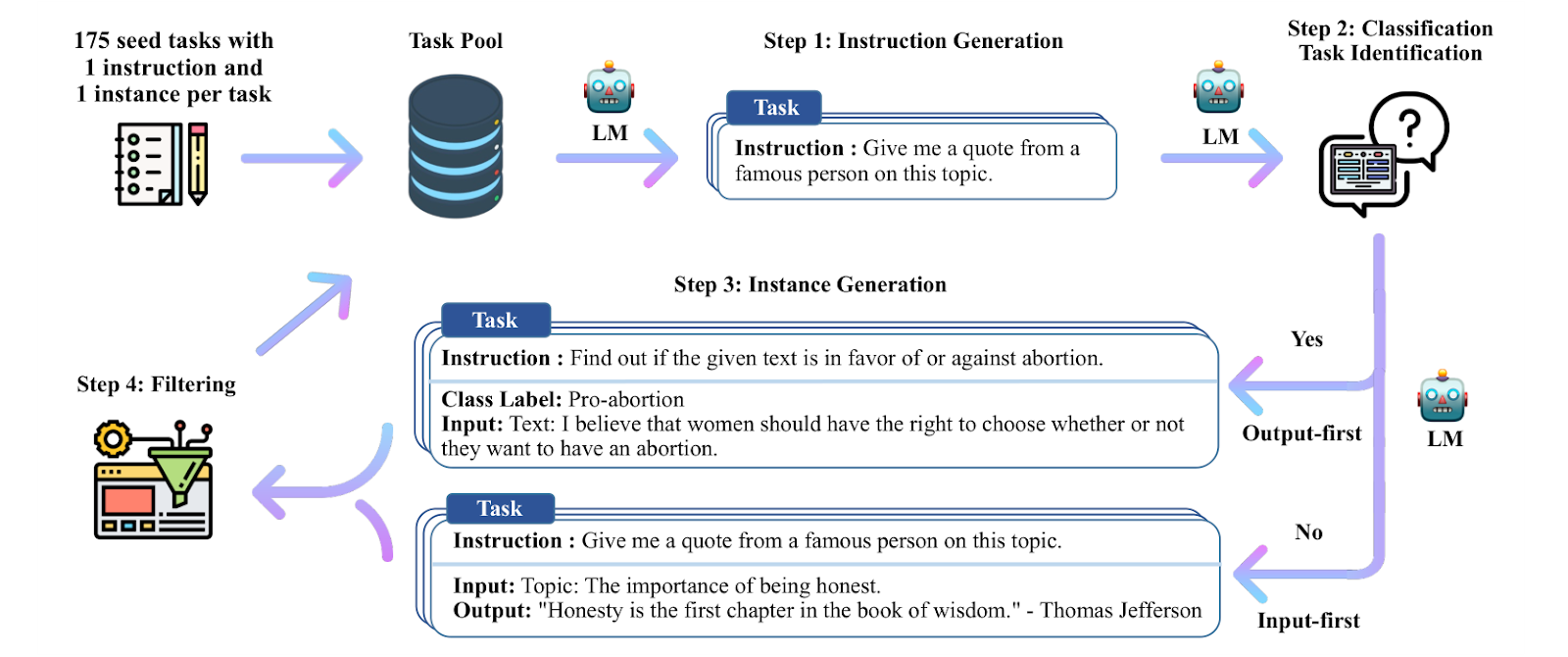
A small set of manually written instructions is used to initiate the generation of new tasks using few-shot learning, the model (GPT-3 in the original work, Wang et al., 2023) generates, filters, and utilizes these data for fine-tuning, and generated data are filtered with various heuristics, particularly using the ROUGE-L textual similarity metric with the existing instruction set, to ensure the dataset’s diversity. In Wang et al. (2023) obtained about 52K diverse instructions corresponding to about 82K input-output examples. While the dataset is relatively large, it is much smaller than the amounts of data required for training large language models. Nevertheless, fine-tuning the base GPT-3 model on these instructions increased accuracy by 33% on the Super-NaturalInstructions test set, approaching the performance of OpenAI’s InstructGPT that used extensive human labeling.
Below, we will explore how such methods are applied to the domain of programmatic code. But first, let me note that the Self-Instruct approach has been directly applied to the programming domain, resulting in an important coding model called CodeAlpaca.
One important work that further develops Self-Instruct is WizardCoder (Luo et al., 2023), which demonstrates how enhancing training data with more complex instructions enables an open model to outperform commercial solutions, in this case Claude and Google‘s LLM which was still called Bard at the time. Naturally, such comparisons are only valid as of the publication date, as closed commercial solutions are continually updated, and their performance improves even without new version numbers or names.
WizardCoder uses an approach called Evol-Instruct (Xu et al., 2023), adapting it for programming tasks. This approach incrementally generates more complex and detailed instructions for working with code using models from the ChatGPT family with various prompts. Code Evol-Instruct includes the following steps.
In WizardCoder experiments (Luo et al., 2023), performance gains stabilized after three rounds of data evolution.
Notably, the instructions are also modified by language models using simple, straightforward prompts. For example, WizardCoder used the following prompt to increase task complexity:
Please increase the difficulty of the given programming test question a bit.
You can increase the difficulty using, but not limited to, the following methods:
{method}
{question}Here, question represents the current instruction to be made more complex, and method describes the method of increasing complexity. Below are the prompts for modifying instructions.
Add new constraints and requirements to the original problem, adding approximately 10 additional words.
Replace a commonly used requirement in the programming task with a less common and more specific one.
If the original problem can be solved with only a few logical steps, please add more reasoning steps.
Provide a piece of erroneous code as a reference to increase misdirection.
Propose higher time or space complexity requirements, but please refrain from doing so frequently.In general, WizardCoder was a great illustration for the “bitter lesson” of LLMs: although we will get to prompting techniques later, it is often enough to just ask the LLM politely to do what you need. This is increasingly true with modern LLMs, and many approaches to prompting become obsolete quite fast, not because they stop working but because they cease to be necessary as straightforward prompts begin to work just as well.
OctoPack. The OctoPack approach (Muenninghoff et al., 2024) demonstrated that synthetic data for instruction tuning could be successfully generated even without using closed commercial models. Specifically, the authors created the CommitPackFt dataset using publicly available commits on GitHub. Changes in code (before and after the commit) and commit messages served as human-written instructions. Here is an example of extracting such instructions:
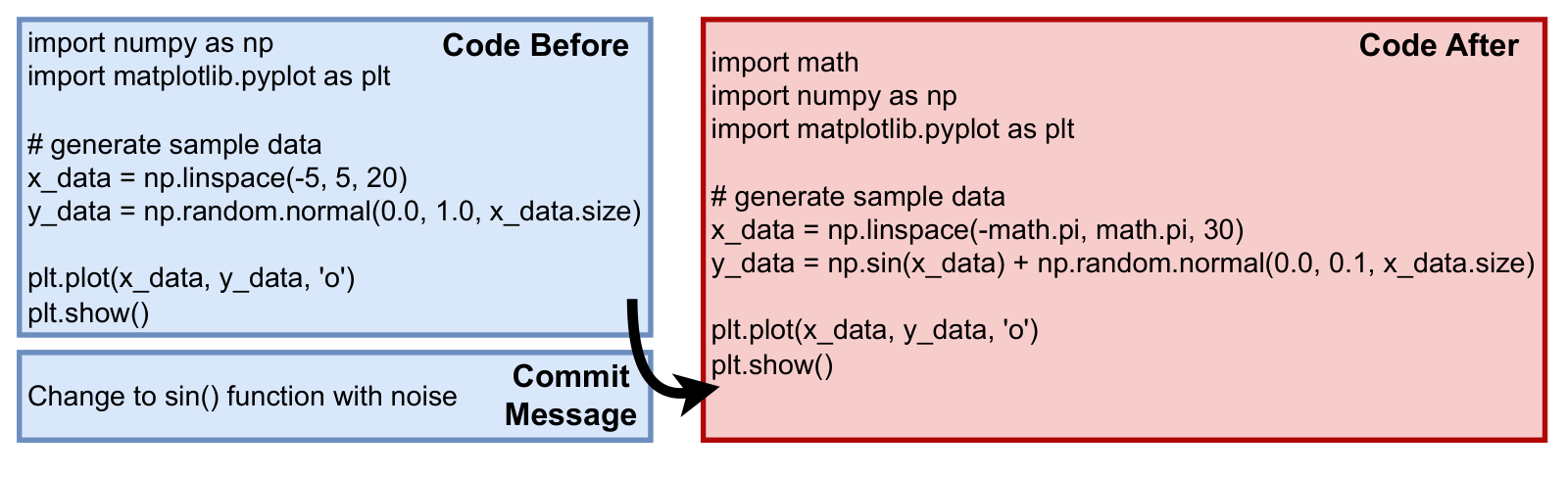
To ensure data quality, only commits with open licenses and clear imperative-style commit messages were included, and the authors also used only commits that touched only one source file. After filtering, the final dataset covered 277 programming languages.
Fine-tuning the StarCoder-16B model on this dataset achieved a HumanEval pass@1 score of 46.2% for the Python language, the highest at the time among models not trained on synthetic OpenAI data. For fine-tuning, the StarCoder model used low-rank adapters (LoRA) that we talked about in a previous post.
Despite all of the above-mentioned advancements achieved by following single-step user instructions, it might take code generation models to new heights if they could become able to process multi-step external feedback. Such feedback can take two forms:
Compiler feedback is obviously crucial in order to allow models to correct syntactic and logical errors in code, while human feedback helps models better understand user instructions, leading to solutions that align more closely with user expectations. Here is an example of such interaction:

The authors of OpenCodeInterpreter (Zheng et al., 2024) proposed a solution to this problem by preparing a dataset with compiler and human feedback. The most interesting part here is the data collection process that involves the following steps.
Here Magicoder and ShareGPT are synthetic datasets of instructions obtained using methods similar to those discussed above. For transforming into dialogues, the authors chose ten categories of queries, including formatting, bug fixing, addressing vulnerabilities, compatibility issues, etc. They also created synthetic instructions for code correction by deliberately introducing errors into responses using GPT-4, executing the programs with errors, and feeding the results back to the model for subsequent corrections. They also used tasks and posts from LeetCode forums that include problems of varying complexity, solutions, and related discussions.
Here are some experimental results about OpenCodeInterpreter shared by Zheng et al. (2024):
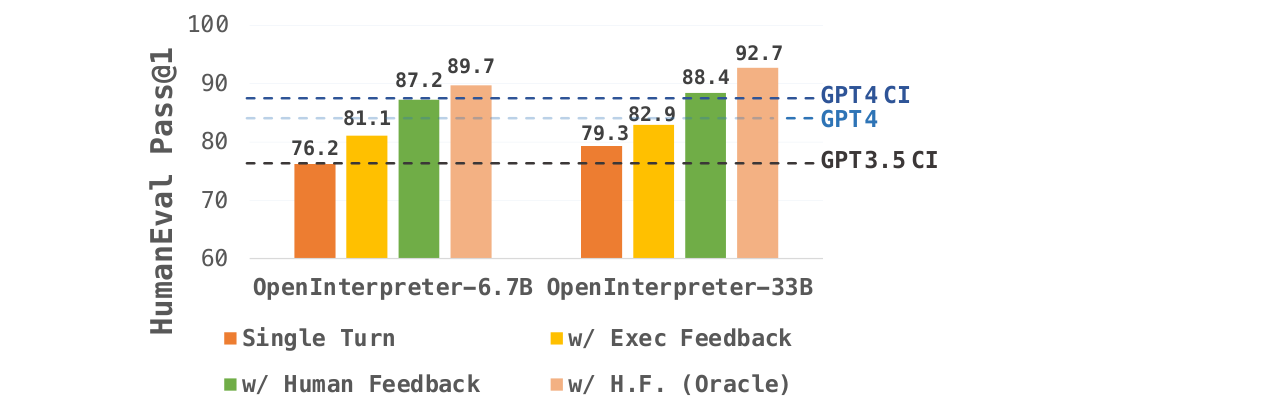
This work is significant in part because it bridges the gap between open-source models and leading commercial models, even models such as GPT-4 with the Code Interpreter feature.
In general, instruction tuning is mostly as good as the data you collect. These and other works show how even with mostly synthetic data produced by other LLMs one can uplift smaller and faster models to the next level, and perhaps even exceed state of the art. The next class of methods is even easier to implement in practice—it doesn’t require fine-tuning or touching the model at all.
I have collected the rest of the main approaches in this section, exemplified by one or two specific approaches. Let us begin with prompting.
Prompting is a method where large language models are controlled not with fine-tuning but by simply changing the prompt itself in smart ways. It often turns out that the LLM’s pre-existing knowledge is quite sufficient for many tasks even if the LLM does not show it at first, and instead of retraining a model with additional data, one could simply modify the text input (prompt) to provide instructions, examples, or context in a form that brings this knowledge forward and leads to the desired response. Below, we discuss examples of various methods for gathering context and designing prompts for code-related tasks; naturally, these are only a few samples from a large field.
The first interesting approach I want to mention is the Repo-Level Prompt Generator (RLPG; Shrivastava et al., 2023), which improved the performance of OpenAI Codex (a closed model) for code completion without any fine-tuning or retraining. The method generates possible context snippets based on the structure of the code and repository and then uses a classifier to filter out irrelevant context for a given code completion position (a “hole”).
The authors identified ten categories of context sources, including the imported file, current file, enclosing class, neighboring files, and others. Seven types of context are extracted from each source: class field declarations, method signatures, method signatures with bodies, string constants, and so on. Combining the sources and context types results in 63 predefined types of context snippets that RLPG can include in the model prompt; the context synthesis process is illustrated below (Shrivastava et al., 2023):
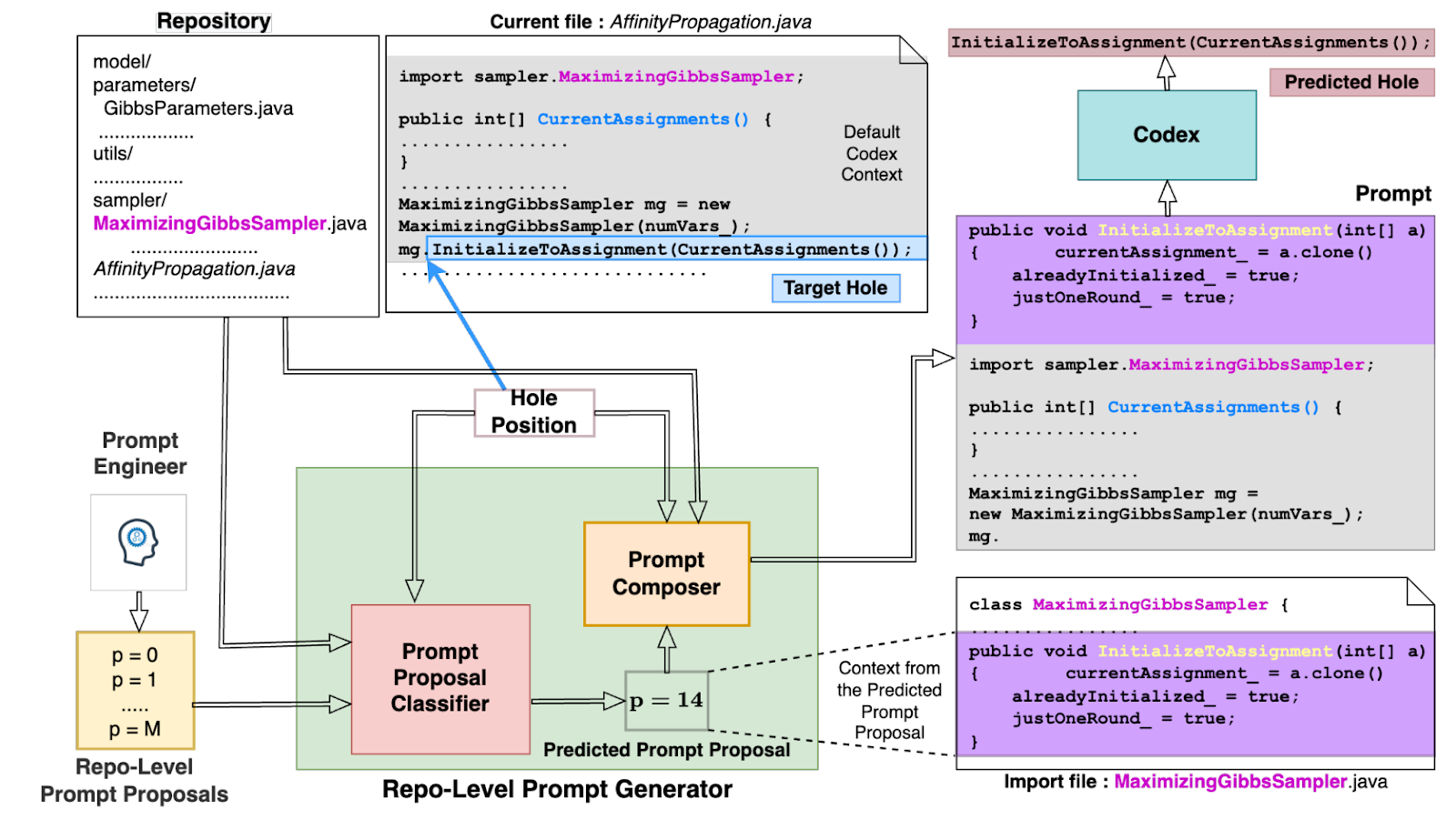
For training the classifier, Shrivastava et al. (2023) collected data from 19 repositories with open licenses from the Google Code Archive, presumed not to overlap with the Codex training set (which used only GitHub projects). After removing blank lines and comments, “holes” for code completion were created in the middle of the remaining lines, for a total of a bit under 93K and capped at 10K per repository. Prompts were generated based on different context sources and types, and they were evaluated via Codex: if the resulting completion matched the original line, the example was labeled as 1, otherwise 0. Approximately 150K queries were made to Codex to gather training data—a large but definitely not prohibitive number.
The classifier was trained with the loss function
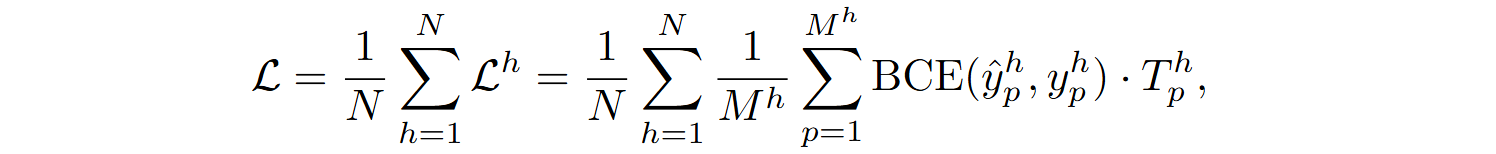
where Mh=ΣpMTph denotes the total number of context types applicable to the current “hole”, N is the total number of holes in the dataset, and BCE is the binary cross-entropy.
Two variations of the model were tested:
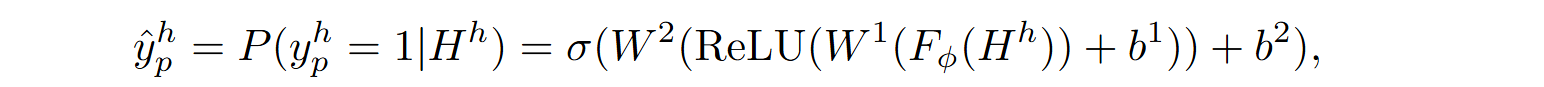
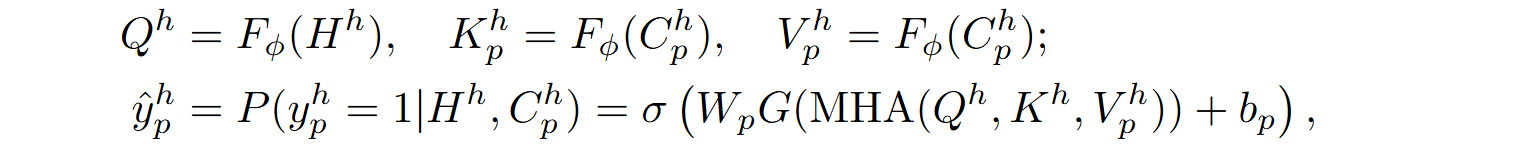
The second version performed better on test data, and ultimately RLPG improved Codex‘s performance by 17%. RLPG is a characteristic illustration of methods that can improve a model without ever even seeing its internal structure or weights, just by changing the context. But there is more interesting stuff to put into that context.
Another approach to improving model quality without fine-tuning is using runtime information from program compilation or execution as feedback. As we have discussed in the section on instruction tuning, such information can help large language models solve complex code generation tasks through iterative interaction with tools.
As an example of this approach, in this section let us consider the Large Language Model Debugger (LDB; Zhong et al., 2024), an advanced method for collecting runtime information that tries to debug programs synthesized by LLMs in the same way as humans debug their own programs. Here is a detailed illustration that we will go through below:
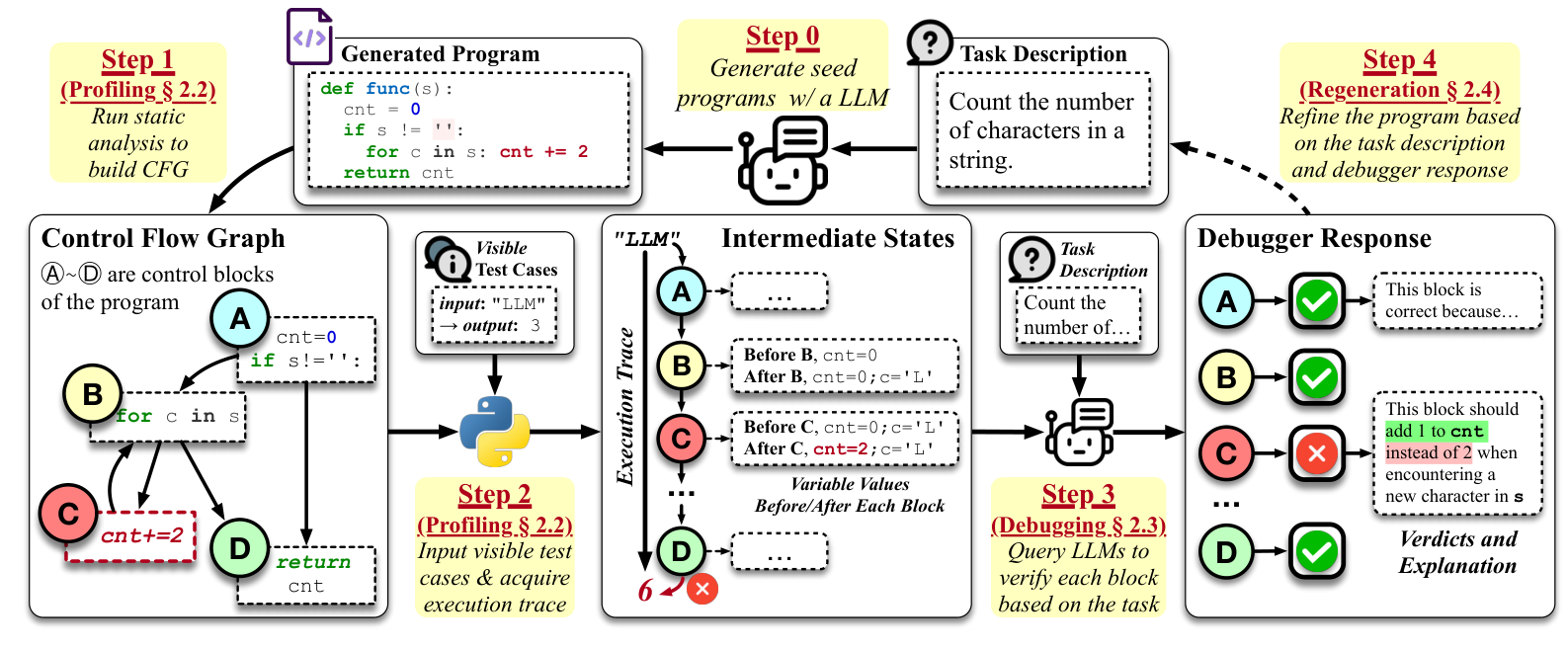
Key steps in the debugging process are as follows.
A significant limitation of this approach is the fact that it has to rely on tests to identify where the code goes wrong. Still, LDB significantly improves the performance of open models, achieving a nearly 10% improvement on benchmarks such as HumanEval, MBPP, and TransCoder (Zhong et al., 2024). Again, I remind that specific numbers are not important for us, what matters is that this approach does improve code generation significantly.
Retrieval-Augmented Generation. We have discussed RAG (retrieval-augmented generation) in detail in a previous post; in code-related tasks, this method is usually employed to gather context for code generation prompts by retrieving relevant information from external sources such as codebases, library documentation, or web search results and appending it to the user query to improve model responses. RAG represents another way to add new knowledge to the model without fine-tuning, and I refer to my post on RAG and the corresponding sources for details (Gao et al., 2023; Zhao et al., 2024; Fan et al., 2024; Li et al., 2022).
A straightforward example of applying RAG to code generation is DocPrompting (Zhou et al., 2023), which enhances Python and Bash code generation by incorporating relevant documentation into the prompt. The DocPrompting workflow is illustrated below with a Python example:
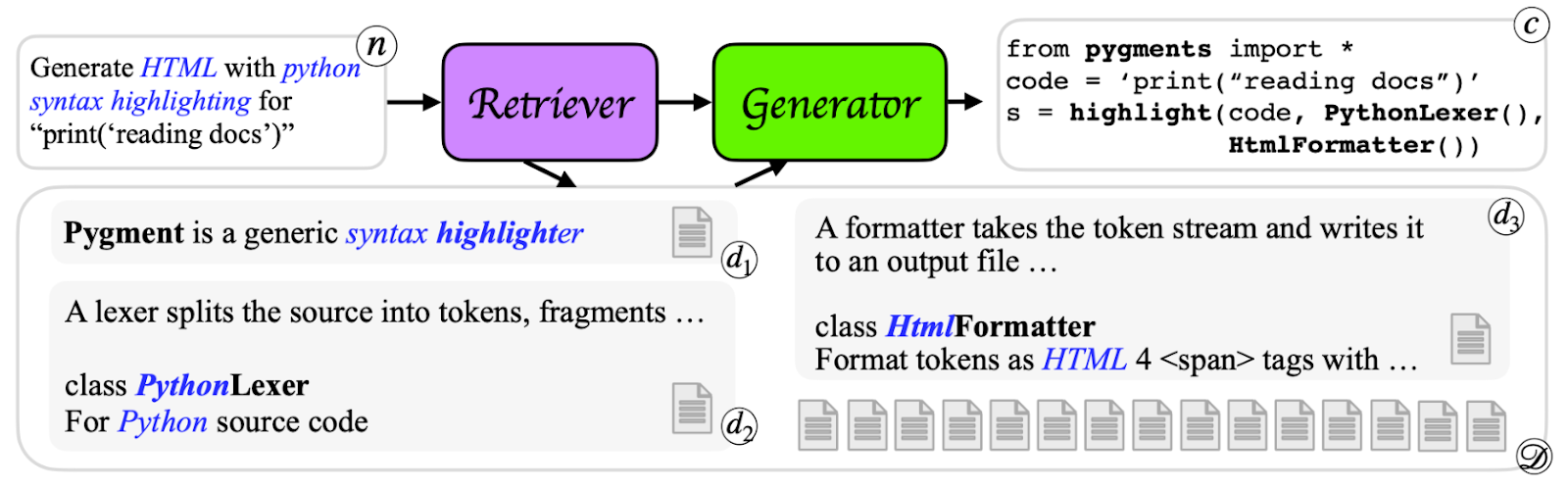
For a given natural language query q it first retrieves a set of relevant documents {d1, d2, d3} from a documentation corpus D and then uses the retrieved documents and query q as input to the LLM to generate code c. Even this simple approach allows an LLM to generalize to previously unseen usage scenarios by “reading” the retrieved documentation. In the figure above, blue text shows tokens shared between the query and documentation, and bold text highlights tokens shared between the documentation and generated code.
For document retrieval, one can use classical methods like BM25 (Robertson, Zaragoza, 2009)—they prove surprisingly resilient in modern information retrieval, and BM25 often shows up as a reasonable baseline in comparisons—or vector-based search with autoencoders such as RoBERTa (Liu et al., 2019). Autoencoders can be trained with the contrastive loss
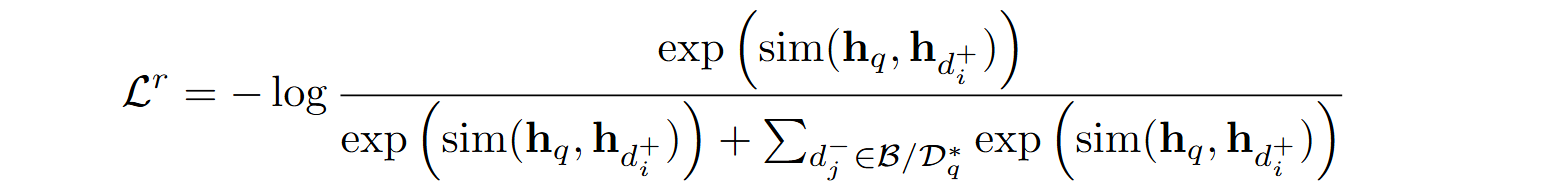
Where sim(hx, hy) is the cosine distance between vectors hx and hy, q is the query with latent representation hq, and di+ and di– are vector representations of relevant and irrelevant documents respectively.
As a result, this simple approach significantly improved the quality of bash commands generation by Codex on the tldr benchmark (Zhou et al., 2022). Similar RAG techniques have successfully been used on internal library documentation (Zan et al., 2022) and samples of similar code (Parvez et al., 2021), again leading to significant improvements.
This approach, exemplified here by a method called Learning to Verify Language-to-Code Generation with Execution (LEVER; Ni et al., 2023), builds on the observation that LLMs often generate hallucinations or errors when producing code, but generating a sufficiently large number of candidate responses significantly increases the likelihood of finding a correct one. We have already discussed this above: the whole idea of the pass@k metric is choosing one of k generations, and the results do improve significantly as k grows; this is a staple in code generation evaluation research (Chen et al., 2021; Du et al., 2024; Austin et al., 2021). This leads to the following idea: let us train a separate verifier model capable of distinguishing correct programs from incorrect ones, then sample many responses from the LLM and pass them through the verifier. The underlying assumption is that verifying a response is an easier task than generating one from scratch.
For other applications, such as solving textual math problems, this approach was proposed by, e.g., Cobbe et al. (2021) and Shen et al. (2021) and further developed by Kadavath et al. (2022), Li et al. (2023), Hosseini et al. (2024), and others. In code generation, verification is usually even easier than for mathematical proofs: many errors can be caught during compilation, execution, or running simple test cases.
Thus, sampling and verification is a natural way to enhance results with minimal computational overhead. The LEVER method (Ni et al., 2023) is a straightforward illustration of this approach, so let me use it to describe some more details. LEVER operates as follows.
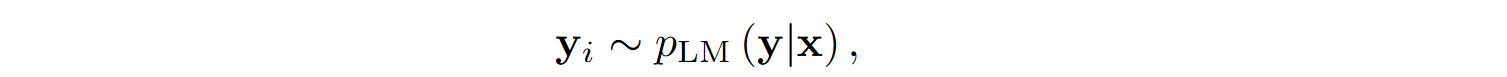
Here is an illustration for this sequence of steps (Ni et al., 2023):
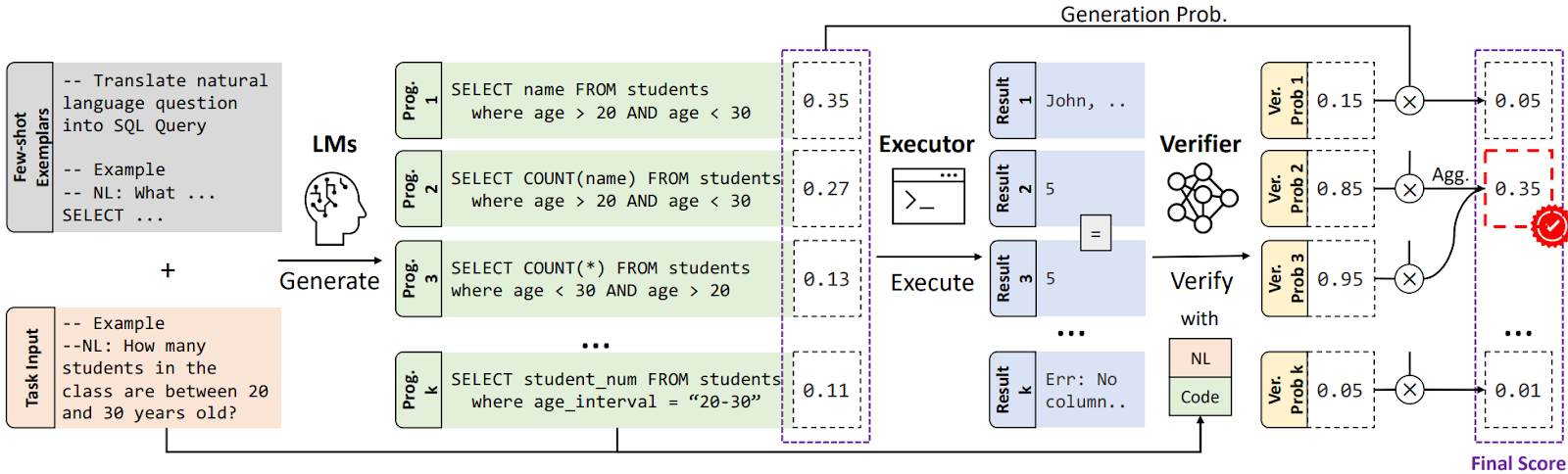
When applying the method, programs are ranked based on a composite score derived from generation and verification probabilities. The verifier calculates the composite probability of correctness:
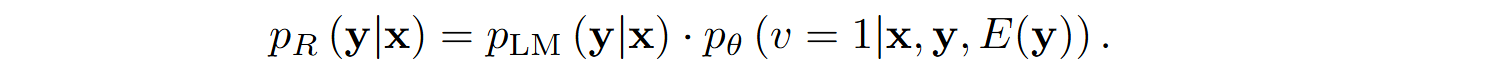
In order to mitigate inconsequential factors such as variable names or program appearance, programs with identical execution results $E(\y)$ are aggregated:
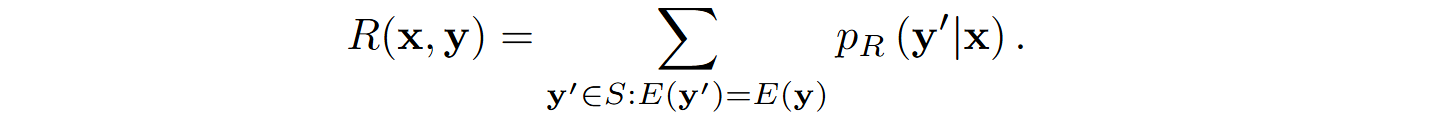
The program with the highest result $R(\x, \y)$ is chosen as the output:
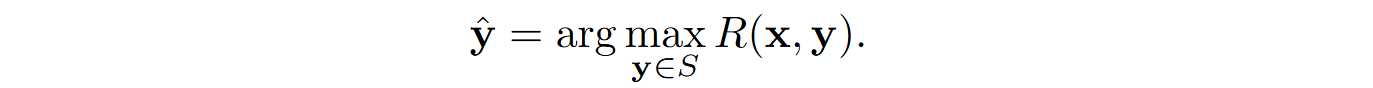
The verifier is trained on automatically annotated data. Each candidate program y receives a label v determined by comparing its execution result E(y) with the reference E*: v=1 if E(y) = E* and 0 otherwise.
The verifier’s loss function is defined as
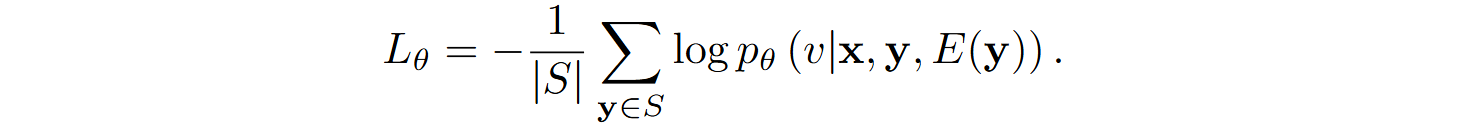
By using execution results for dense feedback, LEVER improves verification accuracy and works effectively even with limited data. The authors show that LEVER improves code generation performance on tasks such as SQL parsing, solving mathematical problems, and Python programming (Ni et al., 2023).
LEVER is not the only method utilizing sampling of multiple programs followed by verification. DeepMind’s AlphaCode system, which achieved human-level performance on the CodeForces platform in 2022 (Li et al., 2022), operates in a similar manner, albeit with significantly greater computational scaling. A sample further development of this idea has been presented by Li et al. (2024), where sampling from LLMs is done through a specially constructed query enumeration strategy. Overall, this direction for improving results is often virtually free, especially if a simple verifier in the form of unit tests already exists, and should work in many practical scenarios. In simple terms, it usually does not make sense to ask an LLM for just one code snippet — ask for three or five instead and choose the best one, it may be better not only in terms of passing tests but also in terms of code quality and coherence (which would not be noticeable in execution-based comparisons).
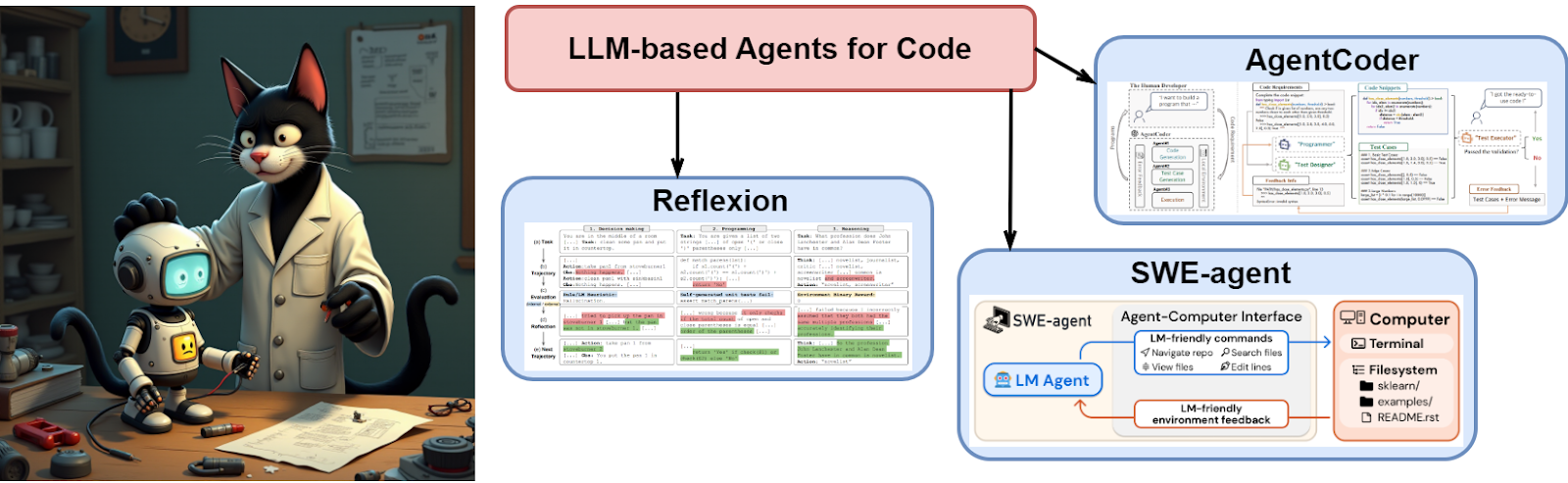
These days, agents are often hailed as the next turn in the LLM evolution spiral: it turns out that modern large language models can act as agents in various environments, interacting with them via text commands. Agent-based methods are rapidly evolving in many different applications, and I will not go into a full-scale survey of them here, but let me list a few examples:
In the programming domain, agent-based methods allow LLMs to plan, debug, and adapt iteratively. In this section, let us consider three characteristic examples of agent-based approaches; while they are recent papers, they are already prominent and have collected a lot of references.
Shihn et al. (2023) introduced an approach for training LLM-based agents using self-analysis and verbal feedback rather than parameter updates. Instead of traditional weight updates via gradient descent, Reflexion enhances the agent through textual self-reflections that can be stored in memory.
The method uses three key modules:
Here is an illustration of Reflexion training:

Each training step in the figure above consists of:
Importantly, Reflexion incorporates a two-tiered memory system:
The self-reflection model integrates this memory to guide future actions, enabling the agent to learn from past mistakes.
Thus, in programming tasks, Reflexion trains itself through generated tests and self-analysis: first, the actor Ma generates code, which is then evaluated based on the results of both compilation and test execution and by the evaluator model Me. Then, the self-reflection model Msr generates a verbal text reflection describing the changes needed to fix the code. The code is then corrected based on this reflection, and the cycle repeats. This iterative approach yields significant improvements: for example, on the HumanEval benchmark Reflexion increased the pass@1 accuracy by 11%, reaching 91% and surpassing GPT-4 with a weaker base model. Improvements are even more substantial on other benchmarks: solution success rates in AlfWorld (Shridhar et al., 2021) increased by 22%, while reasoning tasks from HotpotQA (Yang et al., 2018) improved by 20%.
The agent-based approach with textual reflection has several other important advantages:
Thus, Reflexion opens a promising avenue that combines the power of LLMs with verbal, self-analytical learning; again, I do not claim that Reflection itself is the best possible way to make agents but this is an interesting idea to be explored further. Note that such methods can be applied to any LLM and will improve as the base model improves.
This framework (Huang et al., 2024) is a good example of how any LLM can be turned into an agent with a little bit of scaffolding. Moreover, in the case of coding the scaffolding suggests itself since, as we have already discussed, development is often driven by tests. So the AgentCoder framework consists of three agents:
The interaction between these three agents is very straightforward, as shown below (Huang et al., 2024):
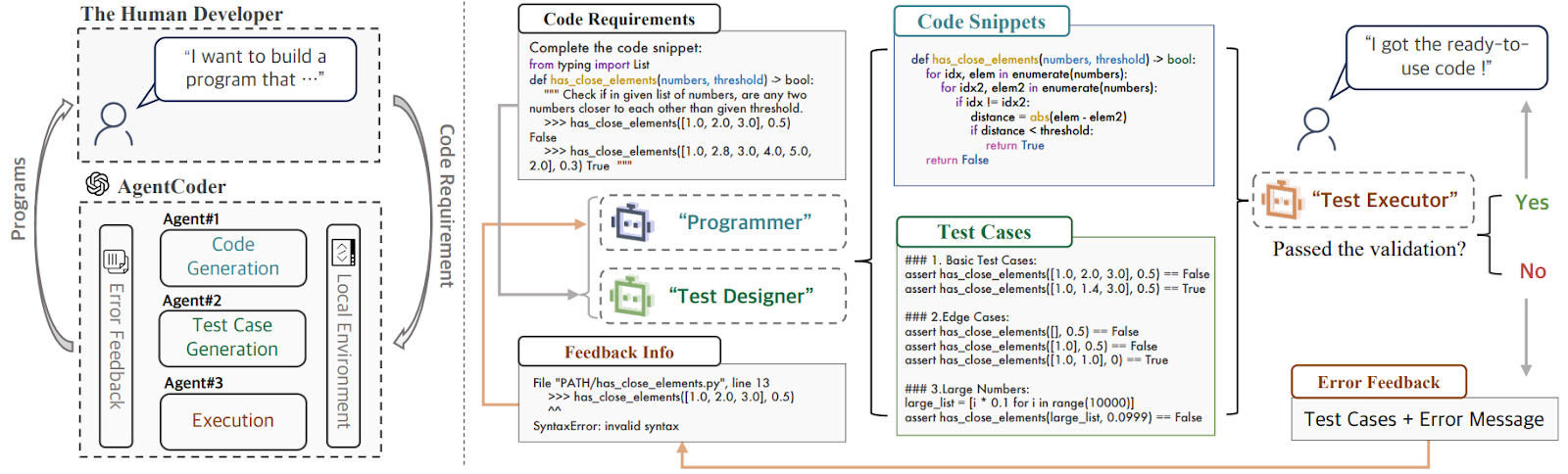
AgentCoder uses chain-of-thought techniques for the programmer, manually crafted prompts for the test designer intended to cover both edge cases and large-scale inputs, and the test executor is not even an LLM, it is a Python script that provides direct execution feedback to the other two agents.
Despite this apparent simplicity, AgentCoder significantly improves the results across all tested datasets. For example, on HumanEval the basic GPT-4 model with zero-shot prompting scores about 67.6% in the pass@1 metric, the above-mentioned Reflexion approach achieves 91.0% with the GPT-4 base model, and AgentCoder reaches 96.3% with the same GPT-4 as the base LLM (Huang et al., 2024). This is an important testament to what LLM-based agents can achieve even with a very direct and straightforward method, if executed well.
As an example of further development of the agent-based approach, let us consider the recently developed SWE-agent system (Yang et al., 2024), designed to automate software engineering (SWE) tasks using LLMs as agents. The core idea lies in creating a specialized interaction interface between the agent and the computer, creatively called the Agent-Computer Interface (ACI), which makes it easier for the LLM agent to solve tasks related to writing, modifying, and testing code.
The LLM functions as an agent, interacting with the computer environment through actions such as editing files or running tests and receiving feedback from the environment. Unlike traditional human-oriented interfaces (e.g., terminals or IDEs), ACI employs:
This design overcomes the limitations of standard interfaces, which can be overly complex for LLM-based models; here is an illustration by Yang et al. (2024):

SWE-agent itself incorporates the following key components (also illustrated above).
On each step, the agent alternates between generating “thoughts” (reasoning about the next step) and executing specific commands. Here is a sample workflow of the agent (Yang et al., 2024):
SWE-agent showed significant improvements, achieving state of the art at the time and sometimes coming out ahead in big leaps. On the SWE-bench dataset it solved 12.47% of the problems, while the best non-interactive model at the time achieved only 3.8%. On HumanEvalFix, SWE-agent achieved the pass@1 metric of 87.7%, which was also a big step forward. And again, the numbers themselves do not matter much and have been overcome since then, what matters is that SWE-agent led to significant improvements compared to its own base model at little inference cost and with no retraining.
In summary, LLM-based agents represent a significant step forward in automating software engineering tasks. They can iteratively improve through structured interaction with the programming environment and can tackle complex, real-world challenges. In this section, we have considered two examples: Reflection shows a simple way to add verbal memory to an LLM agent, while SWE-agent shows that it makes sense to adapt the programming interfaces, currently designed for humans, to let LLMs use them more efficiently.
In this section, we examine the fine-tuning process for two popular industrial code models with open weights. As we have seen throughout this post, fine-tuning aims to transform a base model into a practical assistant for programmers. Similar to the foundational work on InstructGPT, this process is typically divided into two primary stages: instruction tuning and aligning the model’s goals with human preferences (AI alignment), usually through reinforcement learning methods.
In this section, we review the fine-tuning process using two models as examples: Qwen2.5-Coder (Hui et al., 2024) and DeepSeek-Coder-V2 (Zhu et al., 2024). Their comparative results on the LiveCodeBench benchmark are shown in the tables above, so at the time of writing, these models ranked among the top performers alongside commercial solutions from OpenAI (GPT family) and Anthropic (Claude family).
Naturally, by the time you read this the situation has probably changed already — as I have said many times, it is impossible to keep up with AI progress these days if you are writing a book or even a series of long-form posts. But still, in any case, it is a great and potentially relevant illustration. Although the source code and training data are often not available to the research community, existing information about the fine-tuning process for these models is still interesting to consider and can be useful as a guide for your own fine-tuning process or for further specialization of these models to specific practical tasks.
The instruction tuning stage for the Qwen2.5-Coder (Hui et al., 2024) model consisted of the following steps.
The alignment stage used the direct preference optimization (DPO) method (Rafailov et al., 2023), where the model’s behavior is adjusted based on feedback from test executions and quality assessments made by other language models:

This approach is also known as LLM-as-a-judge (Zheng et al., 2023) and is increasingly used in practice to supplement or altogether avoid human feedback. The overall process improves code generation quality and aligns the model with user expectations.
Data preparation for fine-tuning is another hugely important part of the pipeline that often gets overlooked when we talk about machine learning ideas. Since this is an “industrial” section, let us discuss data preparation as well; for Qwen2.5-Coder, it involved a rigorous process of data collection, cleaning, and analysis to create a high-quality set of instructions.
First, the initial data was sourced from open GitHub repositories and existing instruction datasets for code such as McEval-Instruct. The developers trained a specialized classifier based on the CodeBERT model (Feng et al., 2020) to identify the programming language or absence of code, and included top 100 programming languages in the dataset.
Second, to further expand and improve the dataset, synthetic instructions were generated using large language models. These instructions were derived from GitHub code snippets and filtered for quality using, again, LLMs; as far as I can tell, there was no human labeling involved beyond perhaps few-shot examples in the LLM prompts.
Third, a multi-agent system was developed to generate new instructions in various programming languages. Agents were assigned language specializations and could exchange knowledge to improve the dataset. External memory was provided to agents to prevent information duplication. This approach promoted the reuse of programming concepts and knowledge across languages.
Finally, we come to data evaluation: the authors developed a checklist to evaluate the final dataset based on criteria such as relevance, complexity, presence of comments, educational value, and other factors. Whenever possible, the data was validated using isolated environments for code execution, including syntax checks, automatic unit test creation, and test execution.
Overall, these steps have been able to ensure a high-quality, multilingual instruction dataset. This is a great example where we can at least partially lift the veil on the data preparation process, which is always hidden for closed source commercial LLMs. I am sure that OpenAI, Anthropic, and Google have a much more involved process for collecting, preparing, and evaluating their internal datasets, and that this is a key step in pushing the state of the art in any AI direction, including coding.
On the instruction tuning stage, DeepSeek-Coder-V2 (DeepSeek-AI et al., 2024a) used a dataset that includes programming and mathematical tasks. The authors selected 20000 programming instructions and 30000 mathematical instructions from DeepSeek-Coder (Guo et al., 2024) and DeepSeek-Math (Shao et al., 2024), respectively. To retain the model’s general capabilities, they also used additional data from DeepSeek-V2 (DeepSeek-AI et al., 2024b), and the final dataset consisted of 300 million tokens.
For the alignment stage, DeepSeek-Coder-V2 used the Group Relative Policy Optimization (GRPO) method (Shao et al., 2024), a memory-efficient modification of PPO. This phase also included programming tasks with unit tests with unit tests specially written for programming tasks. After filtering, the dataset contained about 40K instructions.
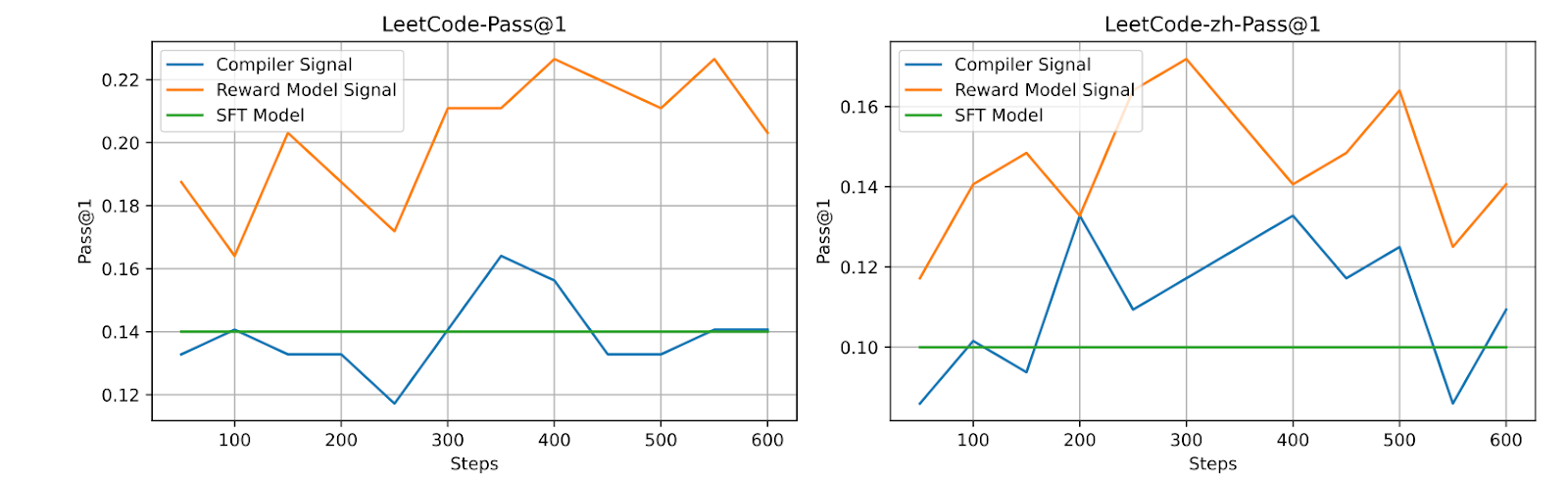
One interesting modification used here dealt with the reward function. For mathematical tasks, the reward function simply compared generated answers with the correct solution. For programming tasks, passing tests also served as a binary reward, but some instructions did not have enough tests for full coverage, making “passing tests” a noisy and suboptimal signal for training. To address this, the authors trained a reward model on test execution data and used it during RL training. This provided a less noisy signal compared to raw test results, and the authors showed how their reward model significantly outperformed direct test feedback on internal datasets (Leetcode and Leetcode-zh), as shown below:
In general, Qwen2.5-Coder (Hui et al., 2024) and DeepSeek-Coder-V2 (Zhu et al., 2024) represent the cutting edge of open weight AI models for programming tasks, and, interestingly, published details on these models, while introducing some new ideas, align closely with the core approaches we have discussed above, and it makes me hopeful that this review is actually still relevant.
The gap in both benchmark scores and actual perceived performance between these two models and closed models from OpenAI and Anthropic is minimal… oops, sorry, was minimal, and then new test results for the full-scale o1 family came out, and now the O1-2024-12-17 (N=1) model tentatively sits in the first row of the table above with 72.4% average pass@1 metric for code generation, compared to 67.2% and 52.5% scored by the first and second row in the table respectively.
The o1 family is a very different can of worms that I don’t want to open here (see, e.g., my earlier post on o1-preview), but in any case, by the time you read this, even better results have probably been published; e.g., the recently announced o3 family does not have a LiveCodeBench entry yet. So let me conclude the chapter with some projections for the future.
All around us, we see examples of how LLMs and especially LLM-based agents navigate and manipulate large codebases, efficiently debug and test programs, and adapt iteratively based on feedback, mimicking human-like development workflows. We have discussed a lot of research papers and even some practical open models, but, of course, the actual frontier is being pushed by the closed models developed in OpenAI, Anthropic, and Google.
One of the most important recent developments has been the o1 family of models; recently, o1 Pro has been made available. Here is the system card, although later it has turned out that the system card is mostly not about the actual model being deployed; see a detailed post by Zvi Mowshowitz about this controversy. O1 Pro is much more expensive than the usual offerings ($200 per month compared to $20 for the standard OpenAI subscription) but it appears that it is accordingly more powerful.
I really hope to talk about the o1 (and maybe o3) family of models in a future post. So far all we have about it are speculations, but there have already been several relatively successful replication attempts, so speculations do matter. At this point, let me just point out that programming is another big strength of o1-pro. Many people have commented on how much better it is for handling large codebases and writing a lot of code from scratch with no mistakes; here is one such response with a video that shows how o1 has helped refactor a large codebase with extensive documentation that needed to be taken into account, and here is a report where the only downside is that o1-pro still won’t challenge the basic assumptions of your project, even if it would be helpful.
Dissenting views mostly agree that o1-pro is excellent but say that, e.g., the latest Claude Sonnet 3.5, which still costs $20, is not noticeably worse and may be even better in some respects; here is one comparison. In any case, modern top LLMs already can do a lot, and coding applications are on top of that:
Moreover, remember the main underlying principle of such capability examples: this is as bad as it ever will be, the only way from here is up. Demis Hassabis, cofounder and CEO of DeepMind, said while introducing Gemini 2.0 (another top model that has excellent coding capabilities): “This is really just the beginning. 2025 will be the year of AI agents.” Indeed, in this post we have already seen how adding even a straightforward agentic scaffold can improve coding capabilities of LLMs a lot, and there will be, of course, more and better work in this direction.
So if you planned on being a coder then yes, maybe it is time to rethink this plan. Programming is already being changed and will no doubt be completely redefined by the LLM revolution. However, unless programmers are replaced entirely, it looks to be something that computer science has already experienced several times. No programmer of today can write in machine code because it has been replaced by assembly instructions. Few programmers can write in Assembler because it has been replaced by high-level languages such as C/C++. These languages have also been becoming more and more high-level: for example, only very low-level C programs work with pointers directly, and most memory management is done automatically. Maybe this will be another step up the meta ladder: instead of writing code, programmers will be writing instructions and specifications for AI models to fill with actual code.
On the other hand, I am still positive that if you want to create stuff, you do need to understand how things work. Maybe a programmer of the future will be mostly writing prompts for advanced AI tools, and the tools will write the code—but it will still help to know computer science, understand how computers operate on the basic level, and be able to dive in if necessary, even if it will be necessary less and less often.
In any case, 2025 is certain to be a very exciting year for AI. Happy New Year, everyone!
Sergey Nikolenko
Head of AI, Synthesis AI