
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
We continue our series on LLMs and various ways to make them better. We have already discussed ways to increase the context size, world models that arise in LLMs and other generative models, and LLM fine-tuning including RLHF, LoRA, and more. Today we consider another key idea that can make LLMs far more effective and useful in practice: retrieval-augmented generation, or RAG. We discuss the basic idea of RAG, its recursive agentic extensions, the R[e]ALM approach that integrates retrieval into LM training, some key problems of modern RAG approaches, discuss in detail knowledge graphs and how they are being used in RAG, and conclude with a reminder that even simple approaches can work well and a list of directions for future work.

A large language model is basically a huge token prediction machine; we have discussed this many times (one, two). In particular, it means that the LLM itself has a specific dataset that it used for pretraining and/or fine-tuning. No matter how large and how smart the LLM becomes, it will never have information not present in the dataset; for example, it will not know any events that happened after the “cutoff date”.
But there are plenty of applications where you want the LLM to process new information! For instance:
We have already discussed ways to extend the input context and alleviate the quadratic complexity of self-attention, but not everything can be put into context. Even if you can fit a whole book into a million token context like Gemini 1.5 already can (Reid et al., 2024), real world tasks such as the ones listed above require access to much more information.
One way to fix this problem would be to introduce external information search as a tool; e.g., you could say to the LLM that it is allowed to call the ‘web_search‘ procedure that takes a query as input and outputs the top 5 Google search results for this query. This is a viable approach, especially for well defined queries such as weather reports or ticket availability, and perhaps we will discuss tool use in LLMs in the future.
However, information retrieval from large corpora is so important that it is usually treated as a separate type of LLM extension, often included by default even if other tools are not available. This falls under the label of retrieval-augmented generation (RAG), introduced by Lewis et al. (2020) during the early days of Transformer-based LLMs. Patrick Lewis, by the way, has apologized in his interviews about the acronym—”We definitely would have put more thought into the name had we known our work would become so widespread”, he said (source)—although in my opinion the acronym is catchy and memorable.
Before diving into RAG, I want to highlight two surveys on the subject, by Gao et al. (2023) and Zhao et al. (2024). They are excellent reviews of RAG and already have hundreds of citations themselves despite being very recent. I have tried not to repeat these surveys, but still much of what comes next is based on them, although we will go beyond them in several directions, in particular regarding Graph-RAG. Other surveys of RAG include Li et al. (2022) and an ACL 2023 tutorial by Asai et al. (2023). With that in mind, let’s get going!
Before branching out, let us begin with an explanation of what RAG is and how it works in the simplest example. Suppose that I wanted to ask an LLM to summarize recent research on RAG to write this post. If I asked GPT-4o, it would be able to produce an excellent explanation of what RAG is (yeah, I checked) since RAG had already entered its knowledge base. But GPT-4o has no chance to know the results published in the last year because its cutoff date was August 2023:
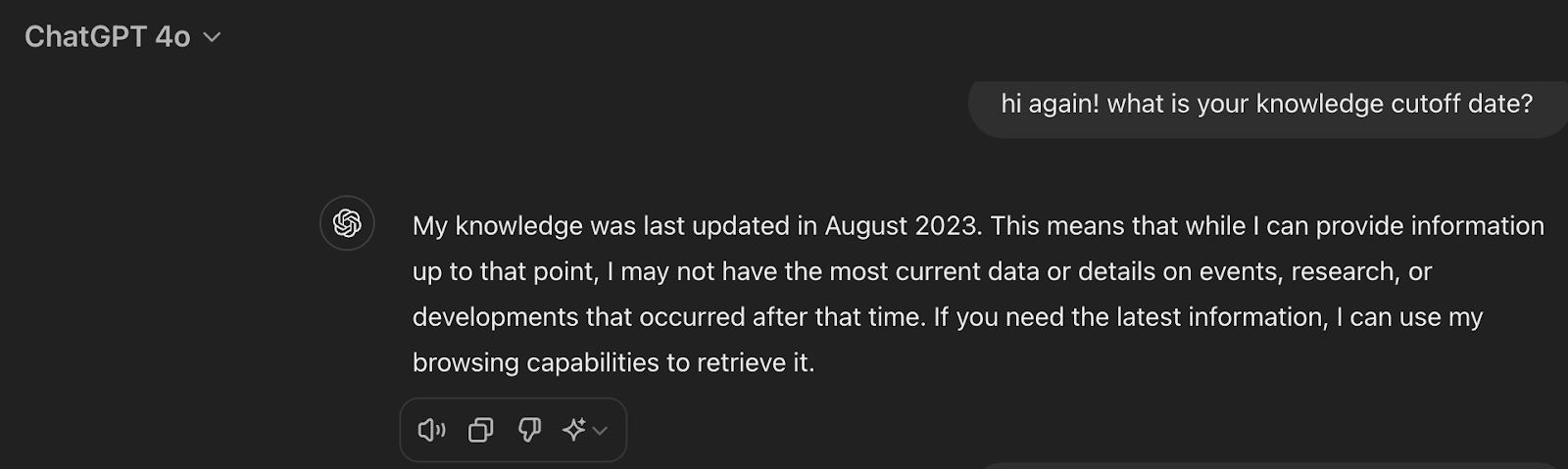
So, for instance, the two excellent surveys that I mentioned above would be beyond GPT-4o’s knowledge. Moreover, the LLM would probably not be able to give any specific links with more detailed information—its knowledge is vast but not so vast as to hold the entire training knowledge base. In fact, GPT-4o simply refuses to do that outright:

How can we remedy that? The solution is quite simple: let’s allow the LLM to retrieve information by, e.g., searching the Web. In its most direct form, “pure RAG” works like this:

The prompt gets reformulated into a query (either in some straightforward way or by using the LLM again), the query is sent to a standard information retrieval engine (Manning et al., 2008) that returns some results, and the top results (probably however many the context window allows) are appended to the query as additional information for the LLM. As a result, RAG gives the LLM the opportunity to search over an arbitrarily large corpus; the additional costs of retrieval are usually negligible compared to running the LLM.
Here is a specific example from the above-mentioned survey by Gao et al. (2023):
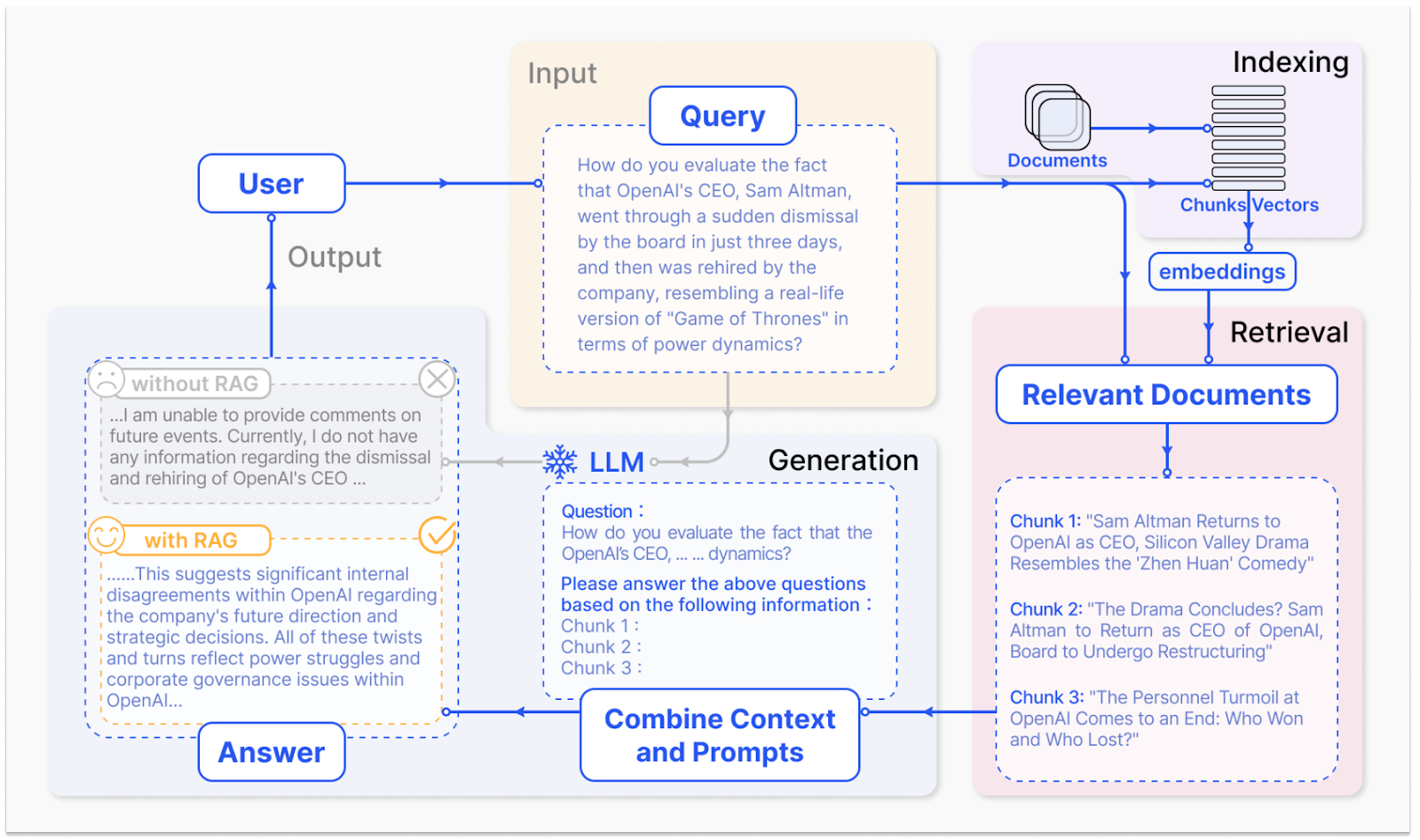
Even in this simple form, RAG is already immensely useful in practice. For example:
RAG is already a standard approach and part of many industrial solutions for LLMs such as Vertex AI Search by Google, NVIDIA NIM Microservices, Amazon workflow based on LangChain, IBM watsonx, Glean, and others. And if you want to “chat with your documents” but don’t feel comfortable sharing all your personal or corporate data with Google or Amazon, you can use an open source tool such as RAGFlow, Verba, or Kotaemon.
But the story does not stop here. Since 2020, there has (naturally) been an explosion of papers related to augmenting LLMs with retrieval. Below, we will discuss the main directions of this research:
The basic RAG pipeline outlined above is just that, basic. When you google something, sometimes you find what you’re looking for on the first try, but very often you need to refine your query, maybe even formulate a few completely new queries based on what you have read by the first one, and combine the results.
Thus, the RAG pipeline is expanded to include a refinement loop, which generally adds something like this:
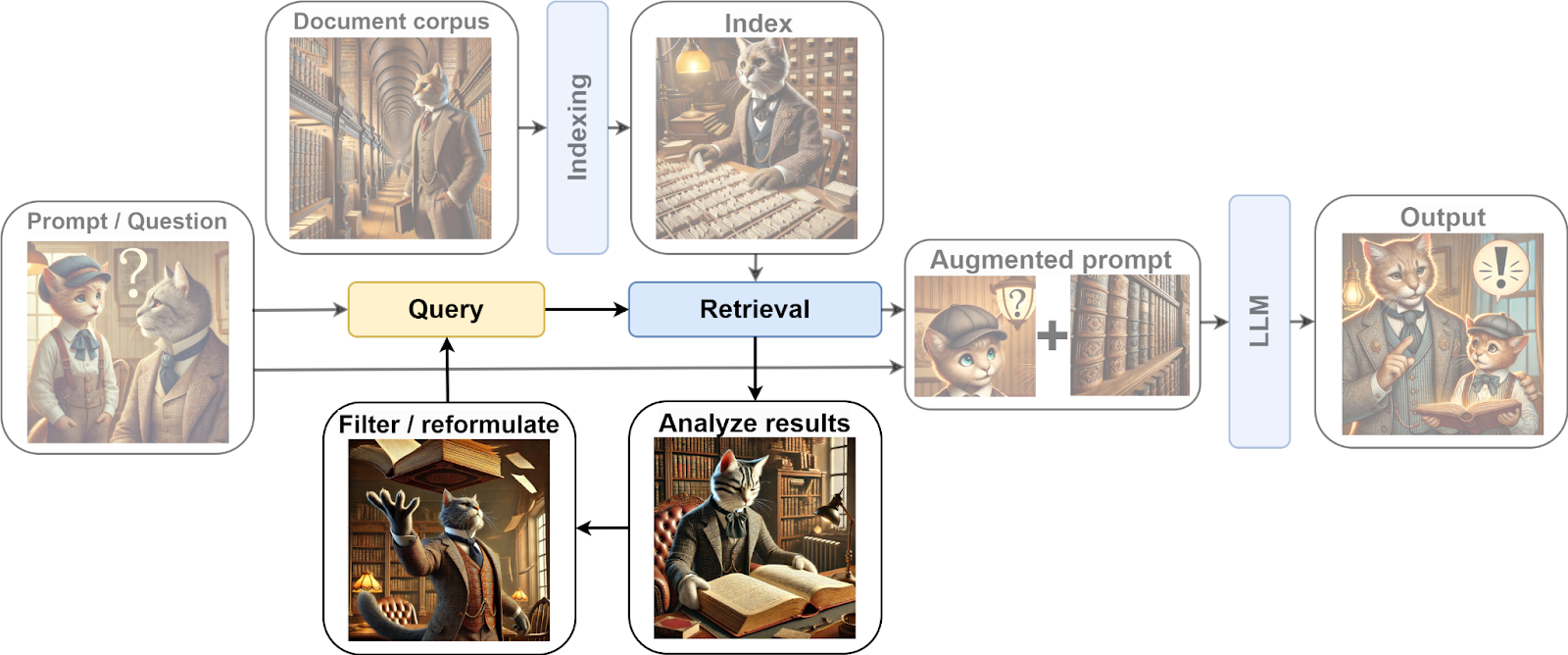
This kind of workflow is modeled in advanced RAG strategies that are often combined under the name of “Agentic RAG”: instead of passively reading the context expanded by retrieval results, here the LLM becomes an agent able to formulate new queries (see, e.g., sample implementations of Agentic RAG in LangGraph). Let us go over a few specific examples.
Shao et al. (2023) provide a straightforward implementation of this idea. Their iterative retrieval-generation strategy takes the output of RAG and uses it as input for another round of RAG (recursively extending to several rounds if necessary), which allows to correct hallucinations and possible factual errors missed on the first iteration.
In the example below, the arena capacity answer highlighted in red was a fact mentioned in one of the documents on the first iteration and erroneously attributed to the answer, as LLMs are prone to do; the second iteration searches again for the correct arena and corrects the mistake:

Self-RAG (Asai et al., 2023), which is short for Self-Reflective RAG, is a good example of a further elaboration of the recursive approach. Self-RAG presents a straightforward but well-executed recursive RAG pipeline based on new special tokens:
Here is an illustration:
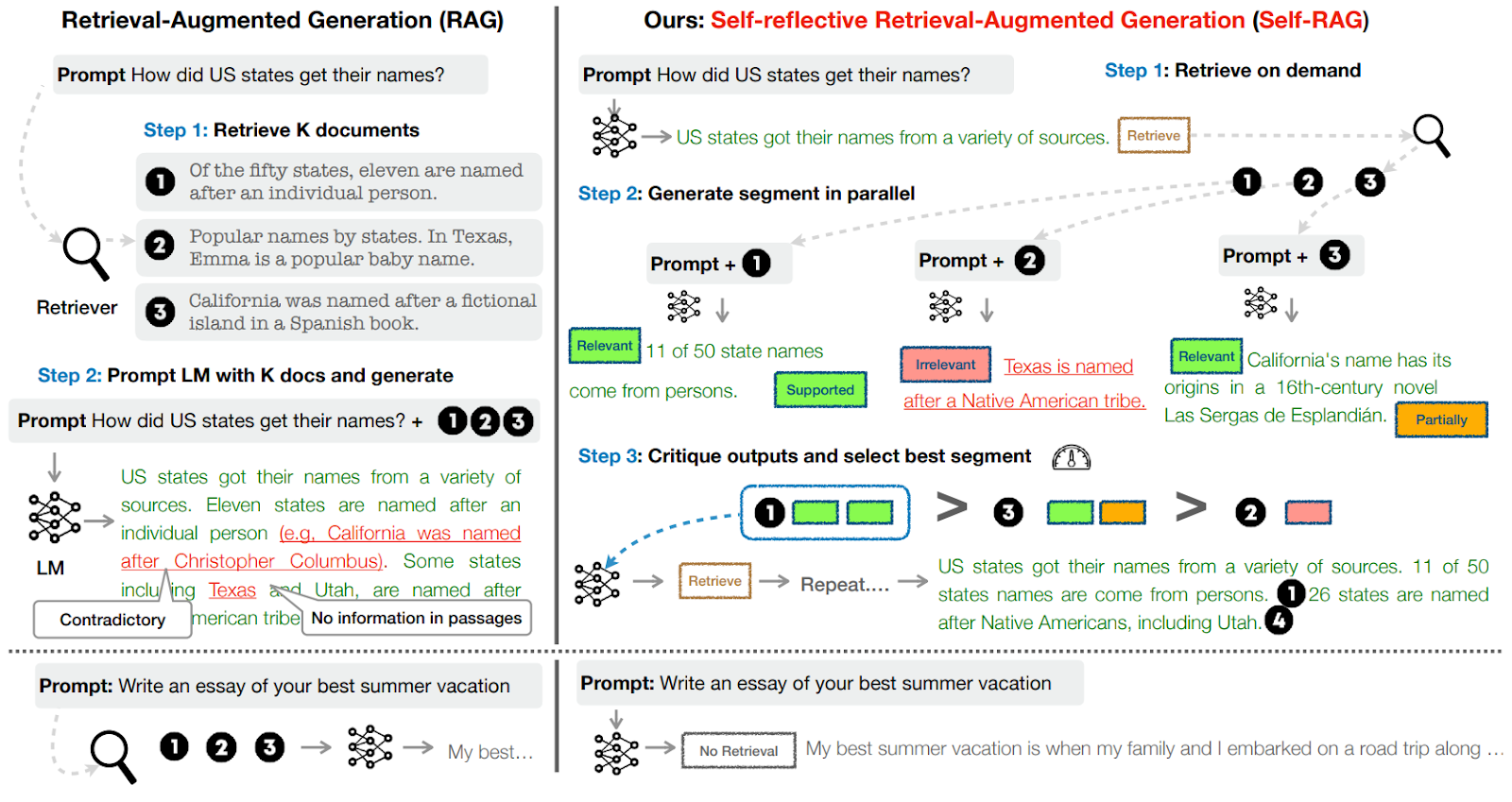
The novelty here lies in the special tokens that represent various qualities of the search results and generated answers such as “Relevant”, “Irrelevant” or “Supported” (by the document). Naturally, the model would have to be fine-tuned to understand what the new tokens mean, and this is done on a synthetic dataset labeled by a separate critic model. The critic model, in turn, is trained in a supervised way based on evaluations done by a state of the art large LLM, GPT-4 in this case.
In a similar approach, Corrective Retrieval Augmented Generation (CRAG) by Yan et al. (2024) focuses on fixing hallucinations and irrelevant retrieval results that are one of the main problems of basic RAG. It runs a separate retrieval evaluator that decides whether retrieved documents are actually relevant and how likely their information is to be correct:
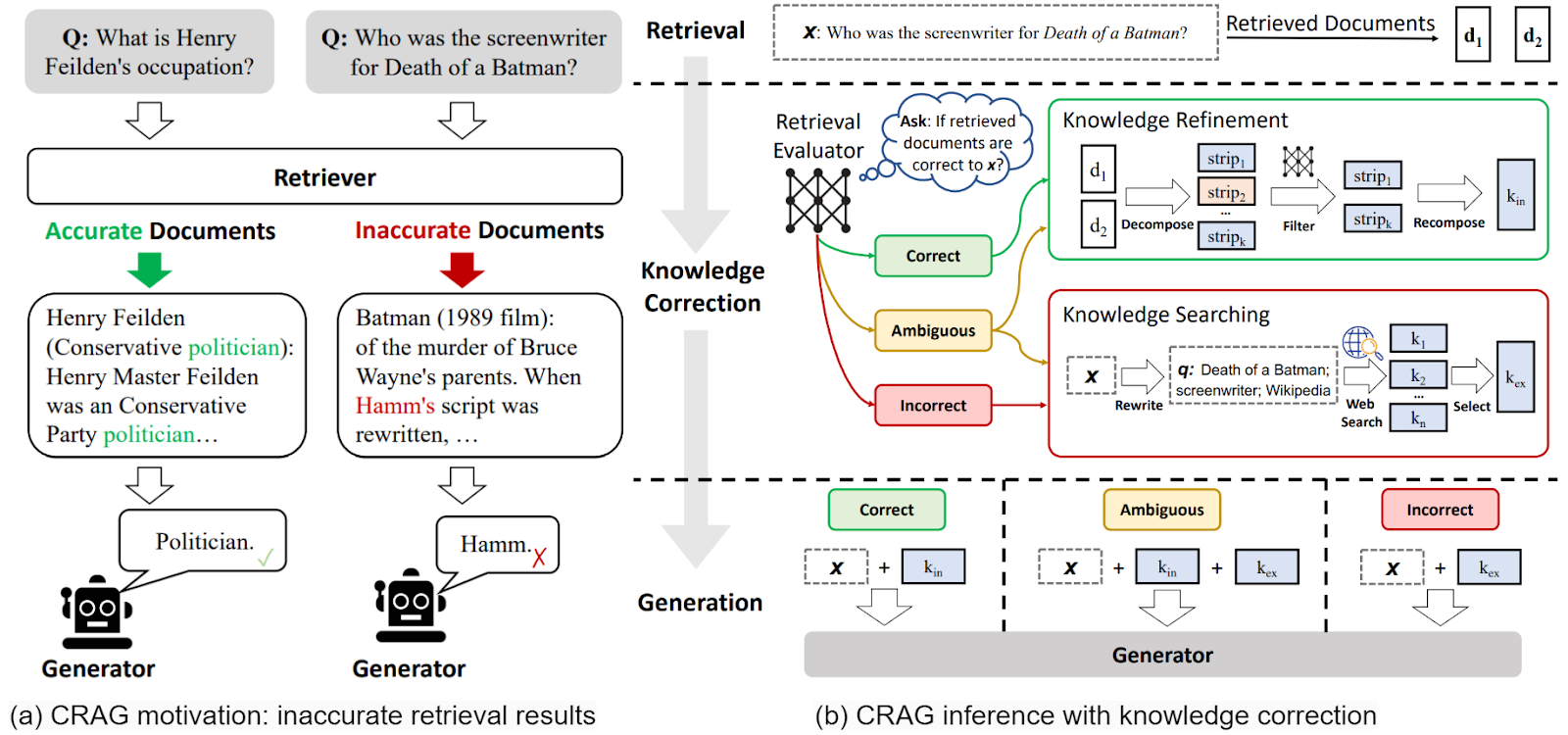
Adaptive-RAG by Jeong et al. (2024) incorporates an additional classifier that chooses the necessary approach. Some queries are simple and straightforward (“Paris is the capital of what?”) and require only one retrieval step or no retrieval at all, while some are more complex and call for multi-step retrieval, and the classifier can choose the correct strategy:

In addition to recursive refinement, there are other techniques that can improve the basic RAG model. We will not go into much detail here, but let me just mention the main directions:

RAPTOR (Sarthi et al., 2024), which stands for Recursive Abstractive Processing for Tree-Organized Retrieval, focuses on a different problem: limitations of the retrieval results themselves and better preprocessing of them. Usually RAG only processes relatively short chunks of information from the retrieved documents near the actual search hits, although the full context of a long text would often help a lot.
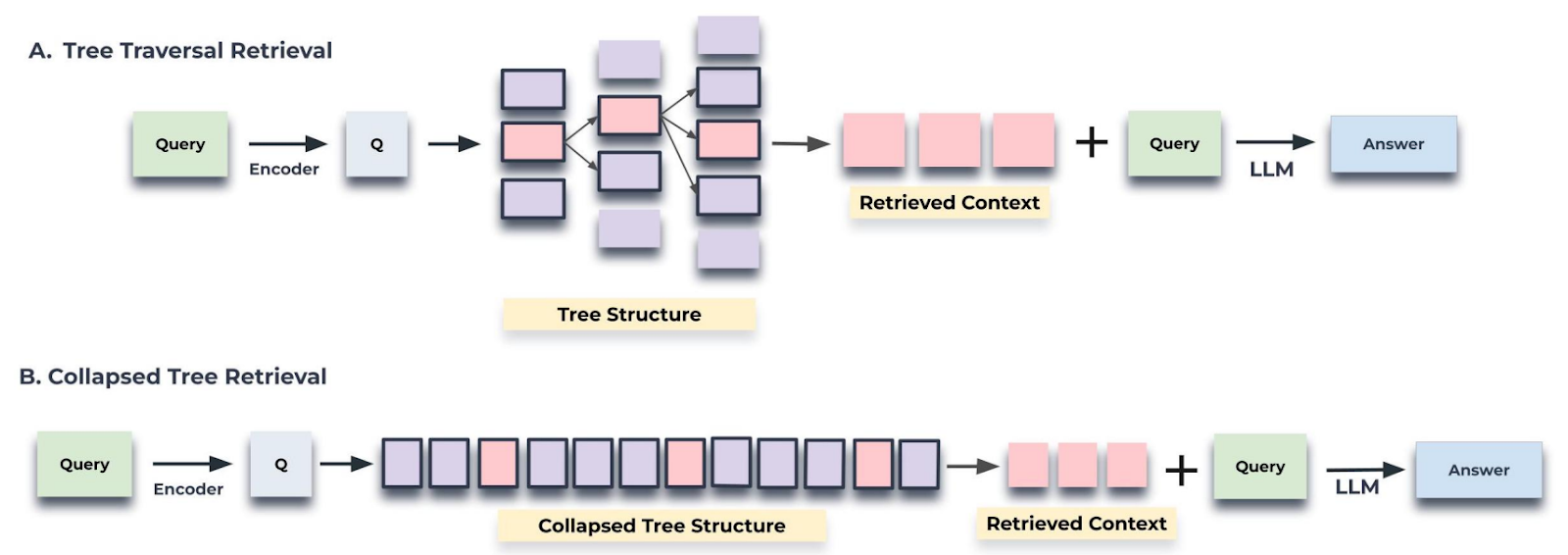
To provide this full context, RAPTOR adds a recursive tree-like summarization step that clusters the vector embeddings of text chunks and generates text summaries of clusters that can be in turn clustered further:

Then retrieval can be run on this tree of summaries, thus retrieving not only the actual short chunks but also the summaries of much longer texts that these chunks are part of; RAPTOR considers both retrieval that traverses the tree and that simply checks all of its nodes:
This significantly improves the LLM’s answers for more general questions on longer texts such as “What is the central theme of the story?”. Questions like that appear in several datasets related to processing longer texts, such as:
The obvious drawback is that RAPTOR needs to build the tree of summaries for the retrieved document, so even though it is a relatively efficient step, RAPTOR is primarily suited for situations when it is obvious which specific long text you need to process to answer the question.
Finally, let me note a recent paper by Google researchers Wang et al. (2024). Their Speculative RAG system makes use of two different LLMs: a “specialist LLM” designed to answer questions based on specific documents and a “generalist LLM” used to combine the results of specialist LLM being run on different retrieved documents. Instead of dumping retrieved documents into the LLM context, Speculative RAG uses the specialist LLM to make several drafts of the response together with rationales for them based on different retrieved documents, and then the generalist LLM can choose the best answer or combine them as it sees fit (illustration from Wang et al., 2024):
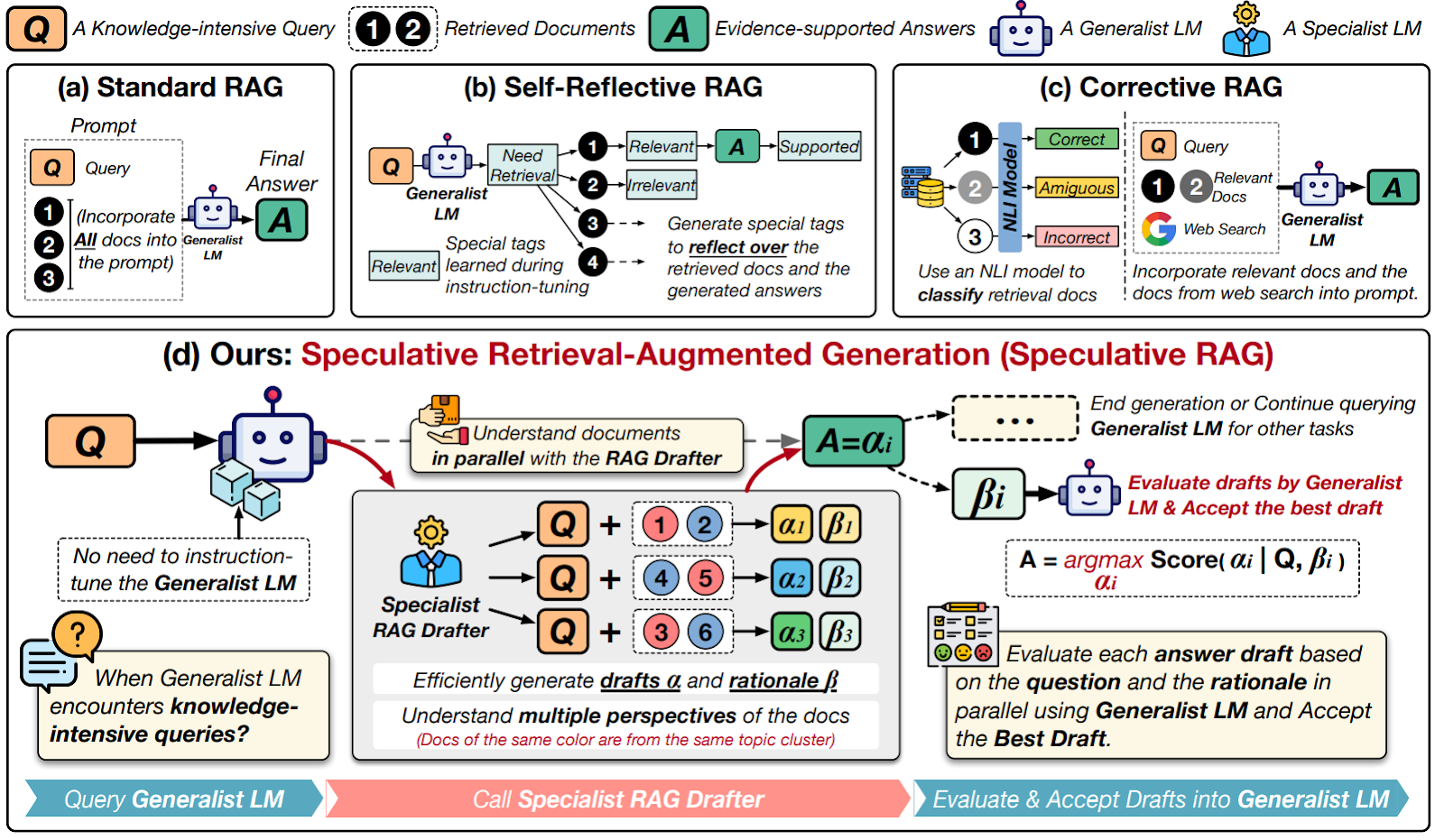
This avoids the problems related to position bias in long context (see below) and allows the generalist LLM to better incorporate different perspectives on the question. The specialist LLM may be weaker (and hence smaller and more efficient) than the generalist LLM since it only needs to process a couple of documents and answer the question directly based on information from them.
In general, RAG methods are being developed in a number of different exciting directions, mostly related to evaluation and reranking of retrieval results, recursive refinement of search queries, better processing of retrieved documents, and criticizing and refining the LLM outputs.
In addition to RAG, there are other keywords related to retrieval-based improvements for language models; the most widely used is RALM (also known as ReALM, Retrieval-Augmented Language Model). Unfortunately, the terminology does not seem to be clearly defined yet: some sources list RAG as a subset of the wider term RALM, others seem to define RALM as using retrieval only on the training set while RAG can use external sources, and yet others view RALM as “RAG 2.0” that further advances the basic ideas of RAG.
This confusion probably stems from the fact that while R[e]ALM sounds like a very general keyword, the original paper that introduced REALM (Guu et al., 2020) indeed used retrieval only on the training set, as a separate part of the architecture learned during pretraining. The point of REALM was to have two different networks, a knowledge retriever and an encoder. During pretraining, the retriever looks for documents that might help in solving the masked language modeling task and supplies the results to the encoder that’s trained like a regular BERT. During supervised fine-tuning and then inference, the retriever looks for a most relevant document for the query and again provides it for the BERT-like encoder:

In this section, we will review a line of work that started from REALM; this is the specific direction that I call RALM here: a language model architecture with a retrieval mechanism embedded into the model and probably trained together with the LM itself, a mechanism that helps in training as well as during inference.
DeepMind researchers Borgeaud et al. (2022) introduced the Retrieval-Enhanced Transformer (RETRO) that incorporates retrieval directly into the Transformed decoder. They turn the training dataset (in their case, the Pile dataset with about 2 trillion tokens; Gao et al., 2020) into a retrieval index based on BERT embeddings of subsequences of tokens. For a given chunk, the retrieval engine outputs its nearest neighbors together with their continuations in the corresponding documents from the corpus. The results are encoder through the Transformer encoder (part of the trained model) and then are attended to by the Transformer decoder in the model:

Borgeaud et al. report that they were able to achieve performance on par with GPT-3 on the Pile dataset while using 25x fewer parameters; this was the first work to scale retrieval-augmented LLMs to trillions of tokens in the corpus and GPT-3 sized models being trained.
FAIR researchers Lin et al. (2024) recently continued this line of work with the RA-DIT framework, which stands for Retrieval-Augmented Dual Instruction Tuning. RA-DIT does not train the LLM together with the retriever from scratch; instead, it uses supervised fine-tuning (recall our previous post) to make the LLM better use retrieval results while at the same time fine-tuning the retriever to better serve the LLM. Here is an illustration from Lin et al. (2024):

In this way, RA-DIT combines a pretrained LLAMA model (Touvron et al., 2023a; 2023b) and a state of the art DRAGON+ retriever (Lin et al., 2023) but makes both of them mesh together better in fine-tuning. The fine-tuning process, by the way, can serve as a good illustration so let us discuss it in more detail. When RA-DIT produces an answer y for an input prompt x, its output probabilities are weighted as
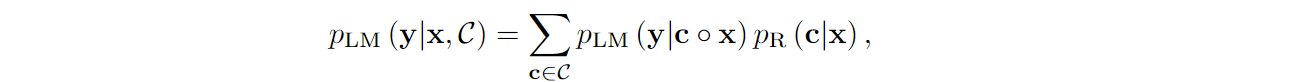
where C is the set of retrieved text chunks c, pR(c|x) is the probability the retriever assigns to chunk c, and pLM(y|c○x) is the probability the language model assigns to y given the prompt of c concatenated with x. Retriever probabilities pR(c|x) are produced via softmax from retriever scores s(x, c), which are just dot products of the query’s and document’s embeddings.
This idea carries over to the supervised fine-tuning process. Supervised training on (x, y) pairs is done separately for the LM and the retriever:

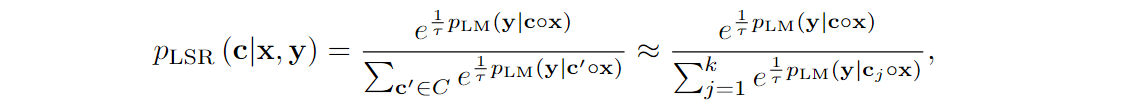
This kind of alternating training is common in systems that consist of two or more well-defined parts: we train one part of the system by fixing the weights of all others and then do it with the other parts. Alternating training is often formalized as optimizing a variational lower bound since the losses may have complex interdependencies; we have seen it, for instance, in training DALL-E (recall our post on it). In this case, since pLSR has a very nontrivial dependence on pLM, when we add them together, optimizing LLM(D)+LR(D) with respect to the language model becomes intractable. Breaking an intractable loss function into tractable components is exactly what variational approximations are for, but in this case neither Shi et al. (2023) nor Lin et al. (2024) provide a derivation for it.
In my opinion, this kind of fusion between the retrieving mechanism and the language model can no doubt help further improve retrieval in joint training. The question is whether fine-tuning will remain necessary at all as LLMs progress further: retrieval will probably always be necessary but we humans don’t have to undergo joint training with Google retrievers to benefit from the search. On the other hand, it’s not like we tried—maybe that lies in the future as well?..
Despite a lot of progress outlined above, there still are problems associated with the use of RAG. One of the most important problems is actually not directly related to RAG but rather to long contexts in general: the larger the context, the harder it is for the LLM to find the “needle in the haystack”.
In RAG, this problem usually takes the form of the “Lost in the Middle” effect recently found by Liu et al. (2024): if the LLM receives many retrieved documents as input, and the necessary information is contained in only one of them, performance will significantly depend on which document in the list contains it.

Liu et al. formalized this point in the multi-document question answering problem illustrated in figure (a) above: the LLM is allowed to use several documents somewhat related to the question but only one of them actually contains the answer. The results are shown in figure (b) above: if the answer is in the first few documents, the LLM’s accuracy is much higher than if it is in the middle, and the saliency of the answer rises again at the end of the context. Liu et al. (2024) showed that this effect is consistently exhibited by several leading LLMs, appears as soon as the total input length exceeds the sequence length used in training the encoder (for encoder-decoder models such as Flan-T5-XXL; Chung et al., 2024) and does not go away if you change the placement of the query compared to the retrieved documents or do instruction fine-tuning.
This specific problem will most probably be resolved by progress in the LLMs themselves. Soon after the publication of Liu et al. (2024), Google released Gemini 1.5, and the corresponding paper was called “Unlocking multimodal understanding across millions of tokens of context” (Gemini Team, 2024). The authors showed that Gemini 1.5 has near-perfect retrieval for a variety of very long context tasks; we discussed this model and generally ways to extend the context for LLMs in a previous post.
However, long context does not solve all problems by itself. Another important problem is redundancy: when you search the Web for something specific, the documents tend to repeat themselves and can saturate any context window. If the repeated documents provide information that’s not relevant to the question at hand, the LLM has a high probability of getting confused by sheer repetition.
I would like to note here that “needle in a haystack” benchmarks such as the ones used by the Gemini team are looking for very specific information, which may be present only in one specific part of a very long context. Here is a sample from the Gemini 1.5 demo on video understanding:
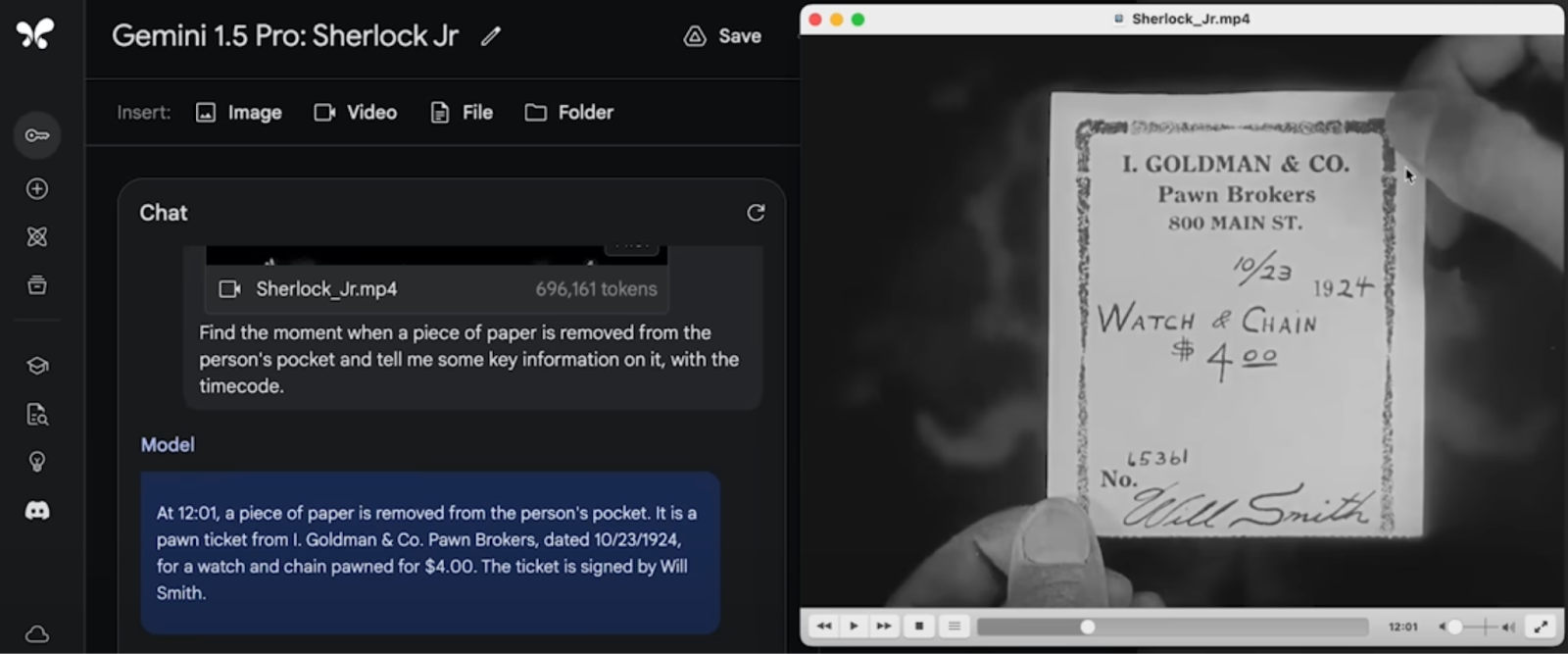
Don’t get me wrong, this is truly an impressive achievement. But the problem here is basically retrieval from context; these kinds of tasks do not involve any generalization or intelligent processing of significant portions of the context. While extra hay makes it harder to find the needle, the question of distinguishing hay from the needle is relatively simple. I wonder what Gemini would say if the question was to “highlight specific influences of Sherlock Jr. on The Purple Rose of Cairo”, a Woody Allen movie with a similar premise, based on the movies themselves rather than critical reviews that had already pointed out the similarities.
For such involved questions, an even more problematic fact is that the knowledge coming from RAG is unstructured. Videos aside, even a regular text-based RAG would usually result in a collection of text snippets that often repeat each other, contain irrelevant extra information or represent retrieval mistakes, i.e., completely irrelevant documents. If you ever tried to learn a completely new field based on the results of a Google search, you know how hard it may be to make sense of this “haystack” as a whole rather than just find the exact trivia “needle” you’re looking for.
For many questions, a more structured way to present information would be both preferable and easily available. To learn (a little) more about Sherlock Jr. I went straight to Wikipedia and never even tried to actually watch the movie, read contemporary critical reviews, Buster Keaton’s memoirs, or other sources that might present themselves: that would take way too much time.
Recently, another very interesting recent direction of study has appeared that may alleviate these problems at least to some extent. Let us discuss it in the next section.
GraphRAG is a direction of study where retrieval queries are run against a knowledge graph and return facts rather than text snippets (see, e.g., a very recent survey by Peng et al., Aug 2024). We have not discussed knowledge graphs on the blog, so this warrants some elaboration.
A knowledge graph (Hogan et al., 2022; Ji et al., 2021; Heist et al., 2020; Yan et al., 2018) is a, well, graph with directed edges and labels on both nodes and edges. A directed edge in the knowledge graph represents a fact defined as a (subject, predicate, object) triple such as (GPT-4, IsA, large language model) or (Sam Altman, CEOOf, OpenAI). The subject and object are the source and sink nodes and the edge between them is labeled with the relation.
The expressive power of knowledge graphs comes from the fact that relations can be arbitrary, and with a proper choice of relations you can fit mostly any factual knowledge in a set of triples. Here is an example from Ji et al. (2021):

If you have a knowledge graph, gathering information about an entity or answering questions about relations between entities (even complex relations that correspond to multi-hop paths rather than edges) becomes a matter of traversing the graph, a much easier and more reliable task than reading and understanding unstructured text.
To be honest, knowledge graphs are a personal favorite of mine. They provide a very easy and very general way to structure knowledge that makes it much easier to make logical inferences. Huge knowledge graphs based on human-verified information are already available, including:
There also exists a wide field of study for automated and semi-automated construction of knowledge graphs from unstructured data (Zhong et al., 2023; Hofer et al., 2023). I have always thought knowledge graphs are underutilized in machine learning; despite the huge literature devoted to knowledge graphs (see the surveys linked above) I believe they could be put to an even better use as repositories of structured information that is usually much more coherent.
Before returning to RAG, let me note several different ways knowledge graphs have already been used together with LLMs. A notable entry here is the ERNIE family of models by Baidu (Sun et al., 2019, Sun et al., 2020, Xiao et al., 2020, Sun et al., 2021), recently made into the Ernie Bot that has reached hundreds of millions of users in China. Starting from the very first model, ERNIE, which stands for “Enhanced Representation through kNowledge IntEgration”, used knowledge graphs to improve the pretraining tasks, enriching the semantics of masking. In ERNIE 1.0 (Sun et al., 2019), it meant that the BERT masks were generated to cover whole entities. In the example below, instead of just filling in “___ Potter” or “J. ___ Rowling” as a random mask would suggest, phrase-level masking forces the network to actually learn the relationship between these entities:

In subsequent versions of ERNIE, this idea was extended to universal knowledge-text prediction that combines a knowledge graph and text snippets; given a triple from the graph and the corresponding text, the model is asked to restore parts of each. Here is an illustration (Sun et al., 2021):

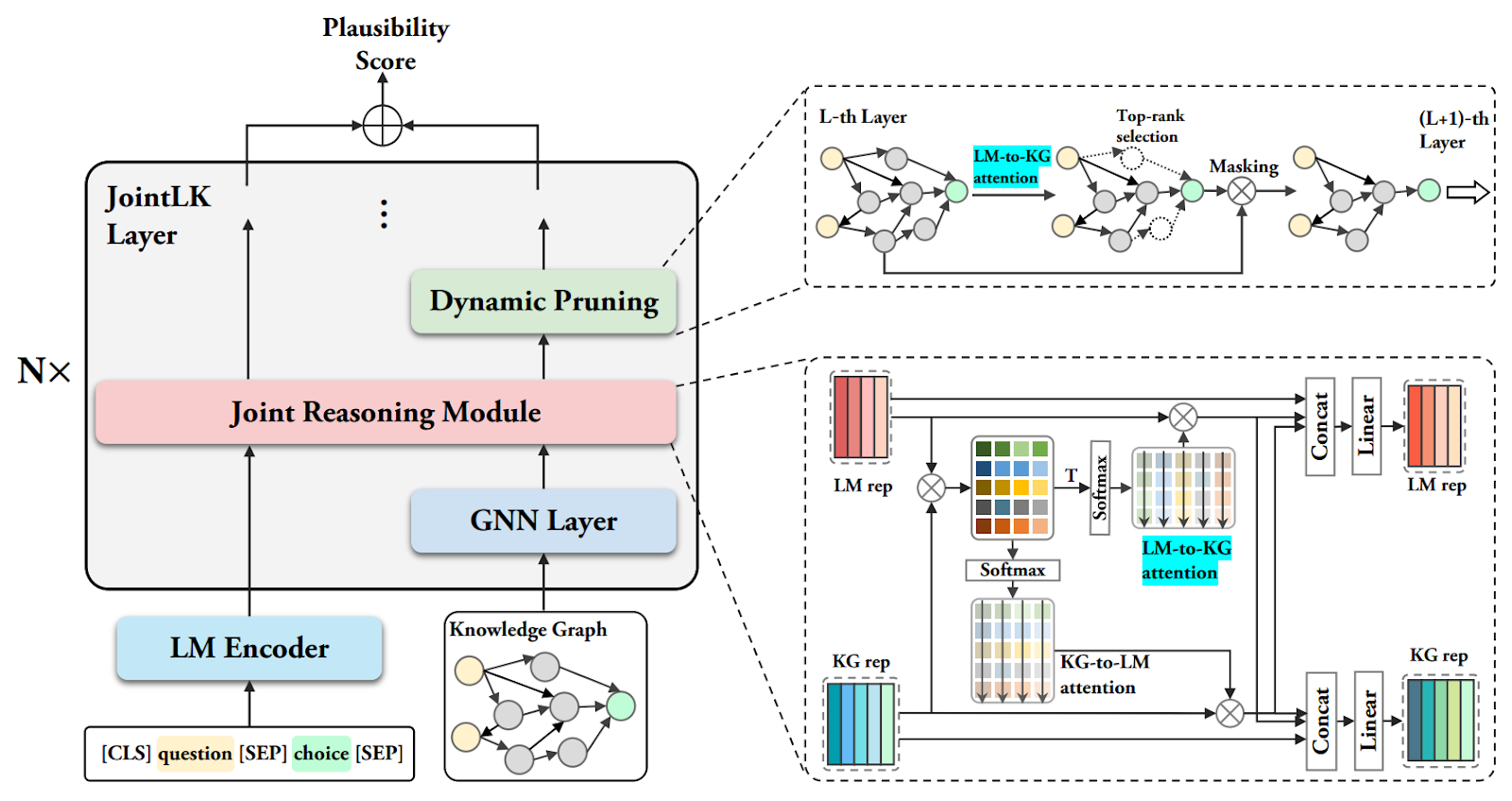
When the LLM has already been trained, knowledge graphs can be used to improve its reasoning abilities and ground the LLM’s answers in verified knowledge, possibly reducing hallucinations (Wang et al., 2023; Chen et al., 2024). Several works develop special neural architectures for that. Approaches before the advent of LLMs usually employed graph neural networks (Ren et al., 2020; Ren, Leskovec, 2020), but now the emphasis has shifted. For example, the JointLK model (Sun et al., 2022) introduces new attention modules that can attend both to a sequence of vectors, like a regular Transformer-based LM, and to parts of the knowledge graph, like a GNN:
These days, of course, it may not be necessary to train a novel architecture: an LLM may be used “as is” with some external scaffolding of knowledge graph retrieval and prompting. Without going into too much detail, here is one example of using the so-called chain-of-knowledge prompting (Wang et al., 2023), a process that expands and significantly improves the “chain of thought” reasoning common for LLMs:

As you can see, the knowledge graph is used as a source of reliable information that LLM outputs and hypotheses can be checked against. There exist many similar approaches (Zheng et al., 2024; Agrawal et al., 2023) but a detailed survey should probably wait for a post devoted to chain of thought reasoning and generally writing good prompts for LLMs (which, I hope, will appear in the future).
The fruitful relationship between knowledge graphs and LLMs also goes in the opposite direction: it is a very natural idea to use LLMs to automatically construct knowledge graphs from unstructured text. One of the first such ideas, COMET (Bosselut et al., 2019; illustrated in (a) in the figure below), used GPT-2 to create new knowledge graph triples from few-shot prompts. BertNet (Hao et al., 2022; (b) in the figure below) starts from a definition of a relation and a few examples, recursively refines the prompts with new paraphrases of the definition, and then uses the prompts to search for entity pairs that have this relation:

The works by Zhu et al. (2023) and Yu et al. (2023) discuss the possibility of an end-to-end automated knowledge graph construction framework based on modern LLMs. They do achieve some success but also highlight some problems that still prevent a full-scale solution, including lack of context, hallucinations, and more. Similar problems have been encountered when applying LLMs to fully automate other knowledge extraction tasks such as named entity recognition (Wei et al., 2023) and event extraction (Gao et al., 2023), where state of the art LLMs do a decent job but do not outperform specially developed solutions. On the other hand, both of these works use the original ChatGPT and predate the release of GPT-4, let alone current models, so the situation may already be different.
But let us get back to the main topic of this post. When applied to RAG, retrieving structured triplets may allow an LLM to give much more detailed and precise answers, especially when they have to uncover relations between different entities (which is very often the case). Here is a sample illustration by Peng et al. (2024):

As you can see, retrieving structured facts can make it much easier to form further deductions and generally process the facts.
To perform the retrieval itself, one can again rely on graph neural networks (GNN) that we have already mentioned. Naturally, you can treat the knowledge graph as a completely separate modality, but there also exist unified approaches. For example, the QA-GNN approach (Yasunaga et al., 2021) uses an LLM to produce a context vector and then plugs it into the GNN for knowledge graph reasoning:

For a recent example of a KG-based retrieval framework, let me highlight Reasoning on Graphs (RoG) developed by Luo et al. (2024). In RoG, the LLM first generates several relation paths that might be useful to answer the question, then these paths are grounded in the available knowledge graph, and finally the retrieved results are again processed by the LLM to produce the final answer:

As a result, RoG lets the LLM gather additional information necessary to answer even in cases when it is not obvious which information is needed, and also to avoid hallucinations along the way. Moreover, RoG can also show the reasoning paths, which greatly improves interpretability: now we can immediately see the chain of factual reasoning behind the LLM’s answer. Here are two examples that Luo et al. (2024) give in their work:

In general, humanity has already collected a lot of knowledge in structured and verified form, so I am sure that using this structured knowledge and probably even preferring it over unstructured text (if structured knowledge is available, of course) is an obvious step that can improve AI systems in general.
What if all that has been too difficult for your liking? You can always go back to a simple alternative that we started with: let’s just extend the LLM’s context with everything retrieval tells us and hope that the LLM can sort it out. The better the LLMs become, the more we can rely on this hope.
In-context RALM (Ram et al., 2023) proposes to do exactly this. Their pipeline is as simple as they come: use an external retriever, collect all retrieved documents, append them to the prompt and let the language model sort it out. Like this:

Note that this is in fact RALM rather than just RAG: the retrieved documents are appended to the autoregressive generation input, so a given next token is conditioned on both already generated tokens and retrieved texts. Ram et al. (2023) rerun retrieval once every s tokens, where s is the retrieval stride; their experiments show that using small values of s, while increasing retrieval costs, actually does improve the results, and in the main experiments they use s=4, running retrieval every four tokens.
The authors show very significant improvements in token prediction perplexity across the board, for a number of different LLMs and different retrievers Another recent work from the same group shows that this approach can significantly improve factuality, reducing hallucinations and getting more factually supported continuations (Muhlgay et al., 2023). So even if you do not have time or resources to fine-tune new models or develop custom architectures, retrieval can improve your LLM’s output even in this default form.
So what does the future have in store for RAG? First, I want to highlight again that large context windows and RAG are both important tools that solve different problems, and one does not make the other obsolete. As base LLMs grow to be more capable, the role of RAG might shift from being a necessary tool to overcome context size limitations to an optimization tool that enhances efficiency, relevance, and scalability, but it will remain relevant anyway.
On the one hand, even a huge context window will never contain the entire Internet or even the entire history of your emails and documents on your computer. On the other hand, a longer context window will enable RAG to work better: if you can afford to carefully read the top 100 Google search results for several different queries rather than only the top 5, your resulting answer will be much better informed. Agentic approaches that gradually refine the query and maybe formulate other related queries for retrieval also keep getting better and will no doubt become an integral part of smart AI assistants.
Second, the internal structure of RAG might change. I currently view GraphRAG that we have discussed above as a very promising approach: triplets extracted from knowledge graphs are a natural representation of knowledge, and this whole field looks like a good “marriage” between knowledge already existing in a more formalized way than just text and LLMs.
Third, we have not really discussed multimodal RAG in any detail: so far it appears to be a rather straightforward application of existing representation learning approaches for other modalities but this can also change in the near future.
Fourth, some applications require time-sensitive retrieval as new relevant information may appear and replace old info. A simple example here would be a financial advisor AI that needs to operate with current stock prices or a personal AI assistant that continuously gathers new updates from your social media and summarizes them for you.
But whatever the future brings, I believe that RAG will always remain a natural and important component of AI systems; not even the LLMs of the far future will be able to fit all of the world’s data into their context, and they will need some mechanism for sieving through this data other than just reading it token by token. In general, while an LLM is the central part of many AI systems it is not an end-all single model for everything: it needs a variety of other tools and subsystems to obtain the necessary information. Next time, we will discuss another important component of modern LLM-based solutions.
Sergey Nikolenko
Head of AI, Synthesis AI
