
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
One of the most interesting AI-related news for me recently was a paper by DeepMind researchers that presented a new mathematical result found by large language models: new constructions for the cap set problem. In this post, we take a step back and discuss the general relation between math and AI. A mathematical proof is easy to verify but may be very hard to find. But there are AI-shaped holes in looking for a proof: math involves multi-step reasoning and planning, hard theorems need to be decomposed into lemmas, there are search strategies involved… However, mathematics has turned out to be unexpectedly difficult for AI. In this post we discuss what people have been doing with AI in math and how LLMs can help mathematicians right now.

I am a mathematician by education, and I have been doing math in some form or other throughout my career. My M.Sc. thesis in 2005 (almost 20 years ago! how time flies…) was devoted to structure theorems for Chevalley groups, my Ph.D. in 2009 was on theoretical cryptography where the main content is theorems rather than protocols, and my Sc.D. (habilitation) thesis in 2022 was devoted to the analysis of algorithms for networking and was also full of theorems.
The general workflow of a professional mathematician goes a little bit like this:
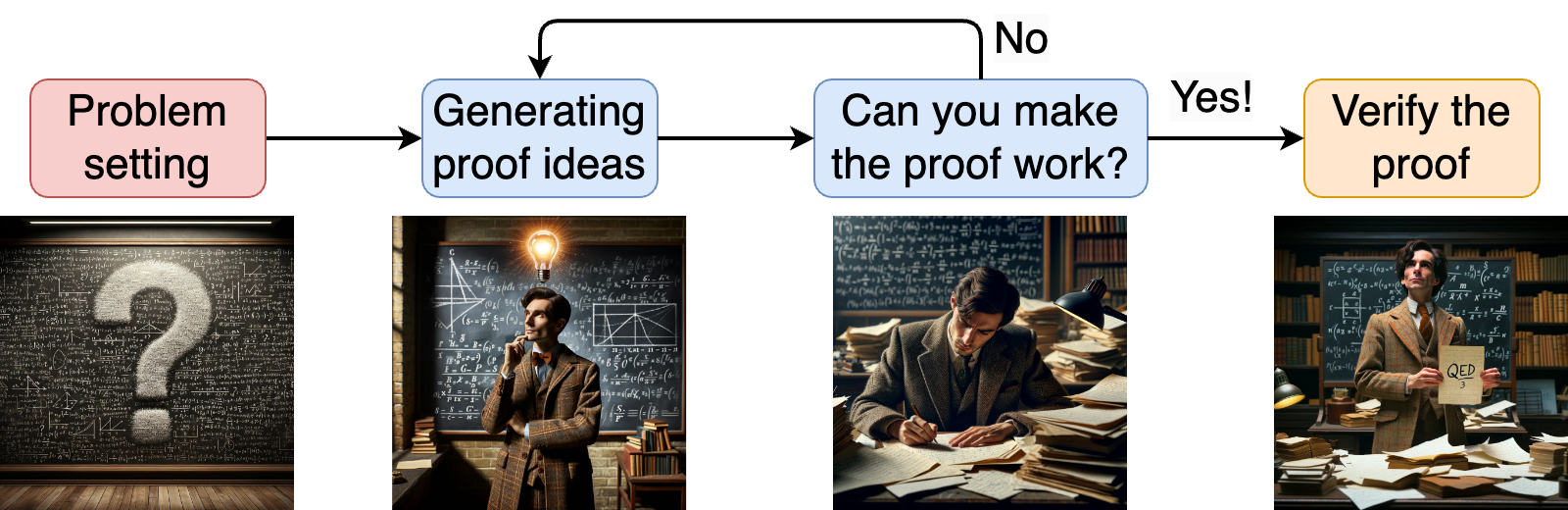
This is a big simplification, of course; for example, you often begin not with a problem but with a method, and try to find an interesting way to apply this method to some new application. But to a first approximation, solving a problem in mathematics usually means proving something, and when you try to prove something new, you usually need to come up with some creative ways to do it. Then your idea needs to be fully fleshed out: that’s where most ideas fail, and it’s back to the drawing board for the mathematician. Finally, once the proof is done, you need to verify it and, if everything is fine, write it up for publication.
I worked on mathematical logic, then machine learning and artificial intelligence, and through all these years I couldn’t help but wonder: why could I still be a mathematician? How is it possible that in our time, 100 years after Hilbert and 80 years after Gödel, theorems are still proven by live flesh and blood people? Let me elaborate a little so you can feel the wonder too.
Mathematics is the most formalized field of research; it is not a “science” since it does not deal with the dirty material world. Mathematics lives in a separate magisterium of abstractions where everything is absolute: you accept a few axioms and derive everything from these theorems via formal derivation rules. And by “formal”, I mean really formal, not general proof ideas like “reasoning by contradiction” but specific indisputable axioms that convert logical formulas to other logical formulas such as modus ponens: if we have a formula P and another formula P→Q, where → denoted implication, then we can add Q to our set of derived formulas (and use it further in the proof).
For example, Alfred Whitehead and Bertrand Russell (shown below) wrote a famous book called “Principia Mathematica”, where they attempted to build the whole mathematics from the ground up, starting from the axioms. In the book, the proof for 1+1=2 appears on page 379:

Naturally, that’s because they had to define the entire set theory, natural numbers, and addition first, but it is still quite an amazing piece of trivia.
Theoretically, you can write down the proof of every correct theorem as a formal chain of such derivations. It will be unbearably cumbersome, so I can’t even give you a serious example here, but in theory it can be done. More modern branches of mathematics such as group theory have this formalization built in: they start off with a fixed set of axioms (definition of a group in this case) and derive theorems formally.
Formalization is a relatively recent idea. For example, high school geometry is usually the place where you can get a feeling for mathematical proofs, but it is actually a pretty informal affair, with a lot of holes that Euclid did not fill. When mathematicians tried to patch up geometry, the 5 Euclid’s axioms expanded into 16 for Hilbert or 10 for Tarski (plus an extra axiom schema). Calculus was initially a rather intuitive affair, tightly interwoven with physics, differential equations, and practical applications. The derivative is the speed, the second derivative is the acceleration, and so on. It was only in the XIX century when all those suspicious counterexamples you vaguely recall from calculus classes (such as the Dirichlet function which is 1 on rational numbers and 0 on irrational ones) finally caught up with mathematicians and made “intuitive math” no longer viable. Something was wrong: mathematics needed to fix its foundations.
The answer was to introduce formal axioms and derivation rules and make math purely formal; this was the project initiated by Georg Cantor and Gottlob Frege in the second half of the XIX century and almost completed by David Hilbert in the beginning of the XX century. In this project, mathematics begins with set theory, usually introduced with Zermelo-Fraenkel’s axioms, and then other branches of mathematics are defined in terms of sets. For instance, natural numbers are usually introduced as ordinals: 0 is the empty set, 1 is the set with one element which is the empty set, {∅}, 2 is the set {0, 1} = {∅, {∅}}, 3 = {0, 1, 2} = {∅, {∅}, {∅, {∅}}}, and so on.
I say “almost completed” because Kurt Gödel’s incompleteness theorems proved to be an unfixable flaw in the original Hilbert’s program: for any reasonably powerful proof system (sufficiently powerful that it can include arithmetic), you can find true statements that are nevertheless unprovable. When Hilbert heard about these results, he went through all five stages of grief, from anger to acceptance.
But really, Gödel’s incompleteness is not a problem in practice. Sure, there exist true unprovable statements, and there is a whole cottage industry devoted to finding specific unprovable statements (wiki). But you won’t find them in everyday mathematical practice. If you want to prove a new theorem, you can be quite certain that it can be proven within “standard mathematics”. Even if a notable counterexample arises (can the Riemann hypothesis be undecidable?), it will remain just that: a very, very special case.
So we can safely assume that formal proofs of new, unproven theorems exist somewhere in the abstract world of mathematical absolute. The next question is: how do we find them?
Formal proofs are hard to find, but once a proof has been found, it is easy to check that all derivation rules have been applied correctly. You could say that finding proofs for theorems is in NP (recall the P=NP problem)… if you measured complexity as a function of the size of the proof rather than the theorem itself. The problem is that some proofs may be unbelievably large, far exceeding the number of atoms in the known universe even for a small and obviously true statement (alas, it would get too technical to give specific examples).
Proof size depends on two things: the statement (theorem) that’s being proved and the proof system where it’s happening, i.e., which axioms and derivation rules we are allowed to use. Universe-sized counterexamples could be proven very compactly, even elegantly in more powerful proof systems — otherwise how would we know they are true? But there is an inherent tension here between the size of the proof and the expressive power of the proof system. You can have a very simple proof system where proofs may be easy to find, but they will be very long even in reasonable cases. Or you can have a very strong proof system that allows for many short proofs, but it will be much harder to find them. Sometimes it all comes down to adding or removing a single important rule, such as the cut rule in Gentzen’s sequent calculus:

Still, these results usually come in the form of counterexamples that one has to actively search for. There is no result that says that interesting mathematical theorems such as Fermat’s last theorem or the Riemann conjecture have to have astronomically long proofs, even in a simple proof system. And surely, even if the hardest riddles of mathematics do indeed turn out to be hard for a reason, there’s still a lot we can do about simpler problems, right? Math is large, it has a long frontier, and there should be plenty of opportunities to advance it.
As soon as computers allowed people to try, automated theorem provers did appear. In fact, in the early days of artificial intelligence logic was thought to be one of the key components. The famous 1943 paper by William McCulloch and Walter Pitts, which introduced the first mathematical model for a neuron and hence a neural network, was called “A logical calculus of the ideas immanent in nervous activity”, and the main results were purely logical in nature. McCulloch and Pitts compared several possible architectures of neural networks and established logical equivalences between them: if a function can be realized by one kind of network then it can also be realized by another. Just read the abstract if you don’t believe me:
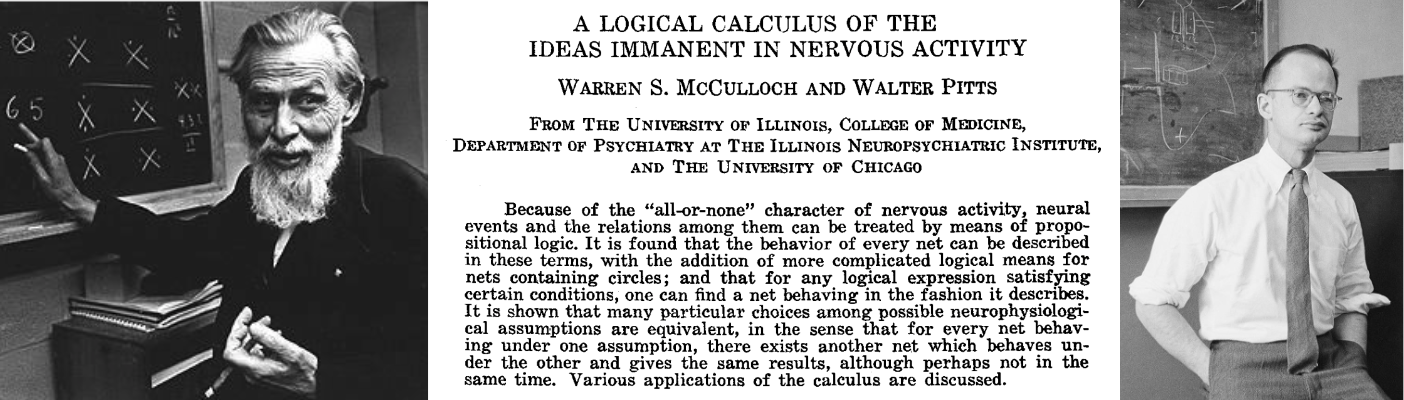
Logic was a key idea in early AI: people thought that the difficult part of getting a machine to think would be to imbue it with logical reasoning, teaching it how to make inferences correctly. It soon became evident that reasoning in the everyday sense of the word is not a problem, and the real problem is converting murky everyday notions into statements you could reason with. Understanding notions such as “near” (as in “don’t go too near”) or “elevated” (as in “you have elevated blood sugar”) gave rise to fuzzy logic, converting a collection of pixels on a photo into a mathematical representation of a 3D object is the fundamental problem of computer vision, and so on.
Still, what about harder reasoning like proving new theorems? One of the first successful automated theorem provers was Logic Theorist, developed in 1956 by Allen Newell, Herbert Simon, and Cliff Shaw (see also Gugerty, 2006). It pioneered many techniques that are now standard. Formulas were represented as trees, and the search for a proof itself was a tree with the initial hypothesis as the root and deductions as branches. Since the search tree (unlike the final proof, which is just one of its paths) would definitely be exponential in practice, Newell, Simon, and Shaw developed heuristics for pruning branches unlikely to lead to a solution, a technique that would become standard throughout early AI. Finally, to implement Logic Theorist the authors developed a programming language called IPL (Information Processing Language) which was the direct predecessor of John McCarthy’s Lisp!
They tested Logic Theorist on Principia Mathematica, feeding it with 52 theorems from Chapter 2, in the same order. When Logic Theorist proved a theorem, it could add it to storage for use in later proofs. As a result, it proved 38 of the 52 theorems (73%!), and sometimes produced shorter proofs than the ones by Whitehead and Russell themselves!
In the 1950s, it was hard to expect this automated search to actually come up with new theorems: computers were slow and their memories were small. Still, these results were extremely promising. Logic Theorist is widely regarded as the first real life program from the field of AI, actually predating the famous Dartmouth workshop where the term was coined. In January 1956, Herbert Simon told his graduate class: “Over Christmas, Al Newell and I invented a thinking machine”, and he would later write that they “invented a computer program capable of thinking non-numerically, and thereby solved the venerable mind-body problem, explaining how a system composed of matter can have the properties of mind”.
The 1950s were indeed a very optimistic time. But where did this line of thinking lead? How did later attempts at theorem proving go?
In the 1960s and 1970s, the researchers’ attention turned to a large extent to symbolic math systems. One of the pioneers here was MACSYMA, which stands for “Project MAC’s SYmbolic MAnipulator” (Pavelle and Wang, 1985; Fateman, 1982). Project MAC (Machine-Aided Cognition or Multiple Access Computer) was an MIT lab that later grew into MIT CSAIL (Computer Science & Artificial Intelligence Laboratory), one of the leading academic AI labs today. MACSYMA was a software system, developed in a specially designed Lisp dialect, that could perform many symbolic mathematical operations including limits, derivatives, Taylor series, Laplace transformations, ODEs, and more. It was a direct precursor to such systems as Matlab and Maple, but it was mostly used as a computational tool for researchers in other fields of science.
Automated theorem proving, on the other hand, progressed much slower. One of the early landmarks here was the Automath formal language developed by Nicolaas de Bruijn in the late 1960s. Automath has been largely forgotten now, but it actually laid the foundations for typed lambda calculus, including the introduction of dependent types, and pioneered the use of the Curry–Howard correspondence, also known as the “proofs-as-programs” correspondence: a program of a certain type (in the sense of typed programming languages) can be seen as a proof of the proposition represented by this type. I won’t go into a detailed explanation here but do recommend the interested reader to work through at least the example given in Wikipedia.
One of the first popular proof assistants was Mizar, a system that first appeared in 1973 and is still in active use today. Then came Coq itself, which remains the popular proof assistant to this day. Another important proof assistant is HOL, which stands for “higher order logic”; indeed, HOL can handle higher-order logic proofs, and it is still a live project with new versions coming out.
Today, there are plenty of tools that can verify formal proofs of mathematical theorems, and some of them can look for new proofs too. Naturally, there have been attempts to formalize at least the math that we already have… but without much of a success.
For example, there is a valiant effort in the form of the Formalized Mathematics journal established in the 1980s. It publishes formal, mechanically verified proofs of known mathematical results; naturally, nobody prohibits authors from using a computer to come up with the proofs either. Right now, some of the latest papers in Formalized Mathematics are solutions to problems from the book “250 Problems in Elementary Number Theory” by Wacław Sierpiński, published in the late 1960s. These are not open problems, they are just somewhat advanced problems for students that you might find in a textbook (here is a paper from Dec 31, 2023).
I’m not saying this to kick Formalized Mathematics, I’m saying this to show that doing math in a formalized and automatically verifiable way is hard indeed, much harder than an outside view on math might suggest. The “QED Manifesto”, a similar initiative put forward in 1993, also quickly dissolved. In general, formalized mathematics still lags very far behind “real” mathematics done by people.
Automated theorem provers, i.e., programs that can try to find proofs all by themselves, do exist. For instance, there is a well-known family of first-order provers developed at the Argonne National Laboratory in Illinois, starting from Otter and continuing via EQP (Equational Prover) to Prover9. More modern examples include Lean, a general-purpose theorem prover and proof assistant.
And they are indeed used in mathematics (see, e.g., the list of papers using Lean), but full-fledged automated proofs are very rare and always constrained to cases where human mathematicians did see the path to a proof, but the path was too cumbersome to do by hand. One famous example here is the Robbins conjecture, proven in 1996 by the EQP prover. Again, I recommend the reader who is familiar with basic mathematical structures such as Boolean algebras to actually read through the problem setting by the link. The Robbins conjecture is about an alternative set of axioms for Boolean algebras, and the question is as close to axioms as possible: is the alternative set actually equivalent to the definition? In 1996, William McCune proved that it is indeed the case, using the EQP theorem prover that specializes on rewriting equations. You can find the whole proof in human-readable form in this paper by Allen Mann, although “human-readable” may be a slight overstatement in this case.
So this was a success for automated theorem proving. But this problem has the perfect combination of traits for the point I want to make:
These traits are characteristic of most mathematical results where computers have been able to meaningfully assist humans. One of the first famous examples is the four color theorem, a conjecture from graph theory that you can paint the regions of any map in four colors so that no two regions painted in the same color share a nonzero border (arbitrarily many regions can come to a single point, of course, but that doesn’t count). As you can see, this is also a short and discrete kind of statement, but the proof (announced by Appel and Haken in 1976) was still done almost entirely by hand. The crucial point, however, required enumeration and analysis of about 1500 different cases, so this part was programmed and done on a computer. It’s not quite the automated proof search you would expect (although in 2005, the proof was actually formally verified in Coq, so the four color theorem is now part of formalized mathematics).

Other examples (see, e.g., this list on Wikipedia) are usually of the same nature: computers help with long case-by-case analysis or with mechanical rewriting of complicated equations, but the ideas remain human. In fact, many mathematicians are still wary of computer-assisted proofs because they are unverifiable by humans and therefore don’t fulfill the main function of a proof: they don’t convince people. In a paper on the Robbins problem, Louis Kauffman sums this conundrum up as follows: “Can a computer discover the proof of a theorem in mathematics?.. I say that a proof is not a proof until a person is convinced by it. In fact a mathematical proof is exactly an argument that is completely convincing to a mathematician! In this sense, a computer does not, can not produce a proof… It does not know the proof. It only finds the steps. It is a human judgement that propels the result of the computer’s search into a statement that the computer has “found a proof”… If we judge that to be a proof, then it is a proof (for us)”.
But all that was in the 1980s and 1990s. Now we have powerful GPUs, deep neural networks that do wonders, exceeding the human level in many tasks that we considered purely human before. So they can help us with math as well… right?
As we have already discussed, there are two main directions in how AI can help mathematics: either directly by finding proofs or indirectly (but usually more efficiently) by doing straightforward but cumbersome stuff like rewriting equations or doing case-by-case analysis.
Several breakthroughs have been made in following the latter strategy. Modern deep learning adds another important twist on this idea: instead of mathematicians writing code that enumerates possibilities, an AI model can try to write the best code for the problem as well. This is very similar to neural architecture search (NAS) that yielded some of the best neural architectures in computer vision, new activation functions, and more. Similar to how you can search for architectures, you can also search for programs, usually with some kind of genetic programming approach since computer programs are naturally represented by trees.
So you can take it one step further and tackle problems where the answer is an algorithm. In 2022, DeepMind’s AlphaTensor made the news doing exactly that: it discovered improvements in matrix multiplication algorithms, improving over Strassen’s algorithm for the first time in 50 years. In AlphaTensor, the tensor specifies which entries to read from the input matrices, and where to store the result; for example, in the three-dimensional tensor below, (a1, b1, c1) and (a2, b3, c1) entries are set to 1, and this means that c1=a1b1+a2b3:
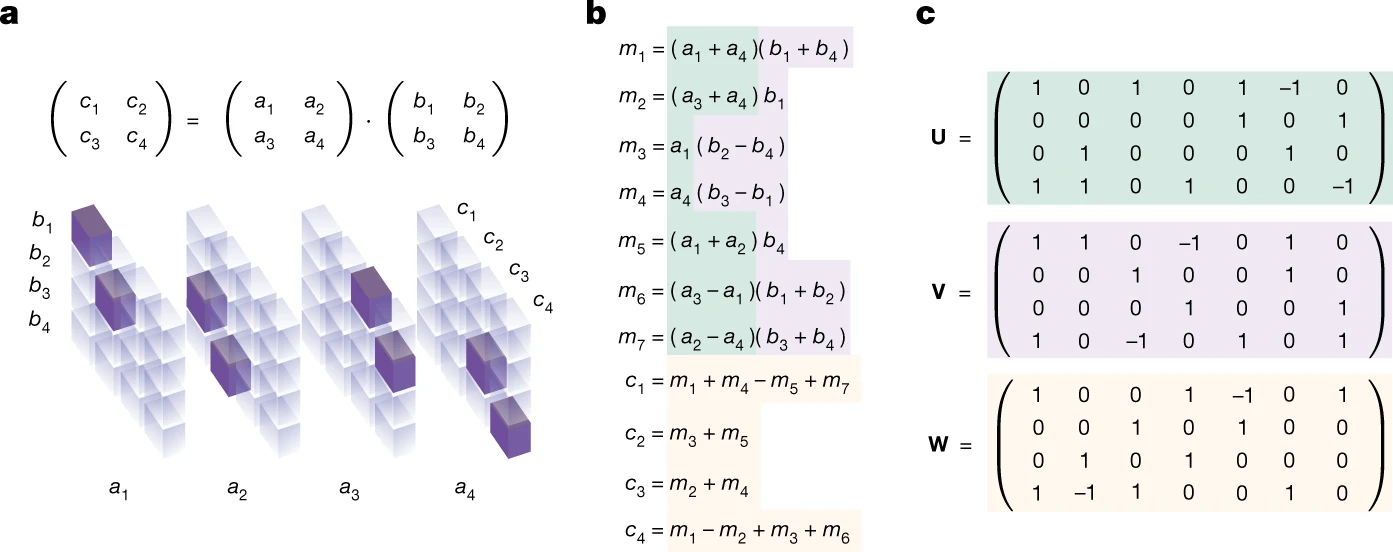
AlphaTensor optimized over such tensors with an MCTS-based algorithm very similar to AlphaZero that plays chess and Go but with some new advances related to the extra large width of the search tree in this case. As a result, it improved over the best known matrix multiplication algorithms for a number of different matrix sizes, starting from as low as 4×4 matrices; this is more than just a constant improvement since these algorithms can be applied recursively to handle block matrices of arbitrary size. This was a very important result, and it was obtained virtually independently of humans; but again, this falls more into the “searching through cumbersome cases” category, the AlphaZero-based search algorithm just helps scale it up to a previously unheard of number of cases.
Another important example in the same direction that made the news last year was AlphaDev, another work by DeepMind in a similar vein that managed to improve sorting algorithms, that is, the cornerstone of almost every data manipulation computer program in the world! In a Nature paper by Mankowitz et al. (2023), the researchers presented another AlphaZero-based modification of MCTS search designed to invent new sorting algorithms. The resulting algorithms have already been implemented in the std::sort C++ library, which means that they are already making millions of computer programs run faster.
As large language models became available, another direction appeared: you could ask LLMs to prove theorems directly! Naturally, it did not work all that well at first, and even today, if you just ask an LLM to prove a theorem, this strategy won’t get you published in Annals of Mathematics.
One way to improve here is to fine-tune LLMs on mathematical content. For example, Minerva (Lewkowycz et al., 2022) did just that, fine-tuning general purpose LLMs from the PaLM family on technical content. As a result, Minerva could successfully reason through some high school level mathematics, although it was still a far cry from proving new results. Here is a sample of what Minerva was capable of:

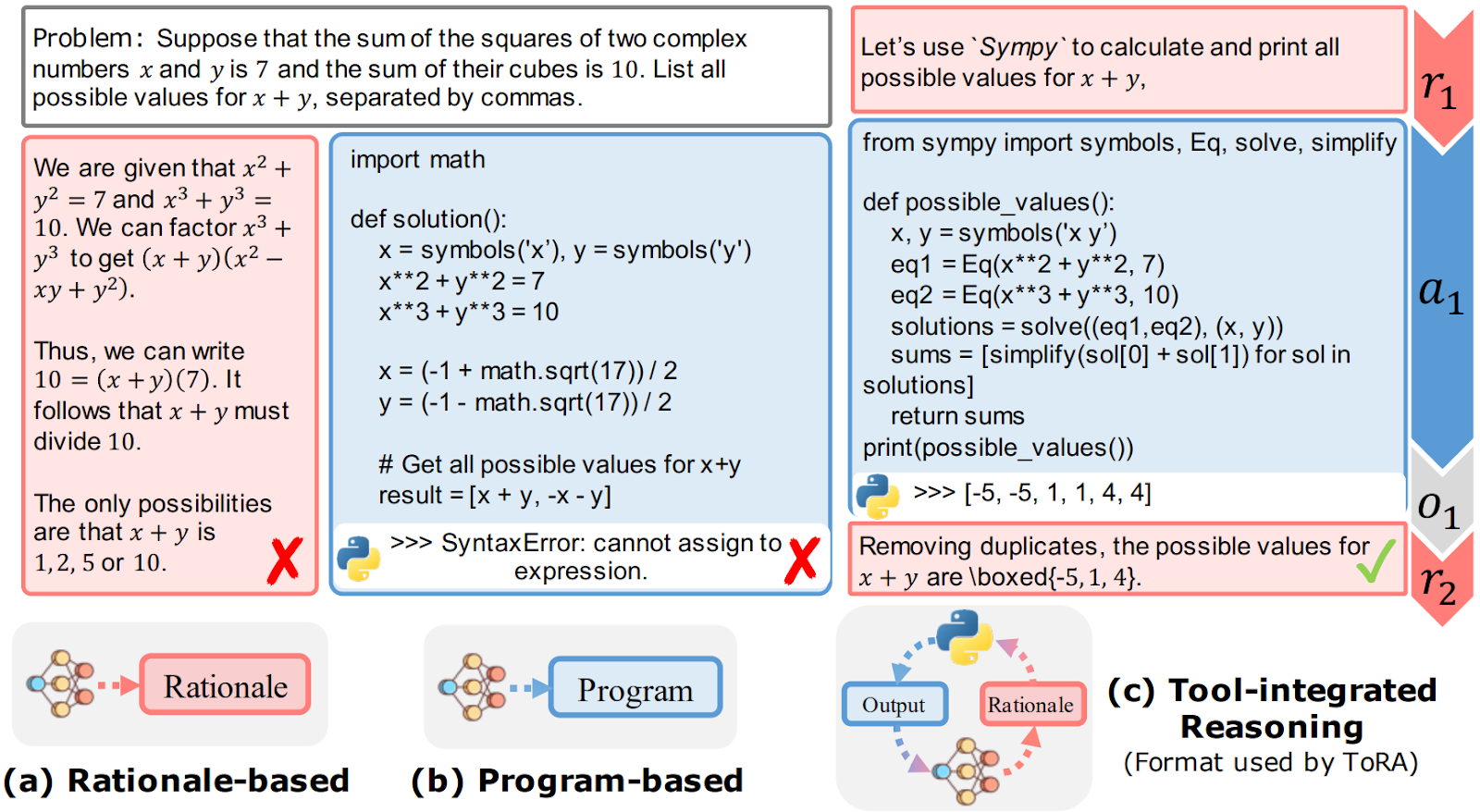
Another approach would be to use the already excellent coding capabilities of LLMs. As you know, modern LLMs can produce correct code snippets, so if your problem can be solved by some kind of enumeration you can ask the LLM to write this code for you. ToRA (tool-integrated reasoning agent) by Gou et al. (2023) closed the loop in this reasoning, using an LLM to write code, then going to an external tool to run it, and then fixing the code and interpreting the results with an LLM again. In the illustration below, the authors contrast ToRA with pure language-based and pure code-based approaches:
Finally, I want to highlight another work by DeepMind (looks like they are the main players here): “Advancing mathematics by guiding human intuition with AI” by Davies et al. This work pursues a very different approach to helping mathematicians: instead of trying to formally prove something, here the authors use machine learning to discover new possible relations between mathematical objects. Here is the general framework of how it works; note that there are both “computational steps” done by AI models and “mathematician steps” done by real people:
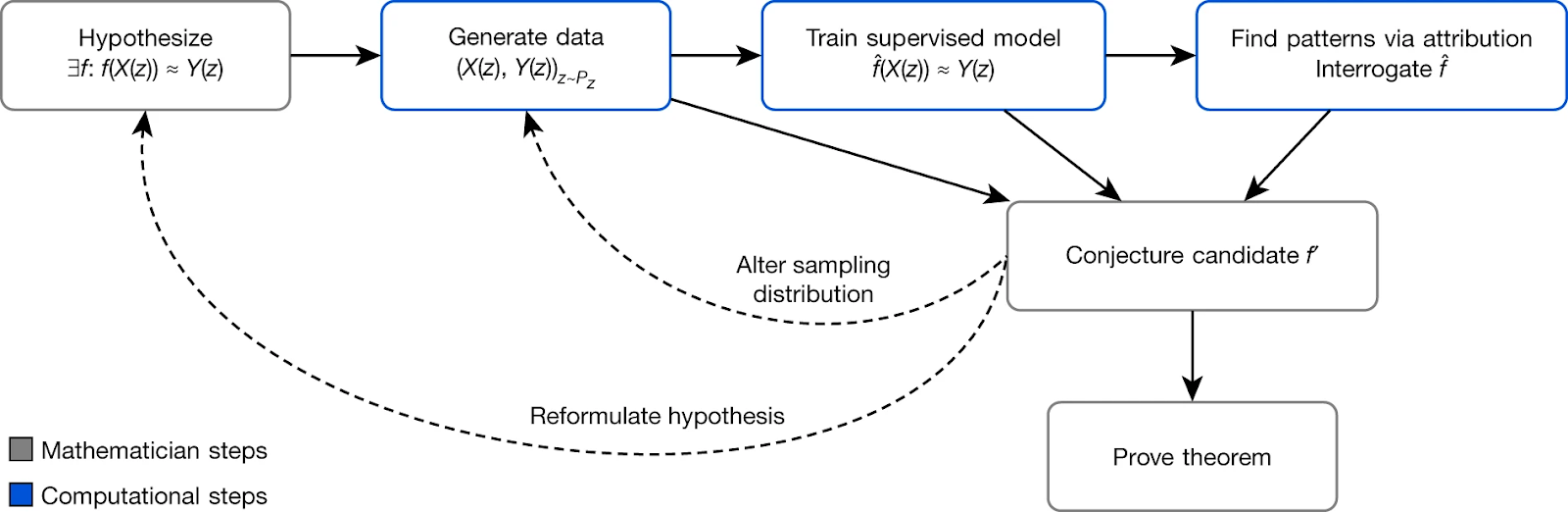
For example, the authors could discover and then actually prove a relationship between algebraic and geometric invariants in knot theory. The margins of this post are too narrow to explain what exactly this means, but in essence, a machine learning model detected that there might be a relationship between one way to describe knots in topology and another. This connection turned out to be real, and mathematicians were able to prove its existence and introduce new important objects that describe it. Naturally, they did it by hand, but their intuition in formulating this result was guided by ML-produced discoveries.
And with that, we have reached the latest news: FunSearch. It is yet another Nature paper by the DeepMind team, in this case adding some large language models into the mix. Let’s see how it works!
We now come to the actual result that motivated me to write this post. In December 2023, DeepMind researchers Romera-Paredes et al. published a paper called “Mathematical discoveries from program search with large language models”. They proposed a relatively simple way to use large language models to guide the search for new mathematical results, not in the form of actual results like most researchers have done before but in the form of programs that could generate these results. It goes like this: given a problem specification,
Here is an illustration from the paper itself:
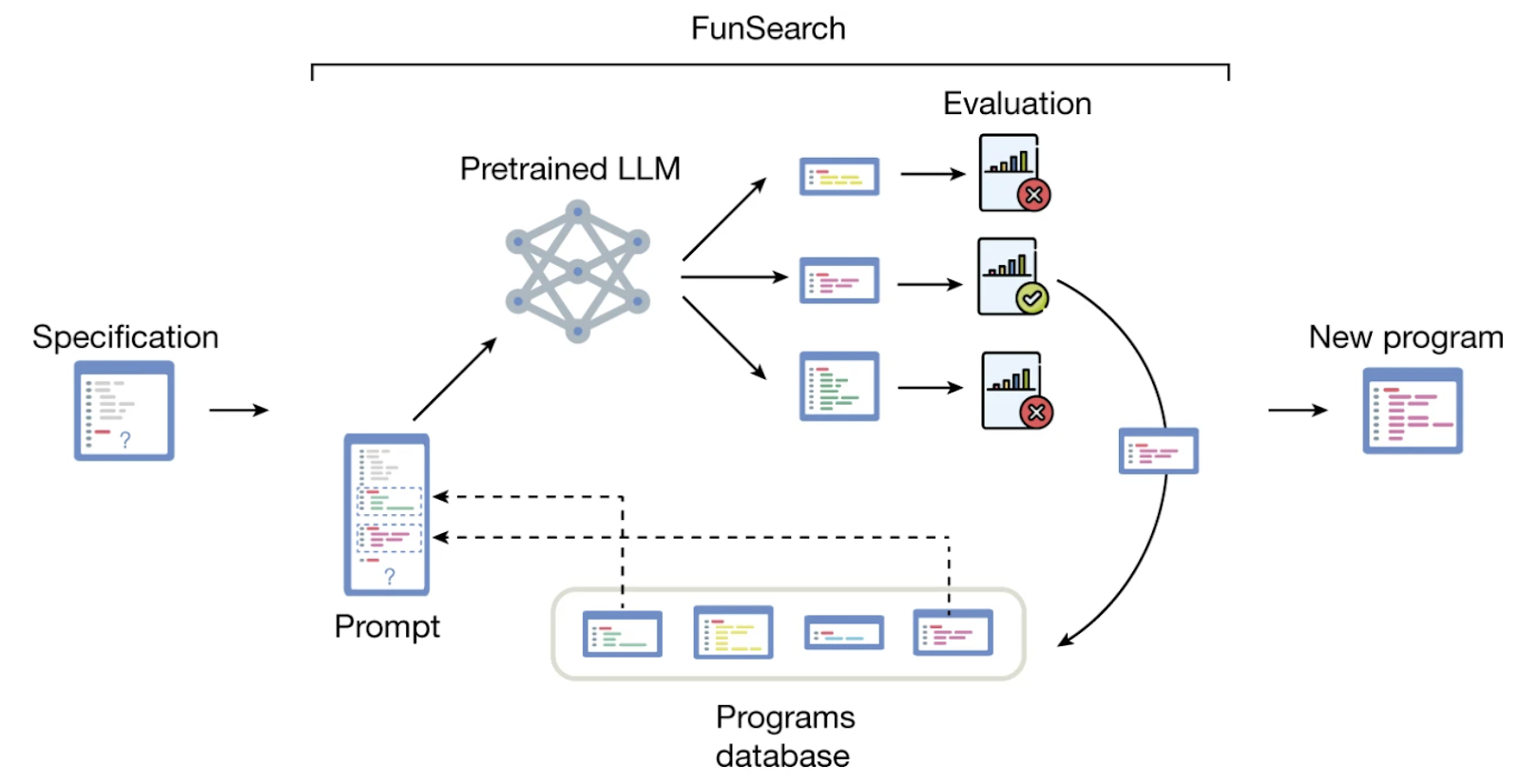
Specification includes an evaluation function that scores the solutions and a “solve” function that provides the barebone algorithm (say, a greedy search) and lets the LLM concentrate on the creative part (for greedy search it is the priority function that compares elements). Sounds pretty simple, and looks like it is: it is more of a prompt engineering result than a new machine learning approach.
So what could FunSearch do? One of the main results in this paper are new bounds for the cap set problem. Fields medalist Terence Tao, by many accounts the best mathematician alive, once called it “perhaps my favourite open question”, so let’s dive into the problem a little bit.
A cap set is a set of numbers in a finite field that does not contain nontrivial arithmetic progressions, i.e., where no three points form a line in the finite geometry of F3n, where F3 is the field of three elements… I started out on the wrong foot, didn’t I?
There is a much more accessible description of what’s going on in the cap set problem. You’ve probably heard of the card game “Set” where players need to shout out “Set!” when they see three cards such that for each of the four attributes—number, color, shape, and shading—the three cards are either all the same or all different. In the example below (taken from here, as well as the general idea of this connection), on the left you see two examples of sets, one where no attribute matches and another where almost all of them do, and on the right you see a sample Set board layout with one set highlighted (are there more? see for yourself):
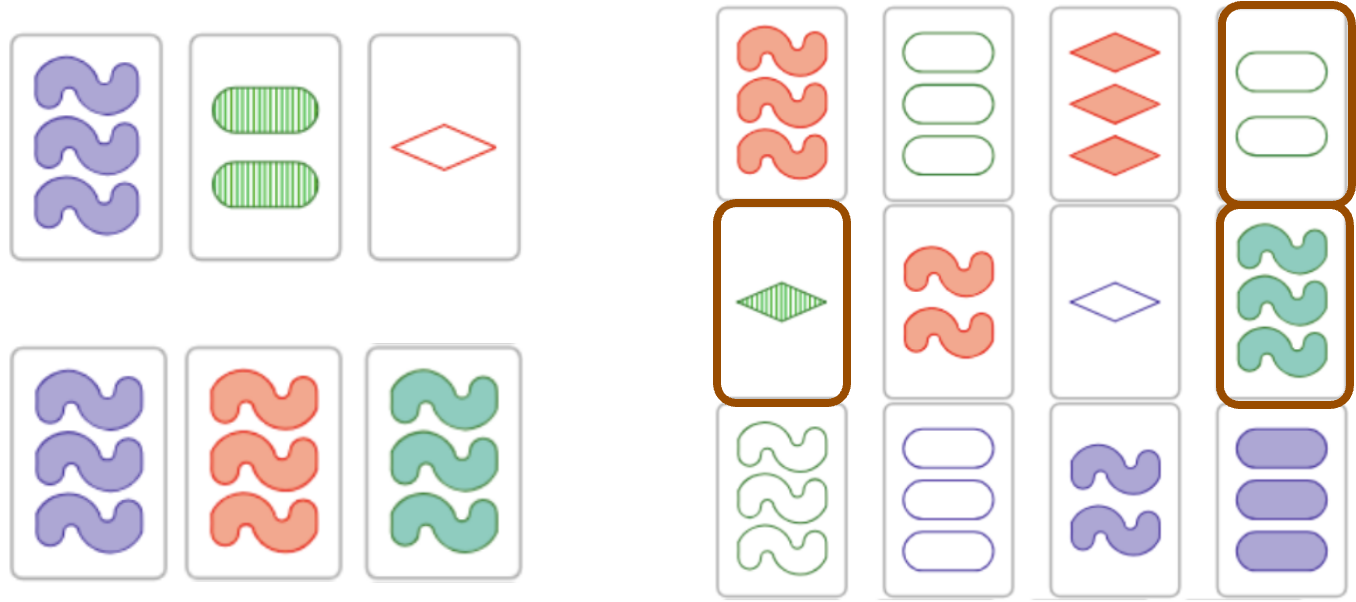
In these terms, a cap set is a collection of cards that contain no sets, and the main question is this: how many cards can you lay down so that they contain no sets? For the original game of Set, the answer is known: back in 1971, Giuseppe Pellegrino proved that there exist collections of 20 cards without a set, but 21 cards always contain one (note that this result predates the invention of the game in 1974, so if there is any connection, the causality here goes in the opposite direction). But in mathematics, you always ask the more general question. Here, we generalize the number of attributes: how many cards with n different attributes (instead of 4 in Set) can you lay down without a set of three cards?
It is obvious that you can have 2n cards without a set: just pick two values for every attribute and use only cards with these attributes. It was proven in 1984 that the upper bound is asymptotically less than 3n, actually at most O(3n/n). For over 20 years, the gap between these two results remained a glaring hole in combinatorics; in fact, closing this gap was what Terence Tao called his “favourite open question” back in 2007.
Important progress was made in 2016 when Ellenberg and Gijswijt used the method developed by Croot, Lev, and Pach to reduce the upper bound to 2.756n; it is telling that both papers were published in Annals of Mathematics, the most prestigious venue for publication in pure math. Since then, there has been no improvement in the exponent for either lower or upper bound.
So what did DeepMind do with the problem? Fun search could provide a new upper bound on the cap set problem for n=8, i.e., it could produce a larger collection of Set cards with 8 different attributes and no sets on board than ever before.
Here is a general illustration where in the top middle we have an illustration for the cap set problem in terms of finite geometry (colors denote lines in F33), on the bottom we have the FunSearch results with a new record for dimension 8, and on the right you can see the program that generates this solution:
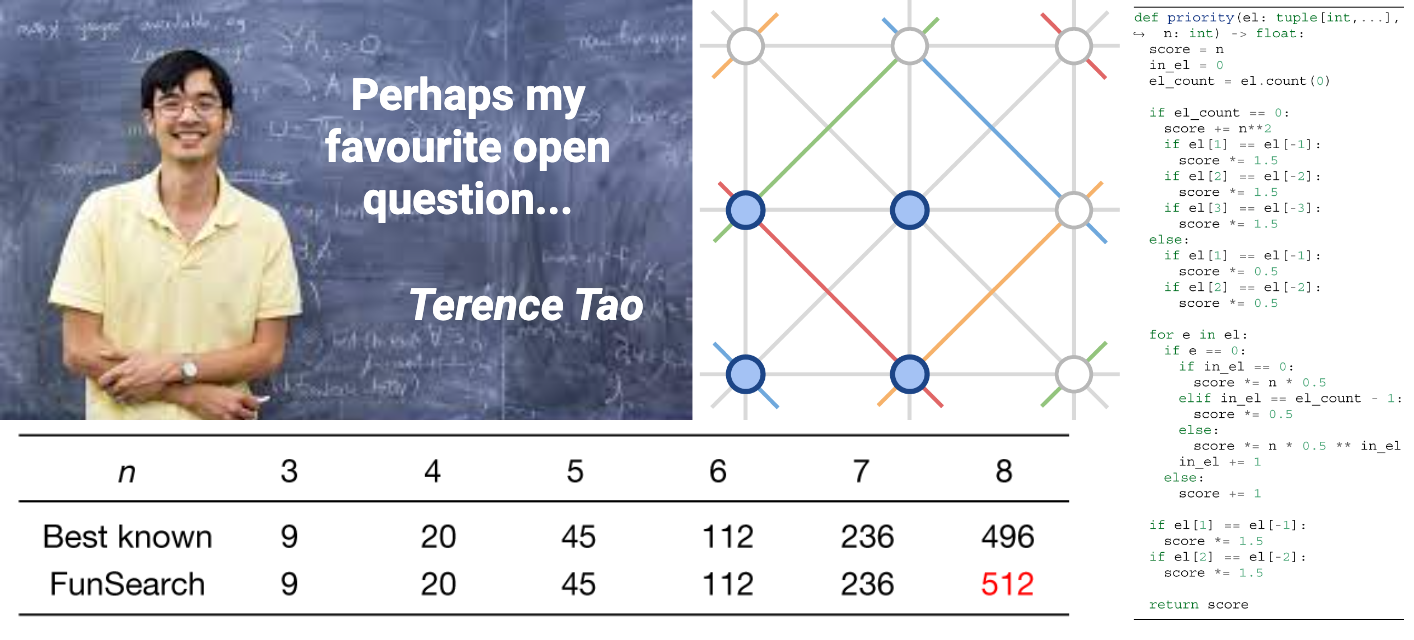
The program is virtually unreadable, and we will not analyze it here, of course, but it is still important that it’s a program, not just an answer in the form of a cap set. By analyzing this program, mathematicians can gain some insight into how this counterexample is structured; Romera-Paredes et al. did just that and could indeed understand the result better and relate it to other known examples in combinatorics.
Still, all this sounds a bit underwhelming: looks like FunSearch is still just searching for counterexamples, like countless helper programs for mathematicians before. It is still unclear when we are going to have a program that actually does new math in the form of proving theorems.
Today, we have discussed the main avenues for how AI can help mathematicians:
But if we put all this together, we basically get the full picture of making mathematics. Let us go back to the picture I started with, the general workflow of a professional mathematician, and put some of the papers and tools we have discussed in their proper places:
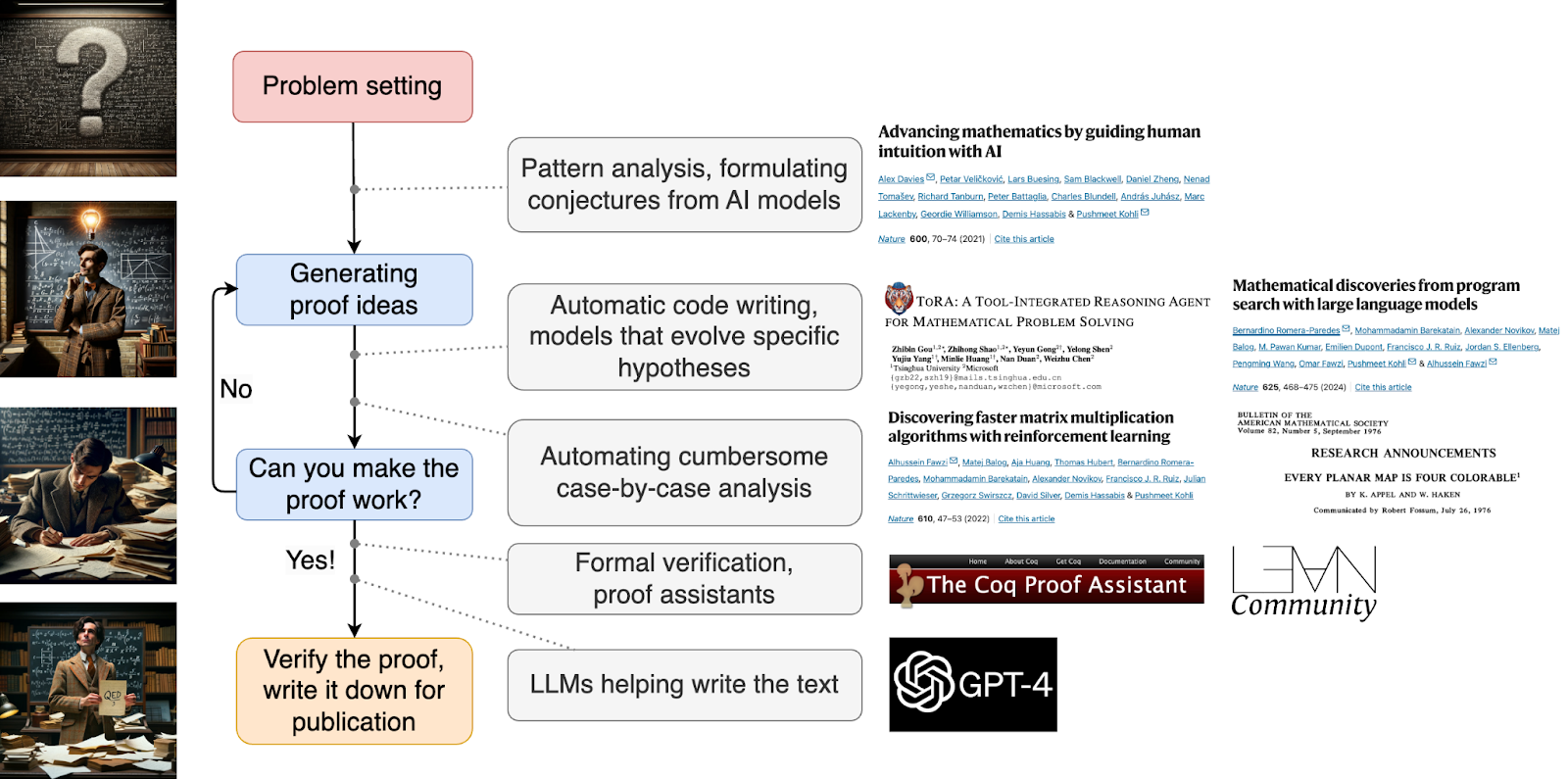
As you can see, AI is already helping mathematicians every step of the way, so maybe the “unreasonable ineffectiveness” I started with is not so ineffective after all. Still, it looks like doing math formally is hard, and so far the latest AI research can help somewhat, but only so much; there is no silver bullet that would just short-circuit the whole workflow and replace human mathematicians entirely. But we have also seen that doing formalized mathematics is hard for people too, even with the help of computers, so maybe there are deeper reasons here too.
On the other hand, AI progress is very fast right now. Two weeks after FunSearch, another DeepMind paper appeared in Nature: Trinh et al.’s “Solving olympiad geometry without human demonstrations”. They present a system able to successfully solve geometry problems from the International Mathematical Olympiad at nearly a gold medalist level; geometry problems virtually always require formal proofs, and IMO problems usually require quite ingenious ones.
Note also that Nature has a very fast but nontrivial review cycle: the IMO geometry paper was submitted in April 2023, and the FunSearch paper was submitted in August 2023; this is more than half a year of progress already made since these results, and in 2023, half a year counted for a lot. So just like in most other fields, we probably won’t be expecting a really working theorem prover right until it appears.
And finally, I would like to take this opportunity to dedicate this post to my first research supervisor, Professor Nikolai Vavilov (not to be confused with his ancestor, the famous geneticist Nikolai Vavilov), who was a key figure in modern algebra, founded a thriving research school, wrote several very interesting textbooks, and lit up every conversation with his wit and erudition. I owe Nikolai Alexandrovich a lot in my mathematical upbringing. Tragically, Prof. Vavilov passed away last September.
Sergey Nikolenko
Head of AI, Synthesis AI
