
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
One of the most striking AI advances this spring was OpenAI’s Sora, a video generation model that sets new standards for video consistency and diversity. Interestingly, the official report on Sora is titled “Video generation models as world simulators”. It notes that Sora has emerging simulation capabilities and is on a “promising path towards the development of capable simulators of the physical and digital world”. Today, we discuss world models in modern artificial intelligence: what they are, how they have progressed over the last few years, and where they may go in the future.

Generally speaking, a world model is an engine that predicts how the environment will respond. The “environment” here may be used in the technical sense of a reinforcement learning environment that gives out rewards and moves the agent to the next state. It could also mean predicting new sensory input for the agent, even when the connection with rewards is unclear.
In my opinion, it is reasonable to assume that world models inevitably arise when we pose sufficiently hard problems for AI models. It is almost obvious that a robotic agent operating in the real world should have some model of how the world responds to its actions. More surprising, however, is how far we can go in reinforcement learning without explicitly modeling the environment, simply by learning from experience. This approach, called “direct RL,” includes algorithms that learn value functions (e.g., Q-learning) or policies (e.g., policy gradient) and underlies many, if not most, applications of RL.
But these days, we are often talking about world models arising in large language models; it may seem very surprising given that all they do is predict the next token of a text string (we discussed the basic language modeling task here and here). How can something like a “dream world” arise from solving a straightforward classification problem over the dictionary tokens?
Consider the variety of problems that can be embedded into language modeling. Languages were created to describe the world, and indeed, you can frame anything in the world as continuing a string of tokens: solve a math problem, invent a recipe, describe the path out of a labyrinth, develop characters… Suppose that we ask the LLM to continue the last chapter of a detective story, when the sleuth is about to reveal who had actually done it. To have a reasonable assumption, the model will have to collect the clues from the context of the whole novel, just like a human reader would do:

(Sorry for spoiling one of the most important plot twists in the history of detective fiction.) In fact, human readers usually don’t succeed in predicting the murderer, and modern LLMs probably would not succeed too much, even if we use methods discussed in our previous post to extend the context window to the whole book.
The idea still stands: a “perfect LLM” would have to contain a “true world model” that would be able to reason about the world; that is what people mean when they say that language modeling is an AI-complete problem. But world models are far from limited to language modeling.
In the rest of the post, we will cover several different results that I would call different kinds of world models as used in deep learning and different aspects of world models. In particular, we will see:
We all possess world models. This is a self-evident fact, and thousands of pages written on the hard problem of consciousness accept that humans have direct access to an introspective mechanism. This mechanism allows us to reason about the world, emulate possible scenarios that can arise in response to our actions, assess their desirability, and act accordingly. For example, you know that if you loosen the grip on a cup of coffee, the cup will fall to the ground and spill everything, possibly shattering in the process. Therefore, even when you mistakenly pick up a hot cup the wrong way, causing it to burn your hands, you don’t drop it as immediate pain would suggest. Instead, you carefully place it on a table and pick it up by the handle to avoid further pain, but also prevent spilling coffee:

This is an impressive amount of physics and planning! How did we learn all that stuff?
Certainly not from teachers in school or parents explaining how cups of coffee work. We will discuss Yann LeCun’s take on world models (LeCun, 2022) below; for now, let me quote one chart from his paper that deals with infant development:
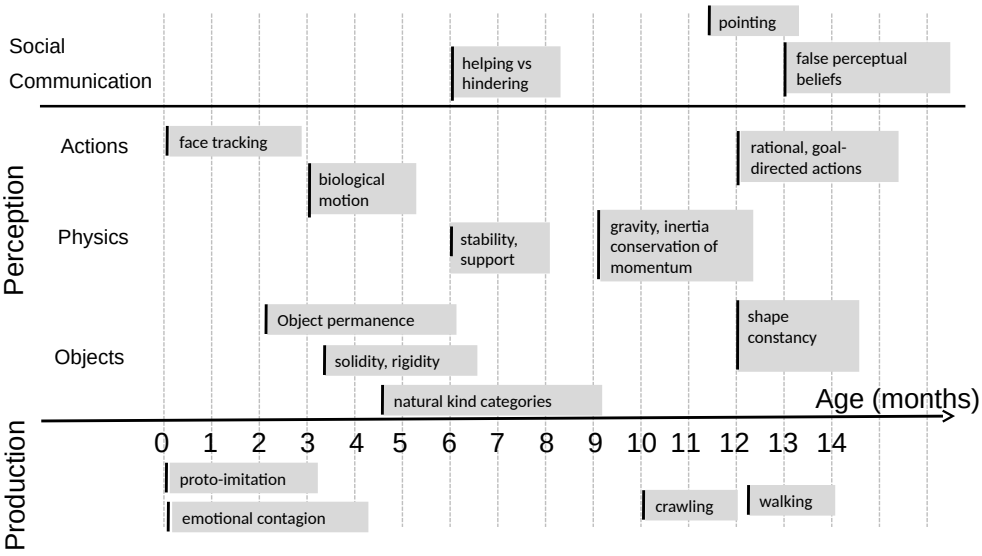
As you can see, children learn some pretty complicated concepts at a very young age, when it is clear that the learning cannot come from direct supervision (language and detailed communication with other humans comes much later), and just saying “imitation” also doesn’t explain much. In particular, they learn the so-called “intuitive physics”, which is just what we would mean by a world model: object permanence, properties like solidity, gravity and momentum.
Note that even just understanding visual inputs is pretty difficult! Our eyes work pretty similar to a camera, registering what is basically a set of pixels at the retina. However, our eyes move constantly in saccades, which are about 200 milliseconds long. This means that pixels change entirely about five times per second, and the visual cortex needs to establish connections between all of these images and provide our internal decision making mechanism (whatever that is) with a streamlined continuous representation of the world around us.
How do we learn all this stuff? This is a big question that does not have a clear answer. But I want to highlight one theory that is gaining traction in neuroscience: predictive coding (see, e.g., Sprevak, 2021). The idea is that everything that the human brain possibly arises from trying to predict the next set of stimuli (picture from Stefanics et al., 2014):
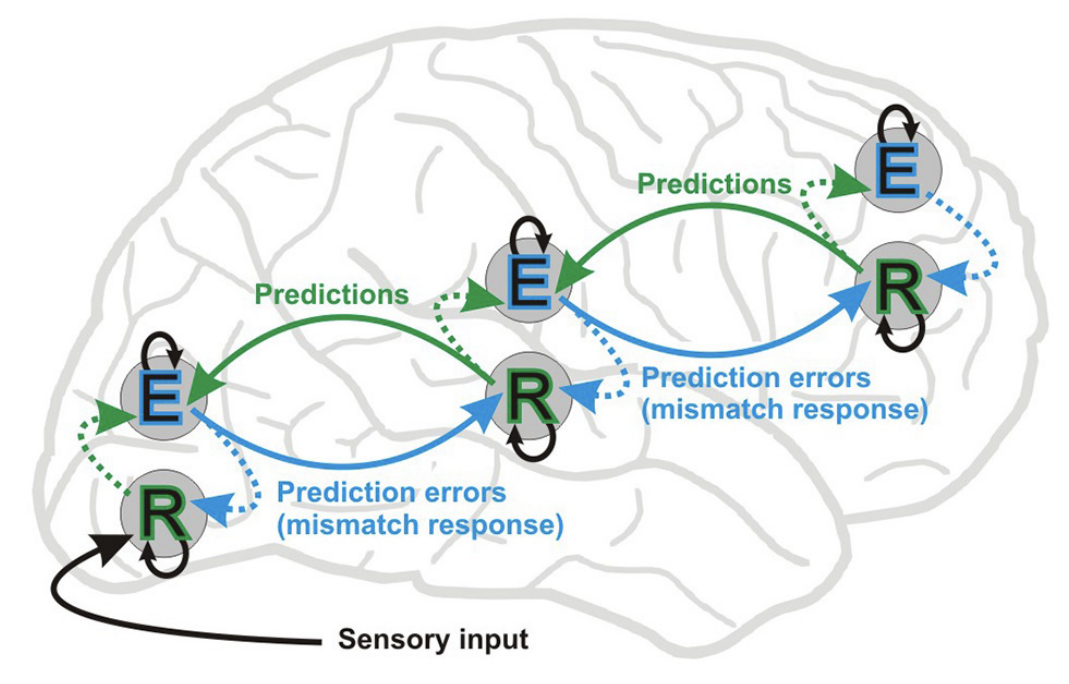
According to predictive coding, the brain is mostly doing representation learning, compressing sensory inputs into latent representations that can be used to predict next sensory inputs. Just like a language model, always predicting the next token! And if there is a mismatch between what it predicts and what it actually sees, the neural connections learn to predict better. Just like neural networks, always minimizing prediction error (not by gradient descent, though)! There are even rather compelling reasons to suggest that the brain is doing approximate probabilistic inference; this is known as the “Bayesian brain” hypothesis (Chater, Oaksford, 2008).
This theory has its own problems, but it quite possibly might be true. If so, resemblances with LLMs are uncanny: by predicting next “tokens” (sensory inputs), our brains develop a world model and even consciousness and first-person experience (whatever that means). Naturally, LLMs and other generative models are not quite there yet; for example, DALL-E currently does not support object permanence across different queries, so the cats and cups in my illustration above are all different; here’s hoping GPT-4o will fix that (see “Geary the robot” here).
But it looks quite possible that the route to general intelligence and even consciousness lies through building a world model, which in turn can be achieved by predicting the next sensory input, whatever the actual hardware. Naturally, we have no guarantees or even projections about whether a future LLM will be able to achieve it, but to me, learning about the predictive theory of mind was quite a (pardon the pun) mind-blowing discovery.
So with neurobiology out of the way (and as usual providing more questions than answers), let’s turn to world models in AI. We will go roughly in chronological order, culminating with our main reason for this post, OpenAI’s Sora. I won’t dive deep into the history of deep learning but in the beginning we go back to 2017, when OpenAI was just getting started…
For this section on early precursors of world models, I could choose any of a large number of works with similar analysis. But it seems interesting to note that in a way, OpenAI was born out of research precisely about world modeling.
In a 2017 paper, when OpenAI was less than two years old, Alec Radford et al. used unsupervised learning on large text corpora to solve the sentiment analysis problem, i.e., find out whether a given product review is positive or negative. Sentiment analysis had been (and still is) an important benchmark for text understanding: it is formulated as simple classification but may require deep understanding of the text (up to, e.g., understanding sarcasm), and relatively large datasets such as Amazon Reviews had been made available long ago.
In 2017, Transformers were not yet invented, so Radford et al. trained a variation of an LSTM (a standard recurrent architecture, see, e.g., here) as a character-level language model. This means that the model “reads” a text prompt and predicts its next character (rather than a word-level token, as modern LLMs do); this can be done in a completely unsupervised way, you don’t need to have sentiment labels to train a language model.
But the interesting part was that in the latent representation learned by the model (it was a vector of dimension 4096), Radford et al. found a specific component (cell, “neuron”, call it what you will) that was responsible for sentiment! Moreover, if you fix the value of the “sentiment unit” and generate new reviews, their tone will come out just as you would expect. Here are a couple of illustrations from the OpenAI paper; on the left you see the activations of the “sentiment unit” on a sample movie review, and on the right, generation results with fixed sentiment:

In this work, we have two important components:
So in a way, that was already a “world model”. This kind of work has been an important part of the AI interpretability field, and important progress is still being made, most notably the (very) recent work by Antropic (Templeton et al., May 2024) that we may discuss in a future post separately.
But these ideas are a little different from the main emphasis of this post and, generally, what we mean by world models nowadays. Let us move on and see how our current understanding came into being.
There is a well-known meme in AI research circles: one of the fathers of modern AI, a prominent German researcher Jürgen Schmidhuber, loves to explain in his talks how he and his team pioneered many ideas that are foundational to modern AI. While some researchers believe he occasionally oversells his past results (see the corresponding Wikipedia article section), quite often he is indeed correct in his claims!
For example:
By the way, I also highly recommend Prof. Schmidhuber’s works on the history of deep learning; he cites many early works that I would never learn about otherwise (Schmidhuber, 2013; 2014; 2020; 2022).
So it is no wonder that in 2018, it was Jürgen Schmidhuber (together with Google Brain researcher David Ha) who again showed this superhuman sense for promising ideas, presenting a paper at NeurIPS whose arXiv version is called simply “World Models” (here is a GitHub version with interactive animations).
They present a simple idea: we humans have mental models of environments around us. So what if we train a network to learn an internal model of some, say, reinforcement learning environment such as a 2D car racing game (main example in the paper)? The model is similar in design to a language model: it learns an internal representation for frames from the environment via autoencoding and learns to predict the next frames.
This allows the model to plan, just like the RL agents above; then a separate controller model can use the internal representations that have been created with this planning in mind to choose the best action. Here is an illustration by Ha and Schmidhuber:
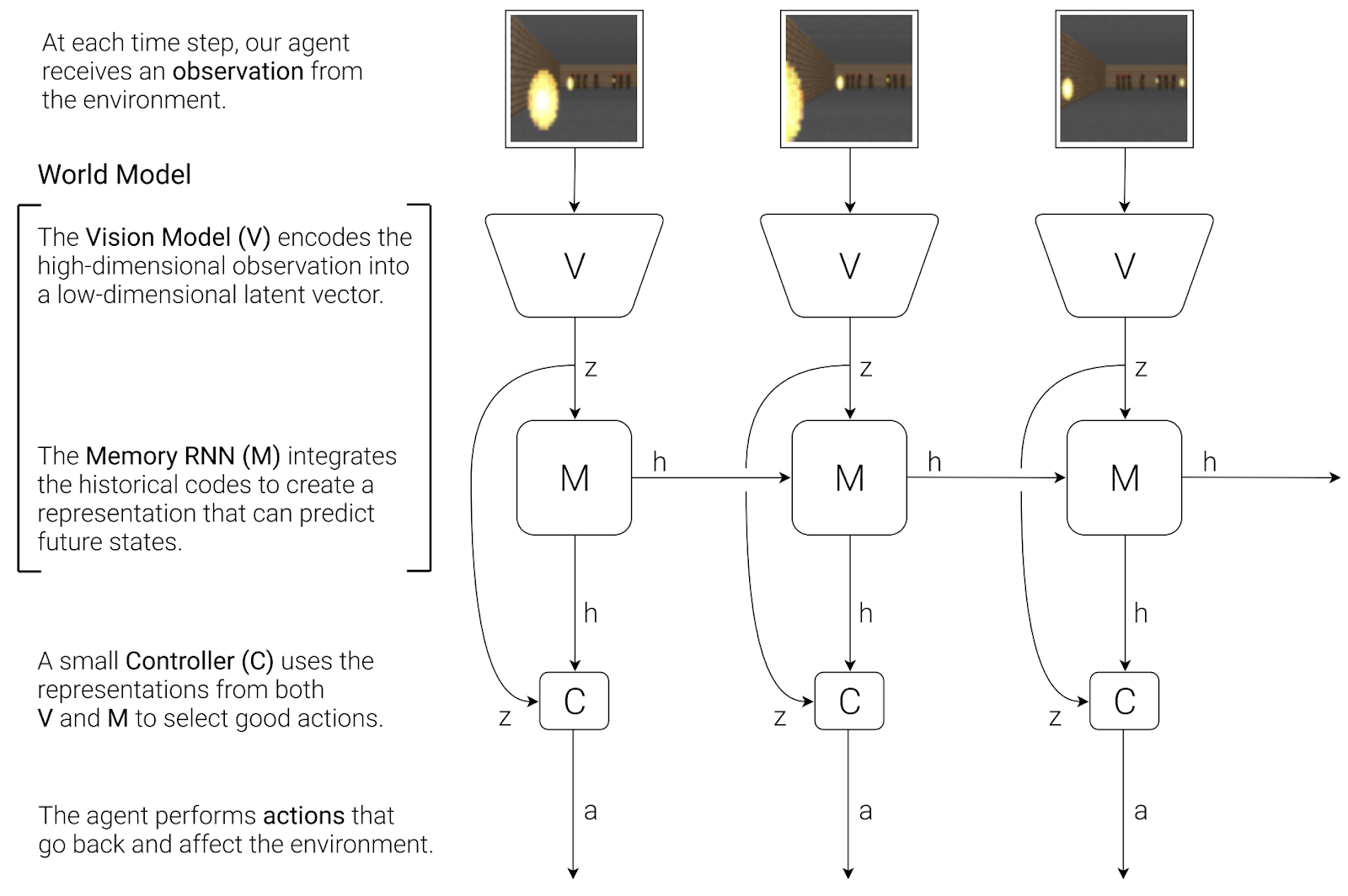
The authors show how world models improve agent results in this racing game and in another standard RL environment, a simple Doom level where you need to navigate away from fireballs. Here is an illustration from the paper that shows a reconstruction of how the agent imagines the environment – pretty close to the real thing, and quite enough to be able to learn on your dreams:

This work was one of the first to show a full end-to-end system with a world model in the form of a neural network learning the environment and helping the agent to act in this environment by providing useful representations for the states. In the next section, we will see a way to go further and use the world model to actively do planning in an environment rather than just feature extraction.
DeepBlue defeated Garry Kasparov in 1997, and Vladimir Kramnik was essentially the last human to play even matches against a computer in the early 2000s. Despite the long history of computer chess and its symbolic importance as a pinnacle of human intelligence, chess programs of that era did not resemble “true artificial intelligence” at all. They were primarily alpha-beta tree search engines with sophisticated position evaluation functions (this is where machine learning could contribute). AI needed a different testbed.
At the same time, the game of Go looked unassailable. Tree search does not work nearly as well there because there are far more reasonable possibilities on every step. At the turn of the century, the best computer Go programs lost to mediocre human professionals with enormous handicaps of 15-20 stones. The situation changed in 2007, when Remi Coulom revolutionized computer Go with Monte-Carlo tree search (MCTS), a method that constructs a tree of possible moves with multiarmed bandit algorithms helping to choose where to put the majority of “experiments”. But still, before AlphaGo beat Lee Sedol, the best Go playing models had been weak compared to professional players. I will skip AlphaGo (Silver et al., 2016) and go straight to AlphaZero here.
The idea of AlphaZero (Silver et al., 2017a; 2017b) is deceptively simple: on every training step, the model performs MCTS that can efficiently search a few moves ahead and thus improves the current policy (playing strategy). Previously, MCTS was used in decision time, to improve the current policy by refining its estimates of position values; in MCTS-based Go programs MCTS was often the only method, with no training at all.
AlphaZero’s idea was to use MCTS in training time and modify the policy with a gradient step towards a new policy improved by MCTS. The training algorithm always has a moving target: for the current policy π, AlphaZero constructs a new policy π’ by applying MCTS to improve π. Then π is improved with policy gradient algorithms to make it closer to π’—but now π’ is better yet, and the process can be repeated. In this way, the policy is continuously brought to new heights (illustrations a and b below are taken from the AlphaGo Zero paper):
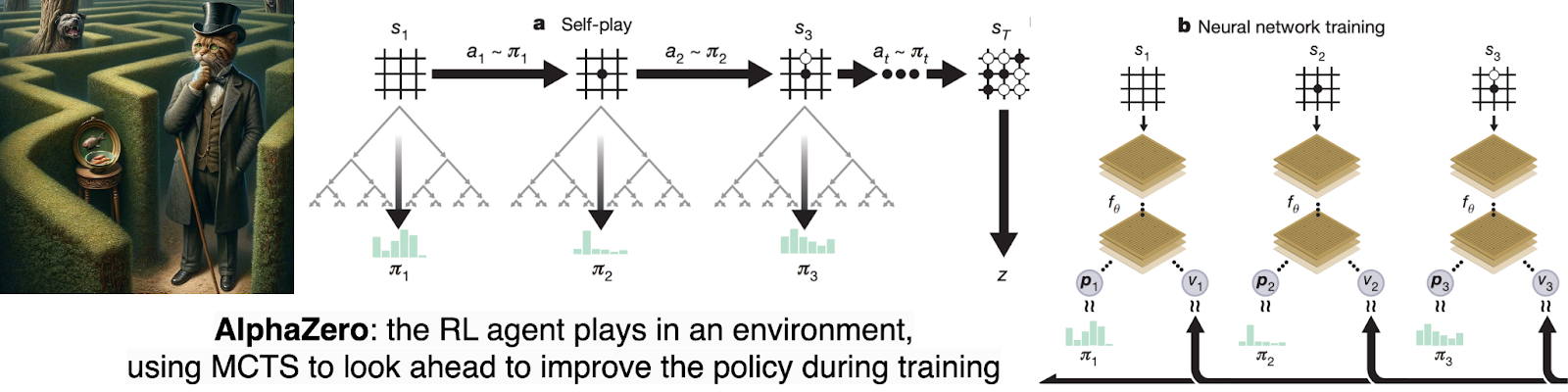
To do that, AlphaZero needs to be able to construct the search tree, which it does by self-play: during training, the agent is playing (an earlier version of) itself. But to run self-play, AlphaZero obviously needs to know the rules of the game. Note that it’s not the same as the model of a reinforcement learning environment since the latter also includes the opponent, but if you have an agent to run as the opponent then yes, this means you have a model of the RL environment.
For chess and Go, a perfect simulator of the environment is easy to construct: you are already learning an agent to play for each side, so you can use the current agent for Black to play against when you are learning to play White better, and vice versa. But for a richer domain, say for a computer game, it would be very hard to learn a simulator for the environment because apart from the agents it also would have to contain the game engine, and you cannot assume that a perfect copy of the game engine is available. And for an even richer domain, say for robotics, the “game engine” would include all of the relevant laws of physics — definitely not something we can assume away or easily learn.
Therefore, MuZero (developed by DeepMind researchers Schrittwieser et al., 2020) takes the next step: it does not need to know the rules, and it learns a model of the environment in a compressed form of hidden states. This representation learning allows the model to learn the environment dynamics in a model that predicts the dynamics of hidden states only, with no need to predict the whole huge state such as the pixels of a game screen. This hidden state is exactly what I would call a world model. Now MuZero can also do MCTS, but in this case the construction of subsequent states in the tree is produced by this “dream” about the latent representations, like this (illustrations a and c below are from the MuZero paper):
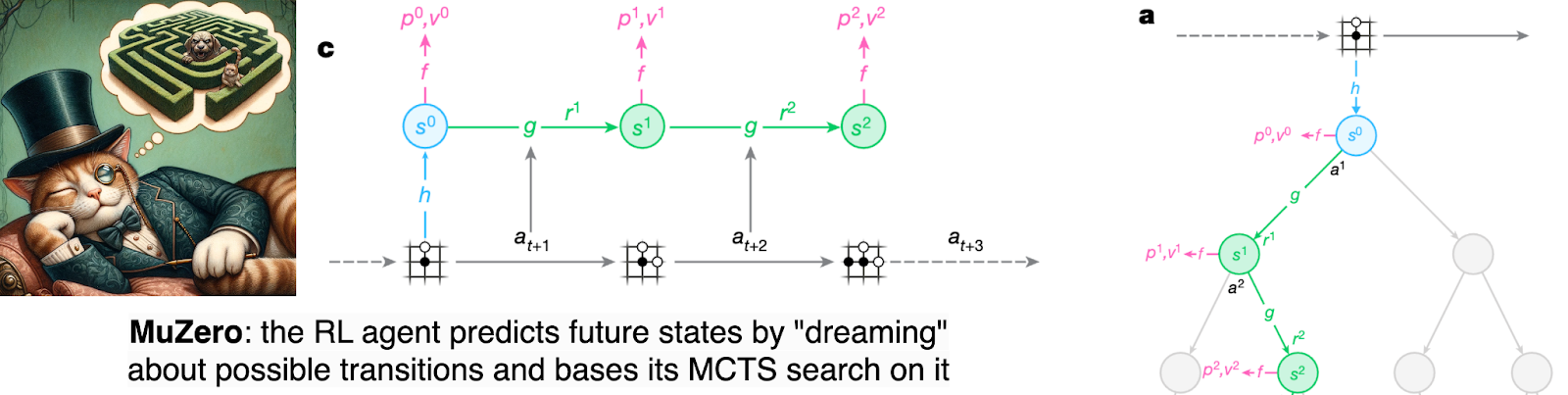
It is no wonder that MuZero was able to extend the success of AlphaZero to richer environments such as Atari games, outperforming the then-champion model-free RL algorithm called R2D2 (Kapturowski et al., 2018). What is interesting is that MuZero actually outperformed AlphaZero in settings where the rules of the game are known, reaching a higher Elo rating in Go and performing on par with AlphaZero in chess and shogi:
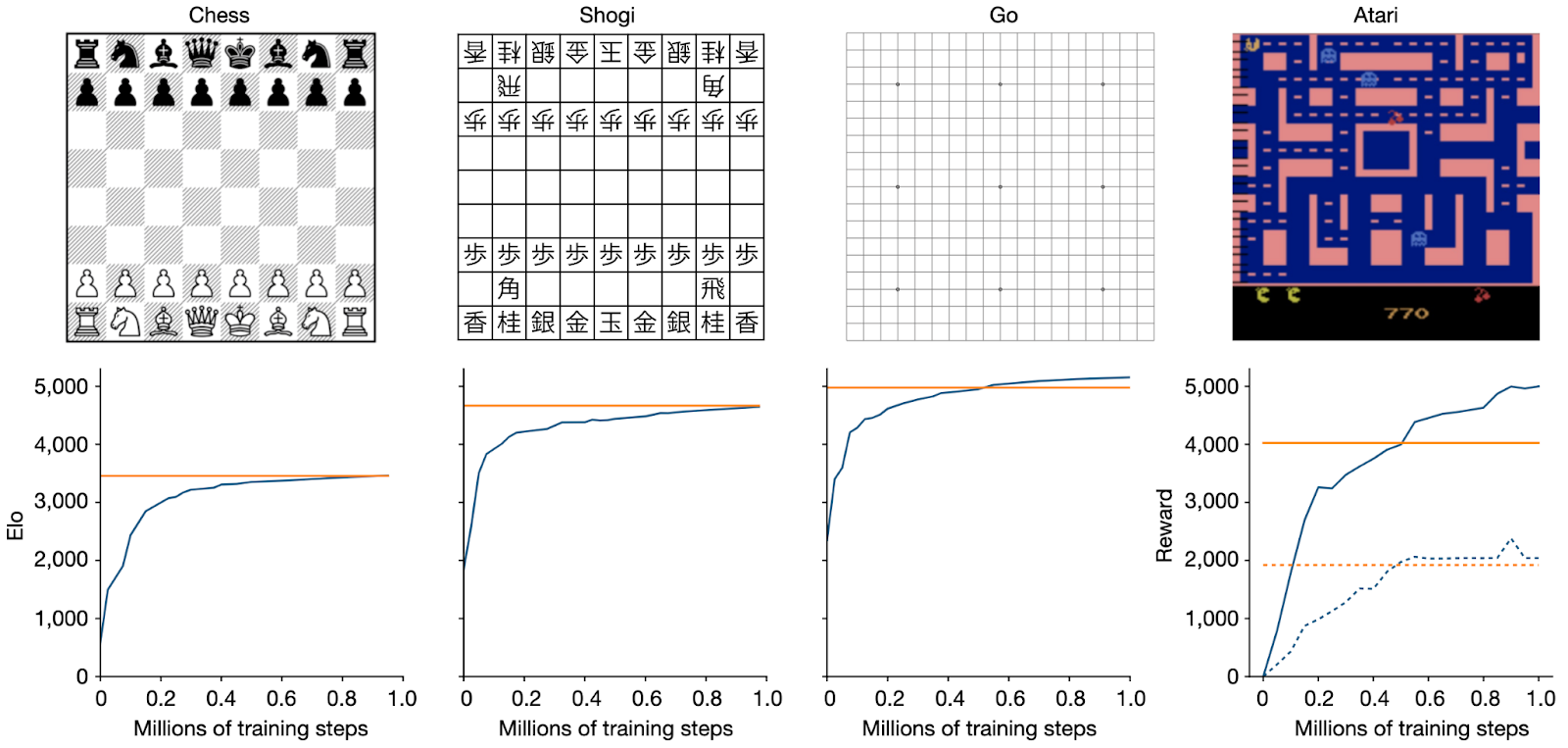
Schrittwieser et al. hypothesized that “MuZero may be caching its computation in the search tree and using each additional application of the dynamics model to gain a deeper understanding of the position” — in other words, the world model added to MuZero became a way to understand the game better than even AlphaZero’s masterfully learned feature extraction. It can focus on only the important features of the environment, abstracting away everything else because its world model does not have to predict all of the features.
This direction is being continued today. I want to highlight one more very recent approach by Alonso et al. (May 2024), called DIAMOND (DIffusion As a Model Of eNvironment Dreams), where a diffusion model serves as a world model for visual tasks such as playing Atari. In MuZero, the imaginary unrolling takes place in the latent space. In DIAMOND, the world model actually produces pictorial representations with a diffusion-based model. The diffusion process is conditioned on prior observations and action taken by the agent (illustrations from Alonso et al., 2024):

The motivation for this is that for many tasks, small details in the visual input—such as the ball position in Breakout or Pong or the color of a streetlight in an autonomous driving task—may have a drastic effect on the policy. And a diffusion model is a great way to capture visual representations:

So we see that world models have proven to be useful even in domains where they are not strictly necessary. What about the domains where they seem to be inevitable? What about, say, robotics?
Robotics generally relies on reinforcement learning (Sutton, Barto, 2018): an agent cannot have a sufficiently robust dataset of the physical world’s reactions in advance, it must obtain this dataset by trial and error. However, unlike AlphaZero and MuZero, which can play against themselves very efficiently, we can’t run a robot in the real world billions of times.
At this point, world modeling circles back to our main emphasis here at Synthesis AI, to synthetic data. You could say that Ha and Schmidhuber’s models were generating a synthetic representation of the world, and that MuZero was generating synthetic traces of gameplay, but there was an important difference: MuZero was doing it in its own latent space. There is no way to go back from the representation to a full-blown game state: you could train a decoder but it would probably be imperfect.
In robotics, synthetic data often takes the form of full-scale simulators that include the relevant laws of physics, material properties, and so on, aiming for a maximally accurate representation of the physical world. I will not spend much time on a review of such simulators here, but they have been surveyed, for instance, in my book “Synthetic Data for Deep Learning”.
We will get to using such simulators below, but in this section let us make a different point. The world model can be fully learned from experience, just like a human child does not obtain any external information except sensory inputs to the brain (kind of by definition) but still learns a world model with astonishing efficiency.
Researchers have attempted to replicate this with deep neural networks. One curious attempt was made back in 2016 by Agarwal et al. in a paper called “Learning to Poke by Poking”. They let a robot randomly interact with objects by poking them and seeing what happens; “seeing” here should be understood literally, the model is learning from visual input. Like this:
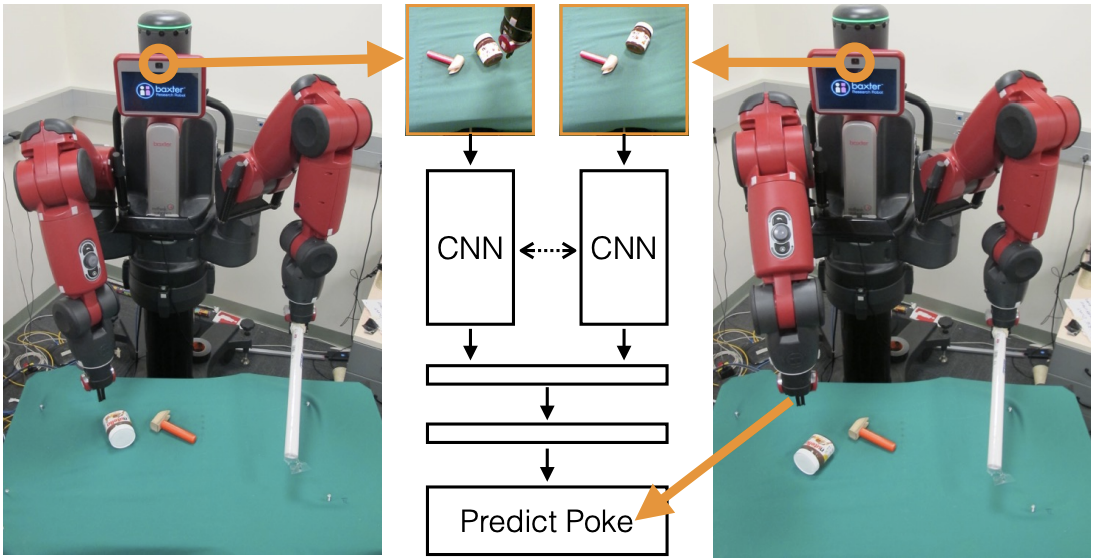
This approach did not take on, but it was developed a long time ago, and by now we have many new ideas at least for the network architectures, so it may be worthwhile to try again. In general, even though our current understanding of reinforcement learning makes it hard to learn a full world model in reality, where experiments are very costly, to many researchers this looks like the way forward.
Researchers like Yann LeCun, whose position paper called “A Path Towards Autonomous Machine Intelligence” argues for just that. LeCun suggests that truly autonomous agents should be built with learned world models. In a way, it is a natural extension of the actor-critic paradigm in reinforcement learning. In RL, the agent is learning a strategy π to produce actions in a state s according to the distribution π(a|s), and the environment responds by providing the immediate reward r and the next state s’:

In a general policy gradient algorithm, π is learned directly from experience (as shown on the left). In an actor-critic architecture, there is a separate component within the agent that learns a value function, i.e., the expected total reward an agent would obtain starting from a state s, V(s), or starting from a state s with action a, Q(s, a); this is shown on the right above. A critic helps the agent to refine its policy updates.
With a learned world model, the actor-critic interaction becomes much richer: now the agent is able to “imagine” potential responses of the environment and search for whole sequences of actions, just like MuZero, but probably without the same kind of search tree since now the actions might be very numerous or even continuous. Here is a picture from (LeCun, 2022) that shows how a single episode of the agent interacting with the environment would go:
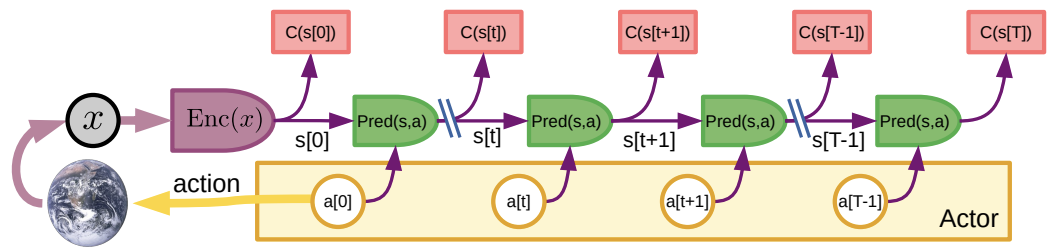
The sequence of actions here is entirely “in the mind” of the agent. Predicting a whole sequence of actions is probably quite expensive computationally, but once we have this prediction, we have a lot of loss function gradients to propagate: every step of the sequence can be compared with actual experience. So this approach can both help train better policies directly and also be used in a MuZero-like fashion to perform decision-time planning.
And with that, we come to our central point: what’s going on in OpenAI Sora?
Ideas similar to Ha and Schmidhuber (2018) continue to define what world models mean for AI. The latest addition to the formidable OpenAI roster of foundational models, the state of the art video generation model Sora, is explicitly designed around the idea of world modeling. Their technical report is titled “Video generation models as world simulators”, although the report only states that Sora “simulate[s] some aspects of people, animals and environments from the physical world” and does not give any hard facts to support this, so we will have to make our own conclusions.
Following OpenAI’s recent (quite understandable) practice of limited transparency, there is no detailed paper on Sora, only a rather vague blog post and report. Essentially, the only thing that is clear is that it is based on a Diffusion Transformer (DiT). While we have discussed latent diffusion models on the blog before, and covered diffusion models in detail, but I have not yet explained DiT here, so let me provide some context.
Introduced by Peebles and Xie (2022), Diffusion Transformers showed that the Transformer architecture can be useful even for a denoising element of a diffusion model. For instance, Stable Diffusion (Rombach et al., 2022) used a diffusion model to produce the latent code for a VAE-based decoder, and DiT also follows the same basic structure (the picture is copied from a previous post):
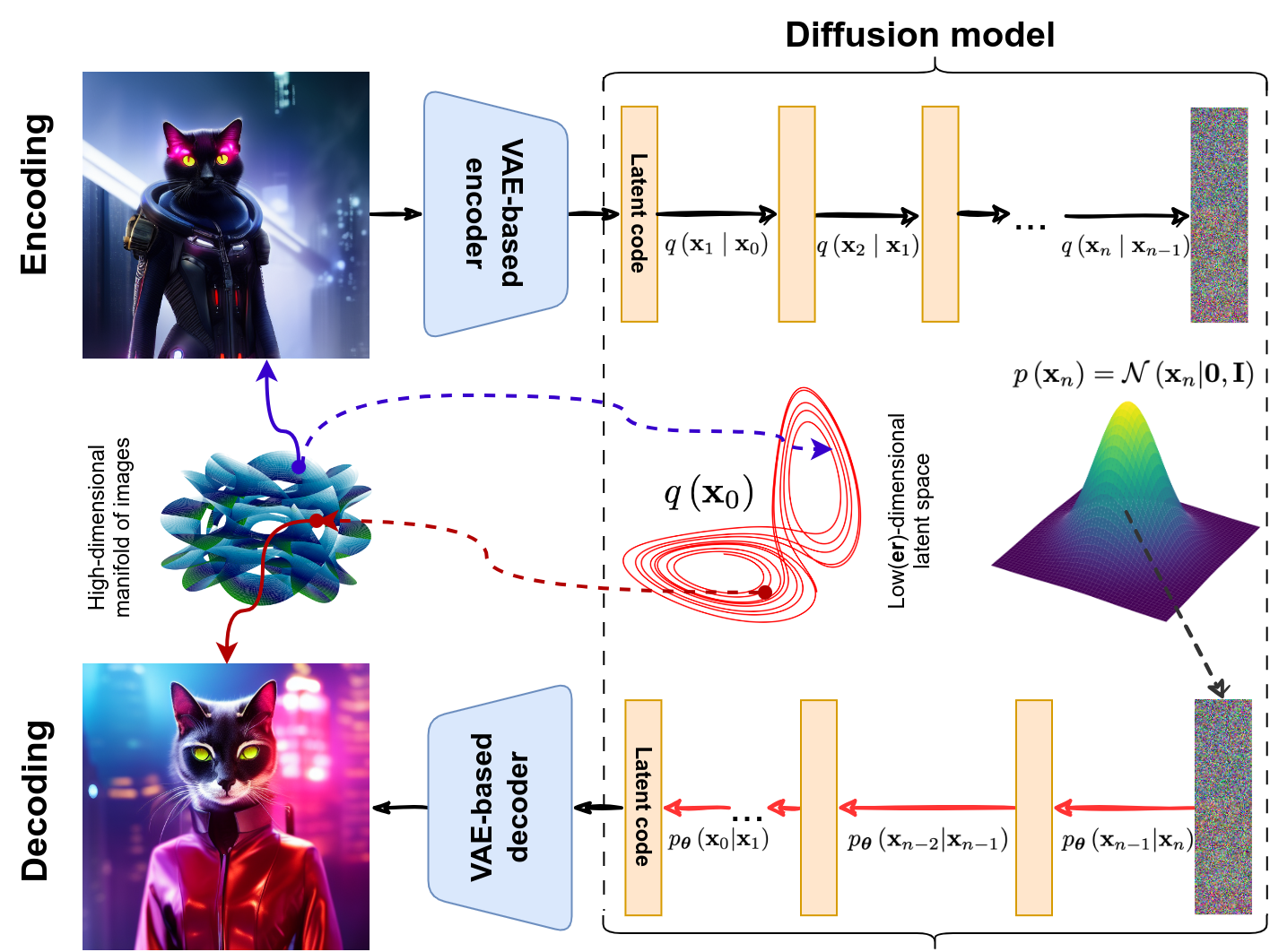
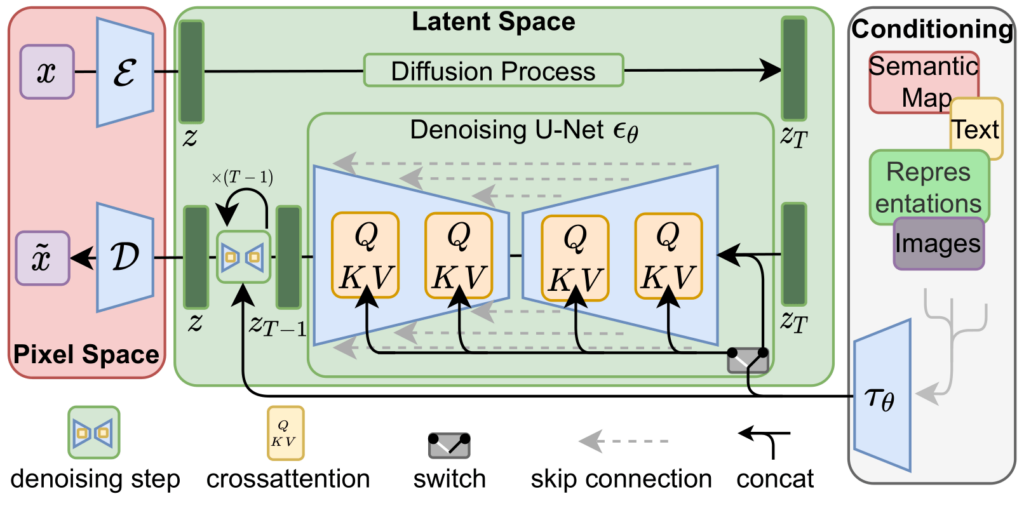
However, this picture does not show what’s inside the denoising blocks. Stable Diffusion used a U-Net-like architecture with cross-attention layers that effectively utilized the condition, yet retained a general U-Net structure (picture from Rombach et al., 2022):
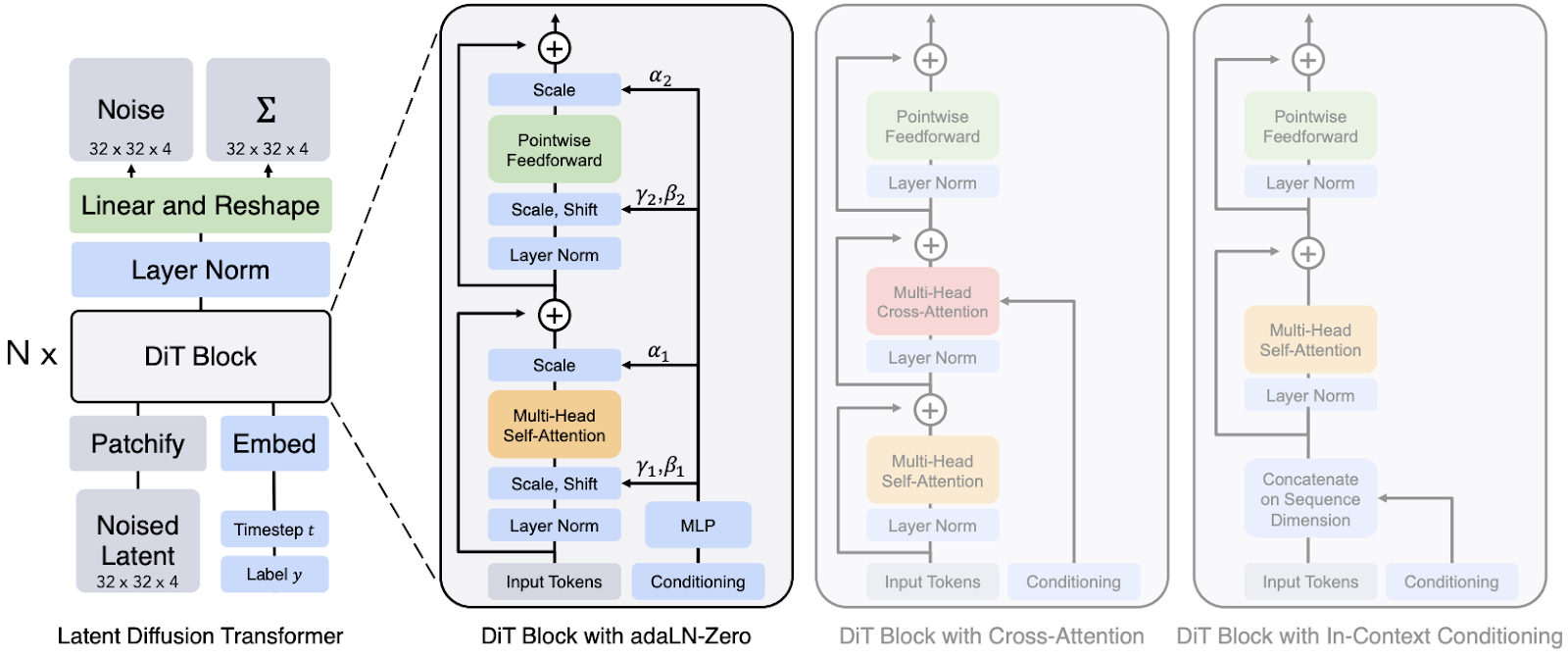
Diffusion Transformers use a “pure” Transformer block for denoising, with a neat trick of using the layer normalization block similarly to AdaIN (Huang, Belongie, 2017) style transfer blocks; illustration from (Peebles, Xie, 2022):
The resulting architecture proved to be much more compute-efficient than previously used U-Net-like diffusion models. In Sora, DiT is generalized to higher-dimensional patches that cover both space and time inside a video. Although the exact way it is done has not been revealed, there is at least one prior model, the GenTron by Meta researchers Chen et al. (2023), that adapts DiTs to video. Here is a generic illustration from the Sora report:

But I digress. Regardless of the model itself, Sora provides great video generation results that often exactly follow our intuitive understanding of physics, although sometimes they fail in that regard. Does this mean that Sora is at least halfway to the holy grail of learning an operational world model from raw video inputs?
At this point, let me link to a very detailed blog post by Raphaël Millière called “Are Video Generation Models World Simulators?”. It covers many of the points that we are going through here, and I recommend it in its entirety. In particular, Dr. Millière considers several definitions of a “world model” and carefully studies whether Sora is likely to fit any of them. His conclusions, which I fully endorse, are as follows:
To me, this is an interesting discussion (and a great post, please do read it!) but these conclusions slightly miss the point. Of course a deep learning model does not have an internal physics engine unless one is artificially attached to it (see below). You and I, however, may not have one either!
Again, I can only recommend reading through the section by Dr. Millière on “intuitive physics”: human infants learn to expect certain physical properties very quickly, and there is a well-established “IPE hypothesis” that posits the existence of an “intuitive physics engine” in our minds. But even for humans, it’s just a hypothesis, and there is an opposite opinion that human physical reasoning is based on visual shortcuts and generally predicting what we will see next rather than approximating the relevant laws of physics.
For Sora and similar models, this hypothetical intuitive engine is even harder to believe in. Some examples generated by Sora clearly violate even our basic intuitions like object permanence or collision properties, which is, of course, expected from a diffusion-based generative model, but not really expected from a physics simulator, however “approximate” it is:

The question for me here is: does it really matter? We humans probably don’t have a built-in Unreal Engine to tell us how the world works. But we have an intuitive understanding of the world that allows us to make predictions, and these predictions are accurate enough for most practical purposes. Sora is not quite there yet, but if some upcoming Sora 2 or Sora 3 does have a similar understanding, it will be enough to disallow videos with such internal contradictions.
Still, this may sound like a lot of work for naught. Why should we wait until some latent representation learns to approximate Unreal Engine 5 from scratch when we already have Unreal Engine 5? Indeed, there have been attempts to combine machine learning models with external tool calls to world simulators; let’s discuss them before we conclude the post.
Even with all the RLHF fine-tuning and other advanced techniques, large language models primarily train as their name suggests: by predicting the next token of text. By default, they don’t have access to external tools like calculators or physics engines, and learning exclusively from text can lead to simple mistakes in this context.
In other words, a large language model, no matter how smart, is akin to a medieval scholastic thinker who derives knowledge exclusively from Aristotle but cannot conduct experiments or use empirical evidence. It would make a lot of sense to let an LLM call some external tools that would provide this evidence to use in the LLM’s reasoning and to inform its replies. This is called grounding, and it is indeed known to be a good way to improve LLM results:

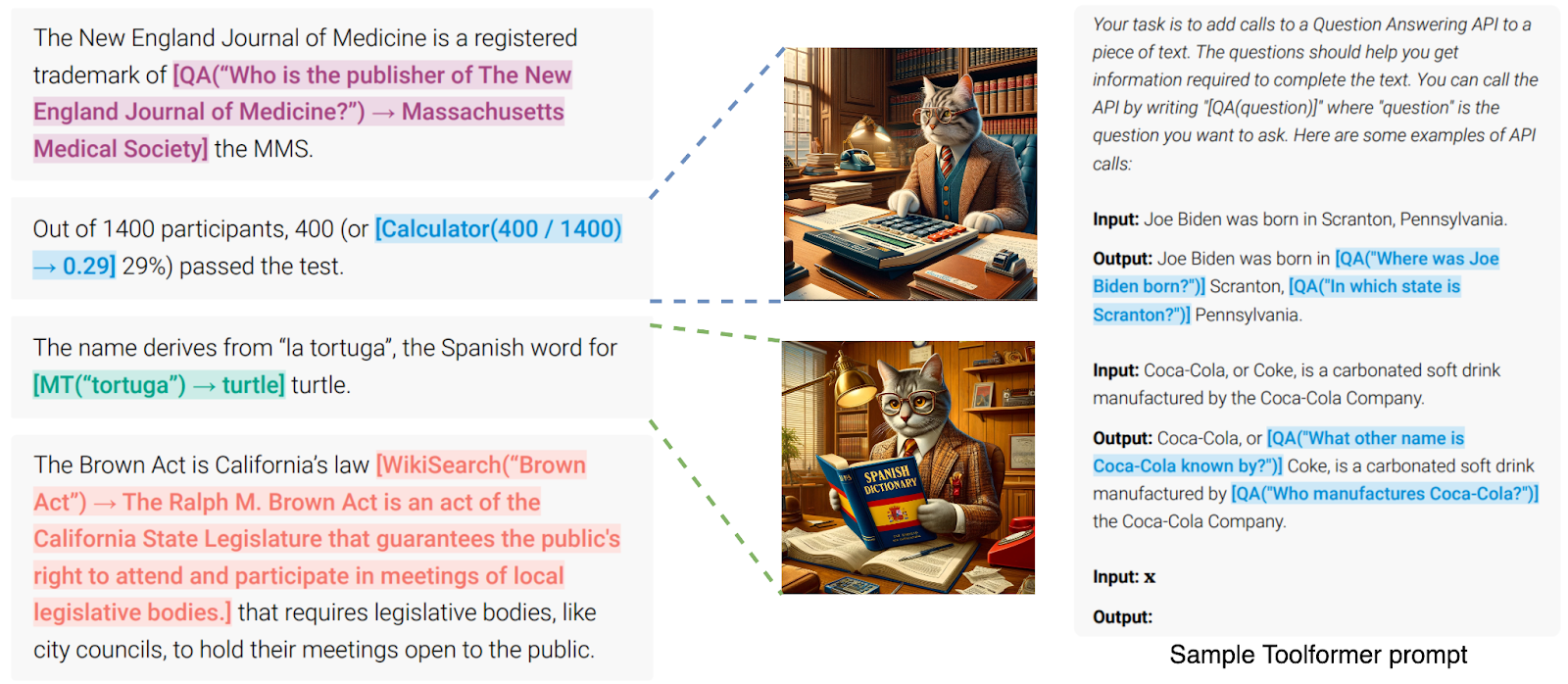
For example, one significant result along this way was the Toolformer approach (Schick et al., 2023), where an LLM learns to use a new tool from a brief description of its API. As a result, the LLM can access a wide variety of tools and learn new ones on the fly (examples from Schick et al., 2023):
And yes, there already exist approaches that ground LLMs with “more real” world simulators to help them reason about our physical three-dimensional world.
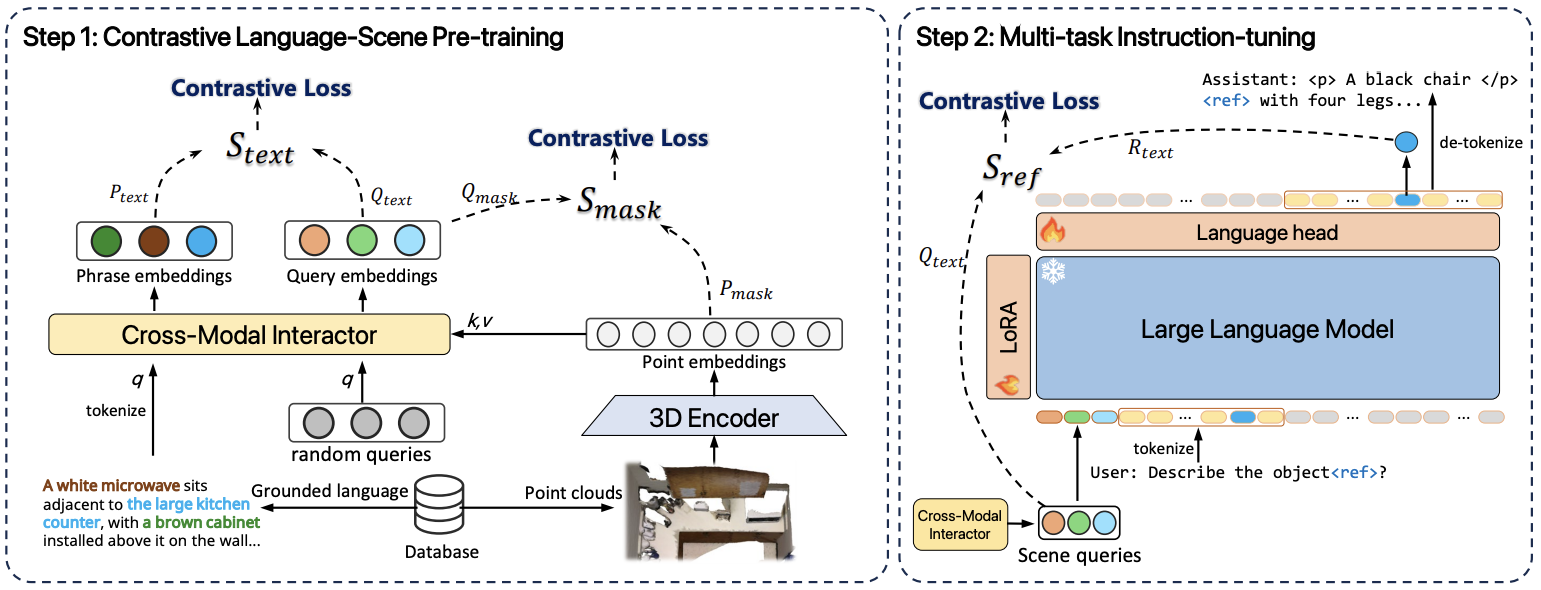
For example, the recently developed Grounded 3D-LLM (Chen et al., May 2024) adds special referent tokens that correspond to objects in the 3D environment where the LLM is planning some actions:

Its 3D point cloud encoder is trained with a cross-modal pretraining procedure based on contrastive losses, similar to CLIP (OpenAI, 2021; see also our earlier post), and the LLM is fine-tuned with LoRA to understand how to work with referent tokens:
The work nearest to our current discussion was done by Liu et al. (2023) from Google Research. They recognize the problem of linguistic reasoning in the physical world and develop an approach called Mind’s Eye that lets an LLM to query a computational physical engine, in this case DeepMind’s MuJoCo (Todorov et al., 2012).
The LLM writes rendering code and runs the external physics engine, informing its output with simulation results:
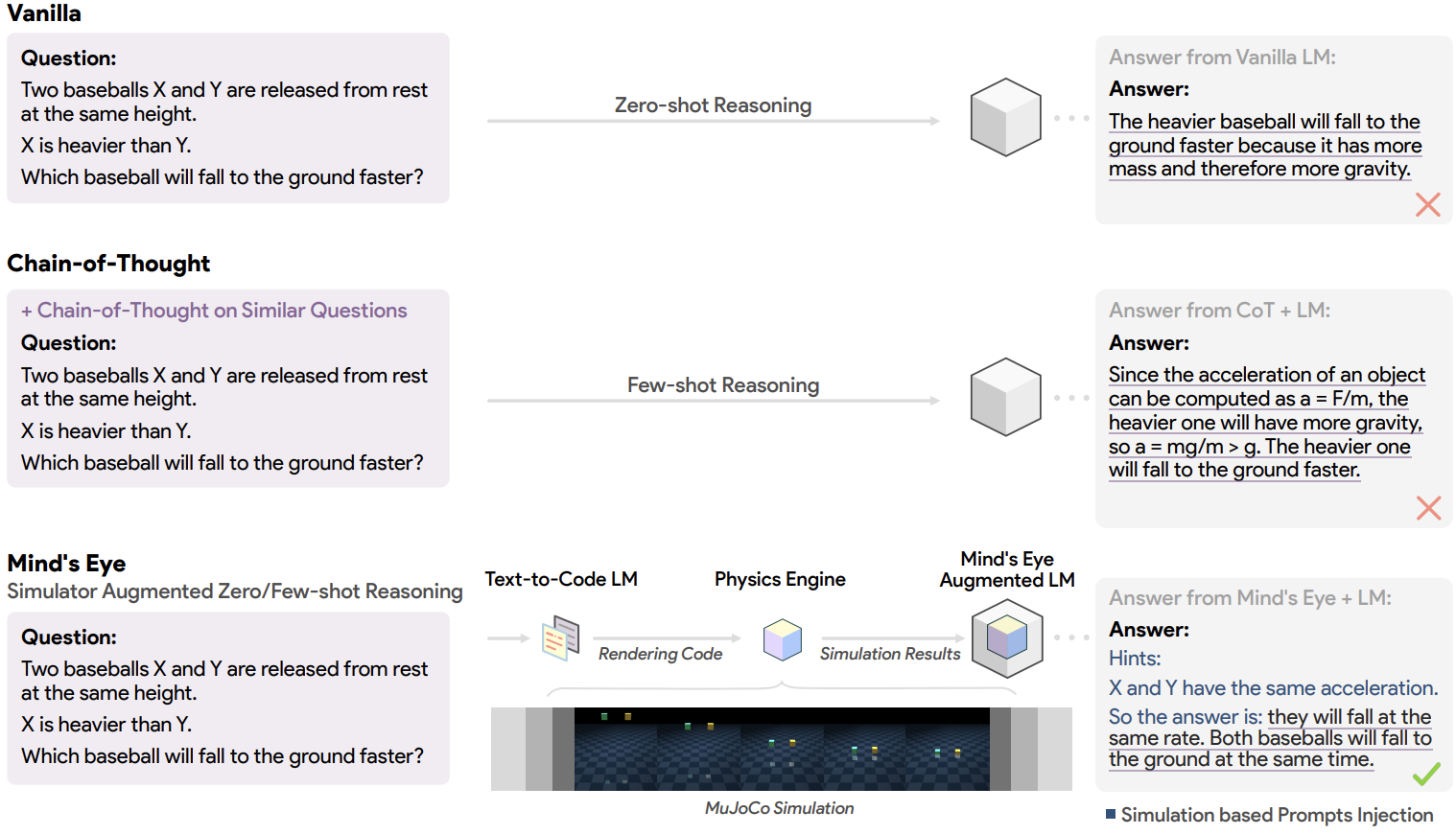
The authors show that this kind of grounding does help LLMs reason better with this “mind’s eye” powered by a computer simulation. So in a way, we already know how to insert a realistic externally implemented world model into an LLM to inform its reasoning about the world. Still, there are at least two important missing pieces:
In my opinion, a foundational model cannot practically run a complicated external tool every time it needs to generate something, but it can certainly use an external simulator for training. Software libraries such as MuJoCo can provide a foundational model, be it an LLM or a multimodal generation tool, with an endless stream of synthetic data and, more importantly, synthetic environments that could be used to experiment and learn about the physical world. This, again, brings us back to our favorite domain of synthetic data, which would include a synthetic physics simulator as well.
In this post, we have discussed world models in modern AI, starting from a very abstract notion of a world model and gradually making it more explicit until, in the end, we showed how to add an external physics-based simulator engine to state of the art LLMs.
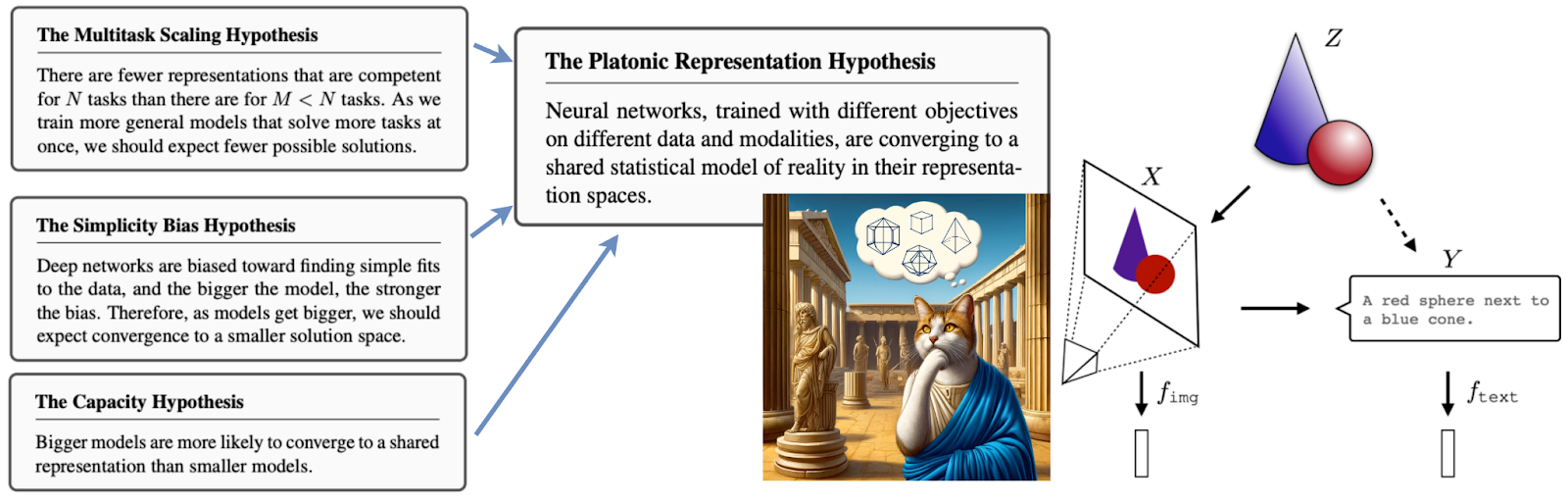
I would like to conclude this post by mentioning a recent work that appeared in May 2024: a paper by MIT researchers Huh et al., titled “The Platonic Representation Hypothesis”. In agreement with Plato’s ideal world of perfect forms (eidos), the authors posit that sufficiently expressive neural networks will converge to the same “optimal” representation of reality in their latent spaces, regardless of the modality they are trained on. This hypothesis is supported by several observations and empirical evidence in this intriguing work:
Still, despite the appearance of Sora that is head and shoulders above previously existing video generation models, and despite recent models that model visual environments with diffusion models and ground LLMs with interactive physics simulators, it looks like the field of applying world models to modern generative AI is still at its very inception. It will be exciting to see how world models become better and more prominent across various AI-related domains, and here at Synthesis AI we hope to spearhead at least some of these applications. See you next time!
Sergey Nikolenko
Head of AI, Synthesis AI
