
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
After a long hiatus, we return from interviews to long forms, continuing (and hopefully finishing) our series on how synthetic data is used in machine learning and how machine learning models can adapt to using synthetic data. This is our seventh installment in the series (part 1, part 2, part 3, part 4, part 5, part 6), but, as usual, this post is (I hope!) sufficiently self-contained. We will discuss how one can have a model that works well on synthetic data without making it more realistic explicitly but doing the domain adaptation work at the level of features or model itself.

In previous installments, we have considered models that perform refinement, that is, domain adaptation at the data level. This means that somewhere in the model, there is a learned transformation that takes data points from the source domain (in our case, synthetic images) and transforms them to make them more like the target domain (real images).
But it sounds like a lot of unnecessary extra work! Our final goal is very rarely to generate more realistic synthetic images. On the contrary, we want to use synthetic images to help train better models; the data itself is not important, it is just a stepping stone to models that work better. So maybe we don’t need to learn transformations on the level of images and can work in the space of features or model weights, never going back to change the actual data?
One simple and direct approach to doing that would be to share the weights among networks operating on different domains. This way, when you train on both domains, the network has to learn to do well on both with the same weights – exactly what you need for domain adaptation. This was the idea of the earliest approaches to domain adaptation in deep learning, but weight sharing and similar ideas remain relevant to this day. For instance, Rozantsev et al. (2019) do domain adaptation with a two-stream architecture; the weights for processing the two domains are not shared but the architectures are the same, and there are special regularizers on all layers that bring their weights together:

Another approach to model-level domain adaptation is to mine relatively strong priors from real data that can then inform a model trained on synthetic data, helping fix problematic cases or incongruencies between synthetic and real data. This also brings us to curriculum learning: it is often helpful to start with the easy cases and get a network rolling, and then fine-tune it in harder and harder situations.
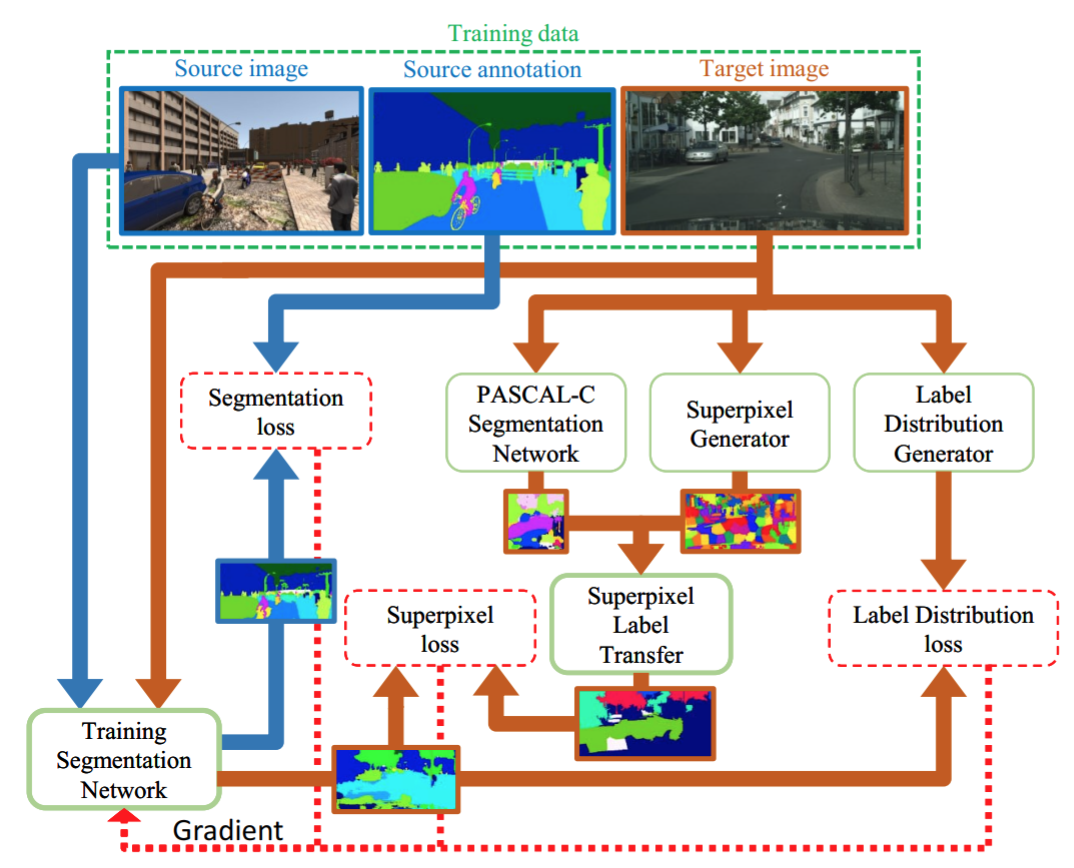
For example, Zhang et al. (2017) present a curriculum learning approach to domain adaptation for semantic segmentation of urban scenes. They train a segmentation network on synthetic data (specifically on the GTA dataset) but with a special component in the loss function related to the general label distribution in real images, intended to bring together the distributions of labels in real and synthetic datasets. The problem here is that this distribution is not available in real data, so this is where curriculum learning comes in: the authors first train a simpler model on synthetic data to estimate the label distribution from image features and then use it to inform the segmentation model:
But there are much more interesting ideas in model-based domain adaptation than just training the same network on both domains with some regularizers. Let’s get to them!
One of the main directions in model-level domain adaptation was initiated by Ganin and Lempitsky (2015) who presented a generic framework for unsupervised domain adaptation. Their basic approach goes as follows:
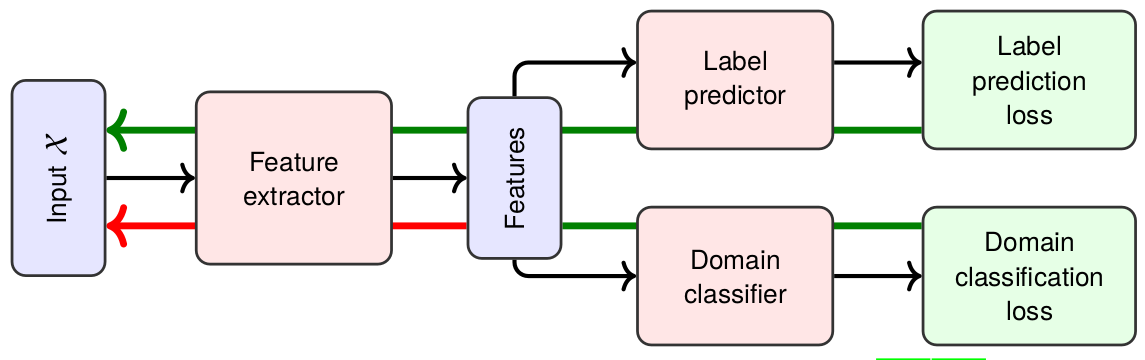
Let’s unpack what we see in this picture:
The idea is to train the label predictor to perform as well as possible and at the same time make the domain classifier perform as badly as possible. This is actually very similar to GANs (which we have discussed before). The difference, however, is that Ganin and Lempitsky devised an ingenious method for training that doesn’t require solving any minimax problems or iteratively alternating between networks.
The method is called gradient reversal: multiplying the gradients by a negative constant as they pass from the domain classifier to the feature extractor. In this way, the domain classifier learns to maximize its error, and the label predictor minimizes it, all at the same time and within the same loss function. Like this:

In a subsequent work, Ganin et al. (2016) generalized this domain adaptation approach to arbitrary architectures and experimented with domain adaptation in different domains, including image classification, person re-identification, and sentiment analysis.
Domain separation networks by Bousmalis et al. (2016) represent a different take on the same problem. They attempt to solve domain adaptation via disentanglement, a very important notion in deep learning. Disentanglement is the process of separating different features extracted by a machine learning model so that these separate parts would have different recognizable meanings. For example, many style transfer models (we discussed it in Part IV of this series) try to explicitly disentangle style from content, and then swap the style part of the features before decoding back in order to get the same image in a different style.
In domain adaptation, disentanglement amounts to separating domain-specific features from domain-independent ones, and trying to make sure that the latter will suffice to solve the actual problem. Domain separation networks explicitly separate the shared and private components of both source and target domains, extracting them with a shared encoder and two private encoders, one for the source domain and one for the target domain:

The overall objective function for a domain separation network consists of four parts (let’s not do the formulas, it is, after all, almost Christmas):
Bousmalis et al. evaluate their model on several synthetic-to-real scenarios, e.g., on synthetic traffic signs and synthetic objects from the LineMod dataset.
Domain separation networks became one of the first major examples in domain adaptation with disentanglement, where the hidden representations are domain-invariant and some of the features can be changed to transition from one domain to another. Further developments include:
The last paper I want to highlight here is by Hong et al. (2018) who provide one of the most direct and most promising applications of feature-level synthetic-to-real domain adaptation. In their Structural Adaptation Network, the conditional generator takes as input the features from a low-level layer of the feature extractor (i.e., features with fine-grained details) and random noise and produces transformed feature maps that should be similar to feature maps extracted from real images:

To achieve this, the conditional generator produces a noise map and then adds it to high-level features. Hong et al. compared the Structural Adaptation Network with other state of the art approaches, including FCNs in the Wild and Cross-City Adaptation, with source domain datasets SYNTHIA and GTA and target domain dataset Cityscapes; they conclude that this adaptation significantly improves the results for semantic segmentation of urban scenes. Here is a sample of their results:

Feature-level domain adaptation provides interesting opportunities for synthetic-to-real adaptation. Many of these methods still mostly represent work in progress, but the field is maturing rapidly, and in our experience, feature- and model-level DA is usually a simpler and more robust approach, easier to get to work, so we expect new exciting developments in this direction and recommend to try this family of methods for synthetic-to-real DA (unless actual refined images are required).
With this, I am concluding this long series on different facets of using synthetic data in machine learning. Most importantly, synthetic data is a source of virtually limitless perfectly labeled data. It has been explored in many problems, but we believe that many more potential use cases still remain. Maybe we will get a chance to explore them together in 2022.
Sergey Nikolenko
Head of AI, Synthesis AI
