
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Today we continue the series on using synthetic data to improve machine learning models.This is the sixth part of the series (Part I, Part II, Part III, Part IV, Part V). In this (relatively) short interlude I will discuss an interesting variation of GAN-based refinement: making synthetic data from real. Why would we ever want to do that if the final goal is always to make the model work on real data rather than synthetic? In this post, we will see two examples from different domains that show both why and how.

In this post, we discuss several works that generate synthetic data from real data by learning to transform real data with conditional GANs. The first application of this idea is to start from real data and produce other realistic images that have been artificially changed in some respects. This approach could either simply serve as a “smart augmentation” to extend the dataset (recall Part II of this series) or, more interestingly, could “fill in the holes” in the data distribution, obtaining synthetic data for situations that are lacking in the original dataset.
As the first example, let us consider Zhao et al. (2018a, 2018b) who concentrated on applying this idea to face recognition in the wild, with different poses rather than by a frontal image. They continued the work of Tran et al. (2017) (we do not review it here in detail) and Huang et al. (2017), who presented a TP-GAN (two-pathway GAN) architecture for frontal view synthesis: given a picture of a face, generate a frontal view picture.
TP-GAN’s generator G has two pathways: a global network that rotates the entire face and four local patch networks that process local textures around four facial landmarks (eyes, nose, and mouth). Both pathways have encoder-decoder architectures with skip connections for multi-scale feature fusion:
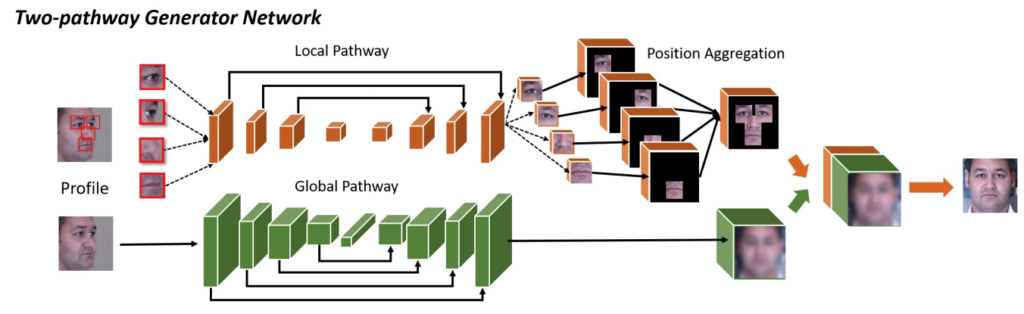
The discriminator D in TP-GAN, naturally, learns to distinguish real frontal face images from synthesized images. The synthesis loss function in TP-GAN is a sum of four loss functions:
I won’t bore you with formulas for TP-GAN, but the results were pretty good. Here they are compared to competitors existing in 2017 (the leftmost column shows the profile face to be rotated, second from left are the results of TP-GAN, the rightmost column are actual frontal images, and the rest are various other approaches):

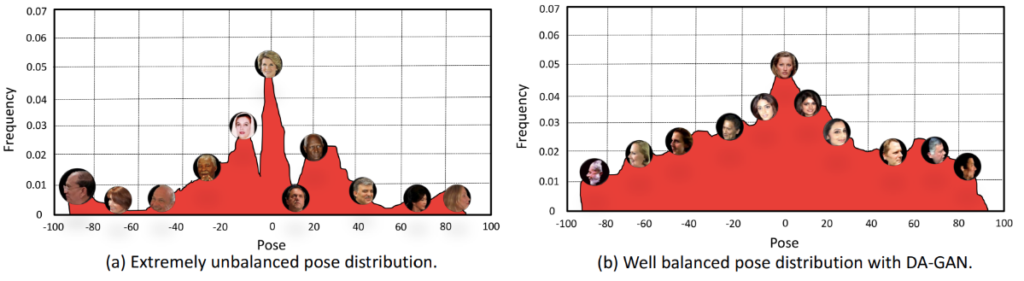
Zhao et al. (2018a) propose the DA-GAN (Dual-Agent GAN) model that also works with faces but in the opposite scenario: while TP-GAN rotates every face into the frontal view, DA-GAN rotates frontal faces to arbitrary angles. The motivation for this brings us to synthetic data: Zhao et al. noticed that existing datasets of human faces contain mostly frontal images, with a few standard angles also appearing in the distribution but not much in between. This could skew the results of model training and make face recognition models perform worse.
Therefore, DA-GAN aims to create synthetic faces to fill in the “holes” in the real data distribution, rotating real faces so that the distribution of angles becomes more uniform. The idea is to go from the data distribution shown on the left (actual distribution from the IJB-A dataset) to something like shown on the right:
They begin with a 3D morphable model, extracting 68 facial landmarks with the Recurrent Attentive-Refinement (RAR) model (Xiao et al., 2016) and estimating the transformation matrix with 3D-MM (Blanz et al., 2007). However, Zhao et al. report that simulation quality dramatically decreases for large yaw angles, which means that further improvement is needed. This is exactly where the DA-GAN framework comes in.
Again, DA-GAN’s generator maps a synthetized image to a refined one. It is trained on a linear combination of three loss functions:
Here is the general idea of DA-GAN:
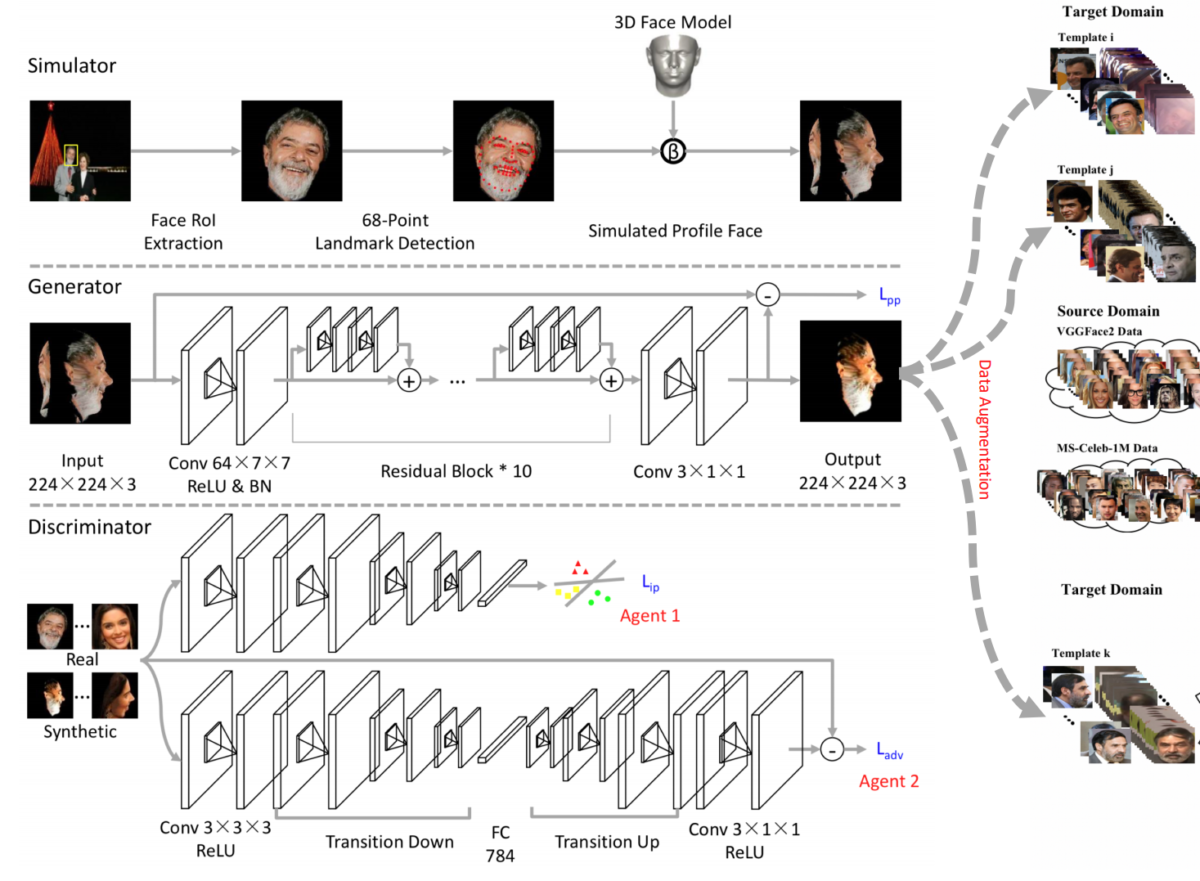
Apart from experiments done by the authors, DA-GAN was verified in a large-scale NIST IJB-A competition where a model based on DA-GAN won the face verification and face identification tracks. This example shows the general premise of using synthetic data for this kind of smart augmentations: augmenting the dataset and balancing out the training data distribution with synthetic images proved highly beneficial in this case.
In the previous section, we have used real-to-synthetic transfer basically as a smart augmentation, enriching the real dataset that might be skewed with new synthetic data produced from real data points.
The second example deals with a completely different idea of using the same transfer direction. Why do we need domain adaptation at all? Because we want models that have been trained on synthetic data to transfer to real inputs. The idea is to reverse this logic: let us transfer real data into the synthetic domain, where the model is already working great!
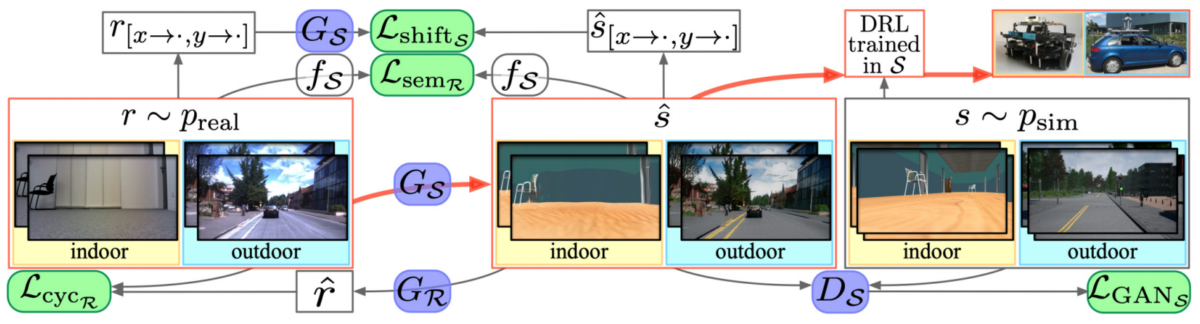
In the context of robotics, this kind of real-to-sim approach was implemented by Zhang et al. (2018) in a very interesting approach called “VR-Goggles for Robots”. It is based on the CycleGAN ideas, a general approach to style transfer (and consequently domain adaptation) that we introduced in Part IV of this series.
More precisely, Zhang et al. use the general framework of CyCADA (Hoffman et al., 2017), a popular domain adaptation model. CyCADA adds semantic consistency, feature-based adversarial, and task losses to the basic CycleGAN. The general idea looks as follows:
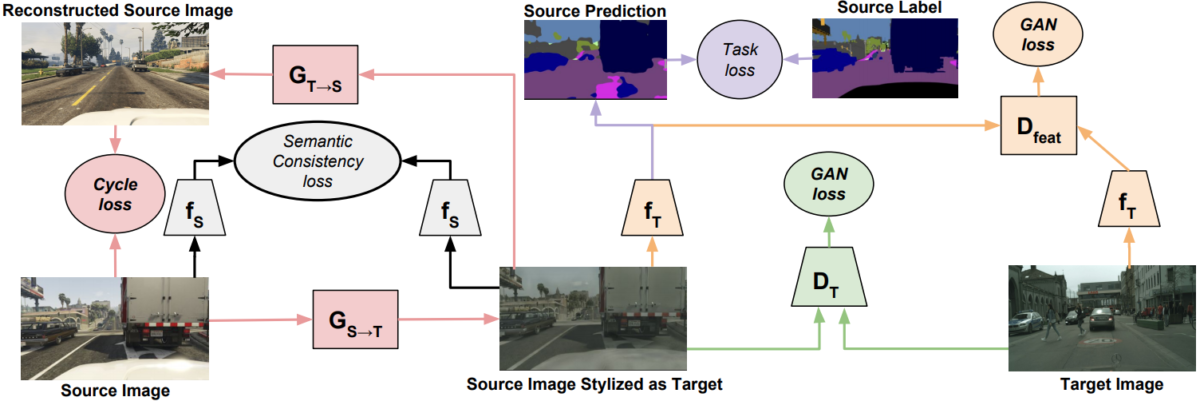
Note that CyCADA has two different GAN losses (adversarial losses), pixel-wise and feature-based (semantic), and a task loss that reflect the downstream task that we are solving (semantic segmentation in this case). In the original work, CyCADA was applied to standard, synthetic-to-real domain adaptation, although the model really does not distinguish much between the two opposing transfer directions because it’s a CycleGAN. Here are some CyCADA examples on standard synthetic and real outdoor datasets:
Similar to CyCADA, the VR-Goggles model has two generators, real-to-synthetic and synthetic-to-real, and two discriminators, one for the synthetic domain and one for the real domain. The overall loss function consists of:
Here is the general picture, which is actually very close to the CyCADA pipeline shown above:
Zhang et al. report significantly improved results in robotic navigation tasks. For instance, in the image below a navigation policy was trained (in a synthetic simulation environment) to move towards chairs:
The “No-Goggles” row shows results in the real world without domain adaptation, where the policy fails miserably. The “CycleGAN” row shows improved results after doing real-to-sim transfer with a basic CycleGAN model. Finally the “VR-Goggles” row shows successful navigation with the proposed real-to-sim transfer model.
Why might this inverse real-to-sim direction be a good fit for robotics specifically, and why haven’t we seen this approach in other domains in the previous posts? The reason is that in the real-to-sim approach, we need to use domain adaptation models during inference, as part of using the trained model. In most regular computer vision applications, this would be a great hindrance. In computer vision, if some kind of preprocessing is only part of the training process it is usually assumed to be free (you can find some pretty complicated examples in Part II of this series), and inference time is very precious.
Robotics is a very different setting: robots and controllers are often trained in simulation environments with reinforcement learning, which implies a lot of computational resources needed for training. The simulation environment needs to be responsive and cheap to support, and if every frame of the training needs to be translated via a GAN-based model it may add up to a huge cost that would make RL-based training infeasible. Adding an extra model during inference, on the other hand, may be okay: yes, we reduce the number of processed frames per second, but if it stays high enough for the robot to react in real time, that’s fine.
In this post, we have discussed the inverse direction of data refinement: instead of making synthetic images more realistic, we have seen approaches that make real images look like synthetic ones. We have seen two situations where this is useful: first, for “extremely smart” augmentations that fill in the holes in the real data distribution, and second, for robotics where training is very computationally intensive, and it may be actually easier to modify the input on inference.
With this, I conclude the part on refinement, i.e., domain adaptation techniques that operate on data and modify the data from one domain to another. Next time, we will begin discussing model-based domain adaptation, that is, approaches that change the model itself and leave the data in place. Stay tuned!
Sergey Nikolenko
Head of AI, Synthesis AI
