
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Today, I continue the series about different ways of improving model performance with synthetic data. We have already discussed simple augmentations in the first post and “smart” augmentations that make more complex transformations of the input in the second. Today we go on to the next sub-topic: domain adaptation. We will stay with domain adaptation for a while, and in the first post on this topic I would like to present a general overview of the field and introduce the most basic approaches to domain adaptation.

In previous posts, we have discussed augmentations, transformations that can be used to extend the training set. In the context of synthetic data (we are in the Synthesis AI blog, after all), this means that synthetic data can be used to augment real datasets of insufficient size, and an important part of using synthetic data would be to augment the heck out of it so that the model would generalize as well as possible. This is the idea of domain randomization, a very important part of using synthetic data for machine learning and a part that we will definitely return to in future posts.
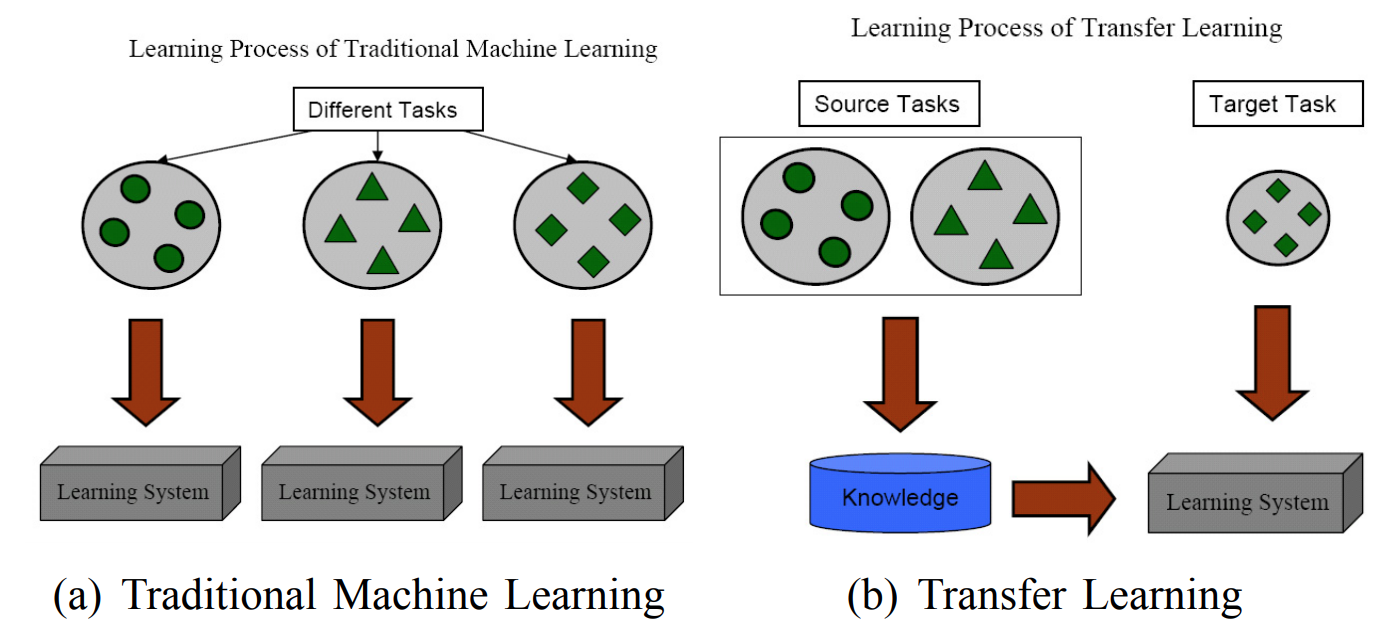
But the use of synthetic data can be made much more efficient than just training on it. Domain adaptation is a set of techniques designed to make a model trained on one domain of data, the source domain, work well on a different, target domain. The problem we are trying to solve is called transfer learning, i.e., transferring the knowledge learned on source tasks into an improvement in performance on a different target task, as shown in this illustration from (Pan, Yang, 2009):
This is a natural fit for synthetic data: in almost all applications, we would like to train the model in the source domain of synthetic data but then apply the results in the target domain of real data. Here is an illustration of the three approaches to this kind of transfer in the context of robotics (source):
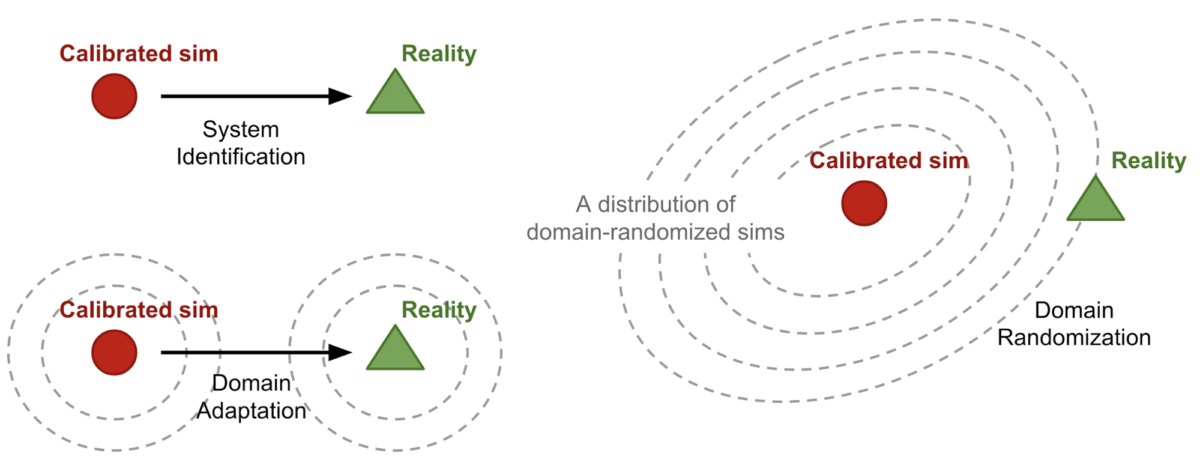
Here we see the difference:
In this series of posts, we will give a survey of domain adaptation approaches that have been used for such synthetic-to-real adaptation. We broadly divide the methods outlined in this chapter into two groups. Approaches from the first group operate on the data level, which makes it possible to extract synthetic data “refined” in order to work better on real data, while approaches from the second group operate directly on the model, its feature space or training procedure, leaving the data itself unchanged.
Let us now discuss these two options in more detail.
The first group of approaches for synthetic-to-real domain adaptation work with the data itself. In this approach, we try to develop models that can take a synthetic image as input and “refine” it, making it better for subsequent model training. Note that while in most works we discuss here the objective is basically to make synthetic data more realistic (for example, in GAN-based models it is the direct objective: the discriminators should not be able to distinguish refined synthetic data from real samples), this does not necessarily have to be the case. Some early works on synthetic data even concluded that synthetic images may work better if they are less realistic, resulting in better generalization of the models. But generally speaking, realism is the goal.
Today I will make an example of the very first work that kickstarted synthetic-to-real refinement back in 2016, and we will discuss what’s happened since then later, in a separate post. This example, one of the first successful models with straightforward synthetic-to-real refinement, was given by Apple researchers Shrivastava et al. (2017).
The underlying problem here is gaze estimation: recognizing the direction where a human eye is looking. Gaze estimation methods are usually divided into model-based, which model the geometric structure of the eye and adjacent regions, and appearance-based, which use the eye image directly as input; naturally, synthetic data is made and refined for appearance-based gaze estimation.
Before Shrivastava et al., this problem had already been tackled with synthetic data. In particular, Wood et al. (2016) presented a large dataset of realistic renderings of human eyes and showed improvements on real test sets over previous work done with the MPIIgaze dataset of real labeled images. Here is what their synthetic dataset looks like:
The usual increase in scale (synthetic images are almost free after the initial investment is made) is manifested here as an increase in variability: MPIIgaze contains about 214K images, and the synthetic training set was only about 1M images, but all images in MPIIgaze come from the same 15 participants of the experiment, while the UnityEyes system developed by Wood et al. can render every image in a different randomized environment, which makes the model much more robust.
The refinement here is to make these synthetic images even more realistic. Shrivastava et al. present a GAN-based system trained to improve synthesized images of the eyes. They call this idea Simulated+Unsupervised learning:
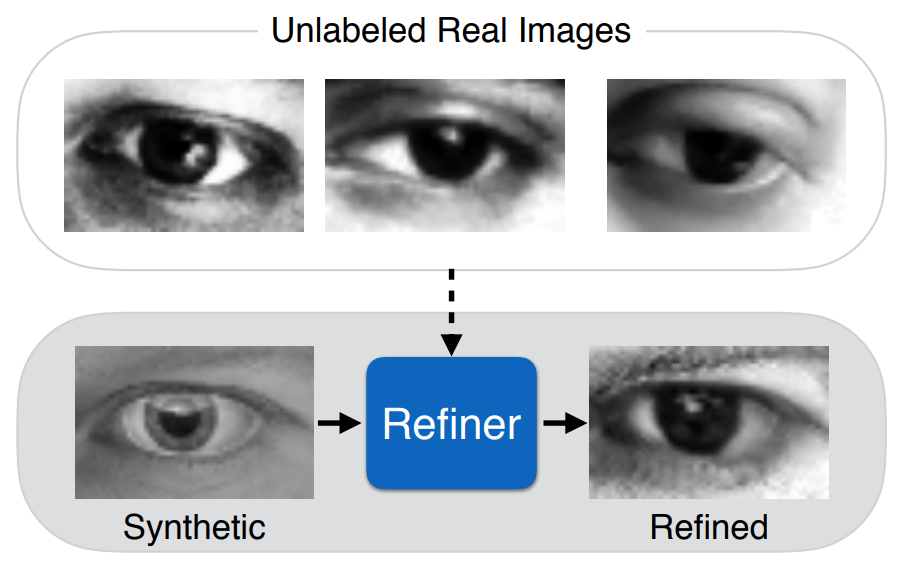
They learn a transformation implemented with a Refiner network with the SimGAN adversarial architecture:
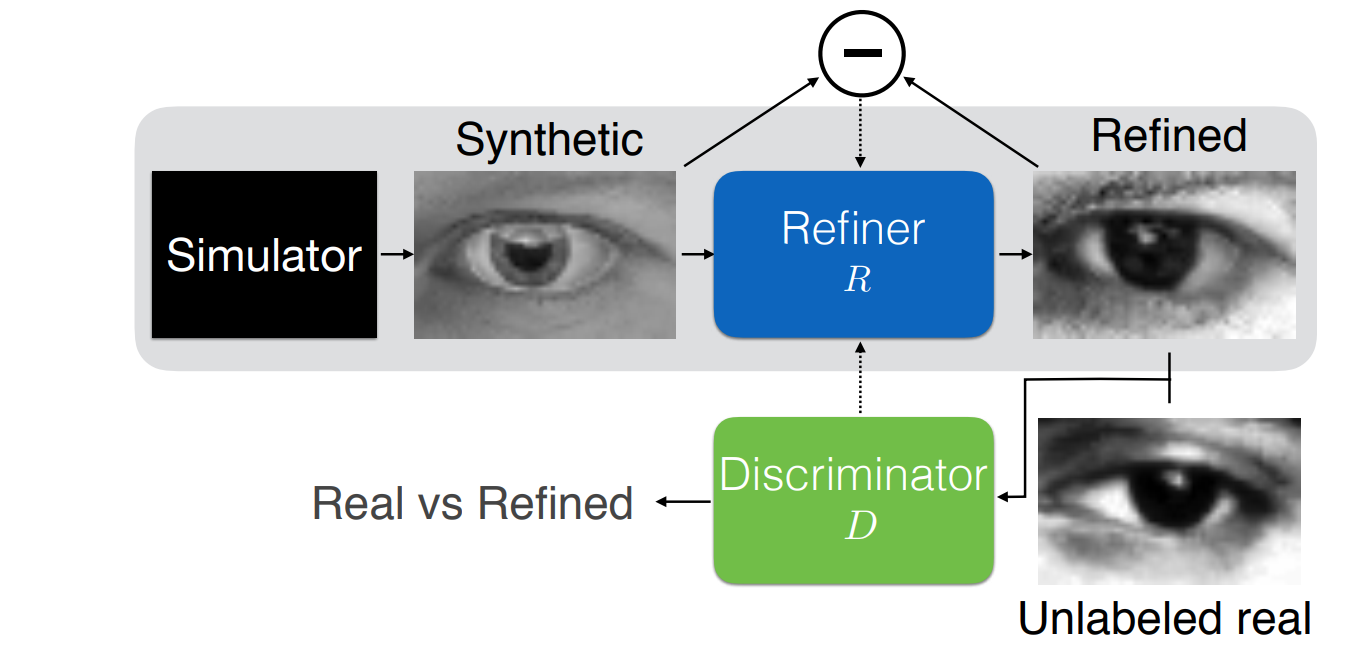
SimGAN is a relatively straightforward GAN. It consists of a generator (refiner) and a discriminator, as shown above. The discriminator learns to distinguish between real and refined images with a standard binary classification loss function. The generator, in turn, is trained with a combination of the adversarial loss that makes it learn to fool the discriminator and regularization loss that captures the similarity between the refined image and the original one in order to preserve the target variable (gaze direction).
As a result, Shrivastava et al. were able to significantly improve upon previous results. But the gaze estimation problem is in many ways a natural and simple candidate for such an approach. It is especially telling that the images they generate and refine are merely 30×60 pixels in size: even the GANs that existed in 2017 were able to work quite well on this kind of output dimension. In a later post, we will see how image-based refinement works today and in other applications.
We have seen models that perform domain adaptation at the data level, i.e., one can extract a part of the model that takes as input a data point from the source domain (a synthetic image) and map it to the target domain (a real image).
However, it is hard to find applications where this is actually necessary. The final goal of AI model development usually is not to get a realistic synthetic image of a human eye; this is just a stepping stone to producing models that work better with the actual task, e.g., gaze estimation in this case.
Therefore, to make better use of synthetic data it makes sense to also consider feature-level or model-level domain adaptation, that is, methods that work in the space of latent features or model weights and never go back to change the actual data.
The simplest approach to such model-based domain adaptation would be to share the weights between networks operating on different domains or learn an explicit mapping between them. Here is an early paper by Glorot, Bordes, and Bengio (2011) that does exactly that, this relatively simple approach remains relevant to this day, and we will probably see more examples of it in later installments.
But for this introductory post I would like to show probably the most important work in this direction, the one that started model-based domain adaptation in earnest. I’m talking, of course, about “Unsupervised Domain Adaptation by Backpropagation” by two Russian researchers, Yaroslav Ganin and Victor Lempitsky. Here is the main illustration from their paper:

This is basically a generic framework for unsupervised domain adaptation that consists of:
The idea is to train the label predictor to perform as well as possible and at the same time train the domain classifier to perform as badly as possible. This is achieved with the gradient reversal layer: the gradients are multiplied by a negative constant as they pass from the domain classifier to the feature extractor.
This is basically the idea of GANs but without the tediousness of iterative separate training of a generator and discriminator and with much fewer convergence problems than early GANs suffered from. The original work by Ganin and Lempitsky applied this idea to examples that would be considered toy datasets by today’s standards, but since 2015 this field has also had a lot of interesting discoveries that we will definitely discuss later.
In this post, we have started to discuss domain adaptation, probably the most important topic in machine learning research dealing with synthetic data. Generally speaking, all we do is domain adaptation: we need to use synthetic data for training, but the final goal is always to transfer to the domain of the real world.
Next time, we will discuss GAN-based refinement in more detail. Stay tuned, there will be GANs aplenty, including some very interesting models! Until next time!
Sergey Nikolenko
Head of AI, Synthesis AI
