
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Some of the most important AI advances in 2024 were definitely test-time reasoning LLMs, or large reasoning models (LRM), that is, LLMs that are trained to write down and reuse their chains of thought for future reference. Reasoning LLMs started with the o1 family of models by OpenAI (I wrote a short capabilities post in September, when it appeared). Since then, they have opened up a new scaling paradigm for test-time compute, significantly advanced areas such as mathematical reasoning and programming, and OpenAI is already boasting its new o3 family—but we still don’t have a definitive source on how OpenAI’s models work. In this post, we discuss how attempts to replicate o1 have progressed to this date, including the current state of the art open model, DeepSeek R1, which seems to be a worthy rival even for OpenAI’s offerings.

“It’s not that I’m so smart, it’s just that I stay with problems longer”. This is one of the many quotes often attributed to Albert Einstein, probably wrongly (Calaprice, 2010). Regardless of the actual author, it is a perfect description of what large reasoning models (LRM) can do: they stay with a problem, generating new thought tokens and ruminating on their own reasoning to make further progress.
Over the past few years, large language models (LLMs) have dramatically advanced our ability to process and generate natural language. Yet, despite this remarkable fluency, many LLMs still struggle with complex reasoning tasks. Enter the era of large reasoning models (LRM; I’m not sure it’s the official name already, but I have to choose something)—LLMs that don’t just respond but actively reason through problems, reusing and refining their own thought processes in real-time.
In this post, we trace the rapid evolution of these reasoning models, starting with OpenAI’s groundbreaking o1 and leading to DeepSeek-R1, an o1 replication that verified a lot of ideas behind LRMs and published them openly. We will explore the key innovations, challenges, and unexpected lessons learned along the way, focusing on how o1 replications have grown into serious competitors in the space.
We still don’t really know how o1 or o3 models work—OpenAI is pretty good at keeping secrets. But since September, there have been plenty of attempts to replicate o1. The defining feature of these test-time reasoning LLMs has been the test-time scaling that we discussed back in September and will discuss again here: a test-time reasoning LLM is one that feeds on its own chain of thought and can use intermediate outputs to produce better results. In this post, we review reasoning LLMs from the beginning, describing several plausible o1 replications and culminating in the latest and greatest replication that may even be better than the original: DeepSeek-R1.
I want to get one thing out of the way first: the amount of press devoted to the $5.5M figure for training DeepSeek-V3 was ridiculous. Yes, as, e.g., Andrej Karpathy explains here, this means a highly optimized training pipeline; a lot of the DeepSeek-V3 paper (DeepSeek-AI, 2024) is devoted to algorithmic optimizations that go all the way down to the hardware level. This is definitely significant progress, other labs will no doubt implement similar optimizations too, and we will devote a section of this post to the higher-level optimizations introduced by DeepSeek.
But it does not mean, as many seem to assume, that you can “get in the game” of training frontier LLMs on a seven-figure budget. The $6M figure concerns the final training run, but it was the culmination of God knows how many experiments performed over months and years of work, by over a hundred rather expensive researchers (note how many authors the DeepSeek papers have), on a cluster that was specially built for DeepSeek by their owner, the High-Flyer hedge fund that does not seem to lack for money in the slightest. A recent report by SemiAnalysis (Patel et al., Jan 31, 2025) estimates the total CapEx for DeepSeek to be ~$1.6B, with a cost of $944M.
This is going to be a large post. We will:
That’s a lot of ground to cover—let’s begin!
Chain-of-Thought. But how do large models “reason”? The answer begins with the development of chain-of-thought prompting. One of the earliest breakthroughs in reasoning LLMs came from an unexpected place—just asking the model to think aloud.
You have no doubt heard of the famous phrase “let’s think step by step”. Back in May 2022, researchers from the University of Tokyo and Google Kojima et al. (2022) found that simply adding this phrase before each answer significantly improved an LLM’s performance!

It turned out that by including this simple instruction in the prompt, models were encouraged to generate a series of intermediate reasoning steps rather than jump directly to the final answer, helping the model organize its thoughts and improving the clarity and accuracy of responses. The prompt urged the models to decompose a complicated problem into subtasks.
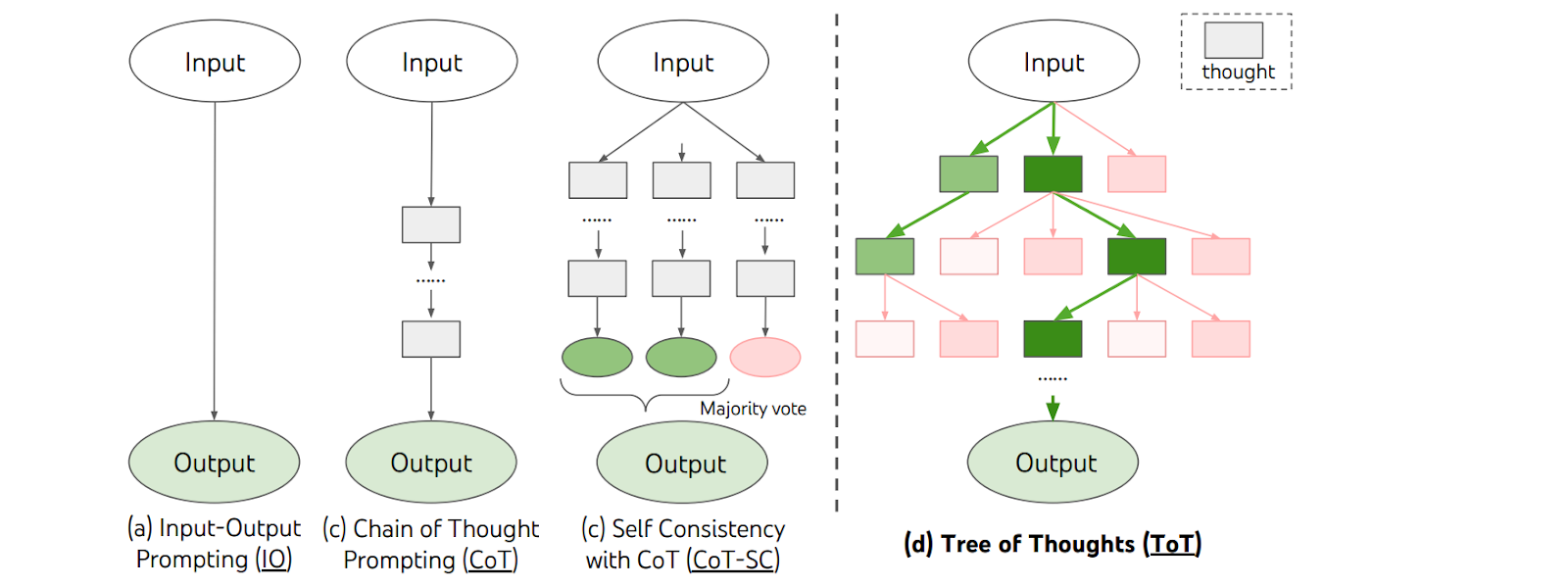
This was a zero-shot variation on the earlier idea of chain-of-thought prompting: the idea that in few-shot prompts, you can give the models full reasoning examples rather than just curt answers. The picture above started from item (c); here is the missing part:

Instead of simply providing a final answer, chain-of-thought (CoT) prompting guides the model to articulate its intermediate reasoning—often through a series of natural language steps—and this too led to significant boosts in performance on a lot of tasks, especially reasoning-heavy tasks such as arithmetic, logic, and commonsense reasoning. Chain-of-thought prompting was known since at least the work of Google researchers Wei et al., (2022) released in January 2022. Chain-of-thought prompting made the internal reasoning process explicit, and this helped LLMs solve problems much better; here is probably the first example of CoT prompting in literature (Wei et al., 2022):
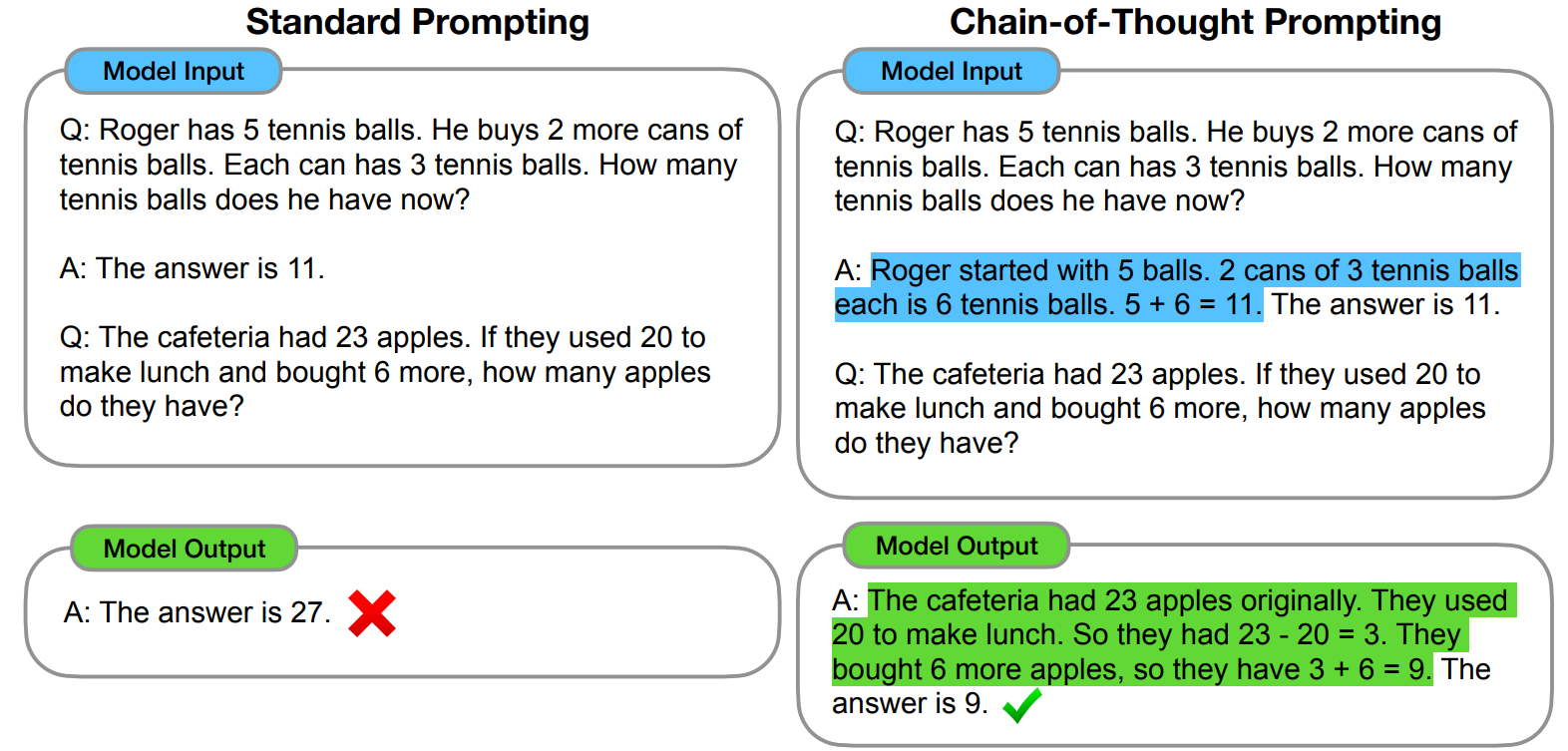
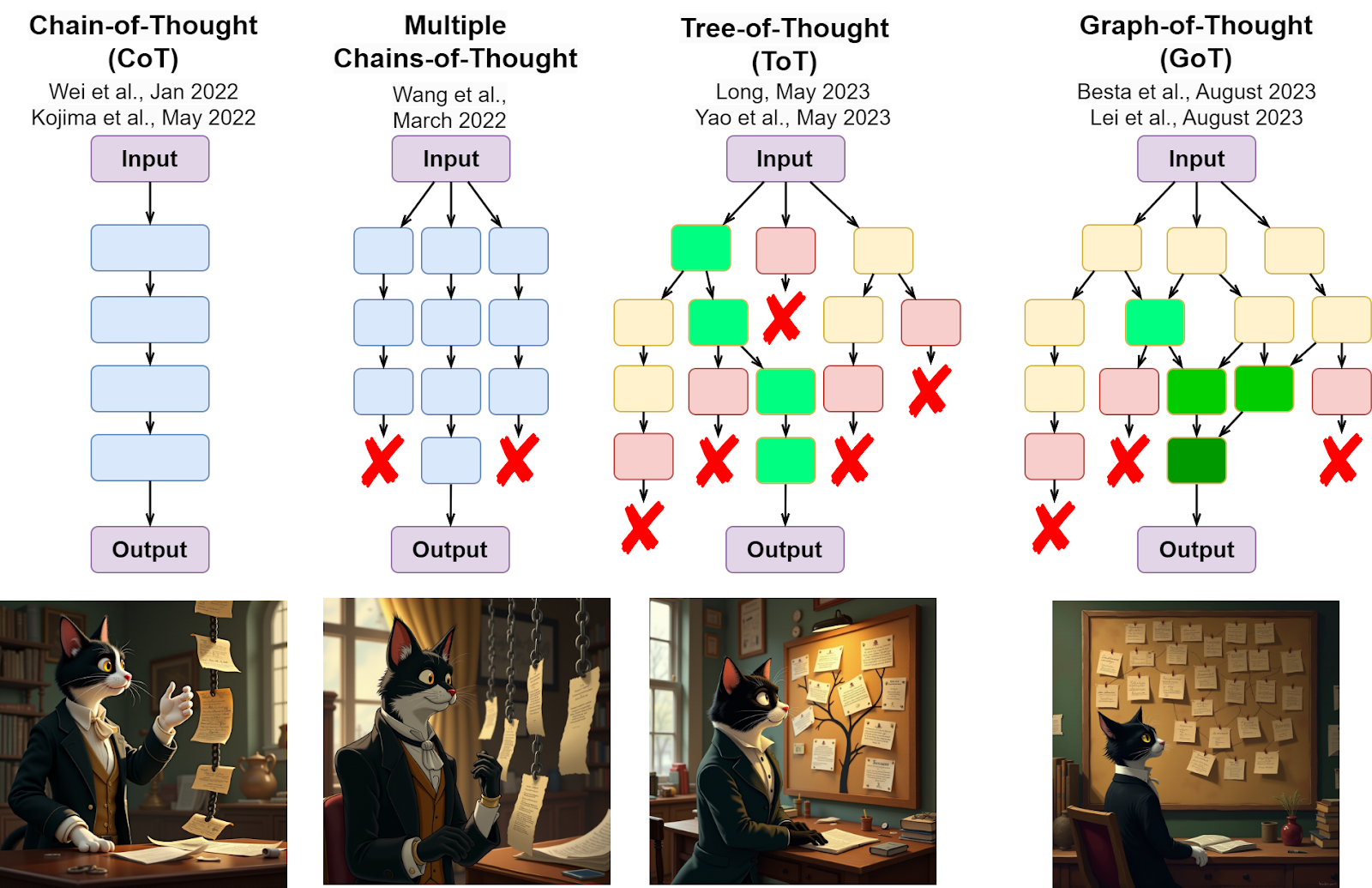
Tree-of-Thought. Building on this idea, researchers set to work on the CoT paradigm and developed a lot of novel variations, mostly related to more advanced structured reasoning strategies. The most important step here is probably going from linear chains-of-thought to tree-of-thought methods (Besta et al., 2024). Traditional CoT prompting shows and encourages a single linear progression of reasoning steps; in contrast, tree-of-thought techniques urge the models to explore multiple branches of reasoning simultaneously. In a tree-of-thought framework, each node in the tree represents a partial reasoning sequence, and the model can branch out to consider alternative hypotheses or strategies at each decision point.
An early important attempt was made by Wang et al. (2022) who introduced the Chain-of-Thought with Self-Consistency (CoT-SC) approach. In CoT-SC, the model samples several different reasoning paths and then aggregates them to obtain the final answer:
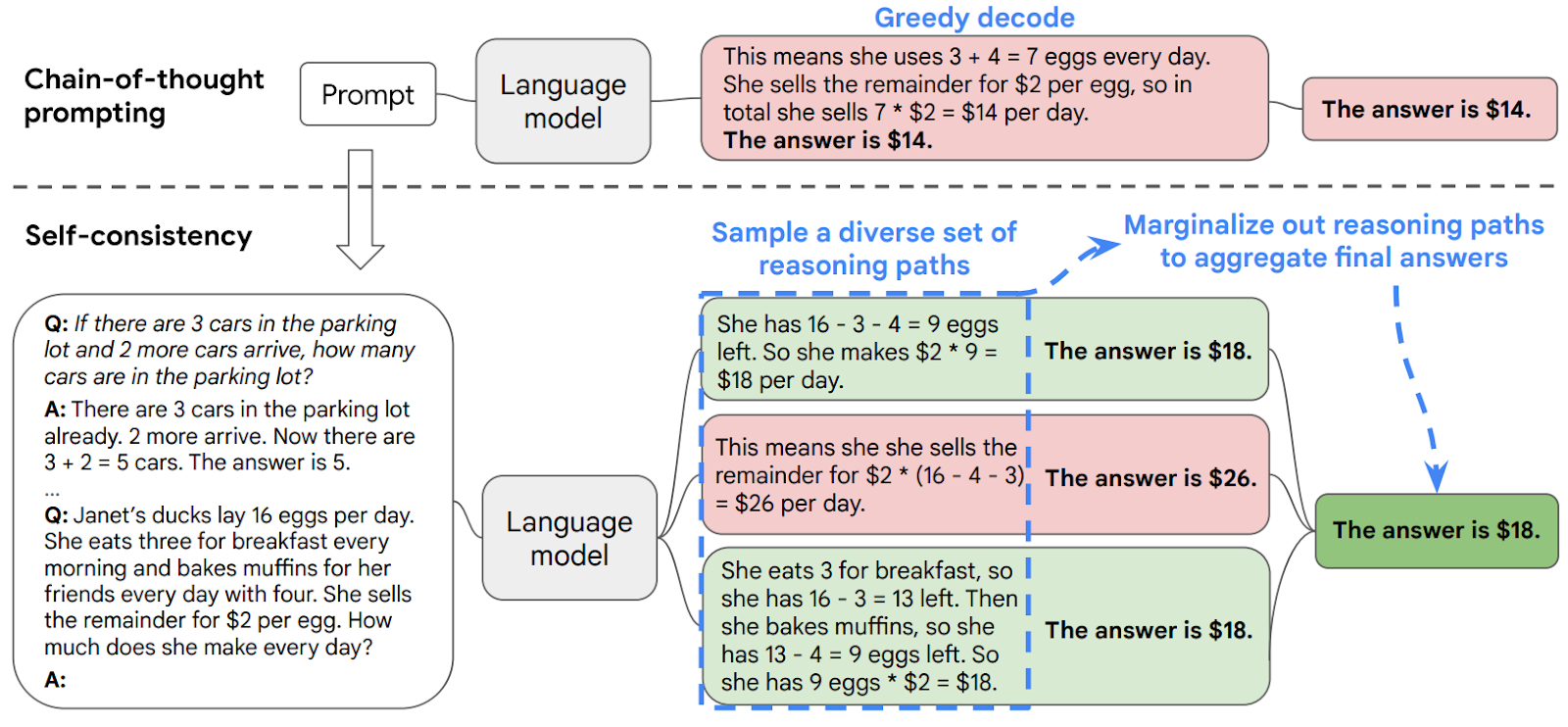
This approach generated multiple parallel chains of reasoning but it was not yet a branching tree. Trees were a natural next step, and they appeared in two works submitted to arXiv virtually simultaneously, only two days apart: Long (May 15, 2023) and Yao et al. (May 17, 2023).
In the former, the tree construction process was supervised by a separate module called the ToT controller, ToT standing for “tree-of-thought”. A checker module evaluates if a solution has been found (for problems like math/logic puzzles you can do it deterministically, for others checking requires an LLM call), and the ToT controller implements a decision procedure of whether to generate more chains of thought from the current node or backtrack; here is an illustration from Long (2023):
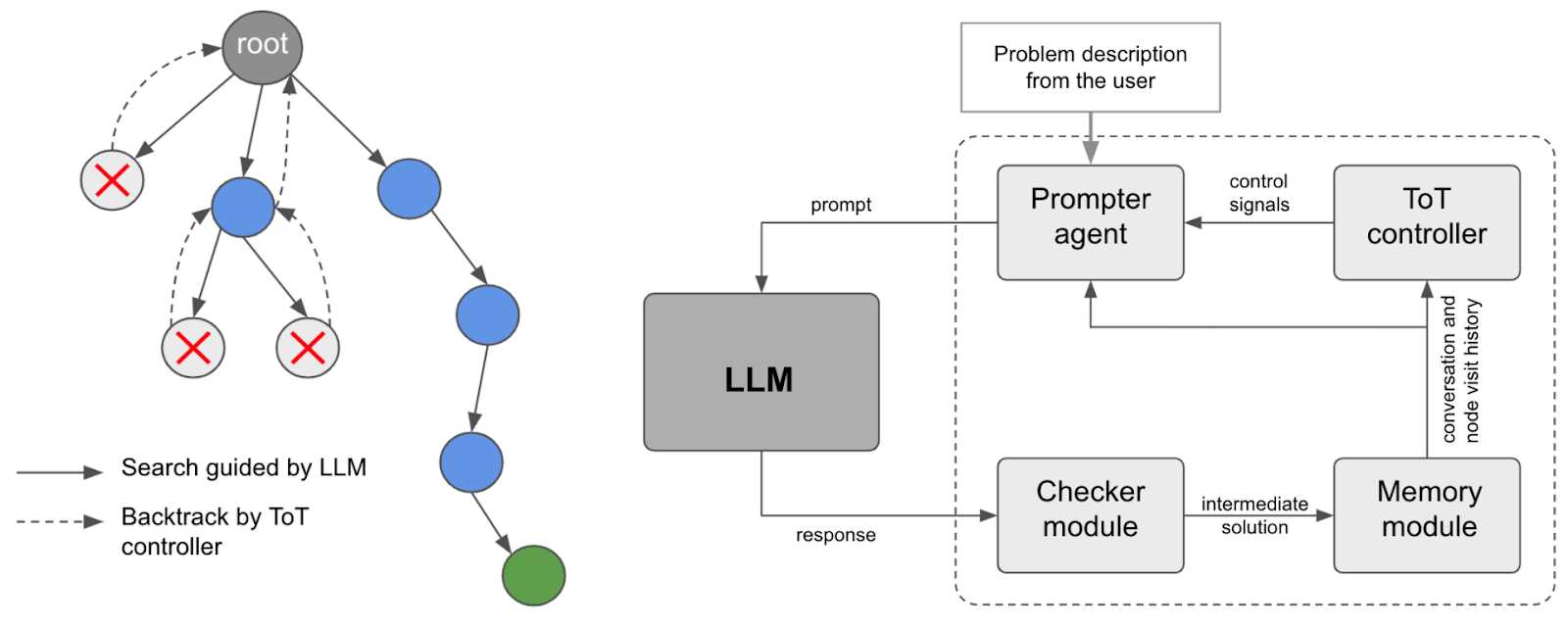
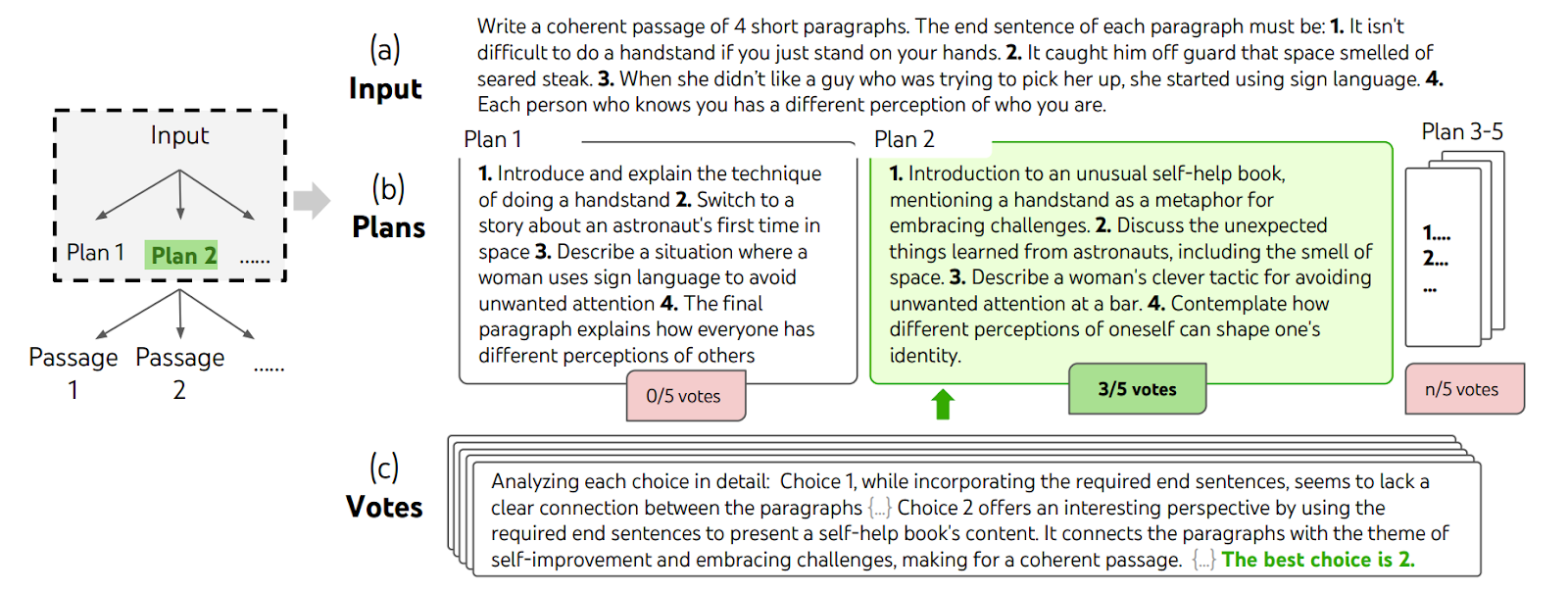
The approach by Yao et al. (2023), also called ToT, was similar; the idea was to generate thoughts, understood as individual coherent reasoning steps, and then implement a voting or other selection mechanism to choose the most promising paths, backtrack, and so on:
On every step, the model would sample several paths and then vote to decide which path is best; here is an example for a creative writing assignment:
Graph-of-Thought and beyond. What is the natural step after a tree of thoughts? A more general graph of thoughts, of course! Generalizing to more general graphs would allow, for instance, to combine two thoughts into one conclusion, a natural operation that we humans do all the time in our reasoning. And indeed, graphs of thoughts (GoT) appeared very soon after ToT, and again we see two papers that introduced first implementations of this idea appearing only two days apart (I know I should have gotten used to the rate of progress in AI these days, but it is still a bit staggering): Besta et al. (August 18, 2023) and Lei et al. (August 16, 2023).
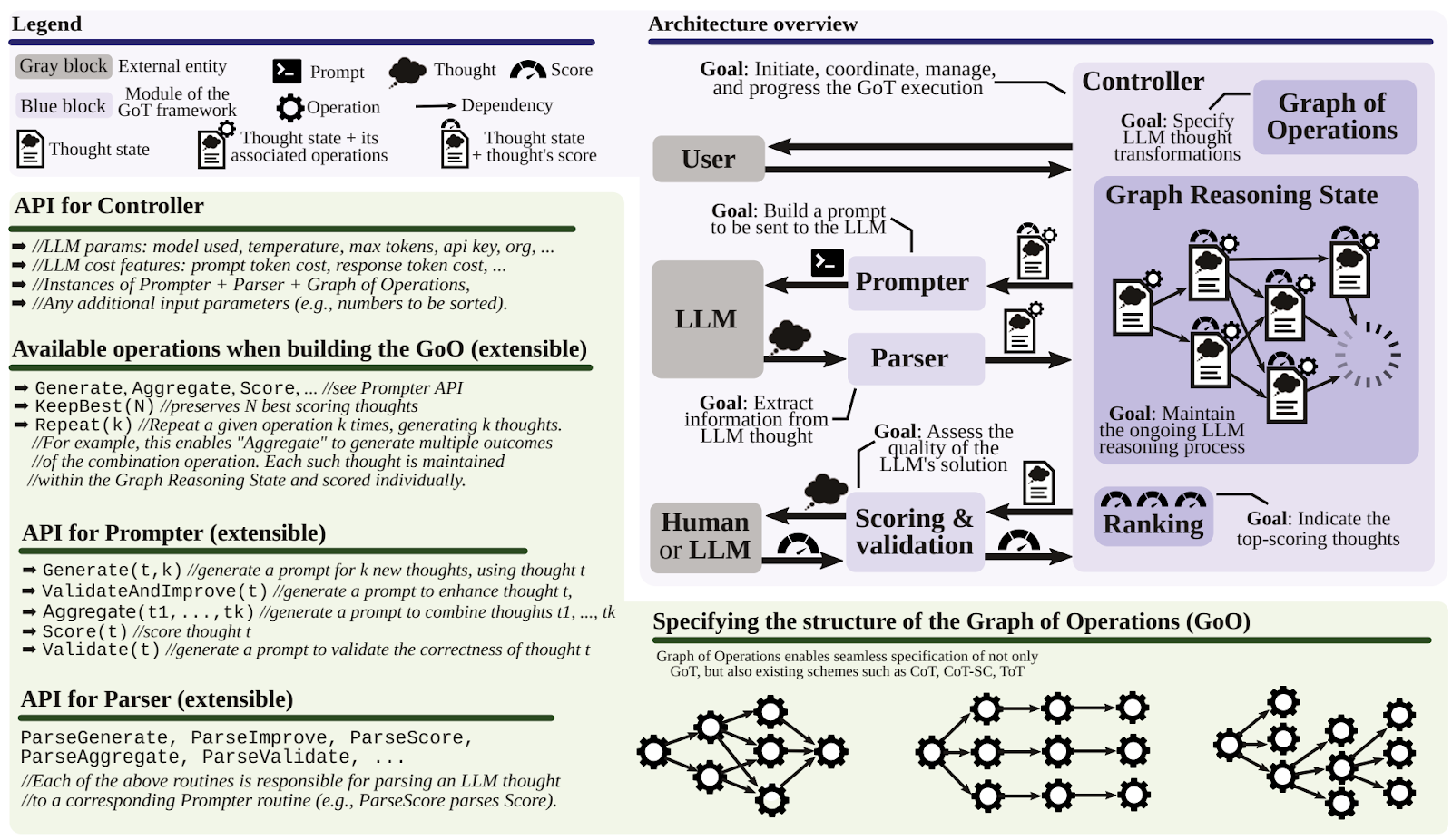
Besta et al. (2023) introduced an approach very similar to Long (2023) but with additional actions available in the controller such as aggregation of several thoughts. Here is a detailed overview illustration of their approach:
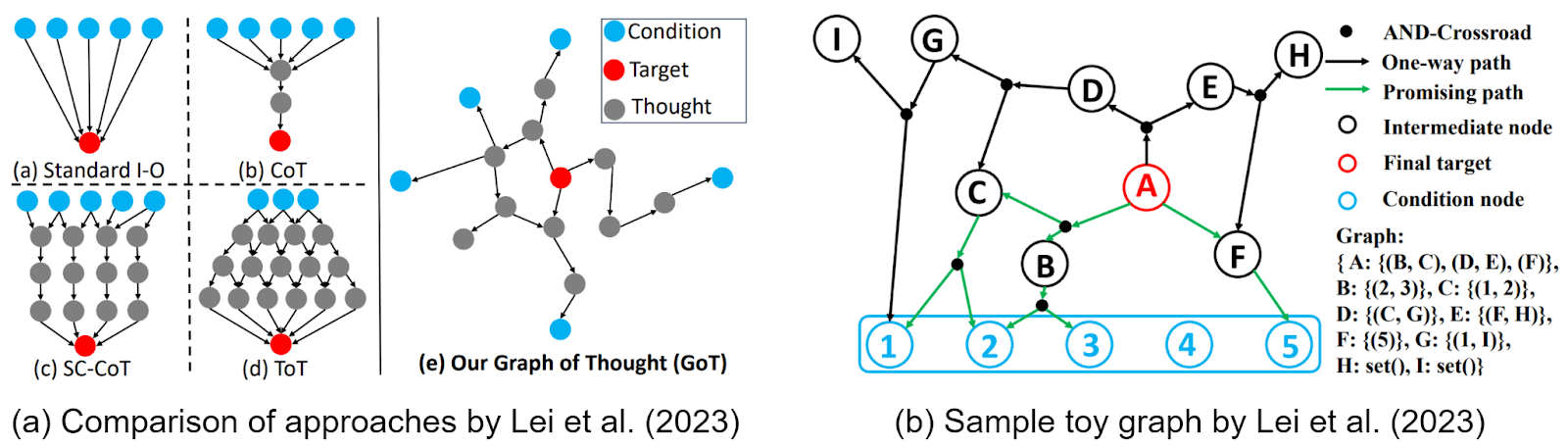
Lei et al. (2023) extended this with another novelty: condition nodes that summarize what the model has learned from previous failures or promising chains of reasoning. In this approach, the checker function has the ability to add new conditions, and then potential solutions are checked against these conditions:
Overall, this line of research progressed along some very expected lines: from chains to trees to graphs. Each step introduced new degrees of freedom in the thought process, and no doubt required new tricks to actually implement and make work, but all this progress was still very much expected. Here is a timeline modeled after the timeline in the survey by Besta et al. (2024):
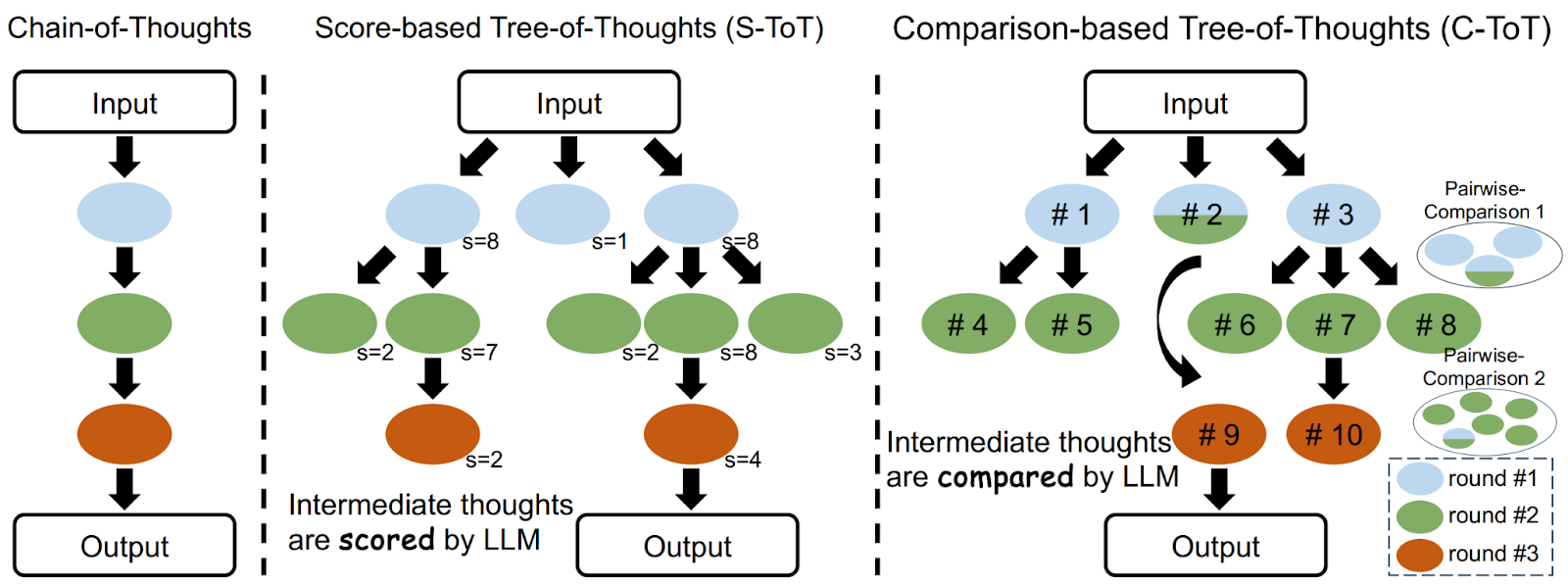
In 2024, this approach continued. For example, any tree-of-thought and graph-of-thought approach needs a way to score the potential of new thoughts to decide which to branch further and which to abandon. Usually these were just absolute scores assigned to thoughts by a separate evaluation module, but Zhang et al. (2024) developed a technique based on direct pairwise comparisons. In this approach, instead of generating a single linear chain of intermediate reasoning steps or assigning scores to possible candidates, the model produces multiple candidate thoughts at key decision points and compares them in pairs to determine which one is the most promising. I will not go into the advantages of this approach over direct scoring, but in many cases, it is indeed better to compare things relatively rather than absolutely; here is an illustration from the paper:
Another interesting development was the Algorithm-of-Thought (AoT) approach by Sel et al. (2023), which formulated problem-solving as an algorithmic process, embedding instructions for tree-based reasoning directly into the prompt. Each node in the tree represents a step in the algorithm, with the model prompted to generate the next step based on prior results. AoT was mostly designed for tasks like multi-step mathematical reasoning and procedural planning, of course:
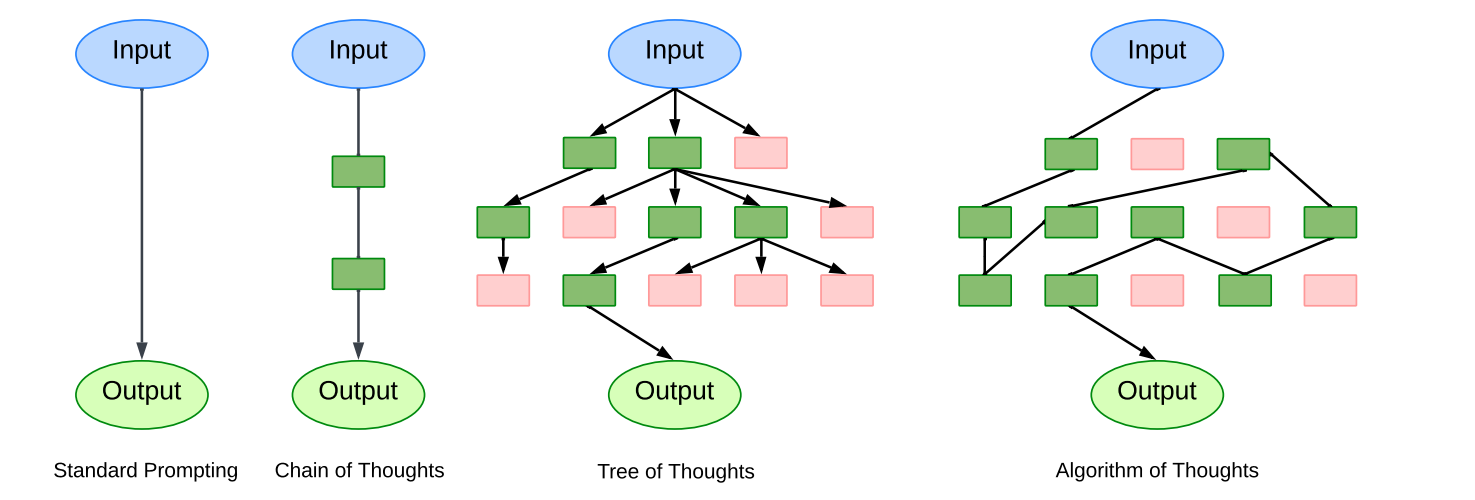
So more trees, more graphs, better comparisons—all good progress, but nothing too groundbreaking. Let me also mention the “tree of uncertain thoughts” by Mo, Xin (2023) and “tree of clarifications” by Kim et al., 2023—even without a detailed explanation you can already sort of understand what the idea is, right?
And then something unexpected happened: OpenAI released o1-preview. While chain-of-thought prompting opened the door to reasoning, OpenAI’s o1 series showed how to refine and scale it effectively; o1 models were the first to demonstrate what happens when chain-of-thought reasoning is taken to its logical extreme: scaling with test-time compute. Let us discuss that model and its implications.
The o1 announcement and system card. We already discussed o1-preview and its capabilities in an earlier post, “OpenAI’s o1-preview: the First LLM That Can Answer My Questions”. There, I mostly concentrated on how o1-preview could answer “What? Where? When?” questions (see the post if you don’t know what that means—it’s fun!) and other new capabilities, but the most important part was the part about a new scaling law. Large reasoning models can do better when given more computational resources at test time, a feature that is very rare in machine learning unless you count hybrid ML-plus-search solutions such as AlphaZero. Here is a sample plot from the original o1 announcement:

We discussed the implications in detail in the same post: if an LLM can feed on its own output and can benefit from more thinking time, this opens up a host of new possibilities. But how did o1 achieve that, what was the difference between CoT-based approaches that we discussed above and o1?
In fact, OpenAI did not tell us much about the training process of the o1 series; you can check their posts but there’s no detailed description there. In December, OpenAI released the o1 system card, but it was all about evaluations, both capabilities and red-team safety evals, and a little bit about the data, and not at all about the model. The safety evaluations, by the way, also looked sketchy since they had been made on a different, weaker version of the model (see a detailed description of this by Zvi Mowshowitz).
As for the actual approach, the system card just said what was already obvious: “The o1 large language model family is trained with reinforcement learning to perform complex reasoning”. While regular CoT asks a fixed model to process thoughts recursively, reasoning models are specifically fine-tuned with reinforcement learning to improve their thinking process.
We have already discussed how reinforcement learning (RL) helps LLMs help humans with RLHF. Adding reasoning capabilities is a natural next step. The idea is simple: generate a reasoning chain, use it as input for another inference, and repeat, like we humans can ruminate on their thoughts and ultimately arrive at novel thoughts that we did not have at first glance. Reasoning requires a model to plan, verify, and correct its own thinking—things that are not explicitly enforced in regular supervised training.
This again looks like a perfect setting for RL: the model is supposed to produce a number of discrete steps (thoughts) that lead to a reward only at the end (solving a problem), with no intermediate gratification. Just like learning to play chess, which has been done almost to perfection with exactly this “RL from scratch” approach of AlphaZero (Silver et al., 2017) and MuZero (Schrittwieser et al., 2019). Instead of just learning from fixed data, an RL-trained model should be able to explore different reasoning approaches, get feedback in the form of a reward, and refine its behavior over time:

Before we proceed to replications, let us discuss one more component in this RL process that seemed promising and necessary at the time.
Process reward models. In 2022, DeepMind researchers Uesato et al. (2022) suggested to upend one basic wisdom of reinforcement learning: never to reward the process, only the final state. If you are learning a game of chess, you do not know how good a given move is, you only know who wins at the end, and if you try to reward, e.g., winning material in the middle of the game you only make things worse: the RL model will engage in reward hacking, and you don’t actually care about killing a pawn, you care about winning the game.
But in long chain-of-thought style reasoning, an LLM will output its thoughts along the way, and every thought might be evaluated on its own merits. If the LLM is solving a math problem, we can assume that making an arithmetic error at some intermediate step is not some cunning plan that will lead to a correct proof, it’s just a mistake that can be found and corrected. If you train a model to find these mistakes, the result is a process reward model (PRM) that can pinpoint the mistakes:

This idea was taken further in a paper called “Let’s Verify Step by Step“, published by OpenAI researchers Lightman et al. (2024). Again, if the model outputs its reasoning as a sequence of steps, you can point exactly to which step went wrong:
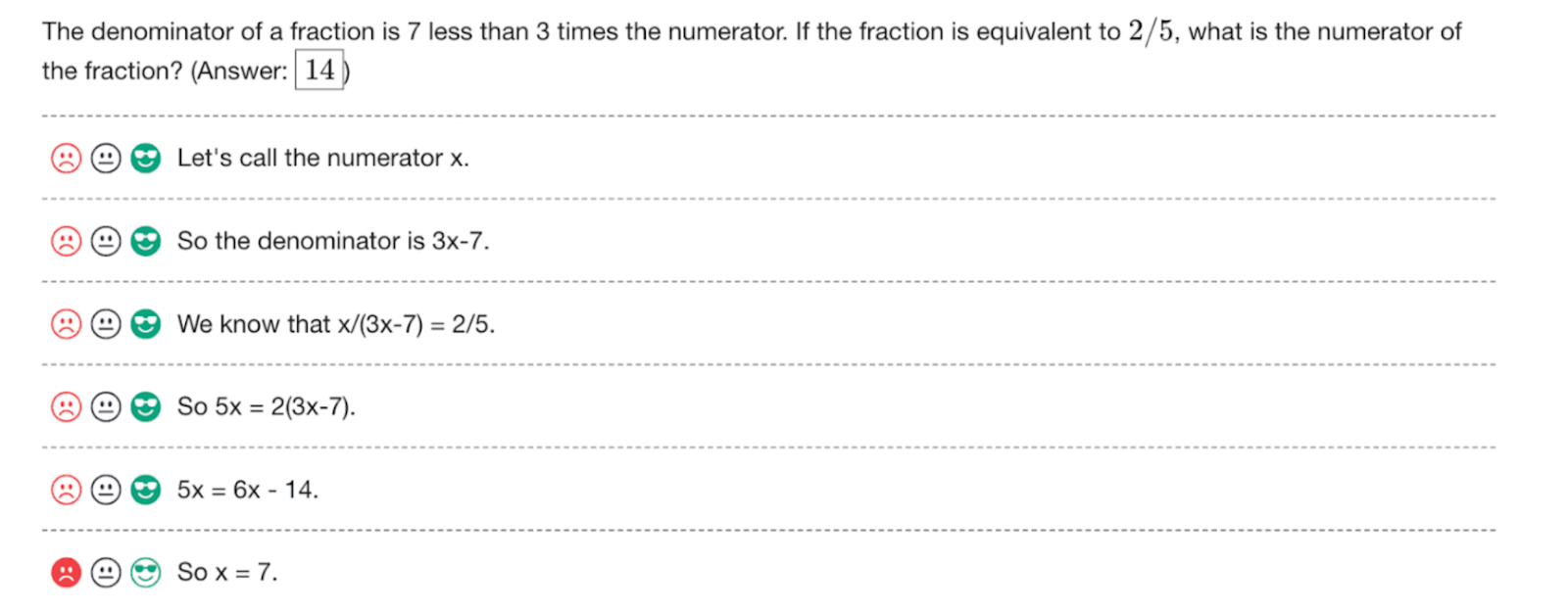
Therefore, Lightman et al. (2024) train a process reward model (PRM) to evaluate the entire thinking process, step by step. For a mathematical proof, it might work like this (the proof on the left is correct, and the proof on the right is incorrect):

This idea indeed improved reasoning and led to better results. A similar approach was put forward by Xia et al. (2024) who suggested an evaluation methodology called ReasonEval with this exact purpose—verify every step in the solution and find where the actual mistakes occur:

Although it was just an evaluation model, the authors also showed how to use it to improve reasoning: if you are doing distillation from the reasoning solutions by a stronger teacher model, it helps to filter them by the ReasonEval framework and fine-tune the student model only on the traces that are actually fully correct, not just correct in their final answer.
So given that PRMs were improved by OpenAI themselves, how exactly would the RL mechanism in o1 work?
O1 replications. Once the advantages of the new model became apparent (that is, immediately), researchers immediately started to suggest how exactly o1 might achieve this breakthrough. For a good representative of these guesses, see this post by Subbarao Kambhampati: “Imagine you are trying to transplant a ‘generalized AlphaGo’—let’s call it GPTGo—onto the underlying LLM token prediction substrate… the moves are auto-generated CoTs… the success signal is from training data with correct answers… let RL do its thing to figure out credit-blame assignment for the CoTs… during inference you can basically do rollouts”.
Sounds pretty plausible, but these were just speculations. Naturally, people have tried to actually replicate the new approach, that is, reinvent it and then implement. How did that go?
An interesting story unfolded in three papers by the same Generative AI Research Lab (GAIR) at the Shanghai Jiao Tong University (Qin et al., 2024, Huang et al., 2024, Huang et al., 2025). The papers were called “O1 Replication Journey”, and the authors’ original intention was to create and openly document the entire research process, from original ideation to testing hypotheses and all the experiments. The first paper was written after only a month of research, in October 2024; here is the timeline from Qin et al. (2024):
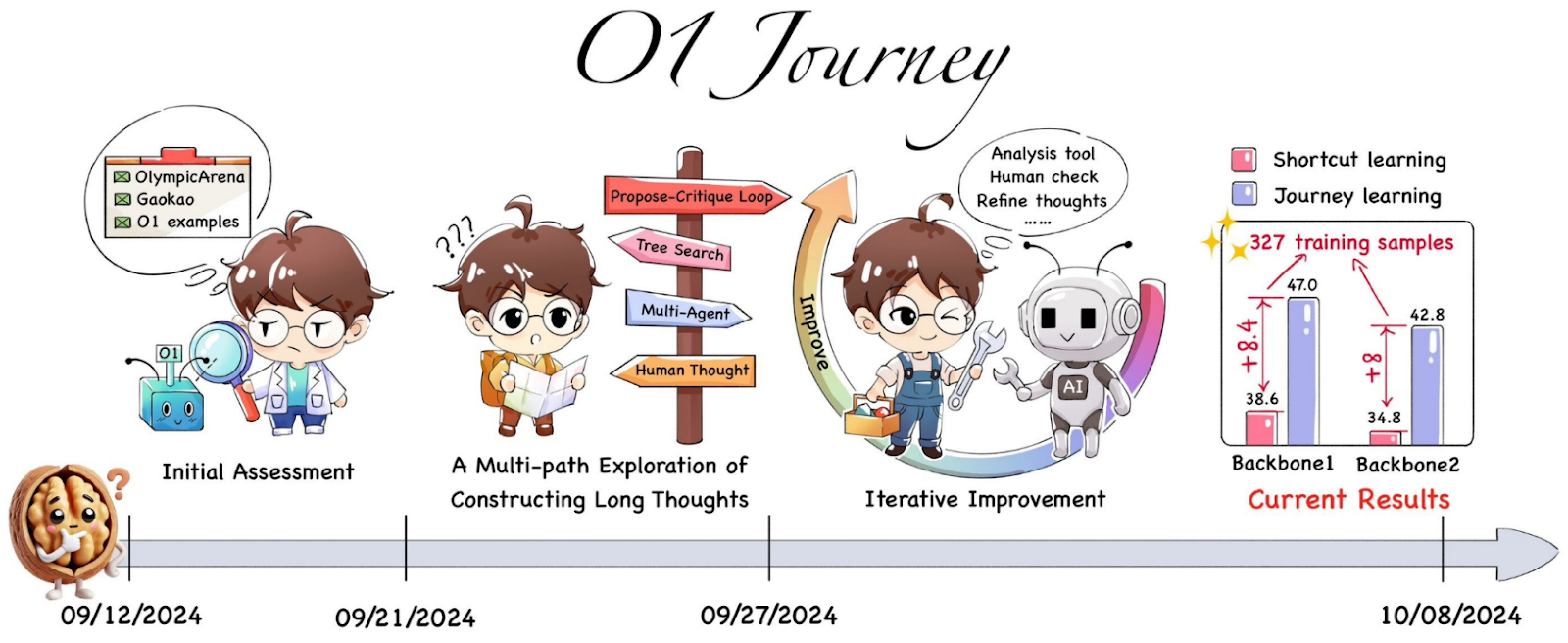
They introduced an approach called “journey learning”, where a model would be trained to output the entire exploration process, including backtracking and failed hypotheses. Qin et al. (2024) showed some original encouraging results and proposed a plan for further research. Their plans involved process reward models and Monte Carlo tree search as a promising algorithm for growing trees-of-thought during test time, and generally the paper reads like the optimistic beginning of a very promising research project.
Guess what happened next? In less than two months, the lab published a report on the second part of their project (Huang et al., 2024). Their main result was that… once you’ve got a dataset of reasoning traces, you don’t need anything else! The best approach for them proved to be knowledge distillation—basically, using o1 to teach a smaller model by copying its answers and learning from them. The researchers found that with a pretty straightforward approach—supervised fine-tuning on tens of thousands of responses from o1’s API—they could surpass o1-preview in solving complex math problems, specifically on the AIME Olympiad style dataset. Even more surprisingly, the distilled model showed strong generalization—despite only being trained on math problems, it performed well in open-domain question answering and even became less prone to agreeing with misleading questions (what they call “sycophancy”). In just two months, the big project with a lot of moving parts was reduced to this:
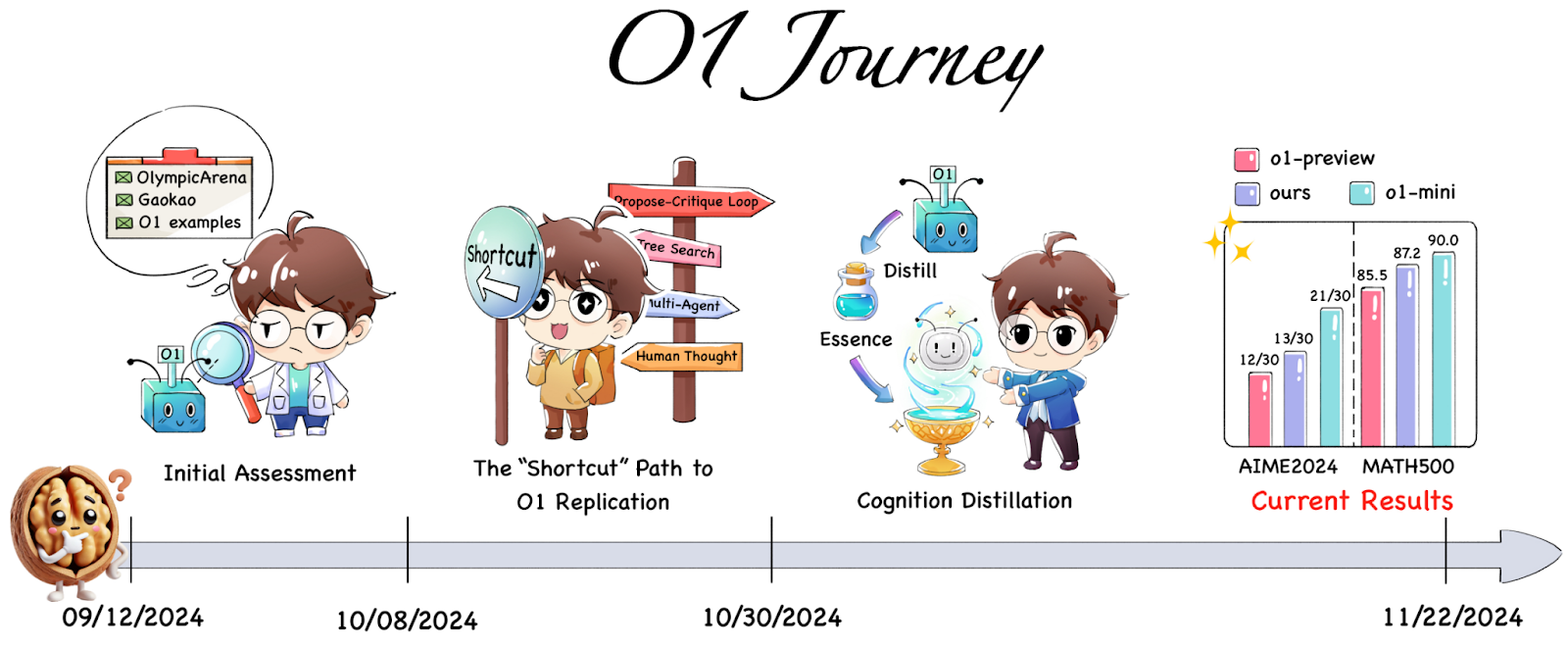
“The bitter lesson” in this case sounds like this: once OpenAI has made o1 available, even in a restricted form, the best way to improve the performance of your model is to use o1 reasoning traces for distillation. You don’t have to actually do anything novel except maybe some filtering procedure—a smarter model is all you need.
However, Huang et al. themselves point out why this approach looks highly suboptimal from a wider point of view:
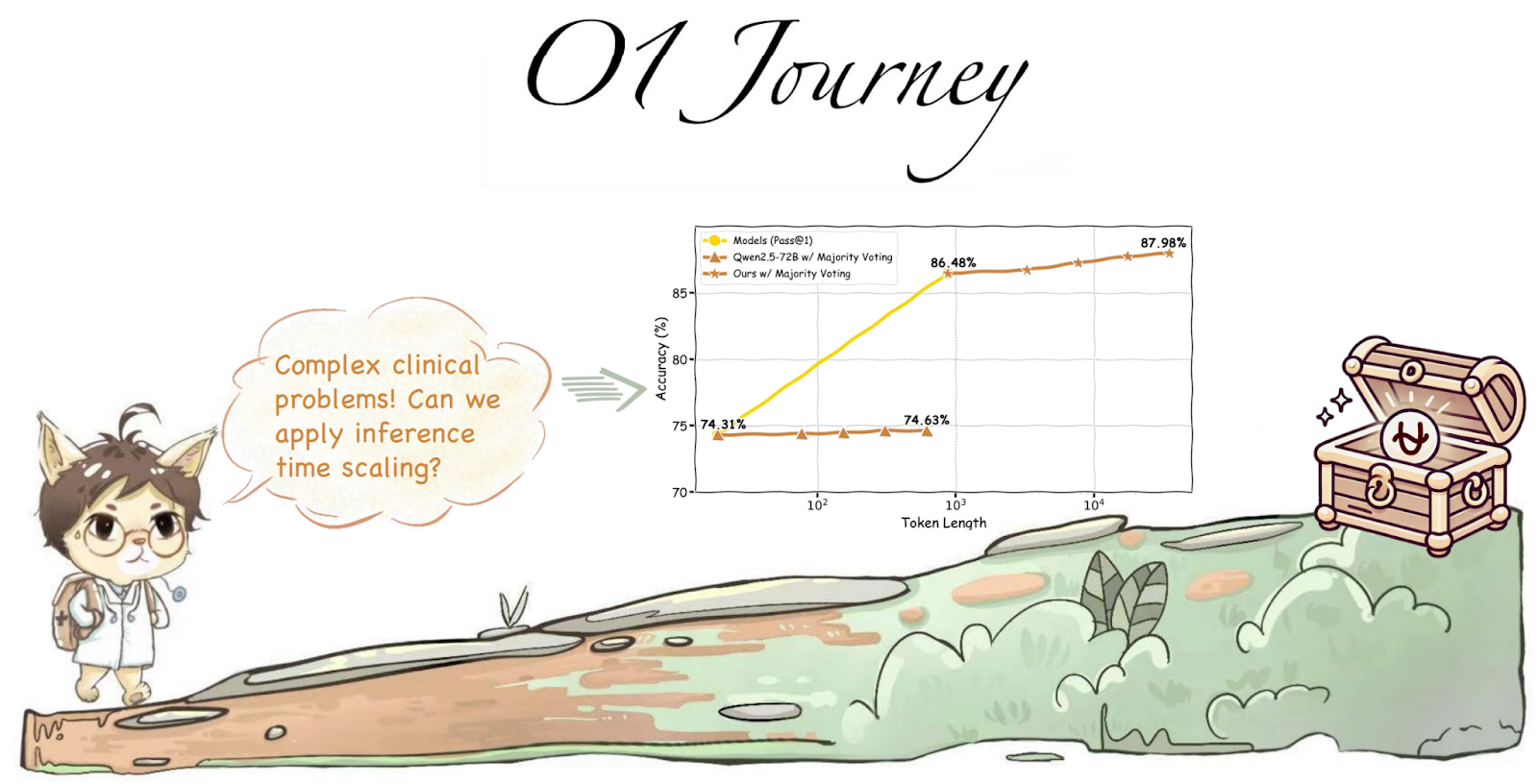
After publishing this report, both optimistic and disappointing at the same time, the GAIR lab found a more specialized field of application for their efforts. The third part of their o1 replication journey, published in January by Huang et al. (2025), concentrates on medical reasoning, showing that inference-time scaling can be helpful for medical diagnoses and treatment planning:
There have been other replication attempts as well. In December, Zeng et al. (2024) published a paper called “A Roadmap to Reproduce o1” where they surveyed existing approaches to reinforcement learning that might be relevant, including process reward models, reward shaping, and various search techniques that might be used both in training and on inference. They provided a lot of educated guesses on how o1 might operate, but this was still just a roadmap.
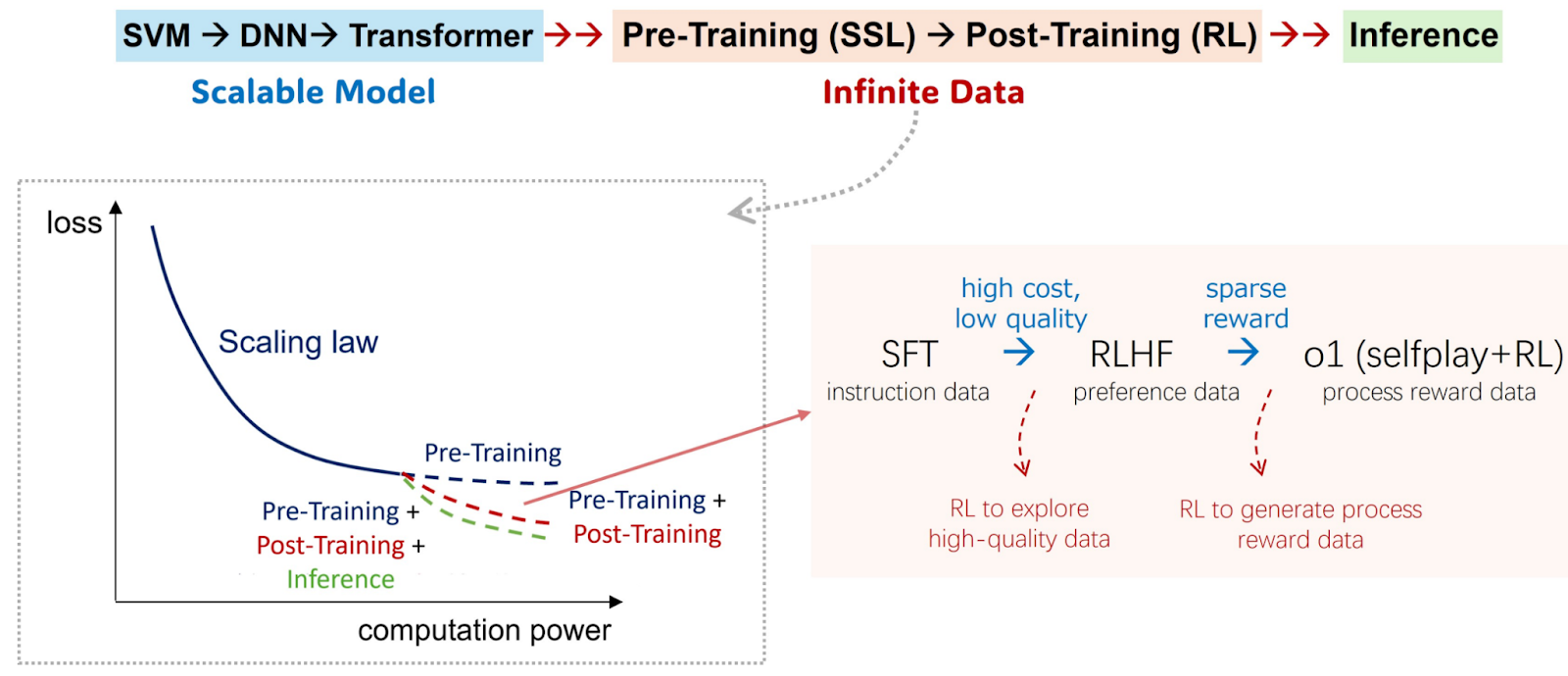
There were more practical replication attempts too. Zhang et al. (2024) released o1-Coder, a model that was specifically designed for programming, a domain where self-play and checking the reasoning step by step work just as well as in mathematical reasoning. They also incorporated a process reward model and used Monte Carlo tree search (MCTS) to improve thinking at test time. Here is their take on the sequence of ML progress, emphasizing that self-play and self-evaluation basically equals infinite synthetic data:
Industrial players also quickly followed suit: LLaMA-o1 appeared for the LLaMA family (SimpleBerry, 2024) and was later improved to LLaMA-Berry (Zhang et al., 2024), the Qwen team released QwQ, and so on. In LLaVA-o1, Xu et al. (2024) expanded o1-style reasoning to vision-language models. But the main treat was still ahead.
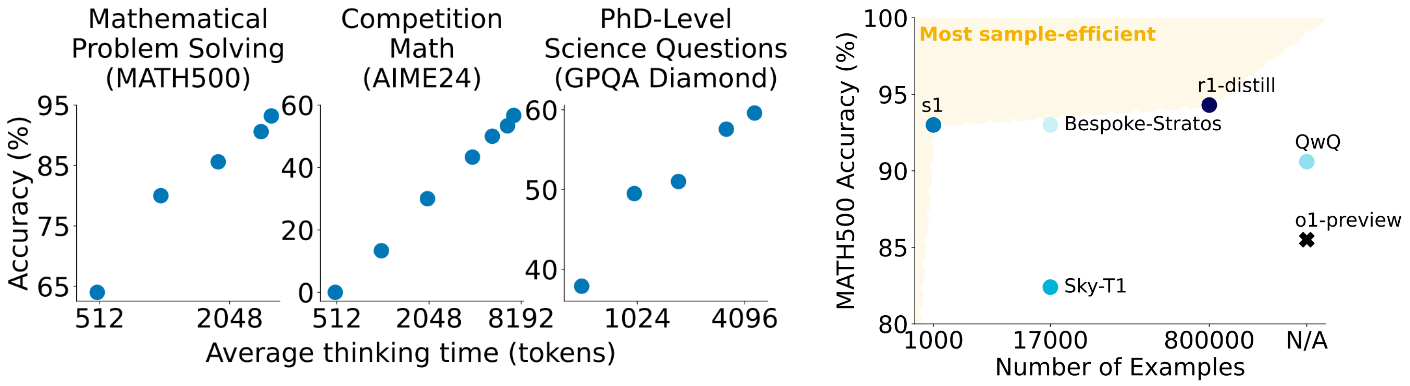
Before we get into the details of R1, let me jump a little bit ahead in time. As I was writing this post, the bitter lesson struck again: on January 31, a reasoning model called s1 was published by Stanford researchers Muenninghoff et al. (2025). This model, with 32B parameters, was trained by pure distillation on a small dataset of 1000 examples, for a total training cost of about $50. While it did not outperform o1 or DeepSeek-R1, it came pretty close in many benchmarks and already exhibited the same kind of test-time scaling that one would expect of good reasoning models and put the model at a very good point on the Pareto frontier of sample-efficiency:
Moreover, Muenninghoff et al. found some creative but ultimately very straightforward ways to turn additional computational budgets into more intelligence:
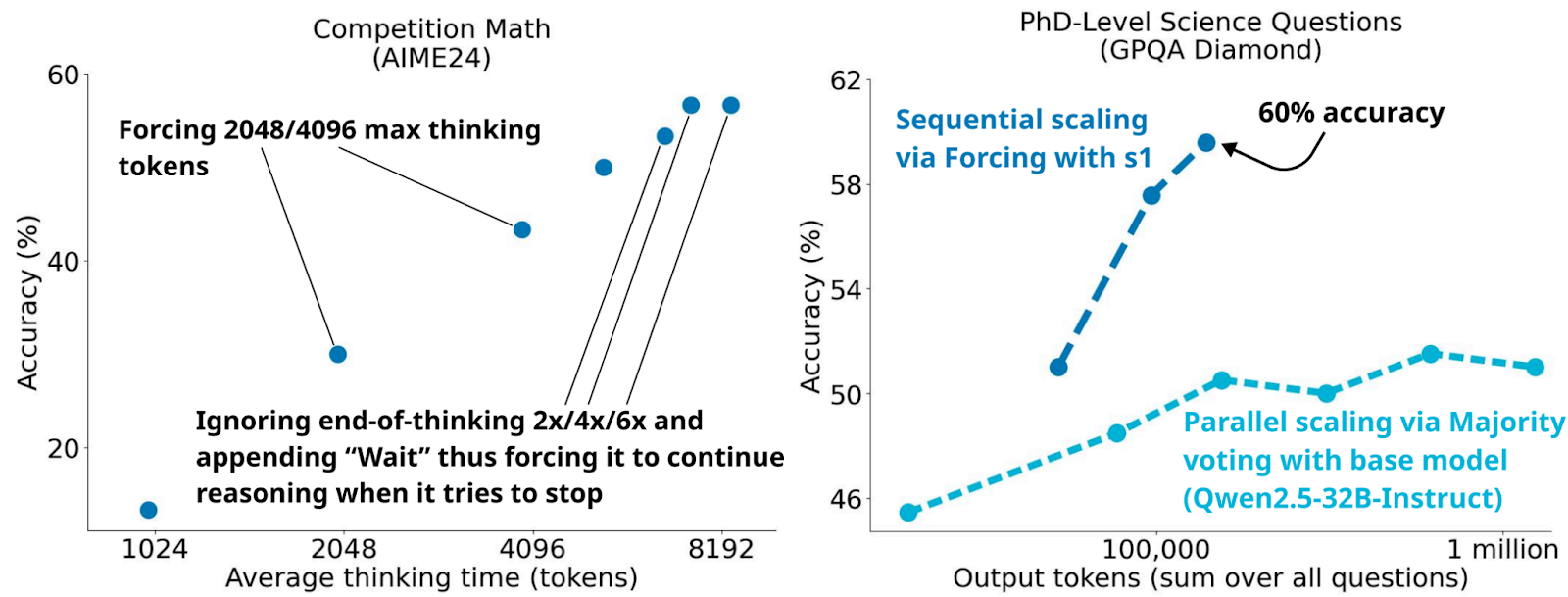
Interestingly, both ways yield significant gains with no change to the underlying model. So yes, the bitter lesson is here in full: once you have a stronger model, distillation is all you need to get smaller ones, and raw scaling of compute in very simple ways can often yield additional benefits. Even wisdom of the crowds seems to work for a crowd of one!
But let’s go back to the main topic. On January 20 (with the paper appearing on arXiv on Jan 22), DeepSeek-AI (2025) released their own replication. The DeepSeek-R1 model made such a splash in the AI community that it overflowed to the general public much more than usual. Moreover, this was a replication accompanied by a detailed academic description in the paper, so we can actually understand and analyze what’s happening in R1. In the rest of this post, we will try to understand what exactly DeepSeek did with R1, and to understand that, we need to begin with reinforcement learning. So let us step back a little.
Policy gradient methods in RL. Large language models (LLMs) are typically trained through supervised learning—they consume massive datasets of human-written text, training to predict the next token in a sequence. By now we all know that this approach produces models that can generate fluent text, but it does not necessarily make them good at reasoning or even helpful at all. We have discussed that to get to optimal reasoning we need to fine-tune the reasoning chain with reinforcement learning.
What kind of RL do we need? There are two general approaches to RL:
In general, policy-based methods are usually more efficient in terms of necessary data, so they would be clearly preferable for LLMs. They have an inherent difficulty in that selecting actions is a piecewise constant function that would not allow gradients to go through, but this problem has been resolved over thirty years ago in the REINFORCE algorithm (Williams, 1992), resulting in the so-called policy gradient algorithms. Formally speaking, the algorithm is trying to maximize the expected cumulative reward as a function of the policy π with parameters θ,
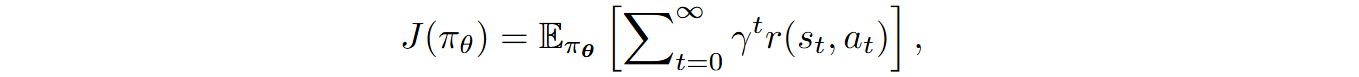
where r(st, at) is the immediate reward on step t and γ is the discount factor, and via the policy gradient theorem you can compute the gradient of the objective function J as
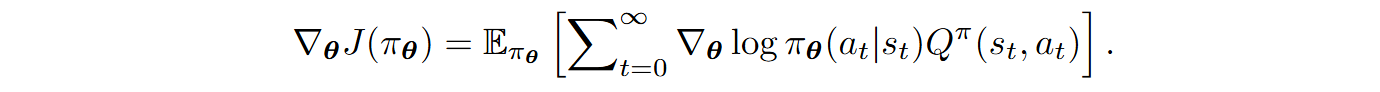
Actor-critic approaches. The REINFORCE algorithm used the objective function J and its gradient directly, but there are severe disadvantages to this approach. There is a catch in policy gradient methods and RL in general: rewards are often sparse (you only get a score at the end of a sequence) and always stochastic (a given sequence is randomly generated). This leads to all estimates being extremely noisy, with huge variances, and further work in RL focused on reducing this variance.
To reduce noise, modern policy gradient methods such as proximal policy optimization (PPO, ) use advantage estimation, learning a separate critic model to predict how much better an action is compared to the average in this state. The critic learns this average, i.e., basically the state value function:

Formally speaking, this amounts to adding a baseline of V(s) to the objective function; it is easy to check that it actually does not change the optimization results (since the sum of action probabilities is a constant 1):
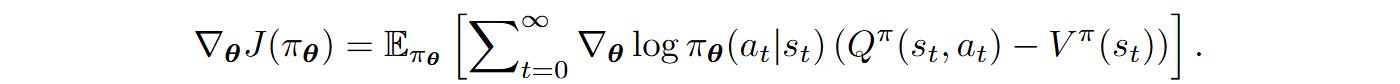
Although formally nothing has changed, in reality the noise has been much reduced at the cost of training a separate model with parameters η to estimate Vη(s).
Overall, actor-critic algorithms (Konda, Tsitsiklis, 1999) work as follows: in a loop,
Later work introduced parallelization schemes with synchronous and asynchronous updates such as A3C and A2C (Mnih et al., 2016) but the main actor-critic paradigm remained unchanged.
Proximal policy optimization. The actor-critic paradigm, however, has one more significant drawback: the gradients may grow large, and updating policy weights too aggressively can cause performance to collapse, leading the policy completely away from reasonable regions.
To alleviate this, proximal policy optimization (PPO; Schulman et al., 2017) introduced a clipped objective function; on a step t,
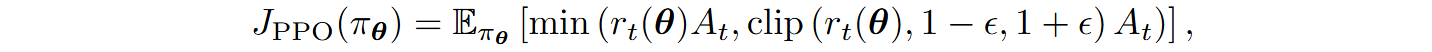
where ε is a small constant, typically 0.1–0.2, and rt(θ) is the ratio function that compares how likely it is to choose the action at in state st for the new policy compared to the old one:
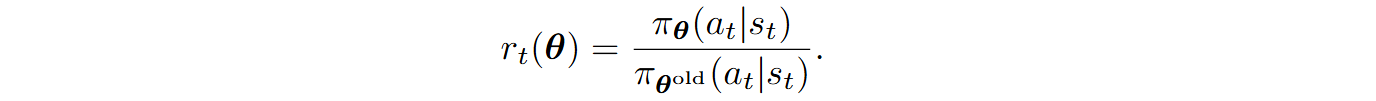
In other words, PPO implements the update directly if it is small, but if the resulting change in probability is too aggressive, PPO clips it, trying to stay inside the trust region of reasonable policies.
Clipping the objective function stabilizes training while still allowing for exploration. Note that I have omitted the sum over t in the formula above, partly to reduce clutter but also because in practice policy gradient algorithms update the weights after a batch of experience is collected, and timestamps are sampled from this replay buffer rather than all summed together.
PPO was in fact a simplification of the trust region policy optimization (TRPO) algorithm proposed earlier by Schulman et al. (2015). In TRPO, the trust region was made explicit with a constrained optimization problem:
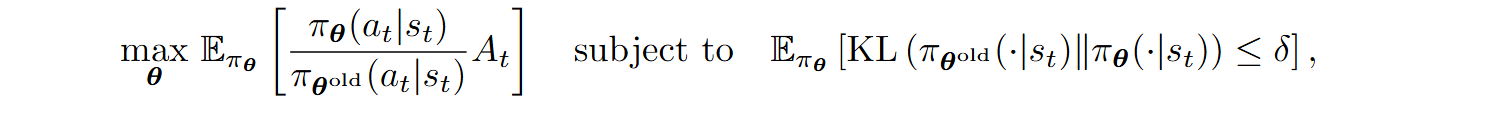
i.e., maximize the expected reward in a region where the new strategy is similar to the old strategy as a distribution over actions taken in state st, formalized with the Kullback-Leibler divergence between them. Standard optimization theory tells us that instead of a constraint you can use a penalty, a regularizer on the KL divergence:

This KL penalty term was replaced with clipping in PPO, but when PPO started being applied to actual LLMs, further regularization was required as the policies would venture too far from the original, engaging in reward hacking or forgetting pretrained knowledge. Therefore, InstructGPT (Ouyang et al., 2022) added another KL regularizer to the objective function in their RLHF procedure:
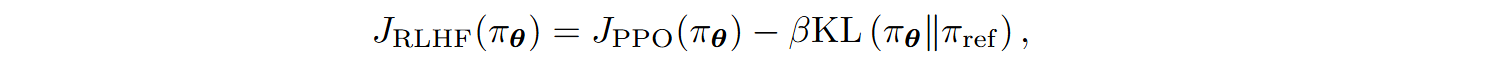
where πref is some reference policy, e.g., the one obtained after supervised fine-tuning but before any RL-based fine-tuning.
From PPO to GRPO. PPO and similar algorithms such as TRPO work well, but they still are actor-critic algorithms, i.e., they require a critic model to estimate the advantage function At. This effectively doubles the computational costs since the critic is as large as the policy model, and if the critic does not train well it can introduce bias and lead policy learning astray. For LLMs, both the costs are very high, and the bias problem is more severe since the sequences are significantly longer than usual: you get a reward only for the last generated token in a sequence of thousands, compared to, say, a chess game that lasts for several dozen moves.
Therefore, the DeepSeek team introduced a new variation of policy gradient algorithms called group relative policy optimization (GRPO) in their previous work on DeepSeekMath (Shao et al., 2024). The idea is simple: we need the critic to effectively normalize the reward estimates. So instead of using a separate model for a critic, we could normalize by sampling several different outputs (answers) from the policy model (LLM) and averaging over them. It’s just like batch normalization: we replace absolute value estimates with statements like “answer 2 is 1.5σ above average”. Adding the same KL-based regularizer as InstructGPT, we get

where the averaging goes over a mini-batch of G answers sampled from the LLM; estimates of the action advantages are also derived from the same mini-batch:
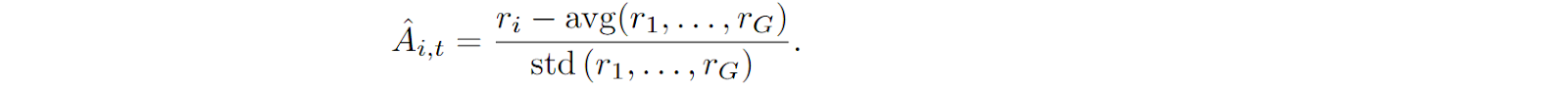
Here is a graphical comparison of PPO and GRPO by Shao et al. (2024):
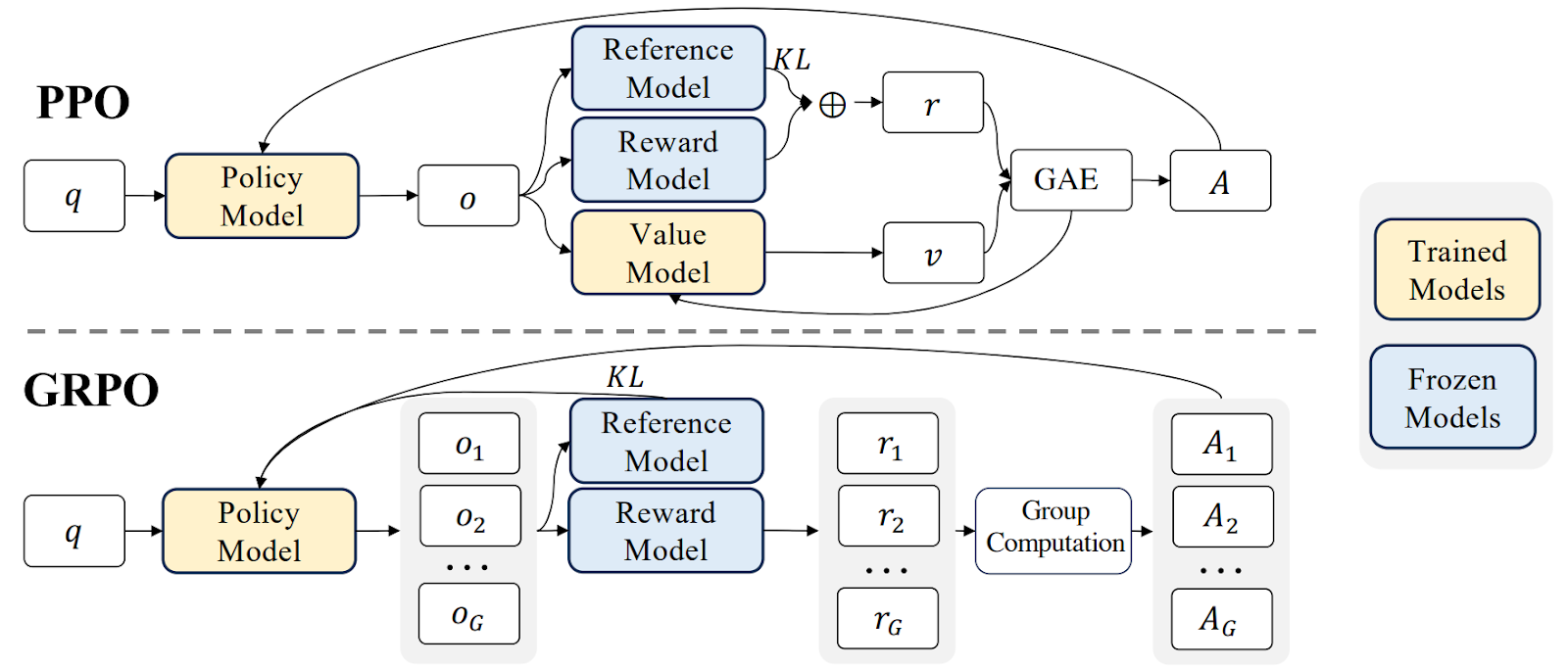
To give you an intuition of why this makes sense:
This comes at a computational cost, of course: if you want to average over a mini-batch of G=16 outputs, it means that you have to run your model 16 times.
In a way, policy gradient algorithms have made a full circle, first introducing a critic model and then getting rid of it when the models have become too large:
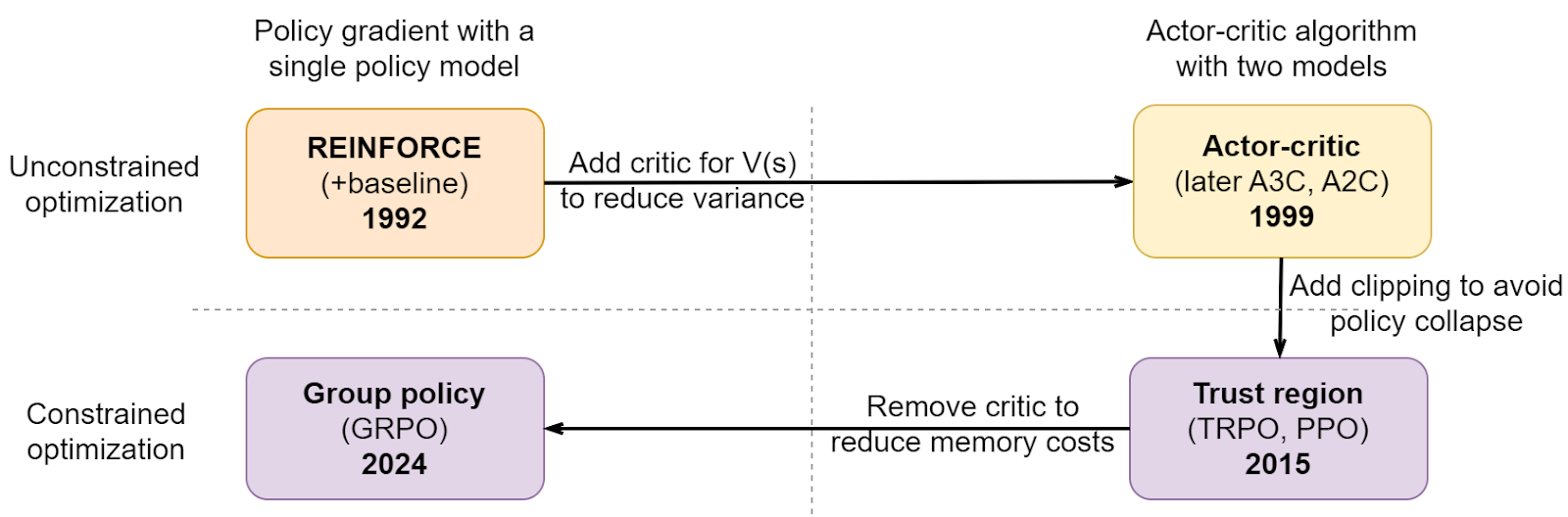
This is not to say that actor-critic algorithms are now obsolete, of course, they are still preferable in many, if not most, situations since often you will not run into the absolute limits of available memory with a single model. But it is interesting how easy it was to get rid of the critic as soon as it became necessary.
So where did that get DeepSeek? DeepSeek’s response to o1 was not just replication—it was an ambitious rethinking of model architecture and training efficiency. Now that we are clear on their main RL novelty, let us examine the other pillar of R1: their latest DeepSeek-V3 model.
Basic structure of DeepSeek-V3. Okay, so by now we understand how RL can be used to improve its reasoning abilities of an LLM, and we have been talking about LLMs for a long time (one, two, three, four, five…). Is that all? Has the DeepSeek team just run the RL on an open LLM like Llama, and increasing capabilities together with their GRPO algorithm have made R1 possible?
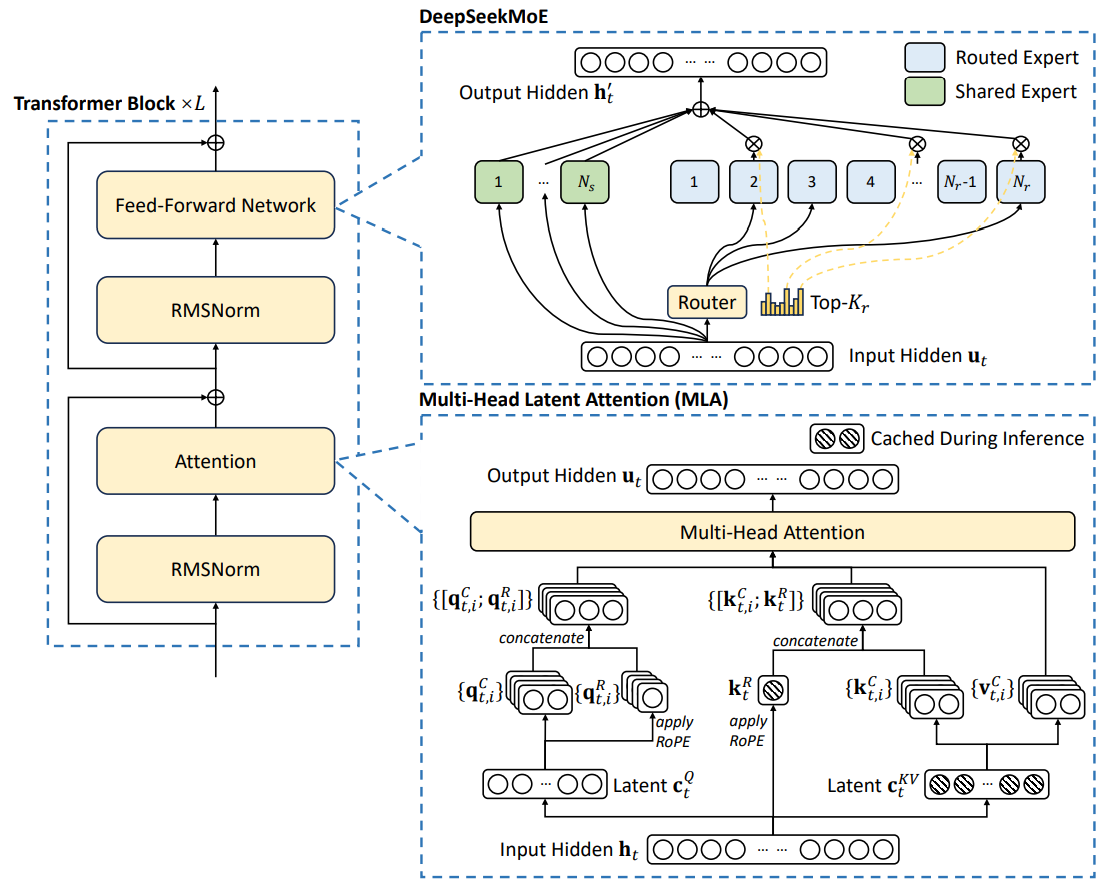
Yes and no. First, they ran GRPO not on Llama but on their own model, DeepSeek V3, released last December (DeepSeek-AI, 2024). DeepSeek V3 has had its own share of new interesting ideas. First , it is a huge mixture-of-experts (MoE) model, with 671 billion parameters in total but only 37 billion active per token and a new load balancing strategy. I hope to write a separate post on MoE approaches so let’s not get into this one now; suffice it to say that in the feedforward part of each Transformer layer, there are many parallel processing paths (experts) and a separate router subnetwork that chooses a few of them (top-k according to its scoring) to activate.
Second, DeepSeek-V3 uses multi-token prediction (MTP) as part of its training objective: instead of just predicting one token per time step, the model is trained to predict multiple future tokens at once. This is not an entirely novel idea; it sounds very straightforward and indeed had been shown to work by Gloeckle et al. (2024) about a year ago. They used a multi-head architecture to predict several tokens at once and showed some improvements:
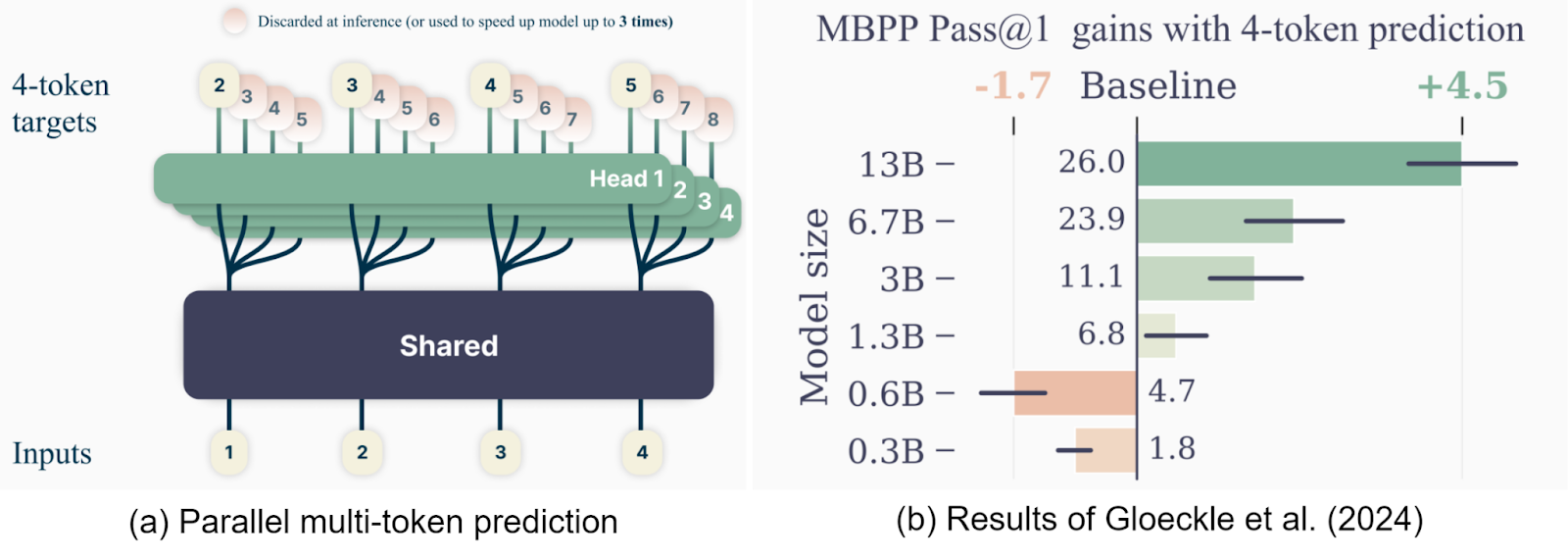
Unlike Gloeckle et al. (2024), DeepSeek predicts several tokens sequentially, keeping the causal chain for every token and predicting the next token with another Transformer block that receives representations produced by the previous blocks as input:
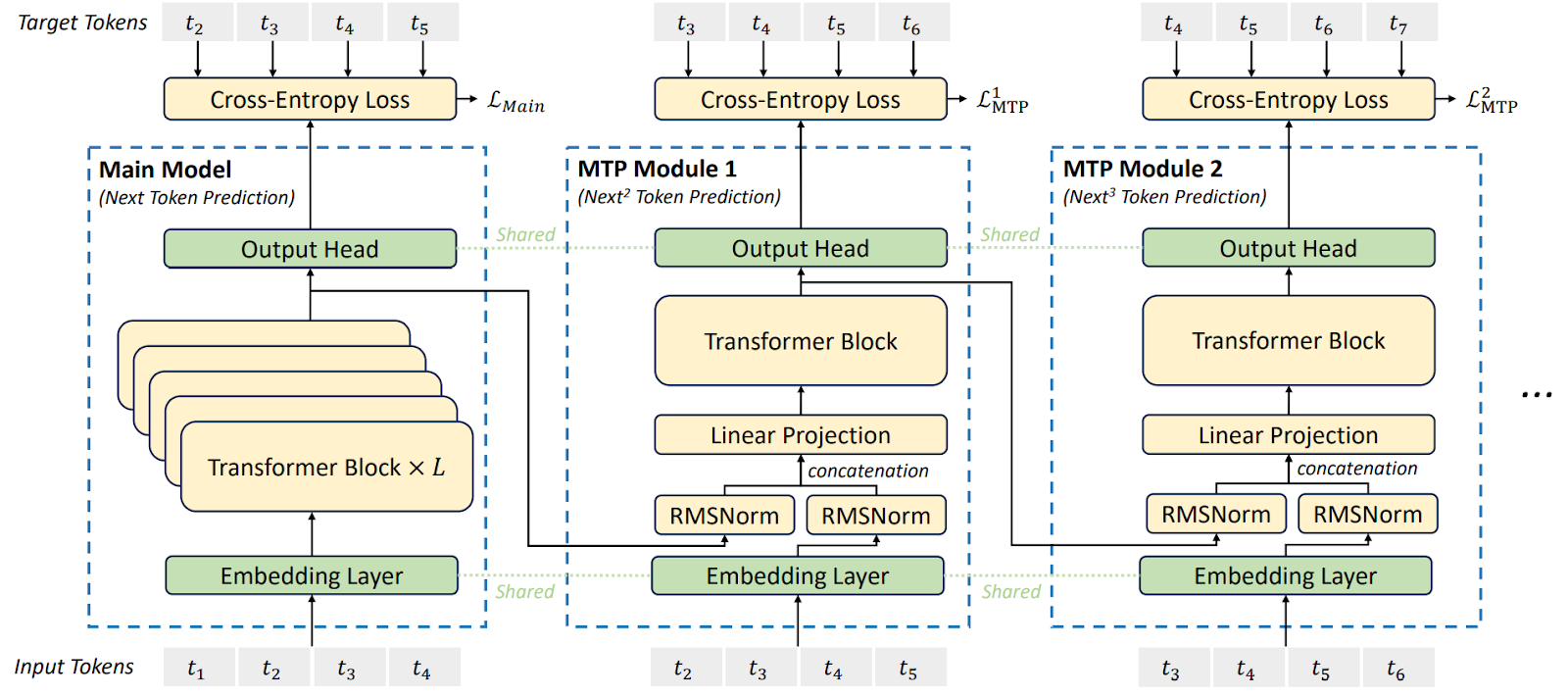
MTP provides a denser signal and helps the model to “plan ahead” better even before any RL is added.
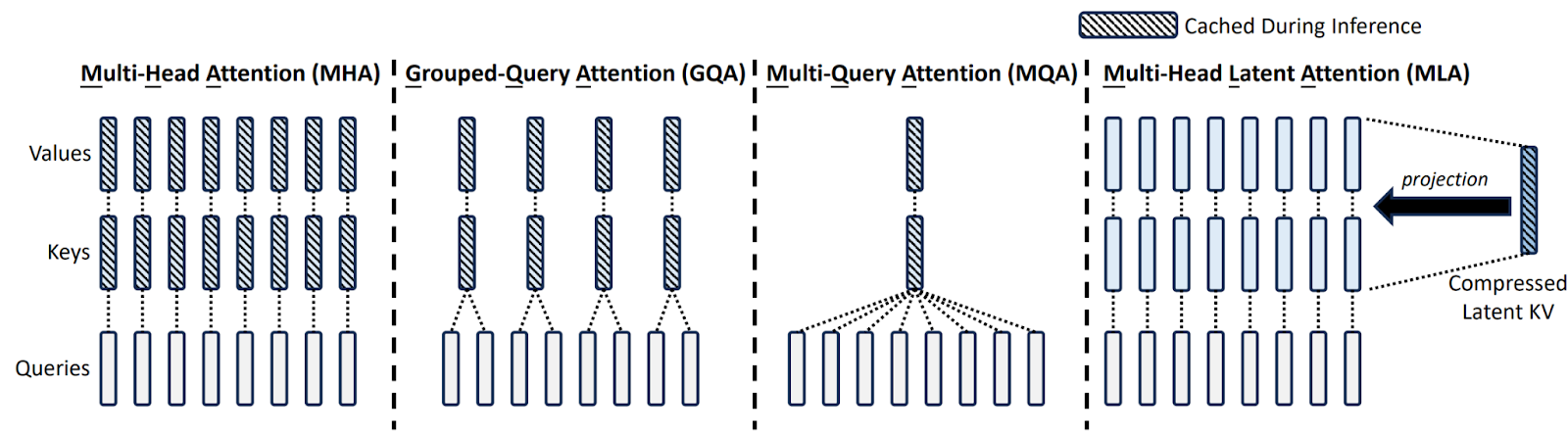
Key-Value Caching and Multi-head Latent Attention. Third, DeepSeek uses the multi-head latent attention (MLA) in its Transformer layers instead of the standard multi-head attention (MHA). This is an approach based on a low-rank approximation to MHA, and although we have discussed similar techniques in a post on extending the context, MLA is new for us because it was introduced only in April 2024, in the DeepSeek-V2 paper (DeepSeek-AI, 2024b). Let us consider it in detail.
We know the standard MHA mechanism: queries, keys, and values are computed as
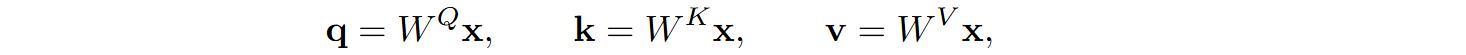
and the results of MHA are given by
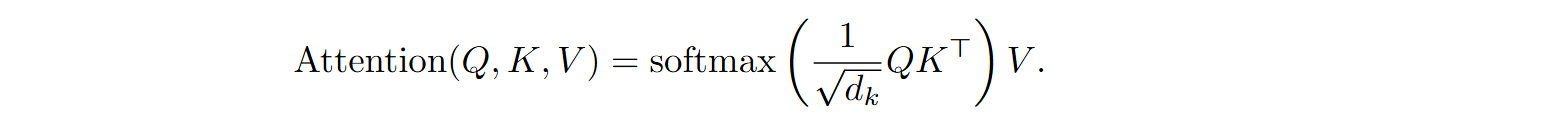
We know that the QKT matrix, which has size L⨉L for an input sequence of length L, is a bottleneck of quadratic complexity, and discussed ways to alleviate it.
But even if we accept the computational complexity, another important bottleneck here is memory needed for key-value caching. To make generation efficient, in standard MHA each token caches a full set of keys (K) and values (V) for every attention head. In this way, queries from newly generated tokens can be much more efficiently processed through the decoder as most keys and values are already precomputed. Note that this is an approximation: theoretically, representations of all tokens—and hence all keys and values—should change with every new token starting from layer 2, but in practice old tokens reuse their keys and values; otherwise generation would be computationally intractable.
Key-value caching is a standard technique, but when dealing with long sequences (like DeepSeek-V3’s 128K context length), this KV cache becomes very memory-intensive. Researchers have developed some approximations to reduce it:
DeepSeek’s MLA takes another step in the same direction. Instead of directly computing and caching full K and V matrices, MLA projects them into a compressed latent space using a down-projection (compression) matrix WC:
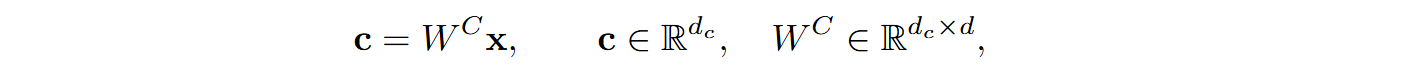
where the compressed dimension dc is much smaller than the original d. During inference, keys and values are restored with reconstruction matrices (also trained):
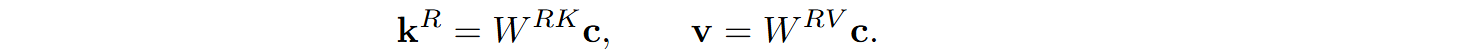
At this point, we are done with the values v, and the keys k are also further augmented with positional embeddings; DeepSeek uses RoPE rotary embeddings (Su et al., 2024) that are applied to a separately reconstructed version of the key and concatenated to kR:

Here is an illustration from the DeepSeek-V2 paper (DeepSeek-AI, 2024c):
Queries are not cached, and they were processed in a standard Transformer way in DeepSeek-V2, but in V3 they also undergo a similar procedure, this time to reduce the memory needed for activations during training:
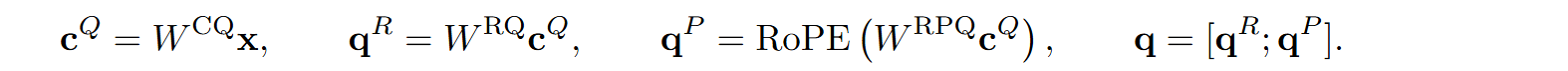
As a result, instead of storing full keys and values for each token, DeepSeek models store only a compressed dc-dimensional latent representation. Keys and values are reconstructed only when needed, saving memory while maintaining efficiency, and as a result DeepSeek V3 can handle up to 128K token windows without exploding KV storage.
At this point, we are done with the DeepSeek-V3 architecture; here is a general illustration (DeepSeek-AI, 2024):
There are also plenty of tricks in the design of the training pipeline that made DeepSeek’s training so efficient, but I will not get into those here and will simply refer to the original paper (DeepSeek-AI, 2024). For us, it is more interesting to see how this could turn into a reasoning model.
From V3-Base to V3. By training the model described above on 14.8 trillion high-quality tokens (data preparation is another big challenge that we will not discuss today), DeepSeek obtained what is called DeepSeek-V3-Base: a raw pretrained model that has not yet been fine-tuned for alignment, real-world usage or, for that matter, reasoning.
To get to DeepSeek-V3, the authors do a standard fine-tuning stage with SFT (supervised fine-tuning) on a carefully curated instruction tuning dataset of 1.5M instances and RLHF with human annotators for data that requires human evaluation: roleplaying in dialogues, creative writing, that sort of thing.
The most interesting part for us is that in SFT, DeepSeek-V3 also uses distillation from DeepSeek-R1 answers: the instruction tuning dataset is extended with samples that show the R1 responses. To get these responses, we need to get to R1 first, so now we switch over to the latest DeepSeek paper that details the reinforcement learning part (DeepSeek-AI, 2025).
R1-Zero: no-nonsense RL training. On the surface, reinforcement learning for reasoning LLMs sounds simple: just reward correct answers and let RL do its thing. It has always been tempting to just run a RL algorithm on a pretrained LLM without any hassle of collecting instruction tuning datasets for SFT, getting human annotators, and so on—so, of course, DeepSeek tried just that!
They started with DeepSeek-V3-Base, used the GPRO algorithm that we discussed above, and defined a reward function with two components: accuracy rewards for actually answering the questions correctly and format rewards for keeping the thinking process within specified tags. As it often happens with RL, it is best not to reward the process but only the result; otherwise models may arrive at reward hacking, producing high rewards with undesirable behaviour. This is a very interesting topic (alas, a topic for another day), and modern LLMs do absolutely engage in reward hacking—see, e.g., a recent post by Lilian Weng.
Note a very important caveat here: to know the reward function, we need to know the correct answers to the problems! DeepSeekMath, a previous effort by the same team (Shao et al., 2024), collected a large curated DeepSeekMath Corpus with mathematical text extracted from the Common Crawl dataset, but this time we need more than just tokens to predict—we need problems, preferably hard problems, with known answers.
For math and coding, this is relatively simple: you can choose math problems that can be solved by formalized external solvers such as SymPy programs, and for coding you can choose problems that have a comprehensive suite of tests available. You can also generate synthetic data along the same lines. This, together with question answering data with known answers, constitutes most of what DeepSeek calls “rule-based rewards”. Still, it is interesting that the DeepSeek-R1 paper does not specify the exact datasets that it used in reinforcement learning.
Note also that this is the main reason why reasoning modes are currently more useful for math and coding than other tasks: math, coding, and direct question answering (QA) have correct answers that can be verified automatically. For a task like creative writing, there is no correct answer to compare to and no formalized set of tests that a solution must pass, only subjective human evaluation or equally subjective automated evaluation by another LLM, which makes a similar RL pipeline difficult to set up.
Glossing over the data question, let’s get on to the results. The authors show how the model’s performance grew with more and more reinforcement learning. Here is their plot on the standard AIME evaluation dataset (mathematical olympiad problems); pass@1 is the one-shot performance and cons@16 is the majority voting (consensus) across 16 runs of the model:
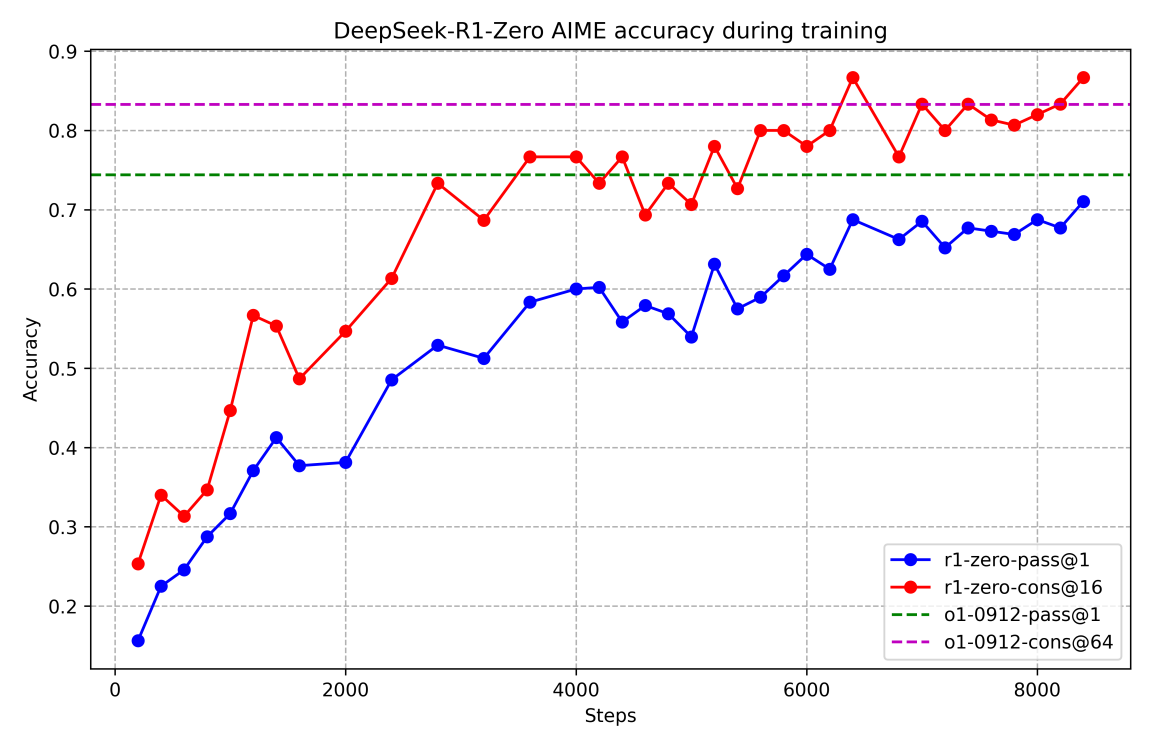
Note that running the model multiple times helps a lot even if we do not suggest human verification and simply take the majority vote of the answers; this is yet another facet of the test-time compute scaling that we discuss in this post.
As RL training progressed, R1-Zero learned to make better use of the thinking time, and the number of thinking tokens grew steadily throughout the training process:
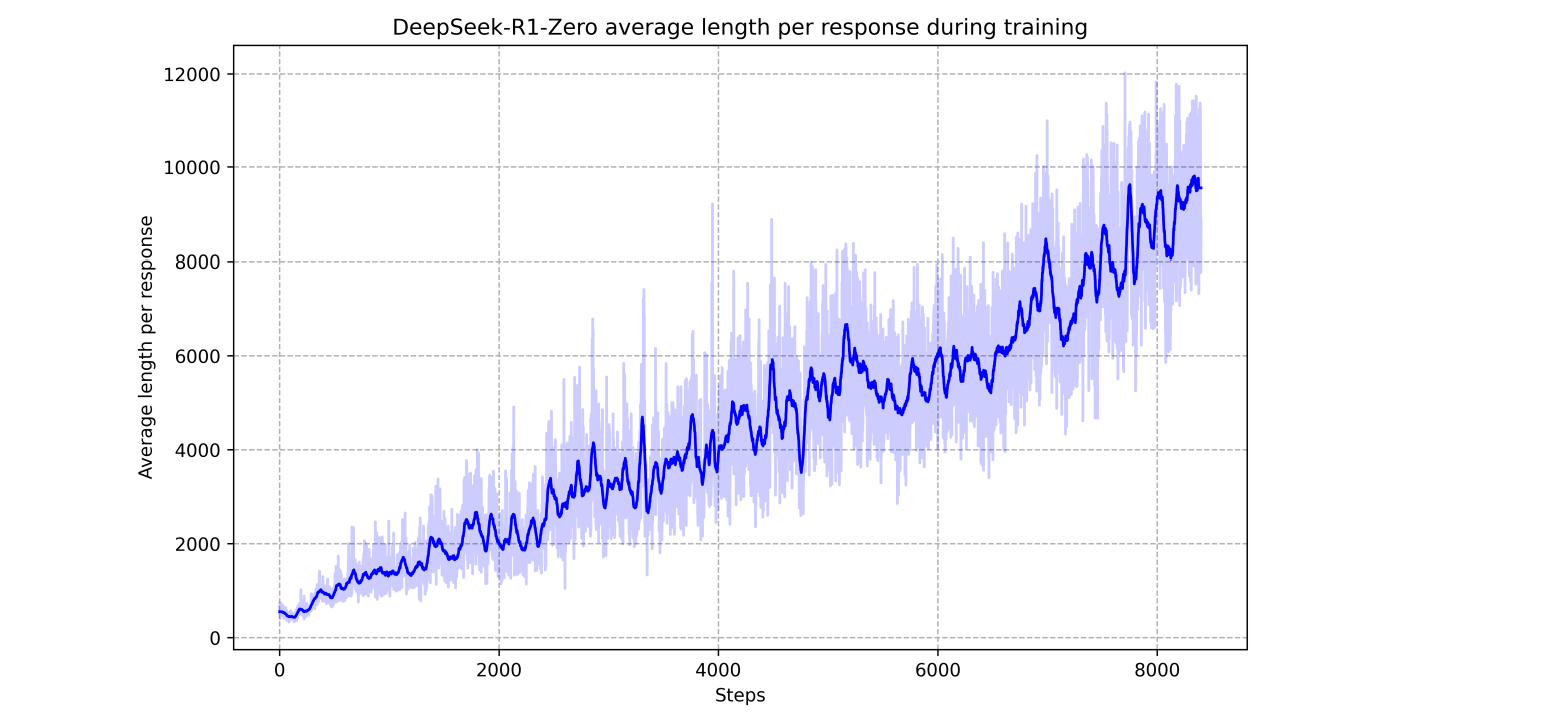
The authors note how exciting it was to witness the emergence of new behaviours in the model such as reflection (re-evaluation of previous thinking steps) and exploring multiple approaches to the problem. They also devote a whole subsection to an “aha moment” in R1-Zero’s reasoning, but, to be honest, I didn’t get their example at all:

To me, it looks like after the “aha moment” the model just repeated the exact same reasoning as above, and I don’t see any mistakes in the formulas the first time around; maybe there’s something I’m missing here, but the paper does not explain it any further…
Anyway, R1-Zero was already an excellent proof of concept for reinforcement learning for reasoning capabilities, but the DeepSeek team pushed one step further. If you can achieve results on par with a version of OpenAI’s o1 by pure RL, what can you do if you guide it with supervised fine-tuning as well?
From R1-Zero to R1. To get to the full R1 model, DeepSeek researchers adopted the following process:
To me, the fact that the authors obtain a separate dataset of 800K samples screams one word: distillation! Once you have already implemented the curation and filtering process, it is easy to reuse the resulting dataset for other models as well: just fine-tune them on the same samples produced by the intermediate R1 checkpoint, or, even better, by the final R1 model.
Naturally, DeepSeek researchers did this immediately, and this is exactly the SFT step of training the final DeepSeek-V3 (non-reasoning) model. Moreover, the authors did distillation on Llama and Qwen models, and we will see the results below. Note, however, that they only did an SFT distillation step and did not try to subject other (non-DeepSeek) models to their reinforcement learning pipeline. This, as they themselves note, may yield additional benefits, so we will see what other researchers with appropriate computational budgets can do with it.
But one of the most important takeaways from R1 lies not in what they did, but rather in what they did not end up doing. While everyone else was trying to incorporate PRMs and MCTS into their RL environments, DeepSeek researchers included a section called “Unsuccessful attempts”, where they report that:
The bitter lesson strikes again, this time in a weaker form: it turns out that you don’t need detailed guidance for the model, you just need to set up the basic training process in the right way. This was unexpected for many researchers, and it was one of the reasons why DeepSeek-R1 became so popular in a field already replete with o1 replications.
Results. Another important reason for why DeepSeek-R1 made a lot of noise was because the evaluation results were simply very high. New models appear from time to time, but this was a reasoning model that actually reached the levels of OpenAI o1 and even exceeded them.
On math and coding benchmarks (which are o1’s forte as well), R1 showed results on par and slightly exceeding the full o1 model and significantly ahead of the o1-mini model:
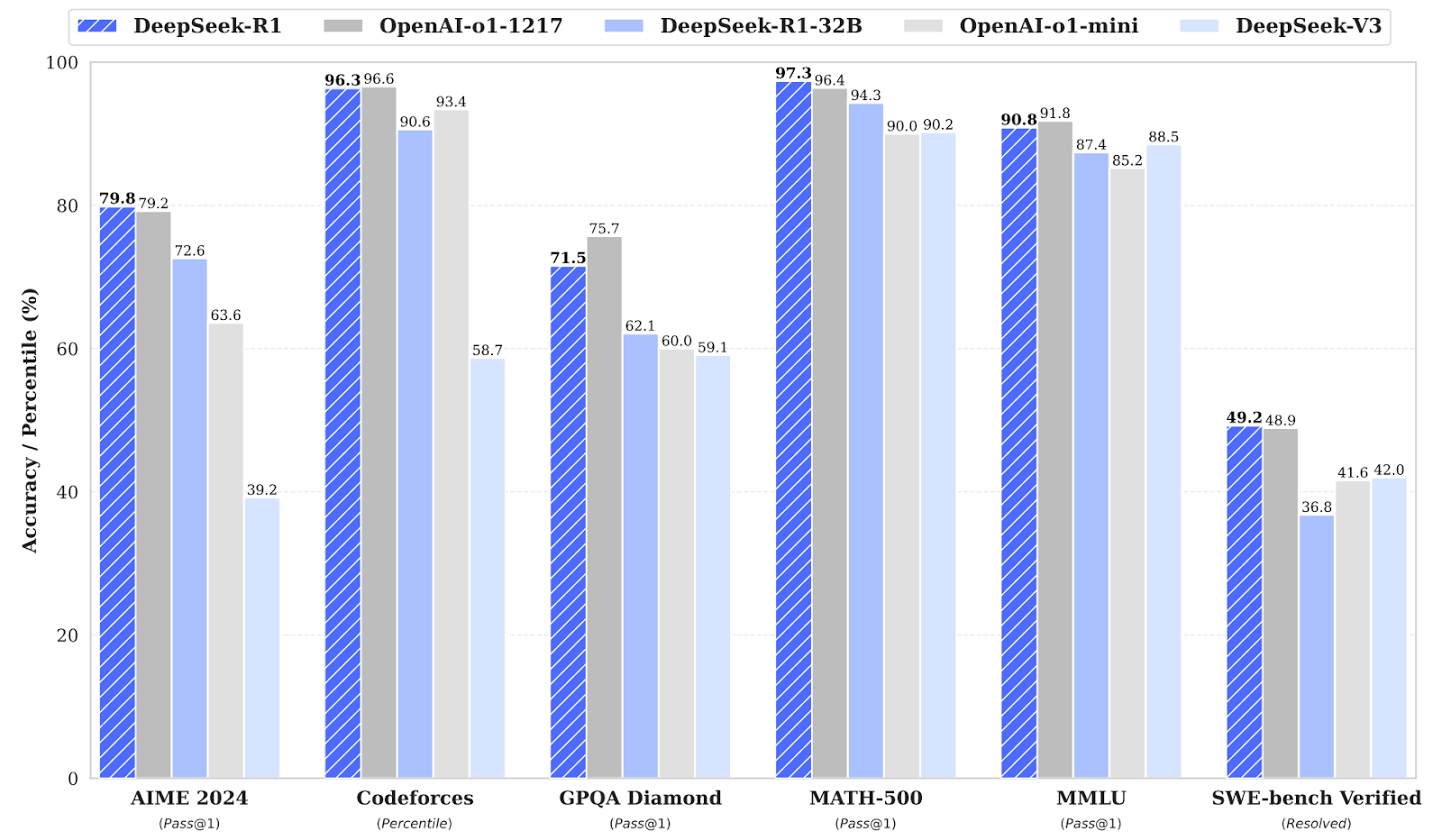
It remained slightly behind o1 on scientific reasoning in GPQA Diamond, but actually results on English language reasoning datasets were also excellent:
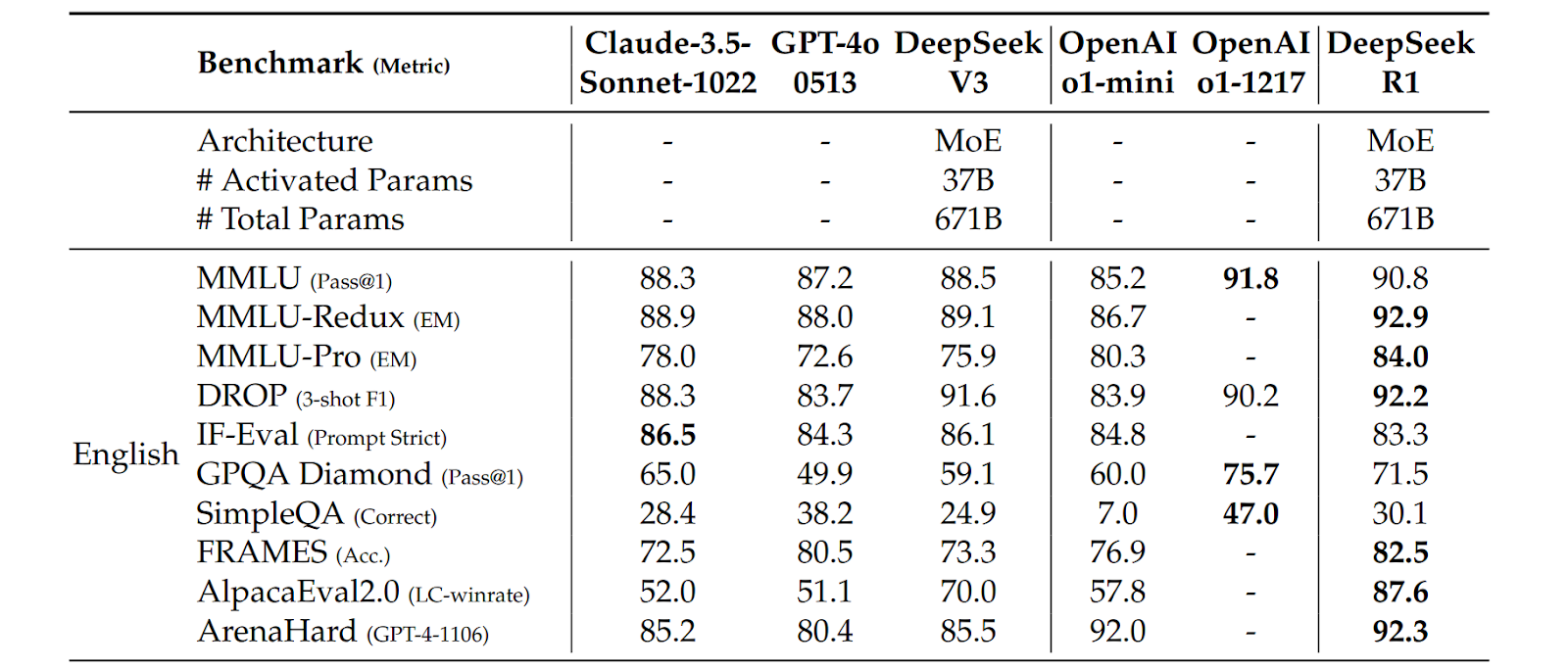
What may be even more important for some applications, DeepSeek also fine-tuned and released a number of distilled models, i.e., regular “non-reasoning” LLMs that were made better by fine-tuning. They used open models from the Qwen 2.5 family and Llama 3.3 and fine-tuned them with SFT on the 800K curated samples that we discussed above. They did not use RL to train further, although the authors note that it might help. Even with this SFT-only approach, the resulting models outperformed other top non-reasoning LLMs in benchmarks:
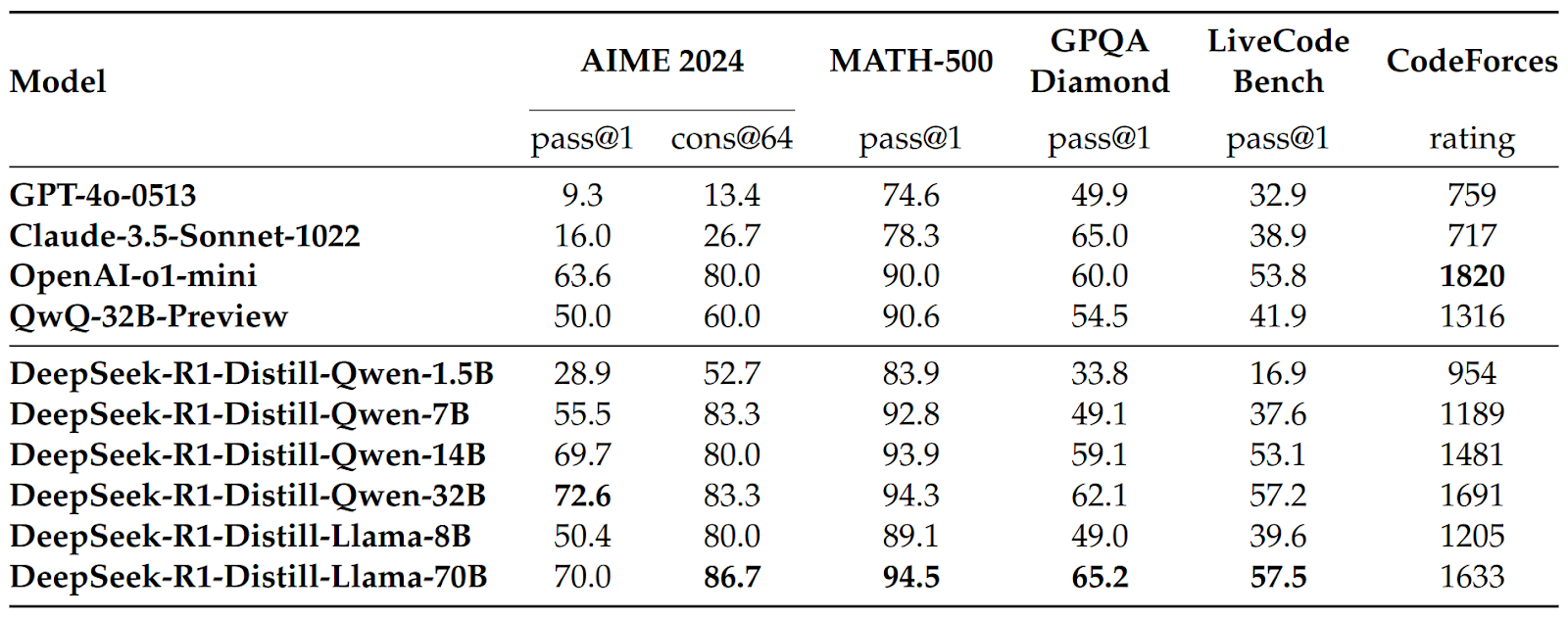
This again confirms the “bitter lesson” found by the GAIR lab: once you have a powerful enough model, the best way to bring others up to speed is not some cunning innovation but simply “distill, baby, distill”…
Oh, and one last thing. Unlike most other frontier models, DeepSeek-V3 and DeepSeek-R1 are indeed completely open, as in both open weights and open code. There are guides on how to install DeepSeek-R1 locally; I used this one and the 1.58 bit quantized version was a breeze to set up and run even on a home desktop with an RTX 3090 and 64GB of RAM. Naturally, the result was unusable in practice, the model ran at about 1-2 tokens per second, but it was very easy to prove the concept.
The journey from chain-of-thought prompting to full-fledged reasoning models represents one of the most exciting developments in AI today. OpenAI’s o1 series set the stage, demonstrating the power of test-time reasoning and opening new possibilities for scaling LLM performance. DeepSeek-R1 pushed the field even further, showing that with the right combination of reinforcement learning and new algorithmic improvements, it is still possible to compete at the highest level with the frontier labs (if not, alas, for under $10M).
Perhaps the most important lesson from this journey is that cutting-edge AI research continues to balance the classical tension between clever innovations and brute-force scaling. DeepSeek’s GRPO approach is a fresh take on policy gradients, and DeepSeek-V3 incorporates not only the MLA mechanism but a lot of training optimizations that go down to the hardware level. Still, its success ultimately came from combining robust reinforcement learning with traditional supervised fine-tuning and large-scale data collection.
Oh, and the one thing I simply cannot understand at all? The market reaction. DeepSeek came out and showed that:
And what did the market say? NVIDIA stock dropped by 15% with a record absolute loss for any company in history, and NASDAQ had one of its worst days ever:
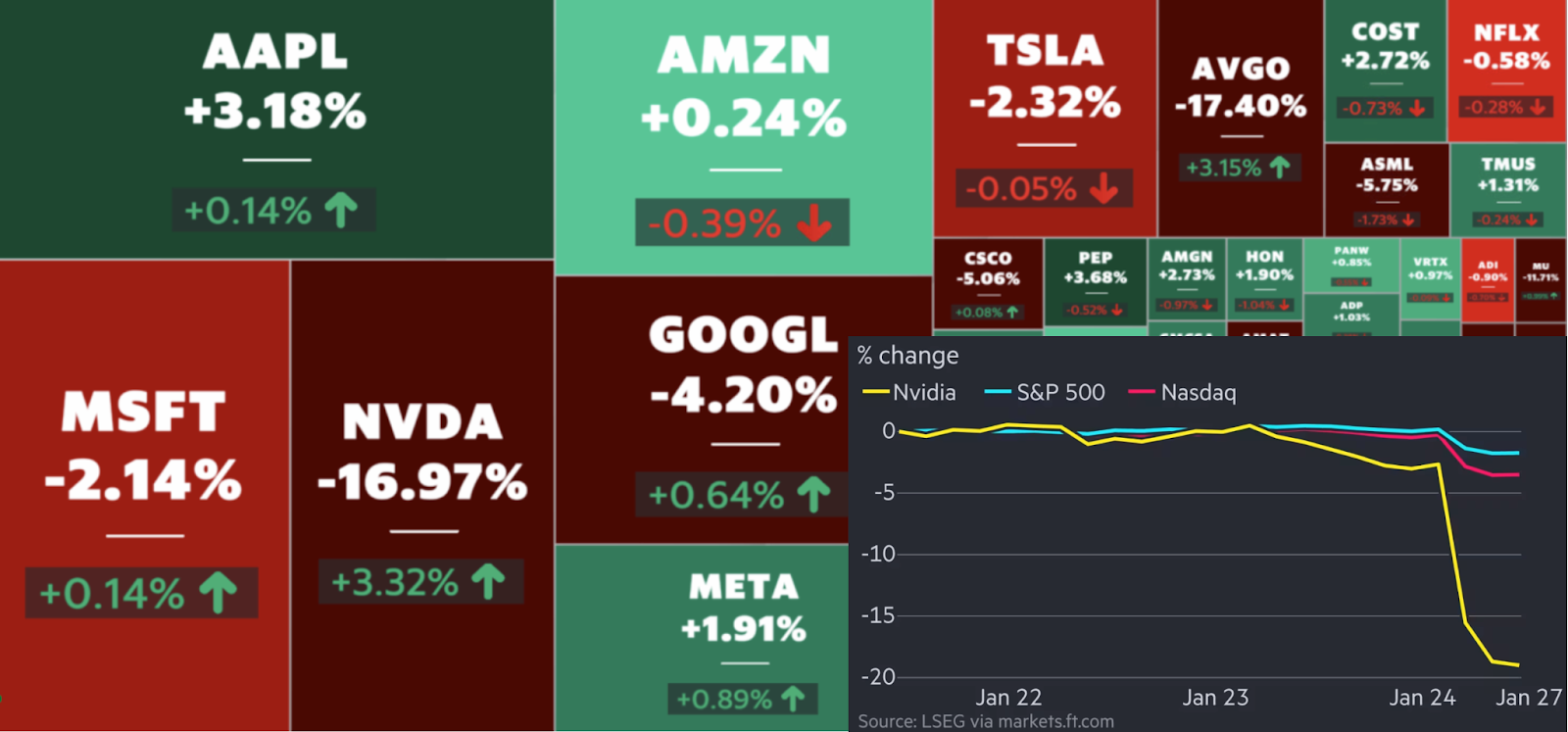
This may be a good reason to congratulate DeepSeek: their parent hedge fund High-Flyer could probably recoup all of the costs, and then some, if they anticipated this move in the markets. But I honestly have no idea what is the actual logic behind this. At least, the market gained back some ground later, although NVIDIA kept hurting from a lackluster presentation of their RTX 50xx GPU series. Moreover, the actual news of an NVIDIA rival appearing in the mix did not seem to have a significant additional impact.
But I digress. As we look ahead, the implications are vast. Test-time reasoning models will no doubt become standard in next-generation LLMs, yet another stepping stone on the road to AGI. OpenAI has already released a new family of reasoning models, the o3 series, that are better yet in benchmarks and seem to be the best on the market right now. At the same time, the demand for computational resources will continue to rise: will the hardware providers be able to keep up? We are only at the beginning of this new era of large reasoning models, and the rate of progress is not slowing down anytime soon.
We live in some very exciting times, exciting even for those of us who can only watch from the sidelines. I will continue to document the journey of modern AI, and I hope that one day these posts will combine into a greater whole. But until then, we have a lot more topics to discuss—see you next time!
Sergey Nikolenko
Head of AI, Synthesis AI
