
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
We interrupt your regularly scheduled programming to discuss a paper released on New Year’s Eve: on December 31, 2024, Google researchers Ali Behrouz et al. published a paper called “Titans: Learning to Memorize at Test Time”. It is already receiving a lot of attention, with some reviewers calling it the next big thing after Transformers. Since we have already discussed many different approaches to extending the context size in LLMs, in this post we can gain a deeper understanding of Titans by putting it in a wider context. Also, there are surprisingly many neurobiological analogies here…

One of the founders of neuropsychology, a Soviet researcher named Alexander Luria, had a stellar career. He managed to remain a world-class scientist in Stalinist Russia, publishing English translations of his famous books and visiting conferences all over the world despite working in such highly politicized areas as psychology, child development and genetics (for instance, he had to defend a physician degree instead of a biological one due to Lysenkoism). Oliver Sacks said that in Luria’s works, “science became poetry”.
As a founding father of neuropsychology, Luria argued that the human brain operates as a combination of three distinct groups of cognitive functions, or “functional blocks” (Zaytseva et al., 2015):
It is fascinating to see how artificial intelligence keeps conquering these general areas of intelligence one by one. In modern deep learning, the first steps were to process “sensory inputs”, i.e., high-dimensional raw inputs such as images or sound. But classical neural networks, such as deep CNNs characteristic of computer vision, were processing the entire input in the same way and only turned to “cognitive processing” in the last few layers; the bulk of their work was about extracting features from raw inputs.
The next step turned out to be to implement attention mechanisms: “look at” the inputs selectively and have a separate subnetwork devoted to which inputs to look at now. This is quite similar to what our brains are doing when they are filtering which parts of, say, our field of view should go into the working memory for further processing.
This step was already sufficient to get us where we are now: as we have been discussing on this blog for the last two years, the self-attention mechanism that enabled Transformers has led to the current crop of LLMs with not that many architectural changes (but a lot of algorithmic improvements, scaling, data collection efforts and so on, of course).
In fact, neurobiology has the predictive coding theory (Rao, Ballard, 1999; Clark, 2013; Ondobaka et al., 2017) that postulates that the brain is essentially an LLM generalized to arbitrary sensory inputs: we keep a predictive model of the environment and learn when actual future diverges from the predicted future. Memory is also implemented via learning, with forgetting done by synaptic pruning and decay and long-term memory being updated during the consolidation process, e.g., when we sleep.
But standard Transformer-based LLMs do not really have a memory. Not in the sense of storing weights on a computer, but in the sense of having a working memory where the LLM might choose to store something and then retrieve it during the “cognitive processing” part of its operation. In a way, methods for extending the context are a substitute for “real” memory, trying to allow straightforward access to everything at once, as are RAG-based approaches that use information retrieval tools to access information that cannot fit into the context. Reasoning LLMs such as the OpenAI’s o1 family or the recently released DeepSeek R1 also can be viewed as adding a form of memory: LLMs are allowed to record their thoughts and then return to them in a future inference.
It sounds like another jump in capabilities may come if we actually add a real working memory to the LLMs, a mechanism that would allow them not only to access back raw context but to save processed information, their “thoughts”, for future reference right as they are processing their input context. In technical terms, this might look like a blend between Transformers and RNNs (recurrent neural networks) since the latter do have memory in the form of a hidden state. In a recent post, we discussed linear attention techniques that are one way to produce this blend.
On December 31, 2024 (yes, literally), Google researchers Ali Behrouz et al. published a paper called “Titans: Learning to Memorize at Test Time”, with a new way to implement a working memory inside the LLM. Their approach, called Titans, looks like a very straightforward idea, it basically just goes ahead and implements a hidden state inside the Transformer, although it did need the recent ideas developed in conjunction with Mamba-like models to actually make it work. Overall, this sounds like one of the most interesting recent developments in terms of the pure academic novelty, and some bloggers are already hailing Titans as “Transformers 2.0”.
In the rest of the post, we dive into the details of Titans. Unlike most other posts here, this one is almost exclusively based on a single paper, so it will follow the paper more closely than usual and will be much shorter than usual. Still, I feel like Titans may be an important advance worth a separate post. We will first discuss the memory mechanisms in Titans (there are three, and two of them are new for us), then show how Titans solves the memory limitations of Transformers, present the technical side, i.e., how this memory works in reasonable time, discuss experimental results, and finish with my conclusion.
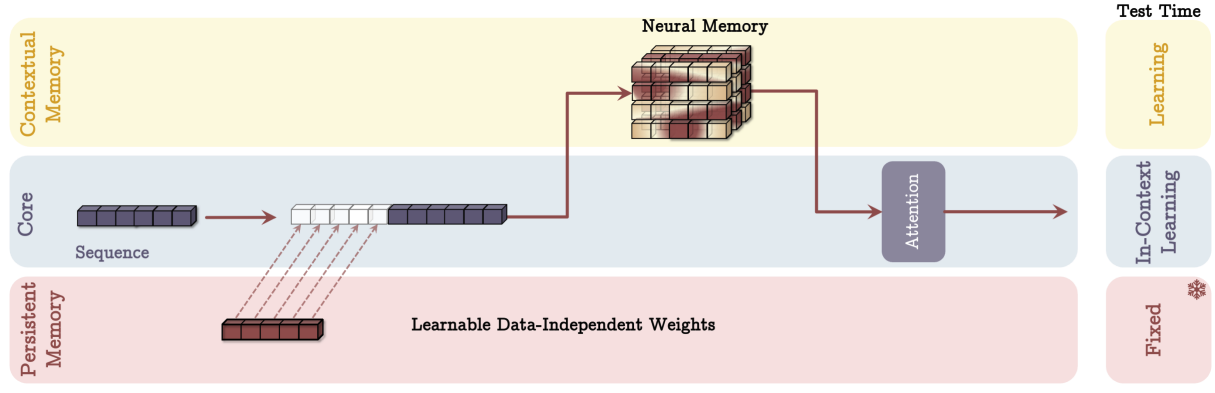
Three levels of memory. At its core, Titans take inspiration from how human memory works. We have short-term memory for immediate information (like remembering a phone number for a few seconds, or like a student can always regurgitate the last few words that the professor has said even if the student had not been paying attention), working memory for active problem-solving, and long-term memory for storing the big stuff.
Titans aim to replicate this hierarchy in neural architectures to handle sequences of data more effectively. Similar to the three components of human memory, Behrouz et al. define three different levels of memory mechanisms:
The paper introduces several different ways to combine long-term memory with other types, but a general flowchart might look like this—long-term memory gets updated after processing every token and then both long-term and persistent memory are added to the input:
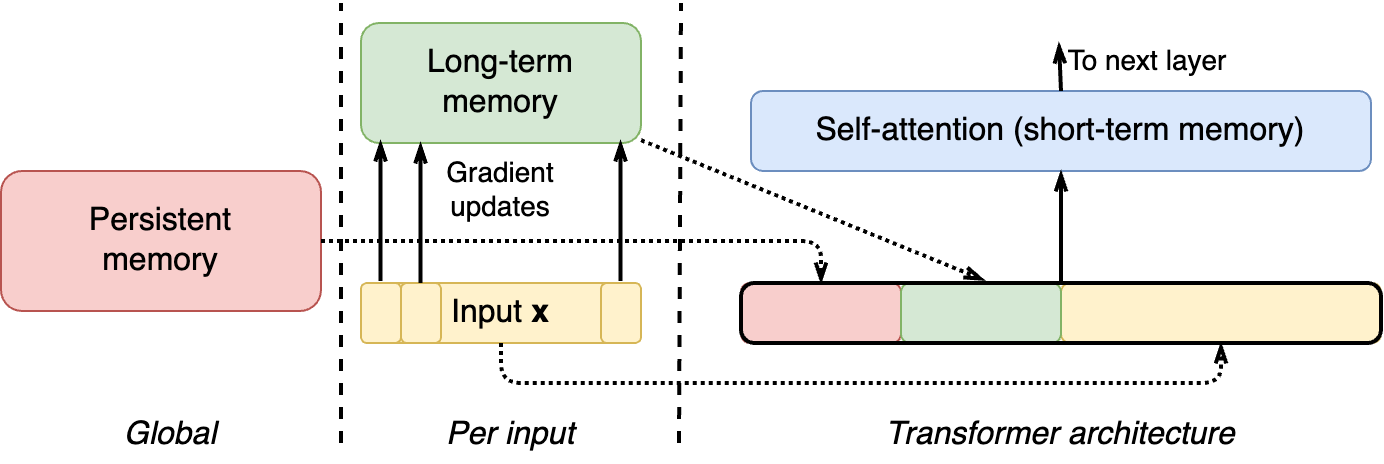
Since short-term memory is exactly regular self-attention (see, e.g., my post on Transformers), let us concentrate on the other two memory mechanisms. Long-term memory is the most important part, so let me begin with persistent memory and save the long-term mechanism for the next section.
Long-term memory. How can a neural network memorize stuff? In essence, it should have some kind of a hidden state that stores information, and rules to update this hidden state and retrieve information from it. We are familiar with this concept in two corner cases:
In one of the latest posts, we discussed the notion of linear attention, culminating in Mamba-like models. In terms of memory, linear attention has a fixed memory size (like an RNN) in terms of the number of parameters but it switches from a vector to a matrix hidden state and uses associative memory, storing information in the matrix so that it can be retrieved with a query vector (the Mamba post has details and examples). Mathematically, in the simplest case linear attention gives you the output as an associative memory lookup by the query vector from the memory updated iteratively on every step:

This is, of course, just a special case of RNNs, a special form of hidden state update and retrieval, but a very useful special case. There is a major constraint to linear attention, which we mentioned in the Mamba post and which Behrouz et al. (2024) also identify: when context becomes too long, associative memory overflows, leading to unpredictable forgetting. To alleviate this, researchers have proposed:
Titans take a step further: instead of treating memorization as layers inside the neural network, why don’t we consider memorization as a separate internal neural network trained on the current context information? In other words, the long-term memory module in Titans performs online learning: given the current input xt and current memory state Mt, the goal is to update Mt with gradient descent according to some loss function ℓ:
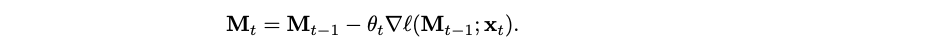
Where will the loss function come from? This actually moves us a step further to how memory is implemented in the human brain: we remember events that are surprising, that is, that do not conform to the predictions of the future that the brain is constantly producing. Thus, Behrouz et al. define the surprise metric ℓ(Mt, xt) as the difference between retrieved memory and actual content; for key-value associative memory, where xt is converted into a key-value pair as
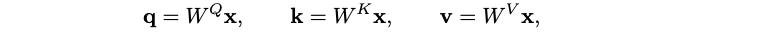
the loss can be defined as follows:
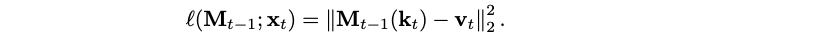
Once again: this is an “internal network”, an inner loop that does this kind of gradient descent while processing a given input, including at inference time. This raises performance concerns, which we will address in the next section.
What is the actual architecture of the “memory network”? Behrouz et al. (2024) use straightforward multilayer perceptrons (MLP) as M(kt); this is natural for a first shot at the goal but they also give two important remarks:
Momentum and forgetting. There are two more key modifications to the idea above. First, if you encounter a “surprising” step gradient descent might soon reduce the surprise to a small value while actually the surprising part of the data continues for longer. Behrouz et al. again compare this to human memory: “an event might not consistently surprise us through a long-period of time although it is memorable. The reason is that the initial moment is surprising enough to get our attention through a long time frame, leading to memorizing the entire time frame”.
Therefore, it makes sense to use not the surprise metric directly but an exponential moving average version of it that would preserve a part of the previous values of the metric. In gradient descent, this reduces to the well-known method of adding momentum:
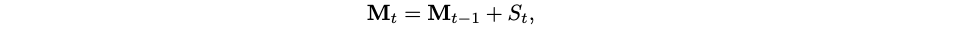
where
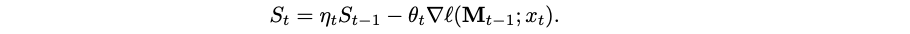
Note that the momentum coefficient ηt can also be data-dependent: the network may learn to control when it needs to cut off the “flow of surprise” from previous timestamps.
Second, as the context grows in size the memory network will eventually overflow, and this leads to the need to have some kind of forgetting mechanism as well. Titans use a “forget gate” for this, adding a value ɑt ∈ [0,1] that controls how much we forget during a given step. Overall, the update rule looks like the following:
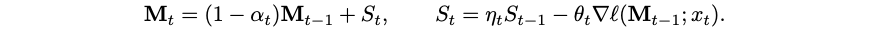
Note that ɑt is also data-dependent, and the network is expected to learn when it is best to flush its memory.
Persistent memory. As we have seen, long-term memory is input-dependent, i.e., it depends on the context. Obviously, it would also be useful to have input-independent memory that would store information specific to the entire task at hand, not the specific current input.
Titans use a simple but efficient approach to persistent memory: they introduce additional learnable parameters P that are appended to the start of every sequence:
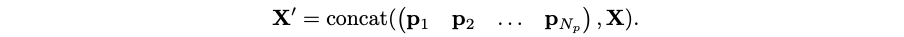
The parameters P do not depend on X and can act as task-related memory.
This idea has already been introduced in literature. For example, Hymba (Dong et al., 2024), a hybrid architecture combining Transformers and Mamba-style attention, introduced the so-called meta tokens that work in exactly the same way. On the other hand, Xiao et al. (2024) treated this idea as “attention sinks”, using it to alleviate the effect that the first attention weights, close to the start of the sequence, are almost always large.
In essence, this is it; no ODEs, no complicated math, just a neat meta-idea of recurrently training a small memory network during each computation on both training and inference, supplemented by persistent memory. There are, however, a few little devils lurking in the implementation details; let’s discuss those.
Where to add memory. Although we have described the proposed memory mechanism in full detail, there is also a choice of where exactly to add it in the architecture. Behrouz et al. (2024) consider three different options.
Memory as a Context (MAC) means that results of retrieval from memory get added to the input x, so it effectively becomes a concatenation of persistent memory, lookup results from contextual memory, and x itself. After this extended input is processed, memory is updated as we have discussed above:
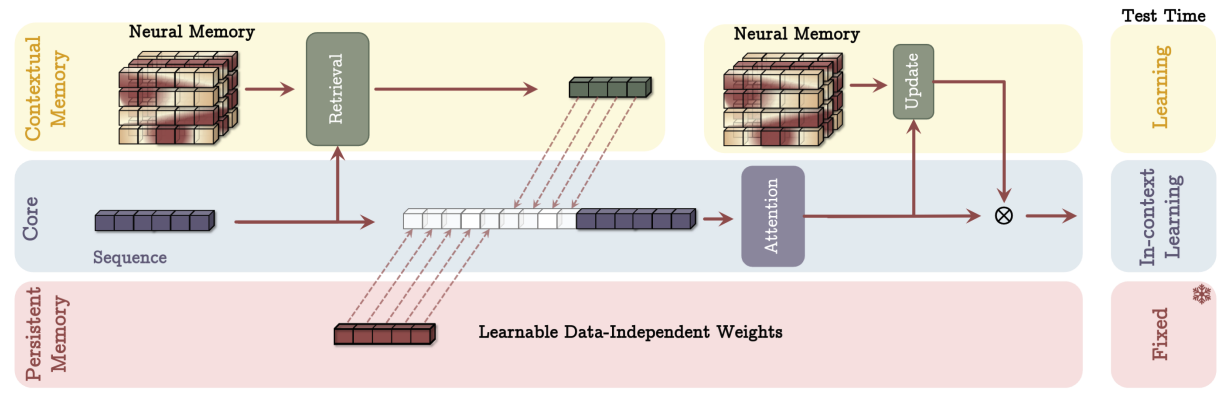
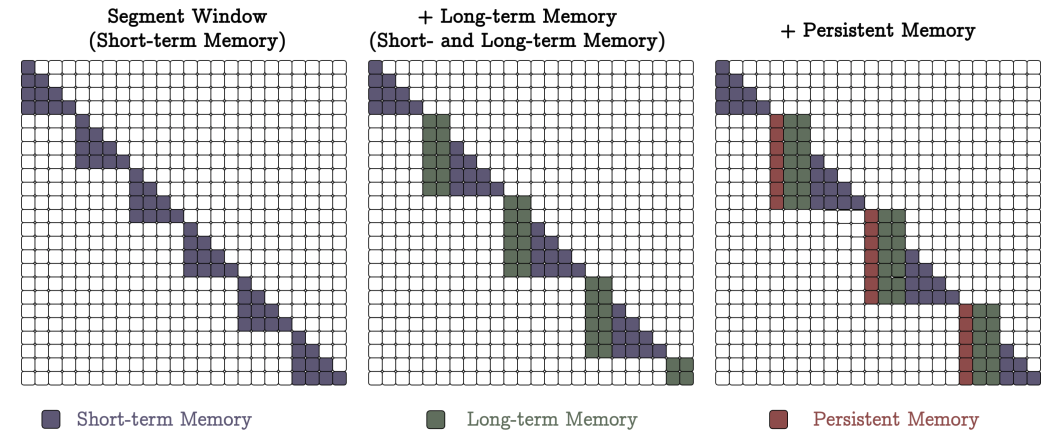
In this case, Titans split the input sequence into chunks that are fed into self-attention one by one, and the long-term and persistent memory mechanisms are prepended to it, so the overall structure of attention masks (recall our earlier post on extending the context) looks like this:
Memory as a Gate (MAG) is a different approach where only the persistent memory is added to the context, and lookup results are used to control the output via a gating mechanism:
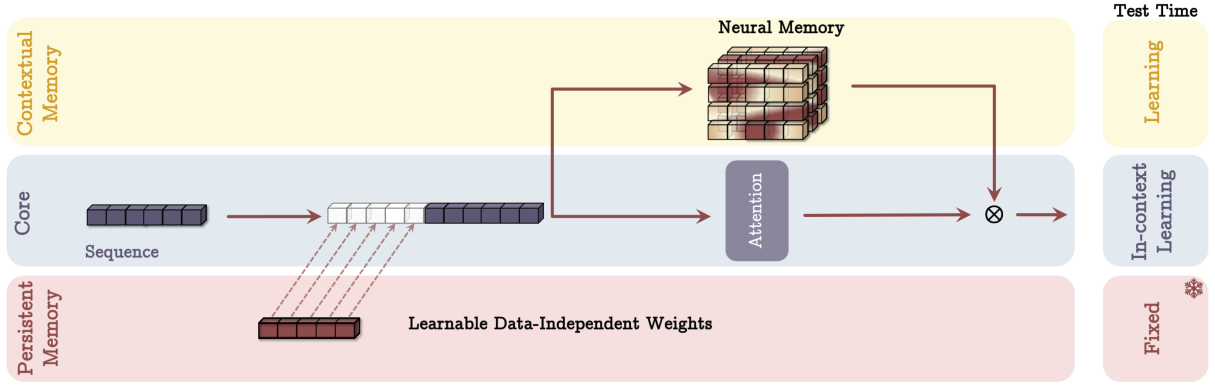
In this case, the input data is not segmented: the input is used to update long-term memory, and the attention mechanism uses a sliding window, like this:
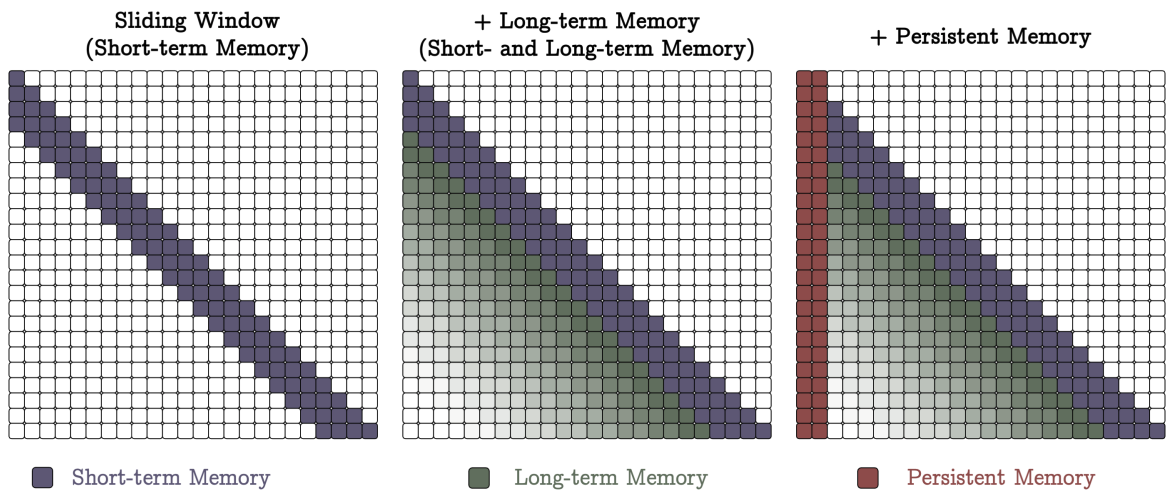
Finally, in the Memory as a Layer (MAL) architecture the memory layer serves as a preprocessing mechanism before the context (extended with persistent memory as usual) is fed into the attention mechanism:
This approach also suggests that since neural memory already can serve as a layer, we can do without the self-attention layer altogether; this architecture is called the neural memory module (LMM) in Behrouz et al. (2024).
Parallel training. Finally, there is the question of computational complexity. Titans sound like a very interesting idea but what use would it be if we had to run actual training for the long-term memory module, sequentially, on the whole context for every training sample?
Fortunately, that’s not the case. It does sound a little surprising to me but actual tools to parallelize this “test-time training” have only been devised over the last couple of years: Behrouz et al. (2024) use the mechanism of RNNs with expressive hidden states that represent machine learning models themselves, a technique developed only half a year ago by Sun et al. (2024).
For Titans, this works as follows. Let’s go back to the update rule, first without momentum:
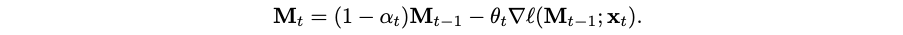
Let’s say that we are doing mini-batch gradient descent with batches of size b, i.e., the input is divided into chunks of size b. In that case, we can write
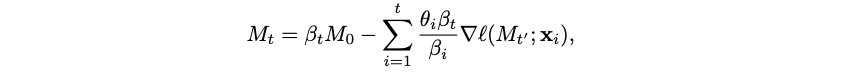
where t’ is the start of the current mini-batch, t’ = t – (t mod b), and βi collects the decay terms,
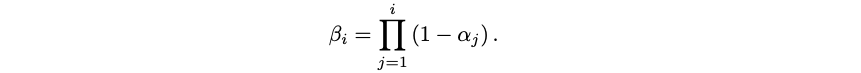
This formula accumulates all the influences up to time step t, and now we can rewrite it in a matrix form. For simplicity, let’s focus on the first mini-batch, with t=b and t’=0, and let’s assume that Mt is linear, Mt=Wt. Now the gradient of our quadratic loss function in matrix form is
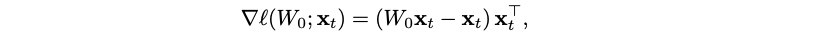
which means that
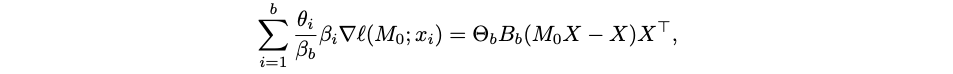
where Θb is a diagonal matrix containing scaled learning rates θi for the current mini-batch and Bb is a diagonal matrix containing scaled decay factors βi for the batch. The matrices Θb and Bb are only needed for the current batch, you don’t have to store them for all N/b mini-batches, so this already makes the whole procedure computationally efficient and not exceedingly memory-heavy.
As for adding momentum, the method above means that the update terms can all be computed at the same time, so the momentum update term can also be computed very efficiently with the parallel associative scan developed in the S4 paper (Smith et al., 2023) that we discussed in a previous post (see also this explanation).
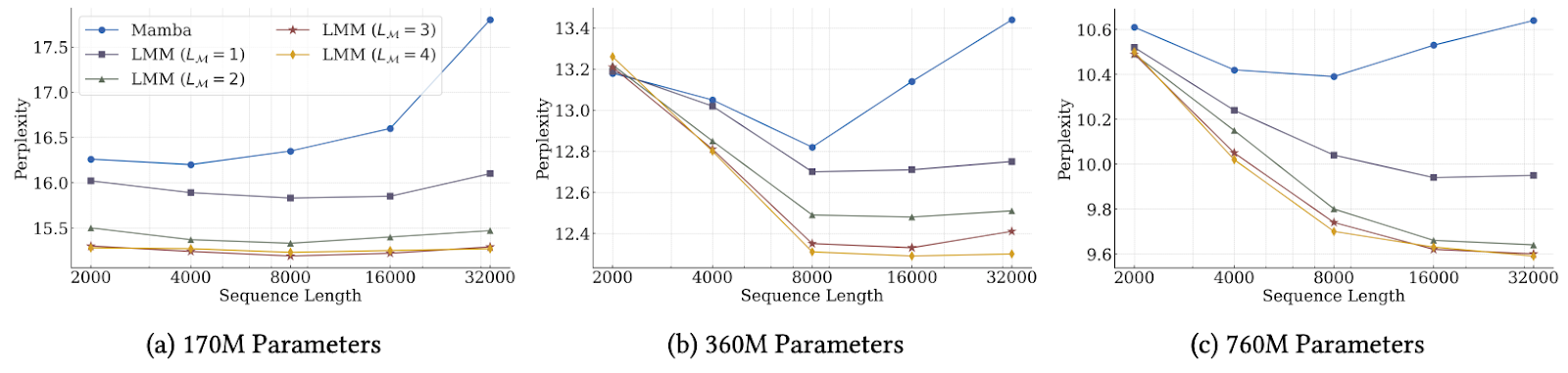
Experimental evaluation. The Titans paper has an experimental comparison of all four versions we have discussed above: MAG, MAC, MAL, and LMM. In most categories, LMM is the best “simple” (recurrent) model and either MAG or MAC is best in the “hybrid” category, where a memory mechanism is augmented with regular self-attention. In the original paper, most comparisons deal with relatively small models; e.g., here is the perplexity among language models with 340M parameters (measly by modern standards) trained on different datasets:
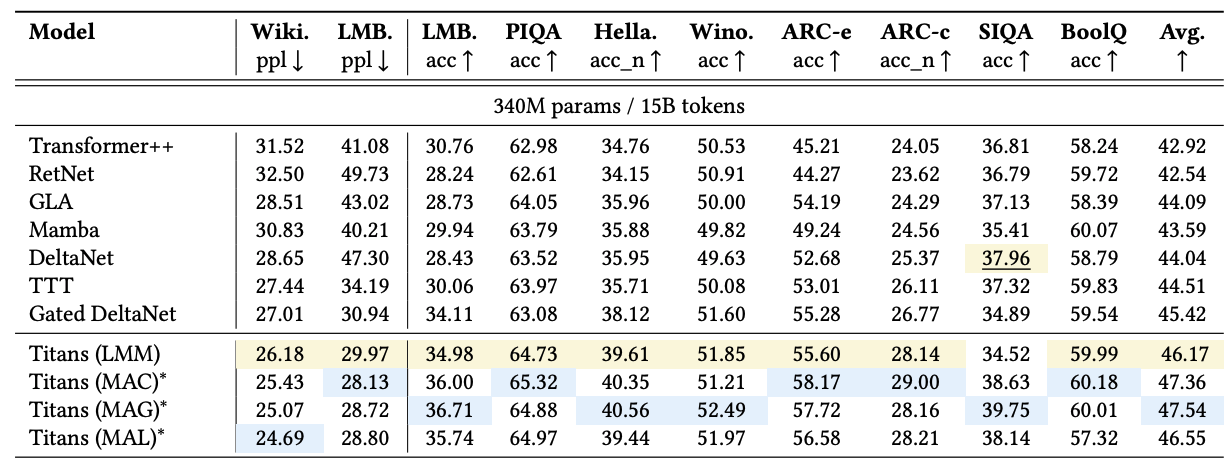
The authors say that experiments with larger models are coming, and it makes sense that they may take a long time. One set of experiments where data from state of the art models is available deals with the BABILong benchmark (Kuratov et al., 2024), a needle-in-a-haystack benchmark where the model has to not just find the “needle” statements in a long “haystack” context but distinguish statements that are relevant for the inferential task at hand and perform the inference. On this recently released benchmark, Titans outperforms much larger models, including not only Llama and Qwen with ~70B parameters but also GPT-4:
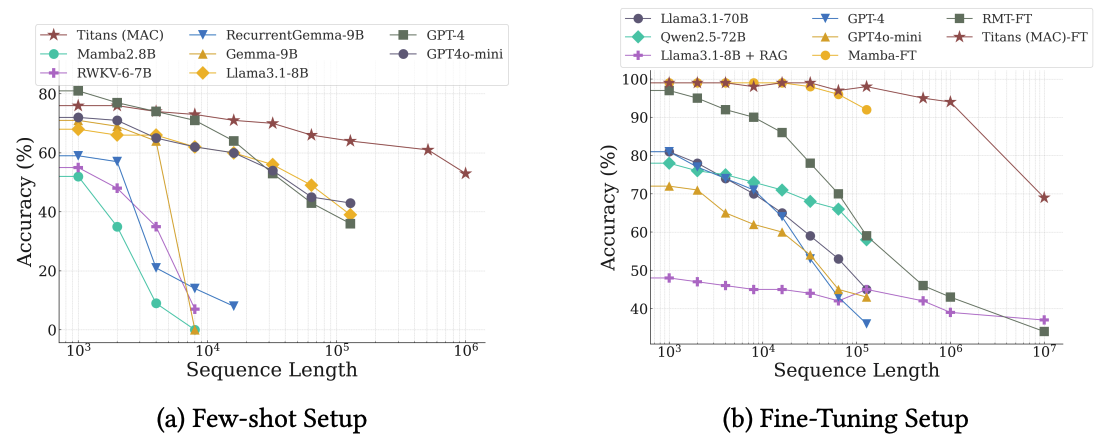
This plot looks very convincing to me: it appears that the long-term memory that Titans propose does indeed work very well.
Just how important are Titans? In my opinion, this is a bona fide engineering breakthrough that combines an ambitious idea (adding memory to LLMs), an elegant implementation (the part about parallelizing is important), and excellent test results. Unfortunately, for now we only have the results of relatively small experiments: while this is understandable for an academic paper only time will tell just how well this idea will survive scaling to state of the art model sizes.
Before we get experimental confirmation, we should not get overexcited. The path of deep learning is paved with ideas that sounded great on paper and in early experiments but ultimately led nowhere. Cyclical learning rates led to superconvergence (Smith, 2015), the amsgrad algorithm fixed a very real error in the Adam optimizer and was declared the best paper of ICLR 2018 (Reddi et al., 2018), ACON activation functions bridged the gap between ReLU and Swish in a very elegant and easily generalizable way (Ma et al., 2020)… all of these ideas made a splash when they appeared but ultimately were all but discarded by the community.
Still, I truly believe that memory is a key component of artificial intelligence that is still underdeveloped in modern architectures. And there are just so many directions where Titans may go in the future! Behrouz et al. (2024) themselves mention exploring alternative architectures for the long-term memory module (e.g., recurrent layers instead of MLPs). One could also apply Titans to tasks requiring ultra-long-term dependencies, like video understanding or large-scale scientific simulations. Getting working memory right may be one of the last obstacles on the path to true AGI. I am not sure that Titans is getting it exactly right, but it is a very interesting step in what is definitely the right direction.
Sergey Nikolenko
Head of AI, Synthesis AI
