
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
We continue the long series of reviews for CVPR 2022 papers related to synthetic data. We’ve had three installments so far, devoted to new datasets, use cases for synthetic data, and a very special use case: digital humans. Today, we will discuss papers that can help with generating synthetic data, so expect a lot of 3D model reconstruction, new generative models, especially in 3D, and generally a lot of CGI-related goodness (image generated by DALL-E-Mini by craiyon.com with the prompt “robot designer making a 3D mesh”).

This is the fourth part of our CVPR in Review series (part I, part II, part III). Similar to previous posts, we have added today’s papers to the OpenSynthetics database, a public database of all things related to synthetic data that we have launched recently.
The bulk of our discussion in this part is devoted to machine learning models that learn 3D objects (meshes, morphable models, surface normals) from photographs. The relation to synthetic data is obvious: one of the main bottlenecks in creating synthetic data is the manual labor that has to go into creating 3D models. After we have a collection of 3D scenes and 3D object models, the rest is more or less automatic, and we can easily produce a wide variety of datasets under highly varying conditions (object placement, lighting, camera position, weather effects, and so on) with perfect labeling, with all the usual benefits of synthetic data. But before we can have all these nice things, we need to somehow get the 3D models; any progress towards constructing them automatically, say from real world photographs, promises significant simplifications and improvements in synthetic data generation pipelines.
We will also touch upon two different subjects: camera noise modeling and controlled 2D image generation. Let’s start with the last one.
Before we proceed to 3D meshes and point clouds, let me begin with a paper on 2D generation, but quite accurately controlled 2D generation. The work “Modeling Image Composition for Complex Scene Generation” (OpenSynthetics) by Yang et al. presents an interesting variation on DALL-E-type models: a Transformer with focal attention (TwFA) that can generate realistic images based on layouts, i.e., from object detection labeling. Like this:

The architecture in this work has many similarities to DALL-E but is actually quite different. First, the basic VQ-VAE structure with a discrete codebook is there, but the codebook tokens do not come from text, they come from ground truth images (during training) and layouts:

Second, as you can see above there is a Transformer for generating the tokens, but it’s not a text-based Transformer, it’s a variation on the visual Transformer. Its job is to serve as a “token model” to produce a sequence of VQ-VAE tokens in an autoregressive fashion based on the layout. A learned model will run this Transformer to generate tokens, and then the VQ-VAE decoder will produce an image based on the sequence of tokens:

But the most important novelty, the one that actually lets this model use layouts in a very interesting way, is a new approach to the attention mechanism in the Transformer. In the classical Transformer, self-attention layers have every token attend to every other token; if we generate the sequence autoregressively, this means every previous token. Focal attention proposed in this work uses masks to enforce the tokens to attend only to the patches and objects that actually relate to it in the scene. Without going into too much detail, here is an illustration of what the masks look like in different variations of this idea:

This is exactly what lets the model generate images that reflect input layouts very well. And it doesn’t even need a huge dataset with object detection labeling for this, the authors used classical COCO-stuff and Visual Genome datasets. A comparison with other models that tried to tackle the same task is telling:

Naturally, the paper is devoted to generation and does not try to use generated images as synthetic datasets. But I view it as an interesting step in the direction of controlled generation; we’ve seen before that even very artificial-looking images can be helpful for training large computer vision models, so it would be interesting to check if images generated in such a controlled way could be helpful too.
It would be an especially interesting case of bootstrapping if one could use images generated by a VQ-VAE and a Transformer to improve the pretraining of these same models—I’m not claiming it’s going to help, I haven’t made or seen any experiments, but it’s an enticing thought to check out.
In the main part today, we will proceed from more specialized models to more general ones. The first two works are devoted to perhaps the most interesting and one of the most complex single objects in 3D modeling: heads and faces. Evolution has made us humans very good at reading facial expressions and recognizing faces; we usually like to look at other people and have had a lot of practice. This is why it’s very easy to get it wrong: “uncanny valley” examples usually feature human heads and faces.
In “Robust Egocentric Photo-realistic Facial Expression Transfer for Virtual Reality” (OpenSynthetics), Facebook researchers Jourabloo et al. consider the problem of generating virtual 3D avatars that would reflect our facial expressions in VR. This makes perfect sense for Facebook as their Oculus Quest 2 VR headset has become one of the most successful models to date.
There are many works on capturing and animating avatars, but compared to other settings, a VR headset is different: we need to model the facial expression of a person who is… well, wearing a VR headset! This sounds very challenging but, on the other hand, we have three cameras that show you the two eyes (covered by the headset) and the bottom of the face. Here is what the input looks like in this system, with camera locations shown on the right:

Jourabloo et al. propose a multi-identity architecture that takes as input three images like the ones above and a neutral 3D mesh of a person and produce the modified mesh and textured to go with it. There are several parts of the architecture, one for shape modification, another for texture generation, and yet another for putting them together and rasterizing:
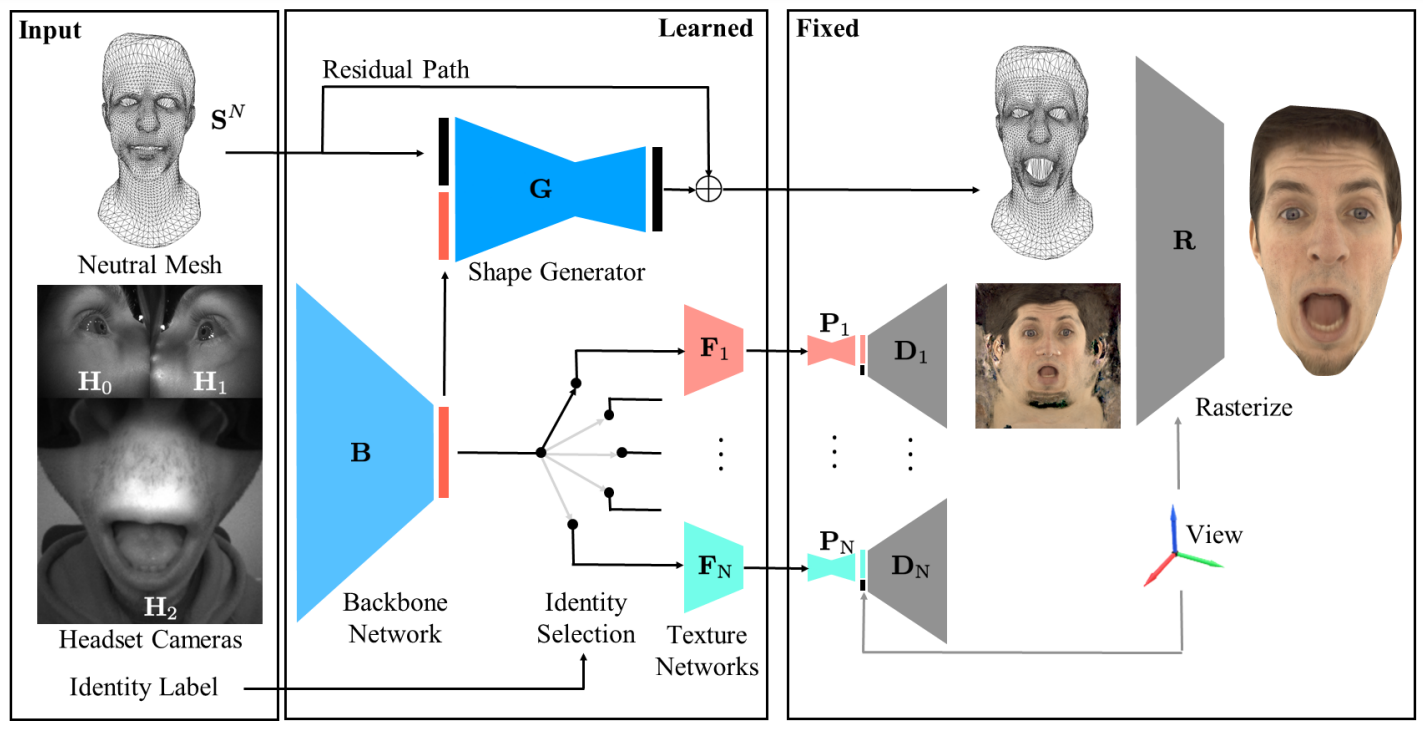
By the way, a major factor in improving the results, as it often happens in computer vision, were augmentations: the authors propose to model 3D augmentations (such as slightly moving or rotating the camera) by 3D rotation and translation of the face shape in the training set, that is, changing the premade 3D shape—looks like another win for synthetic data to me!
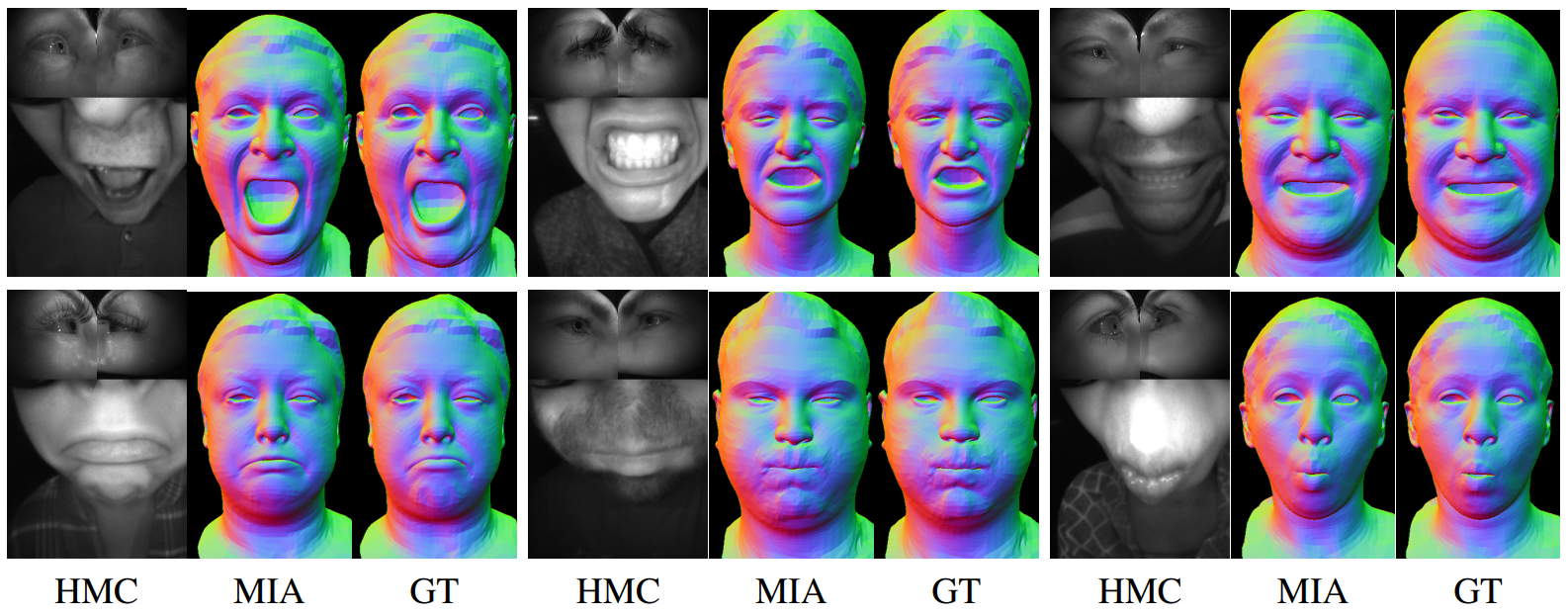
The results are quite impressive; here is a comparison with ground truth 3D models:
And here are sample final results of the whole pipeline, in comparison with a previous work and again with the ground truth on the right:
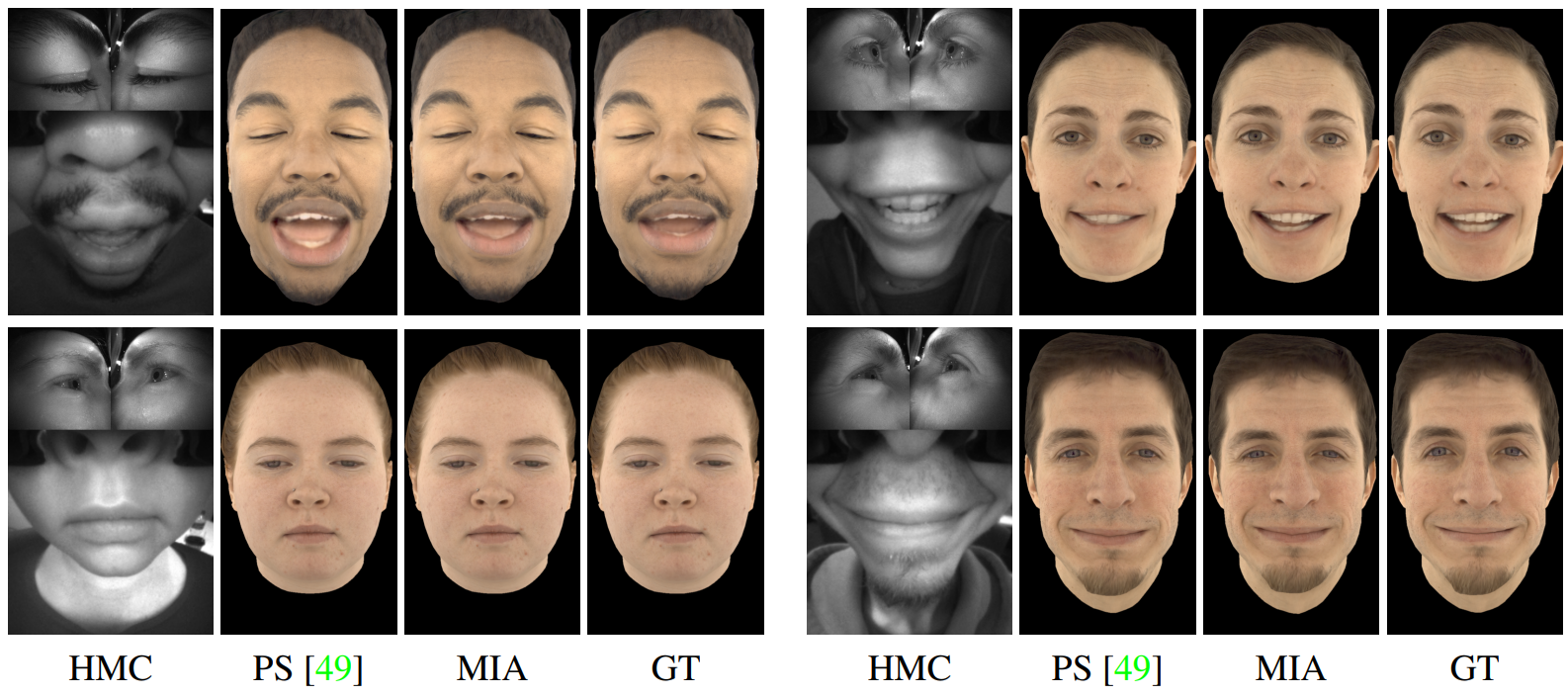
VR technology is constantly evolving, and these examples already look perfect. Naturally, the hardest part here is not about getting some excellent cherry-picked results, but about bridging the gap between research and technology: it would be very interesting to see how well models like this one perform in real world settings, e.g., on my own Oculus Quest 2. Still, I believe that this gap is not too wide already, and we will be able to try photorealistic virtual worlds very soon.
In comparison with VR avatars, this work, also devoted to reconstructing 3D faces, clearly shows the difference between possible problem settings. In “JIFF: Jointly-aligned Implicit Face Function for High Quality Single View Clothed Human Reconstruction” (OpenSynthetics), Cao et al. set out to reconstruct the 3D mesh from a single photograph of a clothed human. Here are the results of the best previous model (PiFU from ICCV 2019, which we discussed in a previous post) and the proposed approach:

The improvement is obvious, but the end result is still far from photorealistic. As we discussed last time, the PiFU family of models uses implicit functions, modeling a surface with a parameterized function so that its zero level is that surface. Another important class of approaches includes 3D morphable models (e.g., the original 3DMM or the recently developed DECA) that capture general knowledge about what a human face looks like and represent individualized shapes and textures in some low-dimensional space.
So a natural idea would be to join the two approaches, using 3DMM as a prior for PiFU-like reconstruction. This is exactly what JIFF does, incorporating 3DMM as a 3D face prior for the implicit function representation:
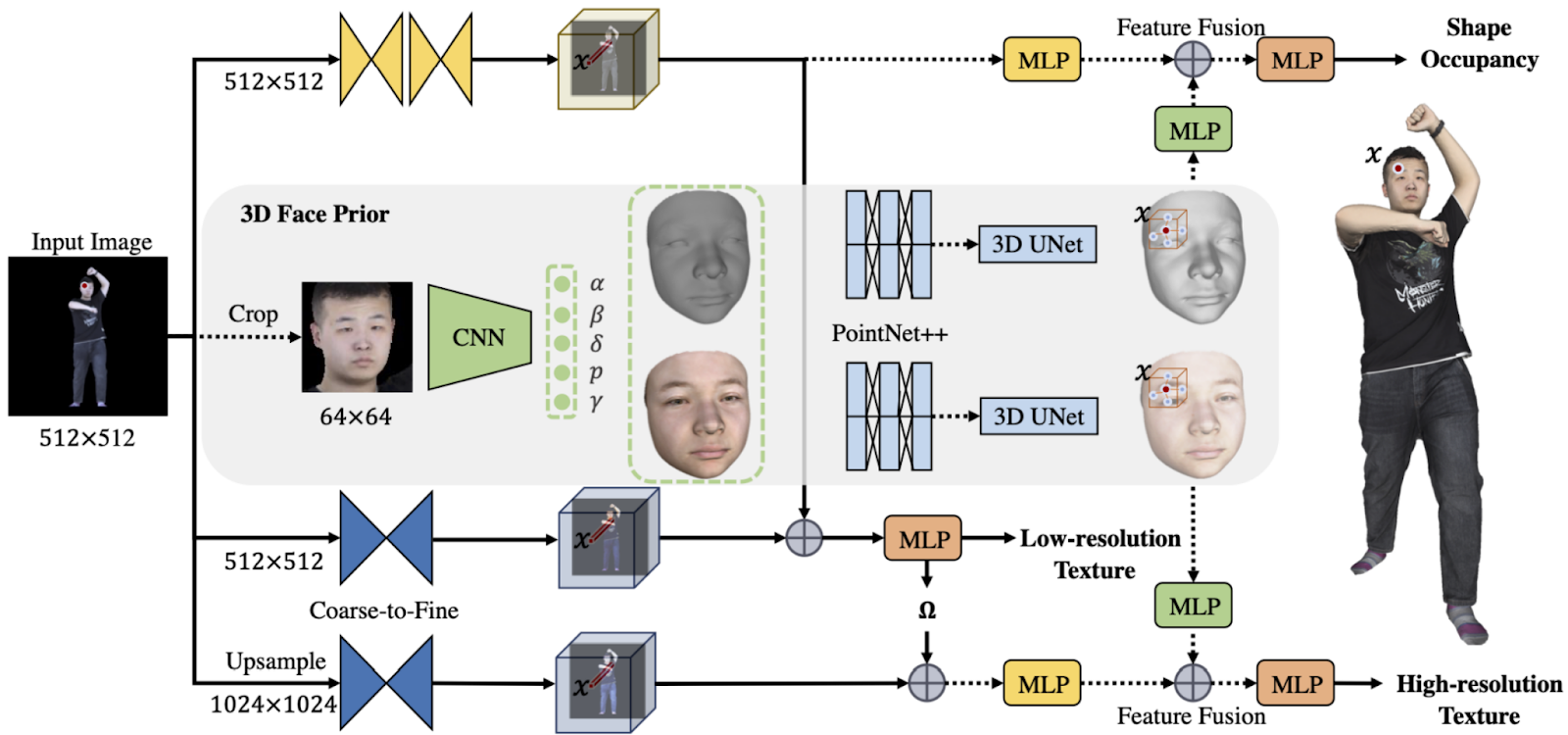
You’ve seen the results above, so let’s keep this section short. The conclusion here is that to get good high-resolution 3D models at this point you need some very good inputs. Maybe there already exists some combination of approaches that could take a single photo, learn the shape like this one, and then somehow upscale and improve the textures to more or less photorealistic results, but I’ve yet to see it. And this is a good thing—there is still a lot of room for research and new ideas!
Human heads are a very important object in synthetic data, but let’s move on to a model, presented in “BANMo: Building Animatable 3D Neural Models from Many Casual Videos” (OpenSynthetics) by Yang et al., that promises to capture a whole object in 3D. And not just capture but to provide an animatable 3D model able to learn possible deformations of the object in motion. Naturally, to get this last part it requires much more than a single image, namely a collection of “casual videos” that contain the object in question. Oh, and I almost forgot the best part: the “object in question” could be a cat!

So how does it work? We again come back to implicit functions. A 3D point in BANMo ( a Builder of Animatable 3D Neural Models) has three properties: color, density, and a low-dimensional embedding, and all three are modeled implicitly by trainable multilayer perceptrons. This is very similar to neural radiance fields (NeRF), a very hot topic in this year’s CVPR and one that deserves a separate discussion. Deformations are modeled with warping functions that map a canonical location in 3D to the camera space location and back. Pose estimation in BANMo is based on DensePose-CSE, which actually limits the model to humans and quadrupeds (thankfully, cats are covered). And to get from the 3D deformed result to 2D pixels BANMo uses a differentiable rendering framework, which is yet another can of worms that I don’t want to open right now.
Overall, it’s a pretty complicated framework with a lot of moving parts:
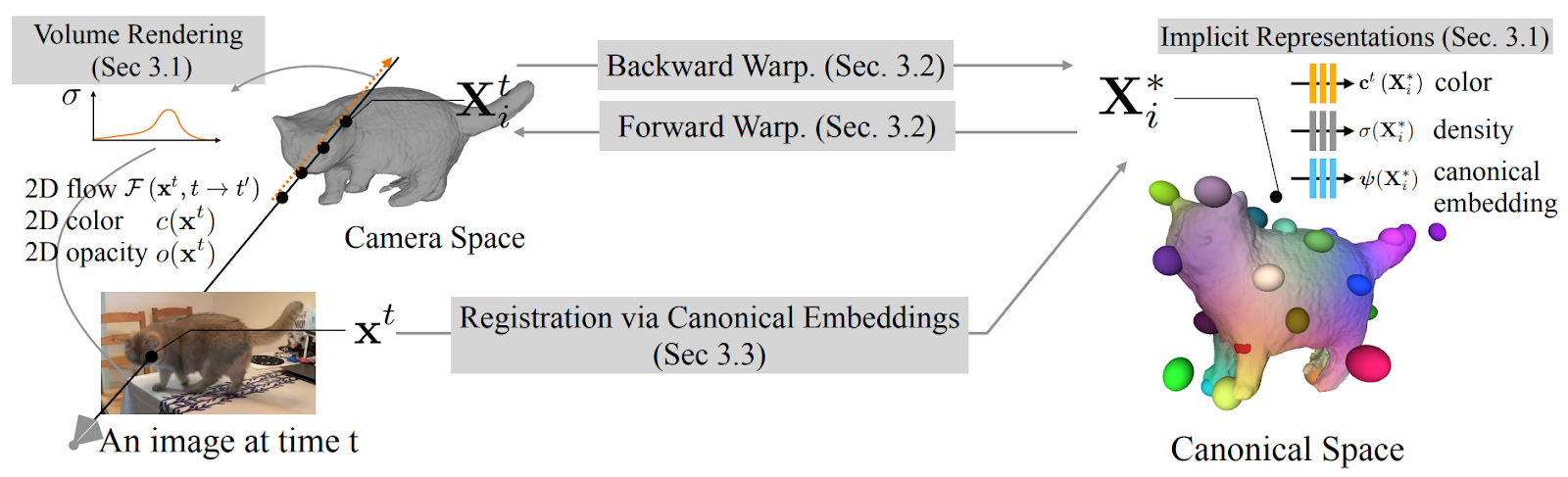
But, as it often happens in successful deep learning applications, by carefully selecting the losses the authors are able to optimize all the parts jointly, in an end-to-end fashion.
Here is a comparison with previous work on similar problems:

As you can see, the results are not quite perfect but already very good. BANMo requires a lot of input data: the authors speak of thousands of frames in casual videos. However, collecting this kind of data is far easier than trying to get a 3D model via a hardware solution or recording videos in a multi-camera setup. If you have a cat you probably already have enough data for BANMo. The implications for synthetic data are obvious: if you can get a new model complete with movements and deformations automatically from a collection of videos, this may reduce the production cost for 3D models by a lot.
Clothing is hard. When a girl dances in a dress, the cloth undergoes very complicated transformations that are driven by the dance but would be extremely difficult to capture from a monocular video. In fact, clothes are the hardest part of moving from heads and faces (where clothing is usually limited to rigid accessories) to full-body 3D reconstruction of humans.
In “Learning Motion-Dependent Appearance for High-Fidelity Rendering of Dynamic Humans from a Single Camera” (OpenSynthetics), Adobe researchers Yoon et al. try to tackle the problem of adding clothes to human 3D models in a realistic way that would be consistent with motion. The problem would be to take a 3D body model as input and output a clothed 3D body model and the corresponding rendering:
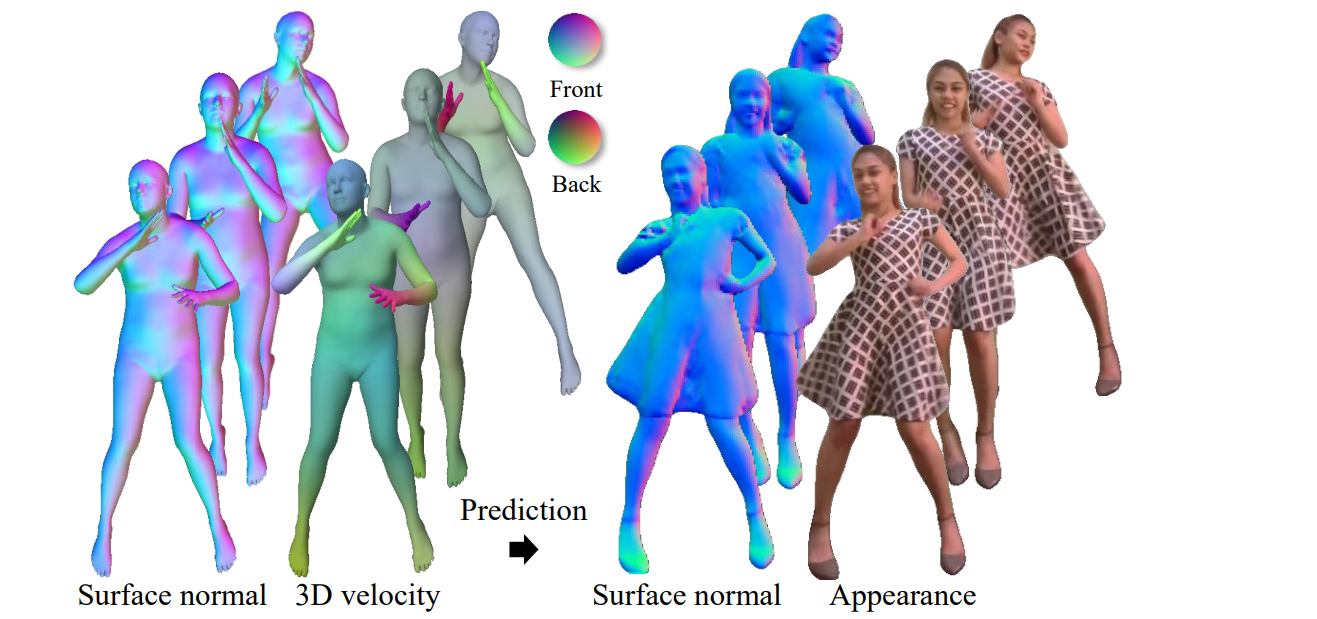
The main challenge here is the lack of data: it would be probably possible to learn the dynamics of secondary motion (e.g., clothing) from videos but that would require a very large labeled dataset that covers all possible poses. In realistic scenarios, this dataset is nonexistent: we usually have only a short YouTube or TikTok video of the moving person.
This means that we need to have strong priors about what’s going on in secondary motion. Yoon et al. propose the equivariance property: let’s assume that per-pixel features learned by the model’s encoder are transformed in the same way as the original body pose is transformed. The encoder produces 3D motion descriptors for every point, and the decoder’s job is to actually model the secondary motion and produce surface normals and appearance of the final result:
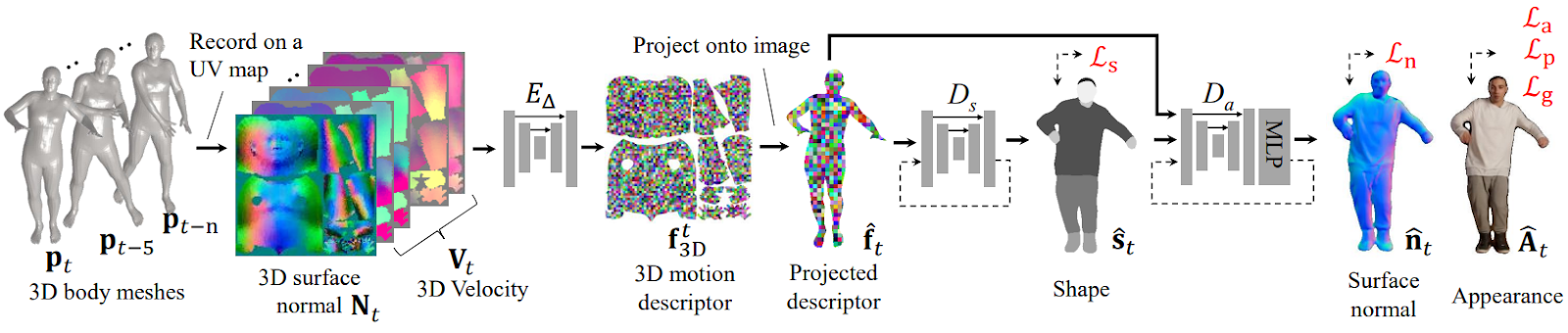
The results are very impressive; in the figure below the rightmost column is the ground truth, the second on the right is the proposed model, and the rest are baselines taken from prior art:

Moreover, in the experiments the poses and surface normals (inputs to the model) are not assumed to be known but are also captured from the input video with a specially modified 3D tracking pipeline. This allows to use the model at standalone videos and also enables a number of other applications:
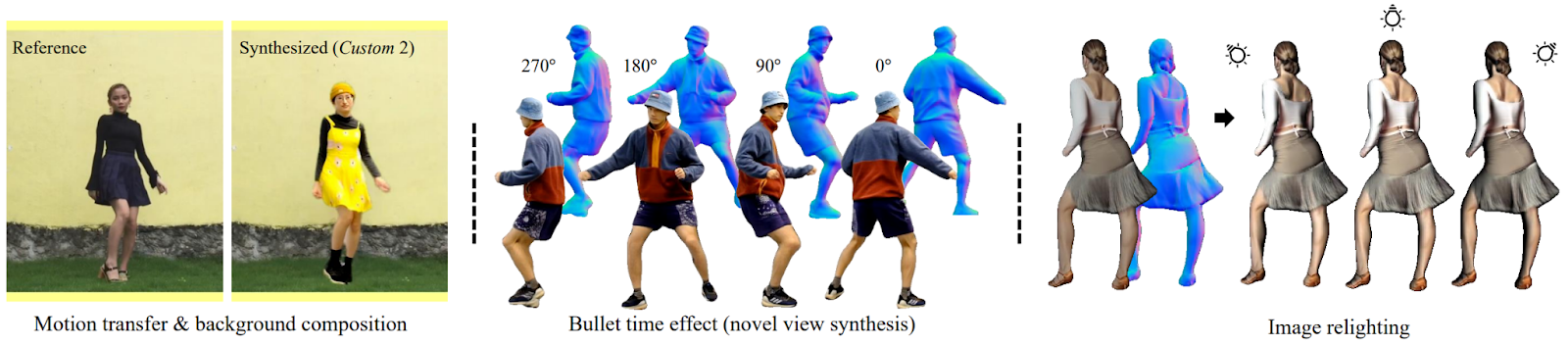
Overall, this year’s CVPR shows a lot of significant improvements in 3D reconstruction from 2D input, be it either a single image, a short clip, or a whole collection of videos. This is yet another excellent example of such a work.
Let’s also briefly mention another work that deals with a very similar problem: reconstructing the 3D mesh of clothes from a single image. The ReEF model (registering explicit to implicit), proposed in “Registering Explicit to Implicit: Towards High-Fidelity Garment mesh Reconstruction from Single Images” (OpenSynthetics) by Zhu et al., tries to extract high-quality meshes of clothing items from a single photograph.
The main idea is to use an explicitly given 3D mesh of an item of clothing and learn from the image a function of how to deform it to match the appearance on the image. This is achieved by segmenting the input into clothing items and their boundaries (in 3D!) and then fitting a standard (T-pose) 3D mesh to the results:
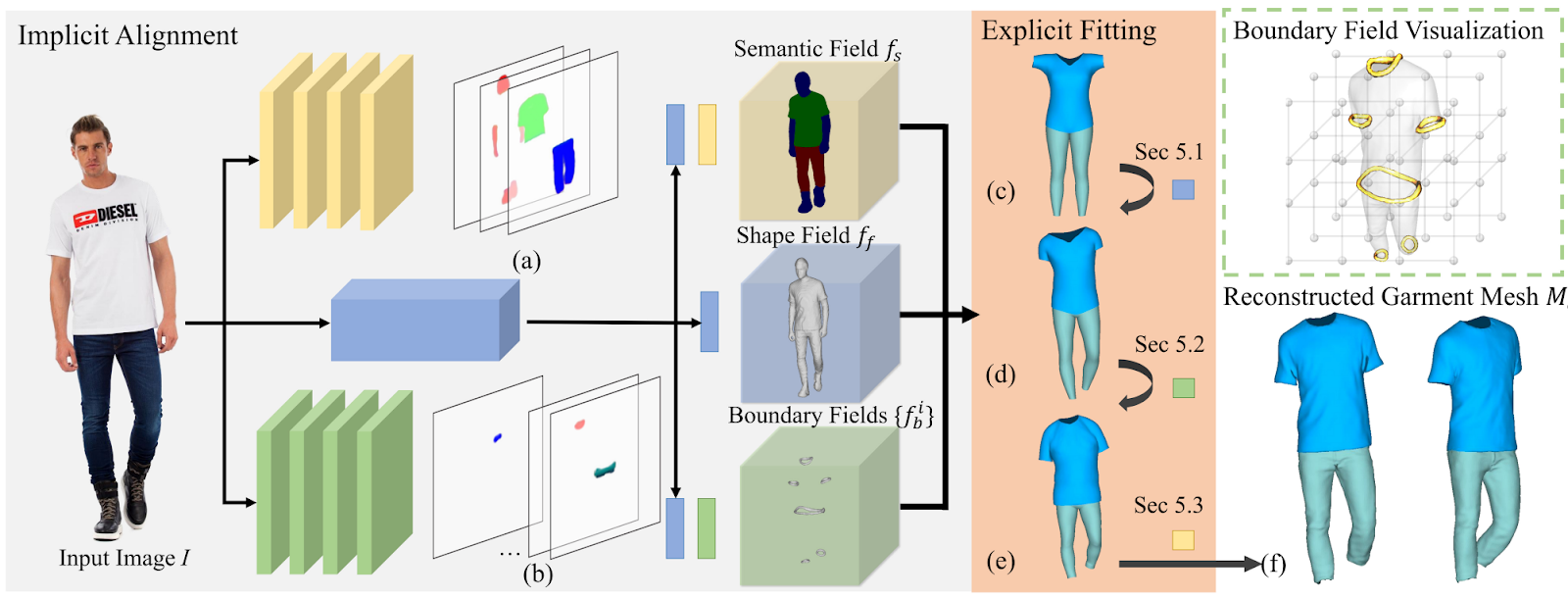
I will not go into details here, but the results are quite impressive. The resulting meshes can then be applied to other 3D meshes, re-deforming them to match:

That is, you can automatically fit a virtual character with your clothes! When this technology is further improved (I don’t think it’s quite there yet), this may be a very important piece of the puzzle for large-scale synthetic data generation. If we can get items of clothing in bulk from stock photos of clothed humans and eliminate the need to model these items by hand, it will significantly increase variation in synthetic data without adding much to the cost.
Our last 2D-to-3D paper today is “PhotoScene: Photorealistic Material and Lighting Transfer for Indoor Scenes” (OpenSynthetics) by UCSD and Adobe researchers Yeh et al. On one hand, it’s the natural culmination of our small-to-large progression: PhotoScene deals with photographs of whole interiors.
On the other hand, PhotoScene tackles a problem that can be crucial for synthetic data generation. Most works that deal with 2D-to-3D reconstruction (including the ones above) concentrate on trying to get the 3D model itself (in the form of a mesh, surface normals, or some other representation) exactly right. While this is very important, it’s only one piece of the puzzle. PhotoScene presents a solution for the next step: given a preexisting coarse 3D model of the interior (either automatically generated or produced by hand), it tries to capture the materials, textures, and scene illumination to match the photo.

An interesting part of the pipeline that we have never discussed before are material priors, that is, low-dimensional parametric representations of various materials that are resolution-independent and can produce textures of numerous variations of materials by varying their parameters.
The authors use MATch, a recently developed framework that defines 88 differentiable procedural graphs that can capture a wide range of materials with a lot of detail and variation, as textures in unlimited resolution ready for applying to 3D models, relighting, and other transformations:

Using this work as a basis, PhotoScene learns to align parts of the input photo with elements of the coarse 3D scene, extracts the most suitable procedural MATch graphs, and learns their parameters. As a result, it produces a scene with high-quality materials and refined lighting, ready to render in new views or with new lighting:
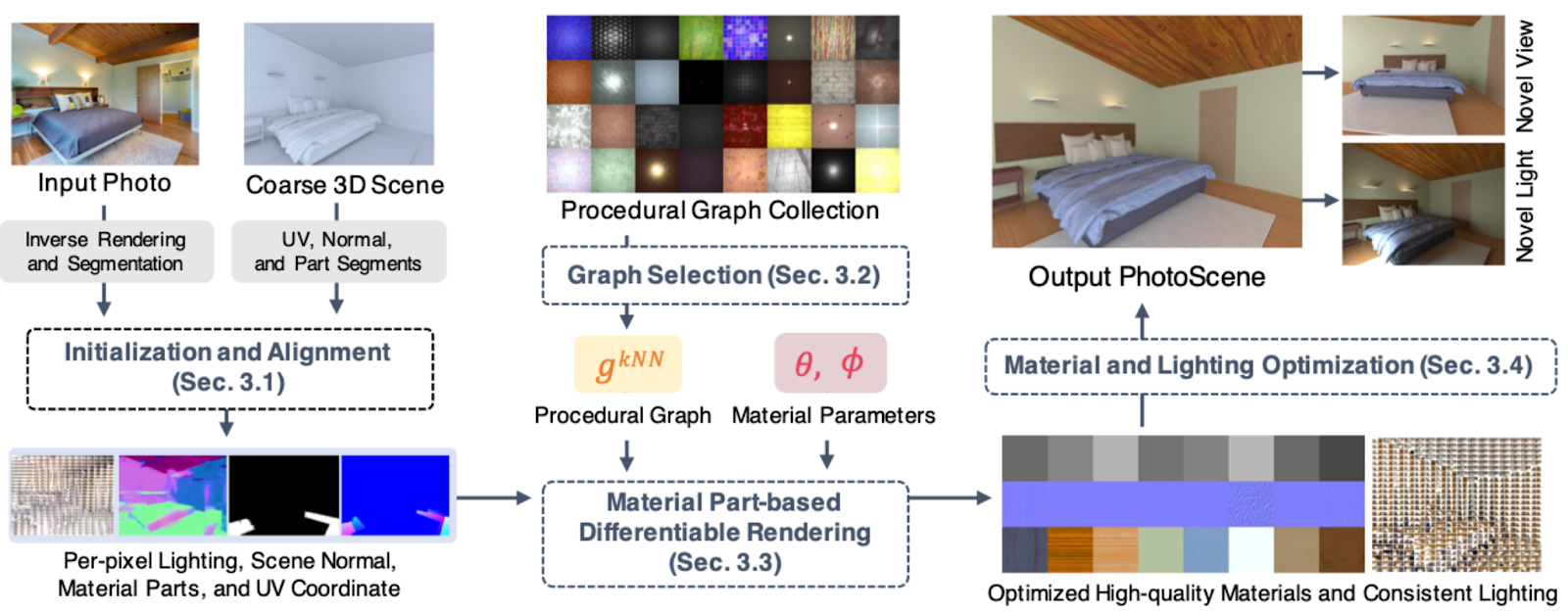
PhotoScene and, more generally speaking, material priors in the form of procedural graphs also represent a very important novelty for synthetic data generation. With models such as this one, we are able to obtain 3D representations of whole scenes (interiors in this case) that can then be used as the basis for synthetic data. It is not hard to throw together a coarse 3D model for a home interior: naturally, there already exist a lot of 3D models for furniture, decor, covers, and other home items, so it’s more a matter of choosing the most suitable ones. The hard part of 3D modeling here is to get the materials right and set up the lighting in a realistic way—exactly what PhotoScene can help with. Moreover, instead of rasterized textures it produces material graphs that can be used in any resolution and under any magnification—another very important advantage that can let us improve the quality and variety of the synthetic output.
In conclusion, as usual, let’s go for something completely different. In “Modeling sRGB Camera Noise with Normalizing Flows” (OpenSynthetics), Samsung researchers Kousha et al. present a new model for modeling the noise introduced by real world cameras.

This is a very specialized problem, but a very important one for quite a few applications, not just image denoising. In particular, I personally have worked in the past on superresolution, the problem of increasing resolution and generally improving low-quality photographs. Somewhat surprisingly, noise modeling proved to be at the heart of superresolution: modern approaches such as KernelGAN or RealSR introduce a parametric noise model, either to learn it on the given photo and then upscale it while reducing this noise or to inject this noise for degradation during their single-image training. It turned out that the final result very much depends on how well the noise model was learned and how expressive it was.
For synthetic data, this means that for many problems, to have really useful synthetic data we would need to have a good noise model as well. If superresolution models were trained on clean synthetic images with noise introduced artificially with some kind of a simple model (probably Gaussian noise), they would simply learn this model and produce atrocious results on real life photos whose noise is generated very differently.
Technically, Kousha et al. use normalizing flows, a very interesting and increasingly important family of generative models that model the density p(x) as a composition of several relatively simple invertible transformations, producing a diagonal Jacobian that ensures either efficient density estimation (masked autoregressive flows, MAF) or efficient sampling (inverse autoregressive flows, IAF). It would take a separate post to fully introduce normalizing flows (I hope I’ll write it someday), so let’s just say that here Kousha et al. introduce a conditional linear flow that is conditioned on the camera and its gain setting and use it in a whole pipeline designed to model several different sources of noise present in real world cameras:
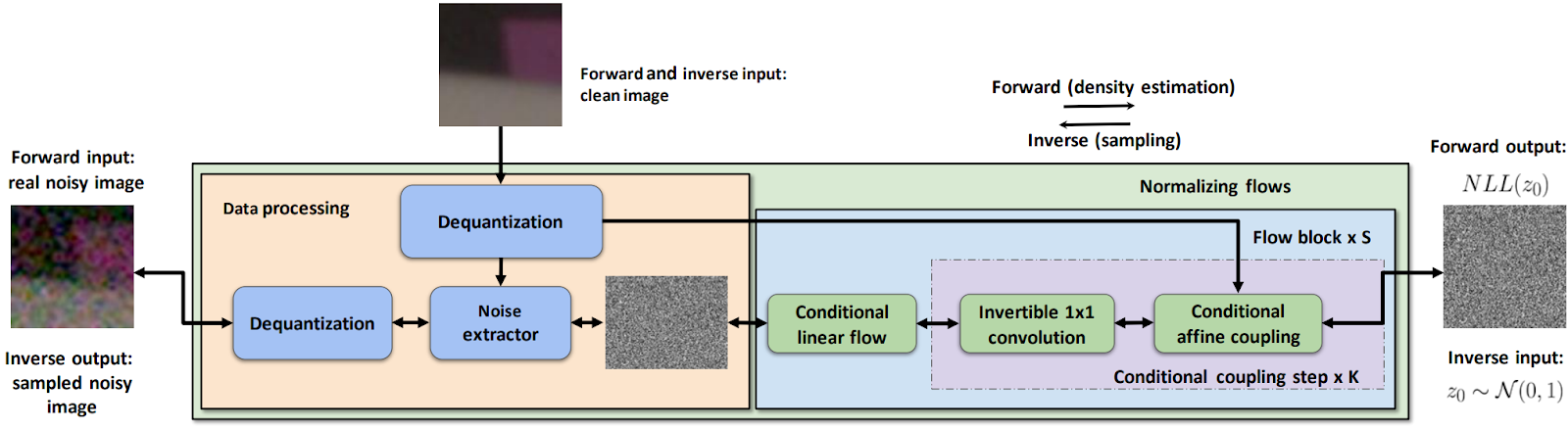
As a result, they learn a noise distribution that is much closer to the real noise distribution (in terms of KL divergence) than previous efforts. There are no beautiful pictures to show here, it’s all about small variations in noisy patches viewed under high magnification, but trust me, as I’ve tried to explain above, this line of research may prove to be very important for synthetic data generation.
Phew, that was a long one! Today we have discussed several papers from CVPR 2022 that can help with synthetic data generation; I have tried to be thorough but definitely do not claim this post to be an exhaustive list. We have run the gamut from low-level computer vision (camera noise) to reconstructing animatable models from video collections. Next time, we will survey what CVPR 2022 has brought to the table of domain adaptation, another hugely important topic in synthetic data. See you then!
Sergey Nikolenko
Head of AI, Synthesis AI
