
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
In a recent series of talks and related articles, one of the most prominent AI researchers Andrew Ng pointed to the elephant in the room of artificial intelligence: the data. It is a common saying in AI that “machine learning is 80% data and 20% models”, but in practice, the vast majority of effort from both researchers and practitioners concentrates on the model part rather than the data part of AI/ML. In this article, we consider this 80/20 split in slightly more detail and discuss one possible way to advance data-centric AI research.
The basic life cycle of a machine learning project for some supervised learning problems (for instance, image segmentation) looks like this:
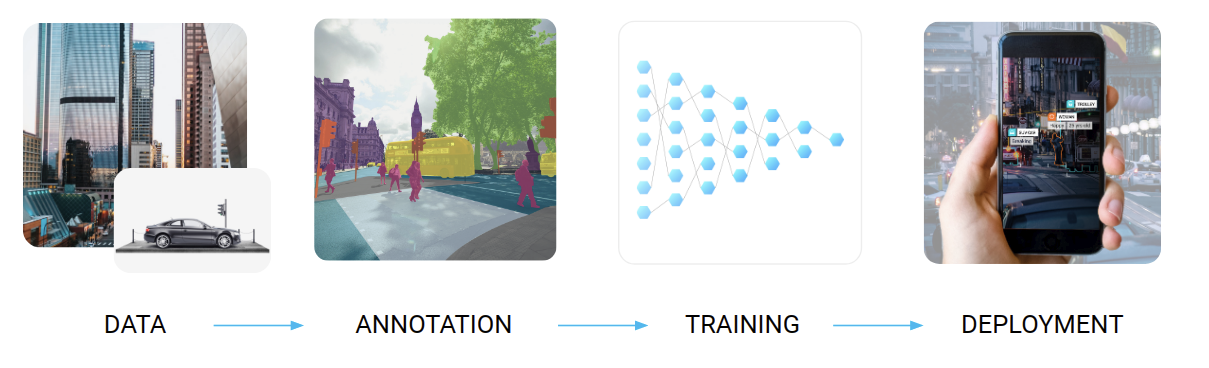
First, one has to collect data, then it has to be labeled according to the problem at hand, then a model is trained on the resulting dataset, and finally the best models have to be fitted into edge devices where they will be deployed. In my personal opinion, these four parts are about equally important in most real life projects; but if you look at the research papers from any top AI conference, you will see that most of them are about the “Training” phase, with a little bit of “Deployment” (model distillation and similar techniques that make models fit into restricted hardware) and an even smaller part devoted to the “Data” and “Annotation” parts (mostly about data augmentation).
This is not due to simple narrow-mindedness: everybody understands that data is key for any AI/ML project. But usually the model is the sexy part of research, where new ideas flourish and intermingle, and data is the “necessary but boring” part. Which is a shame because, as Andrew Ng demonstrated in his talks, improvements in the data department often hang much lower than improvements in state of the art AI models.
On the other hand, collecting and especially annotating the data is increasingly becoming a problem, if not a hard constraint on AI research and development. The required labeling is often very labor-intensive. Suppose that you want to teach a model to count the cows grazing in a field, a natural and potentially lucrative idea for applying deep learning in agriculture. The basic computer vision problem here is either object detection, i.e., drawing bounding boxes around cows, or instance segmentation, i.e., distinguishing the silhouettes of cows. To train the model, you need a lot of photos with labeling such as this one:

Imagine how much work it would take to label tens of thousands of such photographs! Naturally, in a real project you would use a weaker already existing model and use manual labor only to correct the mistakes, but it still might take thousands of man-hours.
Another important problem is dataset bias. Even in applications where real labeled data abounds, existing datasets often do not cover cases relevant for new applications. Take face recognition, for instance; there exist datasets with millions of labeled faces. But, first, many such datasets have racial and ethnic bias that often plagues major datasets. And second, there are plenty of use cases in slightly modified conditions: for example, a face recognition system might need to recognize users from any angle, but existing datasets are heavily scaled towards frontal and profile photos.
These and other problems have been recently combined under the label of data cascades, as introduced in this Google AI post. Data cascades include dataset bias, real world noise that is absent in clean training sets, model drifts where the targets change over time, and many other problems, up to poor dataset documentation.
There exist several possible solutions to basic data-related problems, all increasingly explored in modern AI:
But these solutions are far from universal: if existing data (used for pretraining) has no or very few examples of the objects and relations we are looking for, these approaches will not be able to “invent” them. Fortunately, there is another approach that can do just that.
I am talking about synthetic data: artificially created and labeled data used to train AI models. In computer vision this would mean that dataset developers create a 3D environment with models of the objects that need to be recognized and their surroundings. In a synthetic environment, you know and control the precise position of every object, which gives you pixel-perfect labeling for free. Moreover, you have total control over many knobs and handles that can be adapted to your specific use case:
For instance, synthetic human faces can have any facial features, ethnicities, ages, hairstyles, accessories, emotions, and much more. Here are a few examples from an existing synthetic dataset of faces:

Synthetic data presents its own problems, the most important being the domain shift problem that arises because synthetic data is, well, not real. You need to train a model on one domain (synthetic data) and apply it on a different domain (real data), which leads to a whole field of AI called domain adaptation.
In my opinion, the free labeling, high variability, and sheer boundless quantity of synthetic data (as soon as you have the models, you can generate any number of labeling images at the low cost of rendering) far outweigh this drawback. Recent research is already showing that even very straightforward applications of synthetic data can bring significant improvements in real world problems.
But wait, there is more. The “dataset” we referred to above is more than just a dataset—it is an entire API (FaceAPI, to be precise) that allows a user to set all of these knobs and handles, generating new synthetic data samples at scale and in a fully automated fashion, with parameters defined for API calls.
This opens up new, even more exciting possibilities. When synthetic data generation becomes fully automated, it means that producing synthetic data is now a parametric process, and the values of parameters may influence the final quality of AI models trained on this synthetic data… you see where this is going, right?
Yes, we can treat data generation as part of the entire machine learning pipeline, closing the feedback loop between data generation and testing the final model on real test sets. Naturally, it is hard to expect gradients to flow naturally across the process of rendering 3D scenes (although recent research may suggest otherwise), so learning the synthetic data generation parameters can be done, e.g., with reinforcement learning that has methods specifically designed to work in these conditions. This is an early approach taken by VADRA (Visual Adversarial Domain Randomization and Augmentation):

A similar but different approach would be to design more direct loss functions by either collecting data on the model performance and then learning or finding other objectives. Here, one important example would be the Meta-Sim model that learns to minimize the distribution gap between synthetic 3D scenes and real scenes together with downstream performance by learning the parameters of scene graphs, a natural representation of the 3D scene structure.
These ideas are being increasingly applied in the studies of synthetic data, and I believe that adaptive generation of synthetic data will be increasingly used in the near future and bring synthetic data to a new level of usefulness for AI/ML. I hope that the progress of modern AI will not stop at the current data problem, and I believe that synthetic data, especially automatic generation and closing the feedback loop, is one of the key tools to overcome it.
Sergey Nikolenko
Head of AI, Synthesis AI
