
Do Androids Dream? World Models in Modern AI
One of the most striking AI advances this spring...
Last time, we started a new series of posts: an overview of papers from CVPR 2022 that are related to synthetic data. This year’s CVPR has over 2000 accepted papers, and many of them touch upon our main topic on this blog. In today’s installment, we look at papers that make use of synthetic data to advance a number of different use cases in computer vision, along with a couple of very interesting and novel ideas that extend the applicability of synthetic data in new directions. We will even see some fractals as synthetic data! (image source)

In the first post of this series, we talked about new synthetic datasets in computer vision. This post is only superficially different from the first one: here we will consider papers that apply synthetic data to various practical use cases, concentrating more on the downstream task than on synthetic data generation. However, the generation part here is also often interesting, and we will definitely discuss it.
I will also take this opportunity to discuss two very interesting developments related to synthetic data. First, we will see that synthetic images do not have to be realistic at all to be helpful for training even state-of-the-art visual Transformers, and it turns out that this has a lot to do with fractals. In the last part, we will see how synthetic data helps to automatically fill in the gaps and provide missing data for few-shot learning. But before that, we will see several use cases where synthetic data has helped solve practical computer vision problems. Among these use cases, today we do not consider papers that help generate synthetic data and papers that deal with generating or modifying virtual humans—these will be the topics for later posts.
Just like last time, I remind you that we have launched OpenSynthetics, a new public database of all things related to synthetic data. In this post, I will again give links to the corresponding OpenSynthetics pages.
In “Portrait Eyeglasses and Shadow Removal by Leveraging 3D Synthetic Data” (OpenSynthetics), Lyu et al. consider an interesting image manipulation problem: removing glasses from a human face. While solving this problem is desirable for applications such as face verification or emotion recognition, eyeglasses are very tricky objects for computer vision: they are mostly transparent but can cast shadows and introduce other complex effects in the image. The model constructed in this work consists of two stages: a cross-domain segmentation network predicts segmentation masks of the glasses and shadows cast by them (this part is trained adversarially in order to extract indistinguishable features from real and synthetic data), and then “de-shadow” and “de-glass” networks remove both:
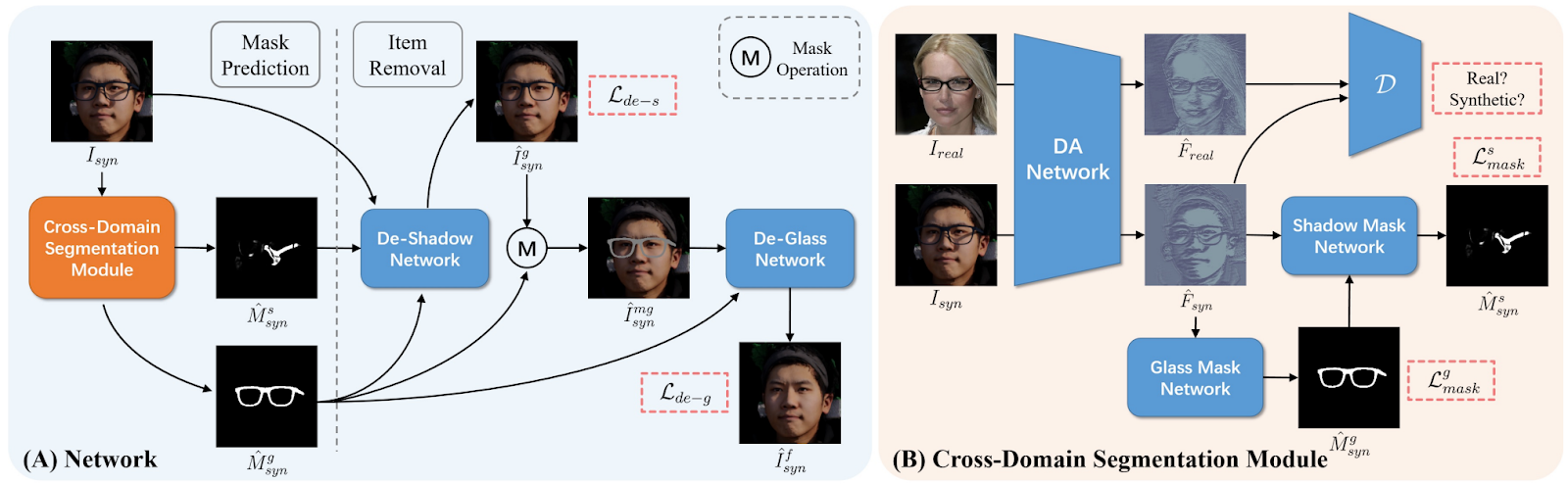
The whole thing is trained on a mixture of synthetic data and the CelebA dataset (real data), and the authors report much improved results for eyeglass removal:

This system is the main point of the paper, but for me, it was also interesting to read about their synthetic data generation pipeline. Starting from 3D models of eyeglasses and 3D face models, they manually label four nodes where the glasses attach to the face: two fixed nodes on the temples and two floating points on the nose, “floating” meaning that these two points can drift to produce different positions of glasses on the nose. With these four nodes fixed, the system is able to find out the pose for the glasses, combine it with the face, and then the authors proceed to standard rendering in Blender, also generating the masks for glasses and their shadows to train the segmentation model:
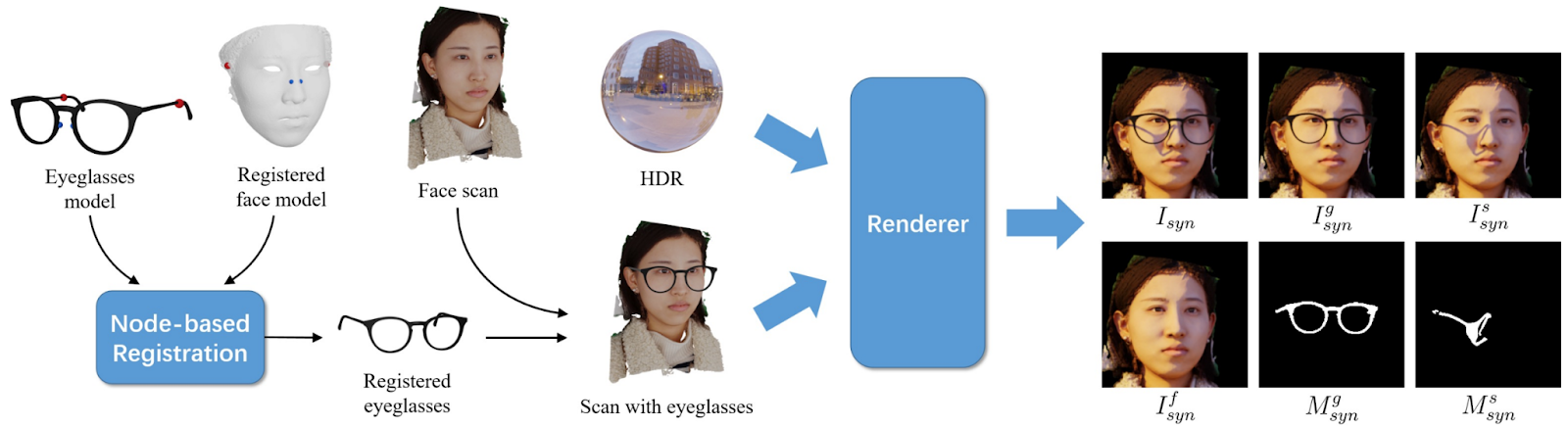
And the results are really impressive. Here are some real examples (perhaps cherry-picked, but who cares?..) from the paper:


The work “Leveraging Self-Supervision for Cross-Domain Crowd Counting” by Liu et al. (OpenSynthetics) deals with a very straightforward application of synthetic data. Crowd counting is a natural use case: it is very hard to label every person on a crowd photo, and using real images raises privacy issues since it is usually impossible to get the consent of everybody in a real-world crowd.
Indeed, there already exists a large synthetic dataset for crowd counting called GCC (Wang et al., 2019) with over 7.6 million people labeled on over 15K synthetic images. This dataset was produced by the Grand Theft Auto V engine, that is, Rockstar Advanced Game Engine (RAGE), together with the Script Hook V library that allows extracting labeling from RAGE. Here are two sample images from the paper, a real crowd on the left and a synthetic one on the right:

Liu et al. use GCC for training and supplement it with unlabeled real images to cope with the domain shift, with a couple of new tricks designed to improve crowd density estimation (such as accounting for perspective since the crowd density appears higher on top of an image such as above than on the bottom). They obtain significantly improved results compared to other domain adaptation approaches; here are a couple of samples (the ground truth crowd density map is in the middle, and the estimated density map is on the right, together with the estimated number of people):
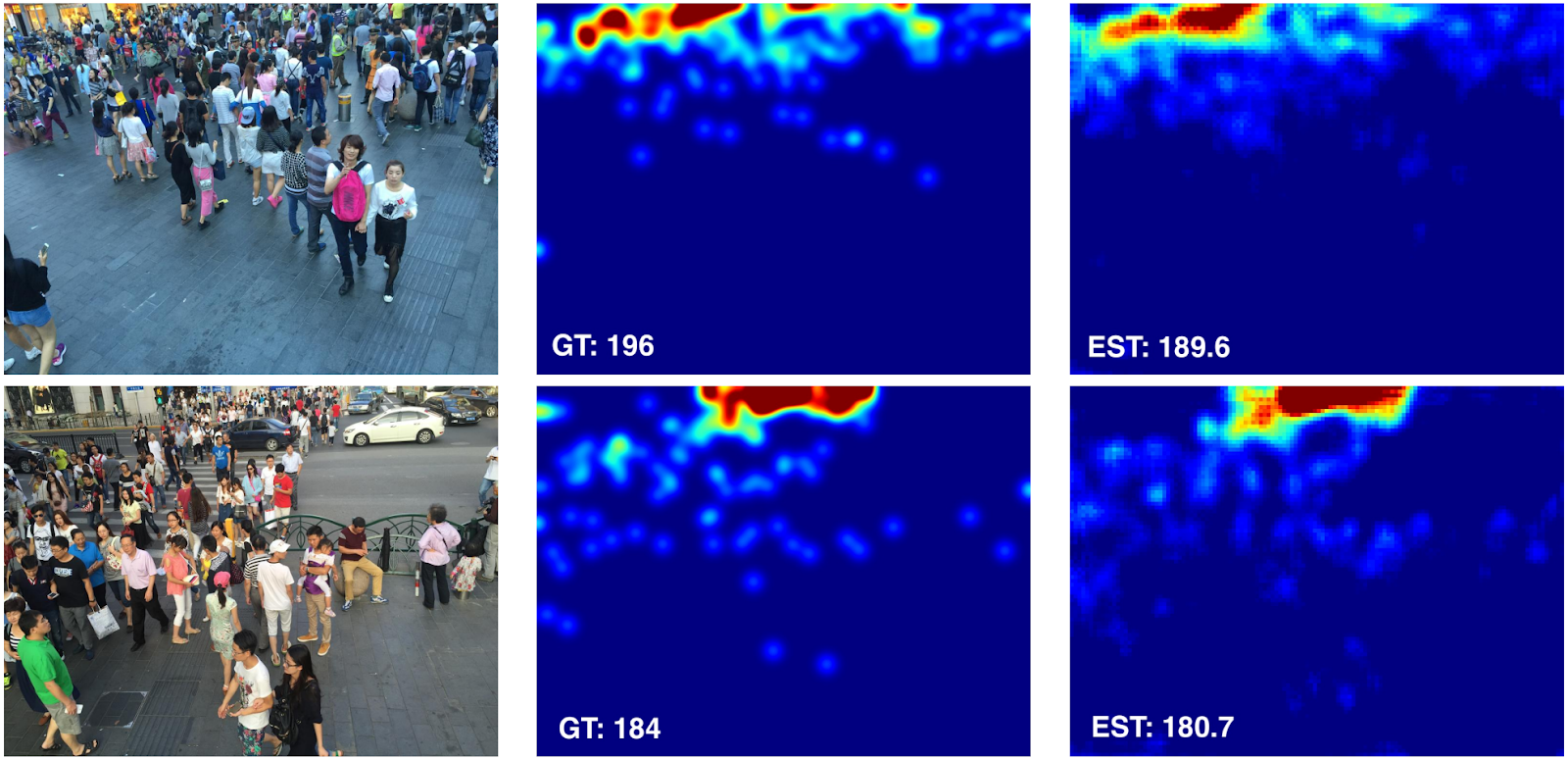
This is an interesting use case for us since it can be read as reaching largely the same conclusions as we did in our recent white paper: if done right, relatively simple combinations of synthetic and real data can work wonders. It is encouraging to see such approaches appear at top venues such as CVPR: I guess synthetic data does just work.
And now we proceed from state of the art, but still quite straightforward applications to something much stranger and, in my opinion, more interesting. First, a very unusual application of synthetic data that requires a little bit of context. In 2020, Kataoka et al. presented a completely new approach to training convolutional networks called Formula-Driven Supervised Learning (FDSL). They automatically generate image patterns by assigning image classes with analytically defined fractal categories. It raises a separate and quite difficult problem of how to do that, but the important thing is that after this transformation, you get a family of fractals for each image category. Here is an illustration from Kataoka et al.:
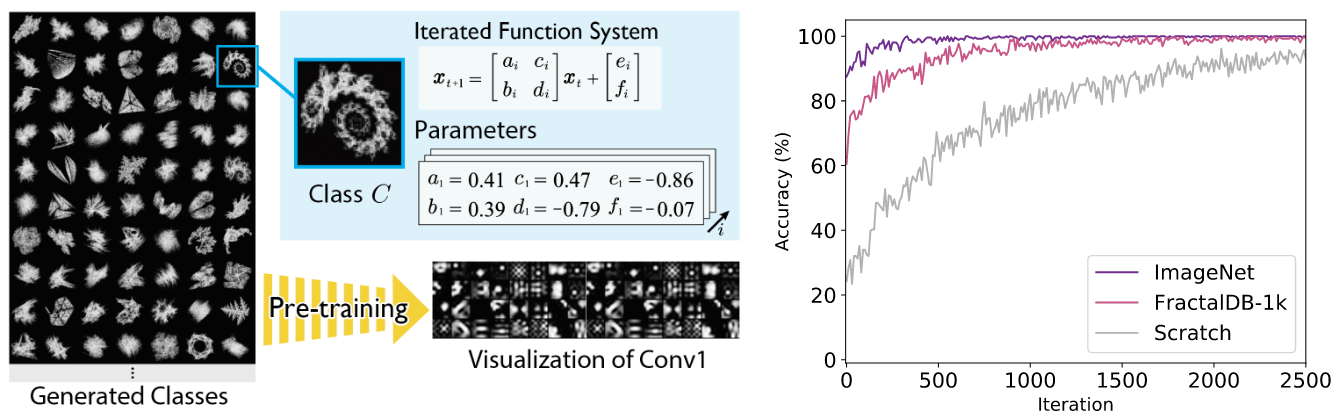
Well, in 2022 Kataoka et al. made the next step (OpenSynthetics), moving from CNNs to visual Transformers. They developed new techniques for their synthetic generation, including a new dataset of families focused on image contours. It turned out that visual Transformers pay most attention to the contours anyway, so even a textureless image is helpful for pretraining:

And visual Transformers perform better when they are pretrained on images like this one instead of real photos! For example, the authors report that ViT-Base pre-trained on ImageNet-21k showed 81.8% top-1 accuracy after fine-tuning on ImageNet-1k, while the same model with FDSL shows 82.7% top-1 accuracy when pre-trained under the same conditions.
In my opinion, this is a very interesting direction of study. Apart from its direct achievements, it also shows that synthetic-to-real domain shift is not necessarily a bad thing, and if the data is generated in the right way, trying to achieve photorealism may not be the right way to go.
This last paper for today is a little bit of a stretch to call synthetic data, but it’s another interesting idea that may have applications for synthetic data generation as well. Last time, we discussed BigDatasetGAN, a generative model able to create images already labeled for semantic segmentation. This may be one of the first steps towards solving the problem of synthetic data: until the works on DatasetGANs, nobody could generate labeled data so nobody could use generative models to directly generate useful synthetic images.
If we are talking about classification rather than segmentation, it looks much easier to sidestep this issue: ever since BigGAN, generative models could produce realistic-looking images in many different categories. But this raises another question: to train a generative model we need a dataset in this category, so why don’t we just take this dataset to train on instead of generating new samples?
The work “Generating Representative Samples for Few-Shot Classification” (OpenSynthetics) by Xu and Le, a collaboration between Stony Brook University and Amazon, finds a new use case where this kind of conditional generation can be useful. The basic idea is as follows: in few-shot learning, say for image classification, one usually trains a feature extractor on a dataset with plenty of labeled data (but the wrong classes) and then adapts it to new classes by estimating a prototype sample. Then this sample can be used for classification; here is an illustration for few-show and zero-shot classification via prototypes from a classical paper by Snell et al. that started this field:
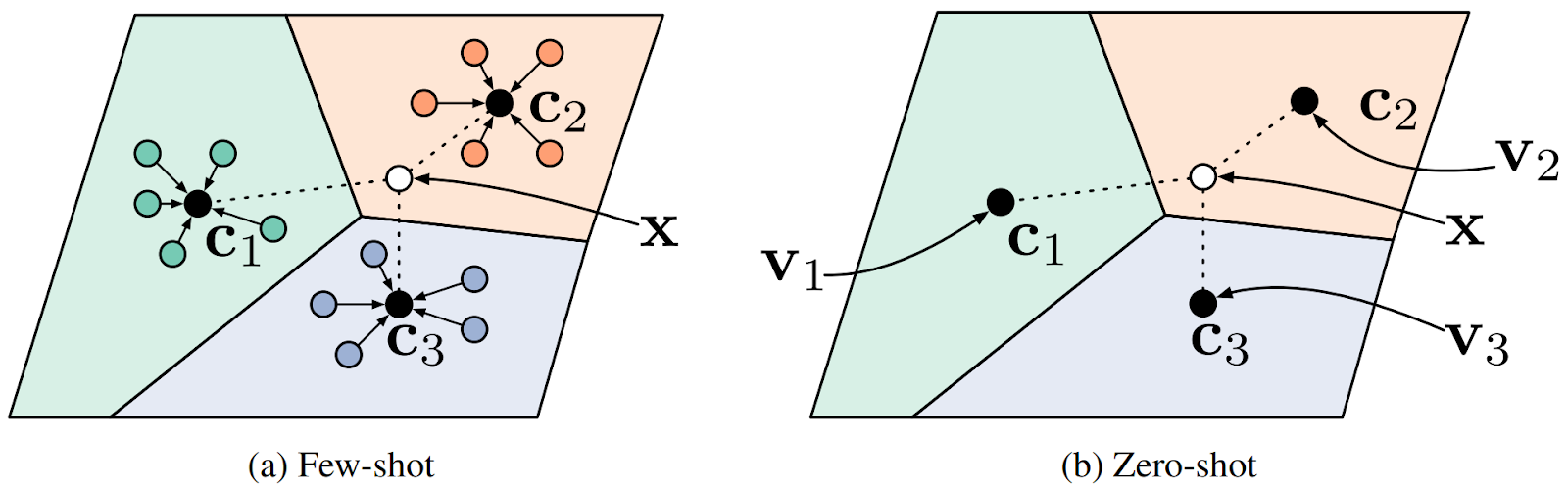
This illustration works in the latent space of features produced by some kind of encoder.
But this prototype-based idea has a drawback: it is hard to find a representative prototype if all you have are a few samples. Even if you have a perfect encoder that produces smooth and wonderfully separated Gaussians for every class, these Gaussians have a core of central representative samples and also non-representative samples that are further from the center:
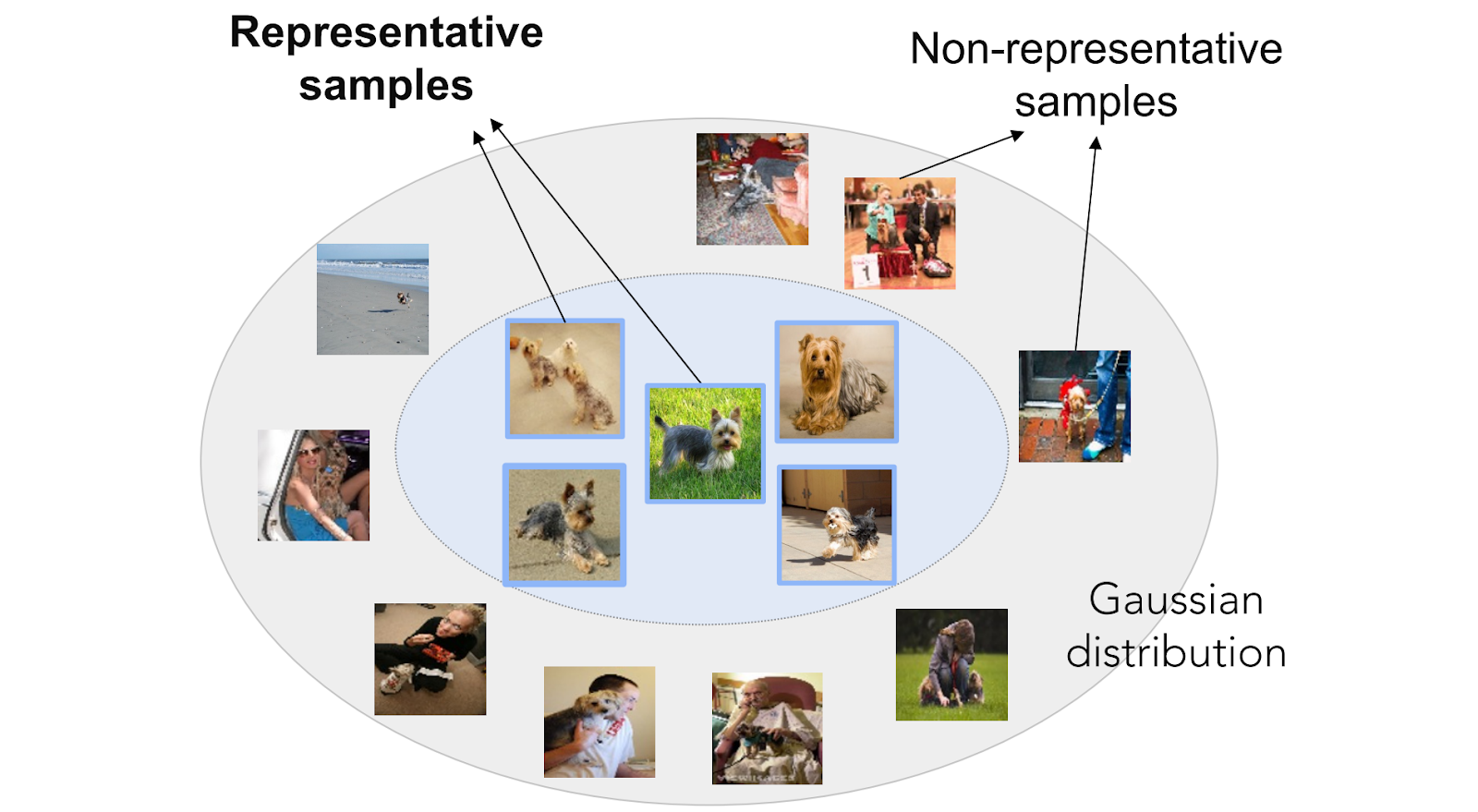
And if we base a classifier on a single prototype that turns out to be non-representative, the results can be far from perfect. Here is an illustration from an ICLR 2021 paper by Yang et al.:
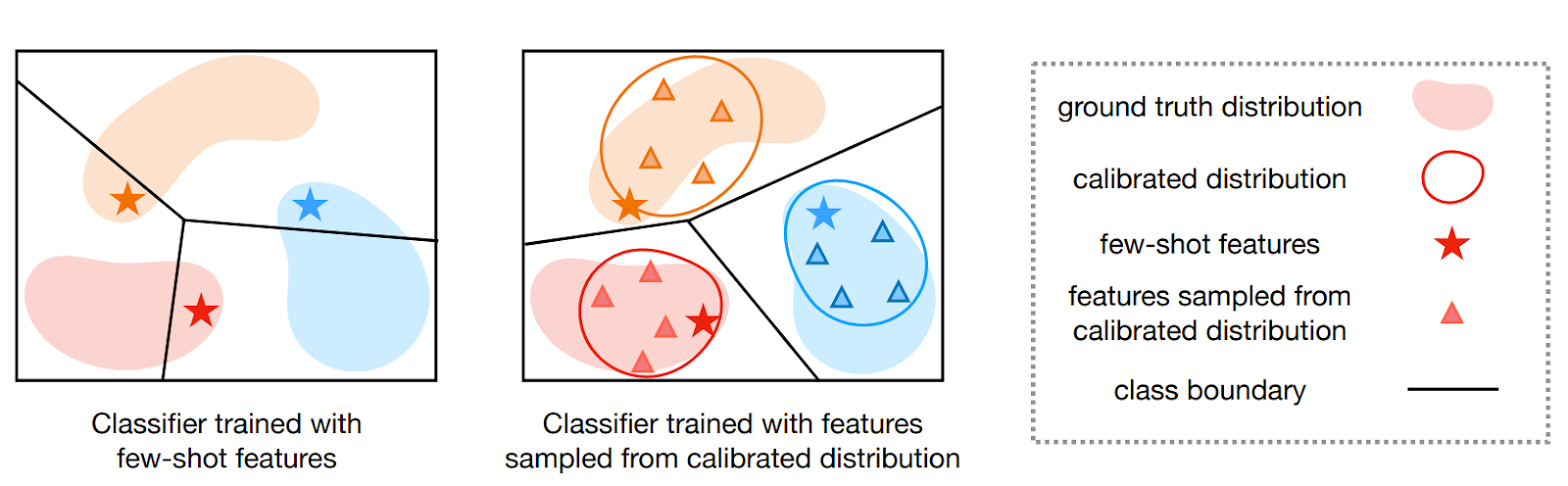
But how do we achieve this kind of calibration? Xu and Le propose—and this is where the relation to synthetic data comes into play—to generate representative samples from a variational autoencoder. It is common to use conditional VAEs to learn to extract representative features from images, but this time the cVAE is restricted to produce only representative, central examples of a class (feature vectors close to the center of a Gaussian) via sample selection:

Note the semantic embedding a: this is where the new samples will come from. For a new class, the authors take its semantic embedding, plug it into this VAE’s decoder, and generate representative samples for the new class. Then the resulting generated prototype is either mixed with actual samples (in few-shot classification) or not (in zero-shot classification), with improved results on miniImageNet and tieredImageNet.
This is definitely a non-representative example of a paper on synthetic data: the “data” is actually in feature space, and the problem is image classification rather than anything with complicated labeling. But this direction, dating back at least to 2018 (Verma et al., CVPR 2018), is an interesting tangent to our space, and just like DatasetGAN, it goes to show a way in which generative models may prove useful for synthetic data generation.
In this post, the second in the CVPR ‘22 series, we have discussed several use cases of synthetic data that have been advanced at the conference, starting from straightforward applications such as eyeglass removal and crowd counting and progressing to less obvious ideas of how deep generative models and even regular mathematical models such as fractals can help produce synthetic data useful for machine learning. Next time, we will discuss a more specific use case related to synthetic humans; stay tuned!
Sergey Nikolenko
Head of AI, Synthesis AI
