
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Last time, we talked about new use cases for synthetic data, from crowd counting to fractal-based synthetic images for pretraining large models. But there is a large set of use cases that we did not talk about, united by their relation to digital humans: human avatars, virtual try-on for clothes, machine learning for improving animations in synthetic humans, and much more. Today, we talk about the human side of CVPR 2022, considering two primary applications: conditional generation for applications such as virtual try-on and learning 3D avatars from 2D images (image generated by DALL-E-Mini by craiyon.com with the prompt “virtual human in the metaverse”).

In the first post of this series, we talked about new synthetic datasets presented at CVPR ‘22. The second post was devoted to various practical use cases where synthetic data has been successfully used. Today, we dive deeper into a single specific field of application related to digital humans, i.e., models that deal with generating either new images of humans or 3D models (virtual avatars) that can be later animated or put into a metaverse for virtual interaction.
Just like in the previous posts, papers will be accompanied by links to OpenSynthetics, a public database of all things related to synthetic data that we have launched recently. We have two important directions in today’s post: conditional generation with different features (usually for virtual try-on applications) and trying to learn synthetic human avatars from photographs. Let me begin with a paper that, in a way, combines the two.
We begin with “BodyGAN: General-purpose Controllable Neural Human Body Generation” (OpenSynthetics), where Yang et al. continue a long line of work devoted to generating images of humans with GANs. Throughout the history of GAN development, humans always showcased the progress, from the earliest attempts that couldn’t capture human faces at all to the intricate modifications allowed by the StyleGAN family. I’ve been showing this famous picture by Ian Goodfellow in my lectures since 2018:

And current results by, say, StyleGAN 3 are much more diverse and interesting:

The classical line of improvements, however, only dealt with the faces, mostly inspired by the CelebA dataset of celebrity photos. Generating full-scale humans with different poses and clothing is a much harder task, especially if you wish to control these parameters separately. There has been previous work, including StyleRig that tried to add 3D rigging control to StyleGAN-generated images and StylePoseGAN that added explicit control over pose, and these works are exactly what BodyGAN promises to improve.
Let’s briefly go through the main components of BodyGAN:

It has three main components:
Training utilizes two discriminators, one for the pose branch and another for the appearance branch, and during inference one can substitute new shape, pose, and appearance encodings (e.g., change the skin color) to obtain new realistic images:
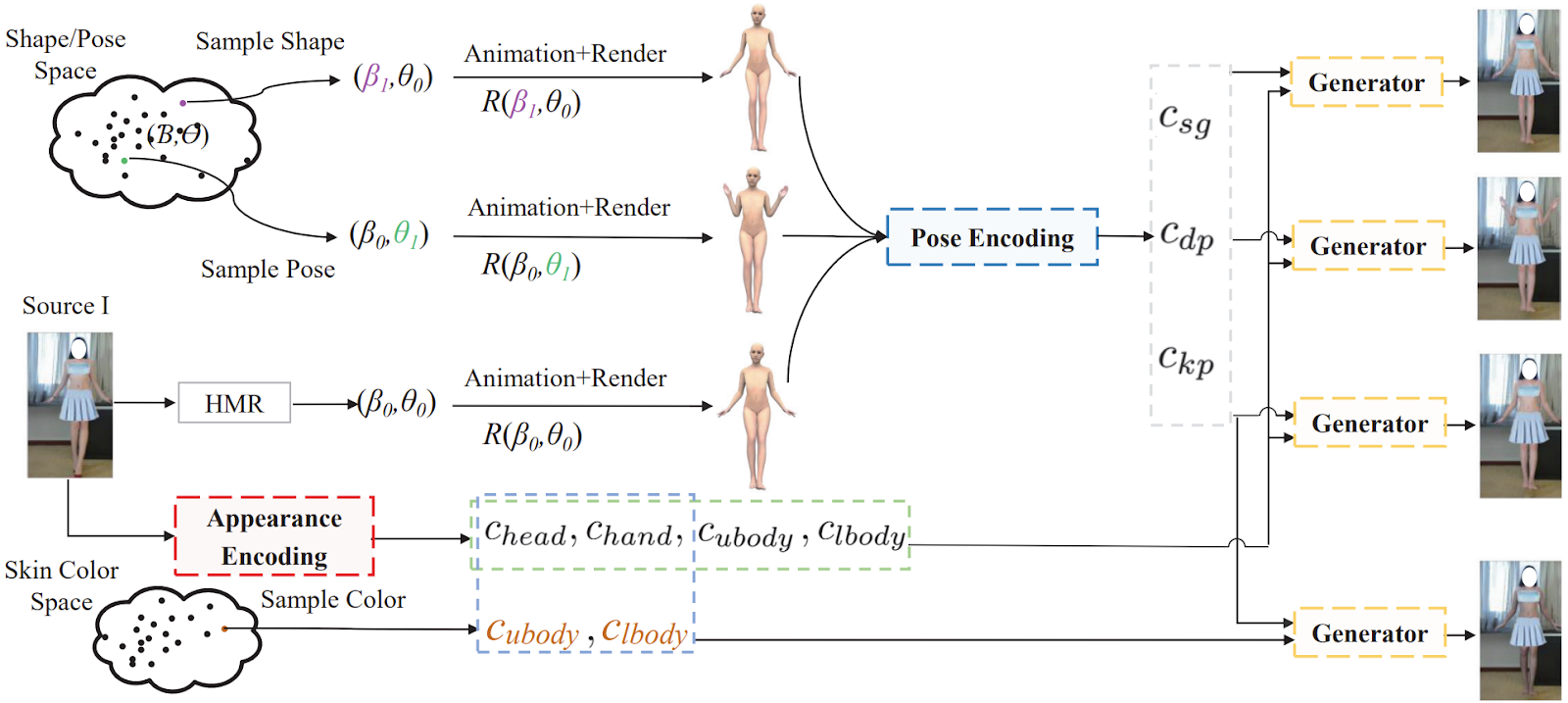
So overall it is a relatively straightforward architecture that hinges on explicit disentanglement between different features, and the network architectures are also quite standard (e.g., discriminators are taken from pix2pixHD). Interestingly, it works better than previous results; here are some characteristic samples for the main application in the paper, virtual try-on (with conditions shown as small images in the corners):

We will see more results about virtual try-on below, it was a hot topic on CVPR ‘22; however, this work shows that even a relatively straightforward but well-executed take on the problem can produce very good results. Overall, it looks like we are almost there in regard to these kinds of conditional generation and style transfer applications for images; I would expect truly photorealistic results quite soon.
But that conclusion was only about images; producing convincing photorealistic videos is much harder, and we still have some way to go here. The work “Dressing in the Wild by Watching Dance Videos” (OpenSynthetics) by ByteDance researchers (ByteDance is the mother company of TikTok) takes an intermediate ground: they do show some results on videos but primarily use videos to perform better garment transfer on still images with challenging poses.
First, they present a dataset of 50000 real life single-person dance videos, Dance50k, with a lot of different garments and poses (at the time of writing, Dance50k was not yet fully available but it’s supposed to be released at the project page). The videos do look diverse enough to get a wide variety of different poses in the wild:

The model itself is interesting and stands out among the usual GAN-based conditional generation. It is called wFlow but the word “flow” is not about flow-based generative models that have become increasingly popular over the last few years. This time, it is about optical flow estimation: the model has a component estimating where each pixel in the source image should go in the target image.

Let us go through the pipeline. The input includes a source image of a person where the garment comes from and a query pose image where the pose comes from. The wFlow model works as follows:
There are some more interesting tricks in the paper, but let’s skip those and get to sample results. First, you can see why videos are hard; video results do have some inconsistencies and flicker across frames, and the lighting is hard to get right:
But as for still images, the model produces excellent results that already look quite sufficient for the virtual try-on application:

We now move on from garment transfer to learning digital avatars. The main difference here is that you have to construct a 3D avatar from 2D images, and then perhaps teach that avatar a few tricks. The first paper of this batch, “I M Avatar: Implicit Morphable Head Avatars from Videos” (OpenSynthetics), concentrates on models of human heads.
In synthetic data and generally computer generated graphics, human heads are often represented with 3D morphable face models (3DMMs); it is a huge field starting from relatively simple parametric models in the late 1990s and continuing these days into much more detailed and nonlinear neural parametric face models. The idea is to model the appearance and facial geometry in a lower-dimensional representation, together with a decoder to produce the actual models (meshes). This idea underlies, in particular, our very own HumanAPI, and here at Synthesis AI we are also investigating new ideas for human head generation based on 3DMMs. This field is also closely related to neural volumetric modeling, e.g., neural radiance fields (NeRF) that are rapidly gaining traction; I hope to devote a later post to the recent developments of NeRFs at CVPR ‘22.
In this work, Zheng et al. base their approach on the FLAME model that parameterizes shape, pose, and expression components. Basically, the 3DMM here consists of three networks (neural implicit fields): one predicts the occupancy values for each 3D point, another one predicts deformations, i.e., transformations of canonical points (points from the original model) to new locations based on facial expressions, and the third provides textures by mapping each location to an RGB color value.
The crux of the paper lies in how to train these three networks. The main approach here is known as implicit differentiable rendering (IDR), an idea that certainly deserves a separate post. In essence, the neural rendering model produces RGB values for a given camera position (also learnable) and image pixel, and the whole thing is trained to represent actual pixel values:

As a result, this network is able to generate (render) new views from previously unseen angles. Zheng et al. adapt this approach to their 3DMM; this requires some new tricks to deal with the iterative nature of finding the correspondences between points (it’s hard to propagate gradients through an iterative process). I will not go into these details, but here is an illustration of the resulting pipeline, where all three networks can be trained jointly in an end-to-end fashion:

As a result, the model produces an implicit representation of a given human head, which means that you can generate new views, new expressions and other modifications from this model. Here is how it works on synthetic data:
And here are some real examples:
Looks pretty good to me!
In this collaboration (OpenSynthetics) between Tsinhua University and Ant Group (a company affiliated with Alibaba Group), Wang et al. also deal with learning 3D morphable models of human faces. In this case, the emphasis is on the data—not synthetic data, unfortunately for this blog, but on data nevertheless.
Similar to many other fields, 3D face datasets come in two varieties: either coarse or small. It’s easy to get a rough dataset with ToF cameras built into many modern smartphones, but to get a high-definition 3D scan you need expensive hardware that only exists in special labs. Wang et al. do both, collecting a large coarse dataset (on the left below) and a small high-quality dataset (on the right):
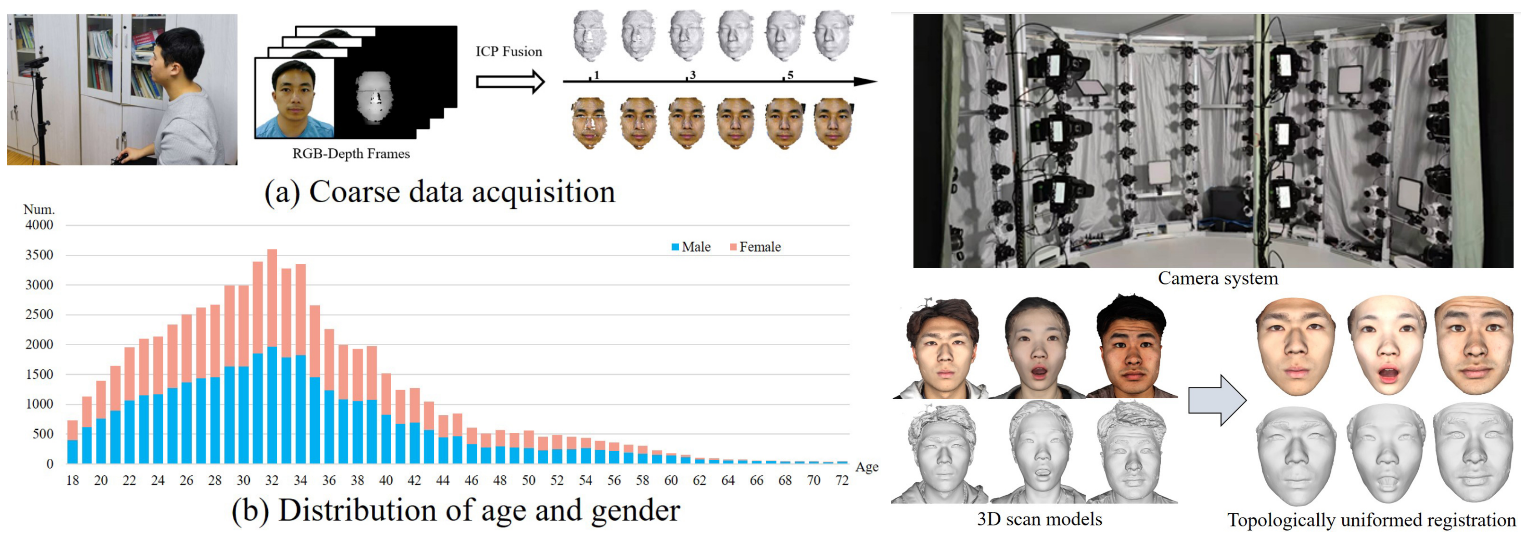
The FaceVerse model then proceeds in the same coarse-to-fine fashion: first the authors fit a classical PCA-based 3D morphable model on the coarse dataset, and then refine it with a detailed model similar to StyleGAN, using the smaller high-quality dataset to fine-tune the detalization part:

These steps are then reproduced on inference, providing a model that gradually refines the 3D model of a face to obtain very high quality results at the end:

Overall, it appears that while there is still some way to go, monocular face reconstruction may soon become basically solved. State of the art models are already doing such an excellent job that give it a few more years, and while the results may still not have movie-ready photorealistic quality, they will be more than enough to cover our needs for realistic avatars in 3D metaspace.
The previous two papers were all about heads and faces, but what about the rest of us? In “Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing” (OpenSynthetics), Google researchers Alldieck et al. present a deep learning model that can take a photo and create a full-body 3D model, complete with clothing.
This is far from a new problem; previous approaches include, e.g., PIFu from USC and Waseda University, Geo-PIFu from UCLA and Adobe, and PIFuHD from Facebook. This line of models produced very good results already, extracting voxel features from a single image and filling in the occluded details. An important drawback of these works, however, was how they worked with color of the surfaces: usually the resulting model had color taken from the photo, with shading effects baked in and hard to disentangle from geometry. This made it difficult to use the resulting model in any way except copy-and-paste, even changing the lighting could produce rather bad results.
In essence, PHORHUM continues the line of PIFu (pixel-aligned implicit function) models: the idea is to represent a 3D surface as a level set of a function f, e.g., the set of points x such that f(x)=0. In this way, you don’t need to store the actual voxels and are free to parameterize the function f in any way you choose—obviously, these days you would choose to parameterize it as a neural network.
In PIFu models, the image is encoded with an hourglass network to obtained point-specific features, and then the surface is defined as an multilayer perceptron that takes as input the features of a current point (its projection on the image) and the depth. The original PIFu had two different functions, one to encode the surface itself and another to predict the RGB values at the current point:
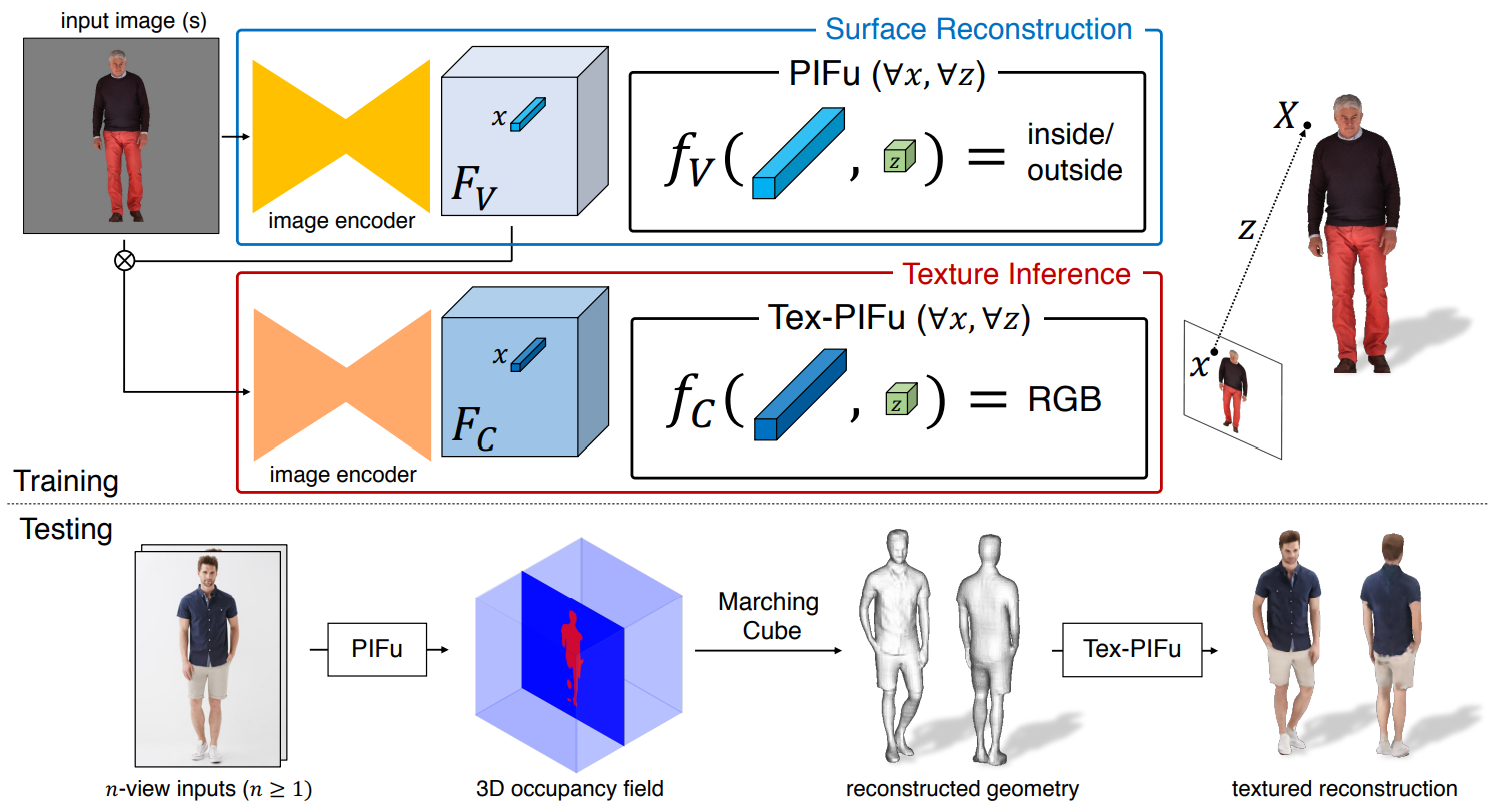
To cope with the problem of colors and shading, PHORHUM tries to explicitly disentangle unshaded colors of every point on the surface and the lighting effects. This means that the function is trained to output not the actual color of a pixel but the albedo color, that is, the base color of the surface, and then PHORHUM has a separate shading network to modify it according to lighting conditions:

As a result, you obtain the albedo colors of skin and clothing, and then it becomes much easier to automatically animate the resulting models, adapting to new lighting as needed:
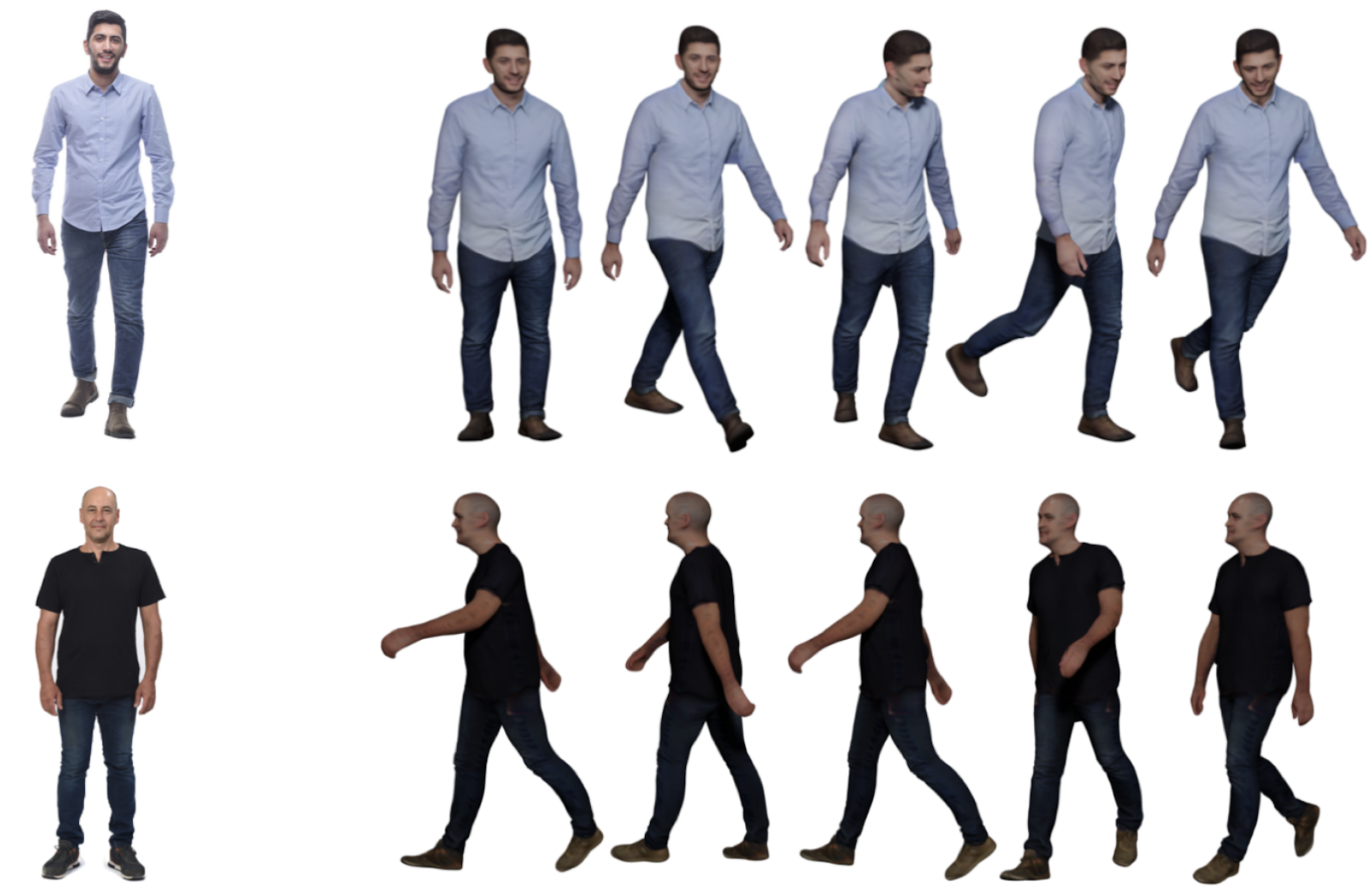
To get this kind of quality, you are supposed to have a good shot of the person but it doesn’t have to be a lab shot with white or green background, anything will do:

Overall, between the previous papers and this one it seems that we will soon have perfectly acceptable virtual avatars walking around various metaverses. I have my doubts about whether this will usher in a new era of remote workplaces and entirely new forms of entertainment—at the very least, we’d first need something less cumbersome than a VR helmet to navigate these metaverses. But it looks like the computer vision part is almost there already.
Finally, let me conclude today’s post with something completely different. Have you ever wondered how animated movies match the characters’ speech with their mouths and tongues? Currently, there are two answers: either poorly or very, very laboriously. In computer games and low-budget animation, character models usually have several motions for different vowels and consonants and try to segue from one to another in a more or less fluid way. In high-budget animation (think Pixar), skilled animators have to painstakingly match the movements of the palate and tongue to speech, a process that is both very difficult and very expensive.
In “Speech Driven Tongue Animation” (OpenSynthetics), Medina et al. from Carnegie Mellon University and Epic Games present a model for automatically generating tongue movements that match the speech. To get the data, you need to do tongue motion capture—I’d never think it was possible but apparently people have been doing it for medical purposes for a long time:
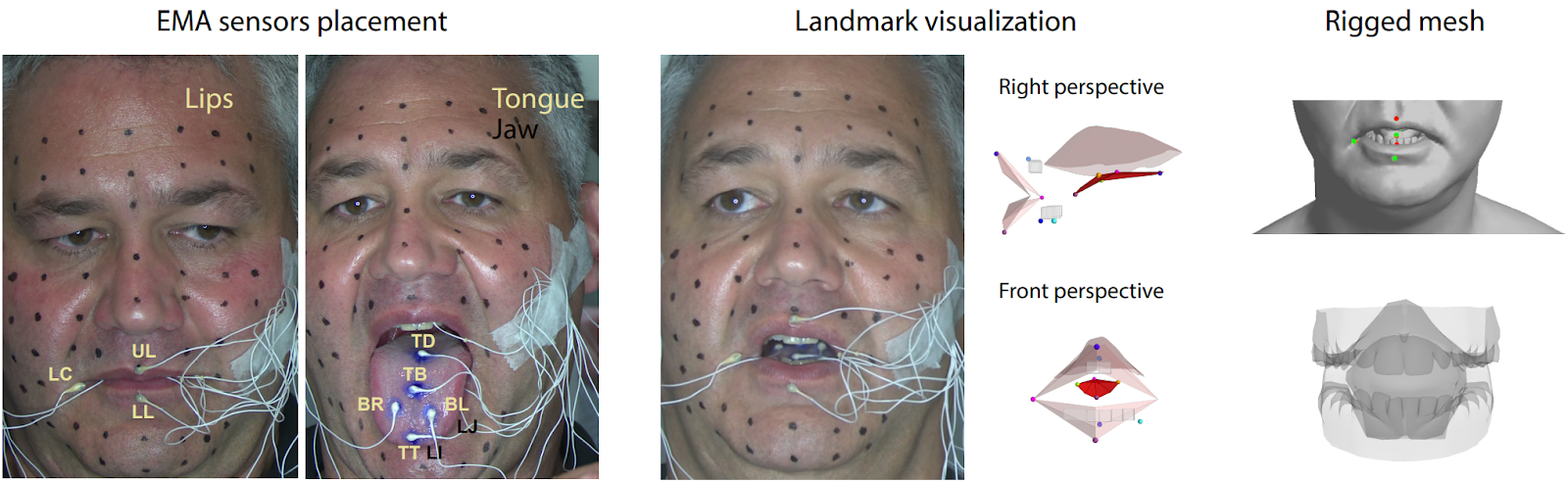
After that, you need to have an encoder to convert speech into features and a decoder that will take these features and get you the tongue animation. The authors have tried several different encoders and decoders, choosing the best results among both classical and recently introduced feature extractors:

Landmark locations are then postprocessed to get the actual animation. This paper won the Best Demo Award at CVPR ‘22, so be sure to check out their website and in particular their video with examples and descriptions.
The paper is affiliated with Epic Games, so I would expect this feature to make its way into Unreal Engine 6 or something, but this paper got me thinking about another possible application. I am not a native English speaker, and although I usually watch movies in English my 11-year-old daughter, naturally, requests Russian voices when we watch Pixar/Disney movies. The modern dubbing industry is quite advanced and goes to great lengths to make speech in a different language more or less fit the mouths animated for English… sometimes at the cost of meaning. It would be enormously expensive to re-animate movies for different languages by hand, but thanks to advances like this one, maybe one day animated movies will be distributed in several different languages with different lip animations produced automatically. And judging by the other results we have discussed in this post, maybe one day live-action movies will too…
In this third post about the results of CVPR ‘22, we have discussed several papers on virtual humans, a topic that has stayed important for CVPR over many years. In particular, we discussed two important use cases: conditional generation, usually in the form of virtual try-on, and production of 3D avatars from 2D images, both for heads/faces and for full-body avatars. Both problems are key areas of application for synthetic data, as we have seen today and as we have been working towards here at Synthesis AI.
Our next topic will be similar but not directly related to humans anymore: we will discuss generation of synthetic data (or any new photo and video material) based on 3D reconstruction and similar approaches. Stay tuned!
Sergey Nikolenko
Head of AI, Synthesis AI
