
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
We have already discussed how to extend the context size for modern Transformer architectures, but today we explore a different direction of this research. In the quest to handle longer sequences and larger datasets, Transformers are turning back to the classics: the memory mechanisms of RNNs, associative memory, and even continuous dynamical systems. From linear attention to Mamba, modern models are blending old and new ideas to bring forth a new paradigm of sequence modeling, and this paradigm is exactly what we discuss today.

We have already discussed at length how Transformers have become the cornerstone of modern AI, powering everything from language models to image processing (see a previous post), and how the complexity of self-attention, which is by default quadratic in the input sequence length, leads to significant limitations when handling long contexts (see another post). Today, I’d like to continue this discussion and consider the direction of linear attention that has led to many exciting advances over the last year.
In the several years of writing this blog, I have learned that it is a futile attempt to try to stay on top of the latest news in artificial intelligence: every year, the rate of progress keeps growing, and you need to run faster and faster just to stay in one place. What I think still matters is explaining ideas, both new ideas that our field produces and old ideas that sometimes get incorporated into deep learning architectures in unexpected ways.
This is why I am especially excited about today’s post. Although much of it is rather technical, it allows me to talk about several important ideas that you might not have expected to encounter in deep learning:
Taken together, these techniques represent a line of research… well, my first instinct here was to say “an emerging line of research” because most of these results are under two years old, and Mamba was introduced in December 2023. But in fact, this is an already pretty well established field, and who knows, maybe this is the next big thing in sequence modeling that can overcome some limitations of basic Transformers. Let us see what this field is about.
As we have discussed many times (e.g., here and here), traditional Transformers use softmax-based attention, which computes attention weights over the entire input sequence:
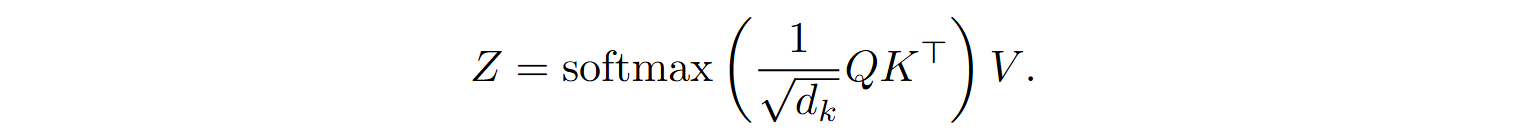
This formula means that kiTqj serves as the measure of similarity between a query qj and a key ki (see my previous post on Transformers if you need a reminder about where queries and keys come from here), and one important bottleneck of the Transformer architecture is that you have to compute the entire L⨉L matrix of attention weights. This quadratic complexity O(L2) limits the input size, and we have discussed several different approaches to alleviating this problem in a previous post.
Linear attention addresses this problem with a clever use of the kernel trick, a classical idea that dates back to the 1960s (Aizerman et al., 1964). You may know it from support vector machines (SVM) and kernel methods in general (Schölkopf, Smola, 2001; Shawe-Taylor, Cristianini, 2004; Hofmann et al., 2008), but you also may not, so let me begin with a brief explanation.
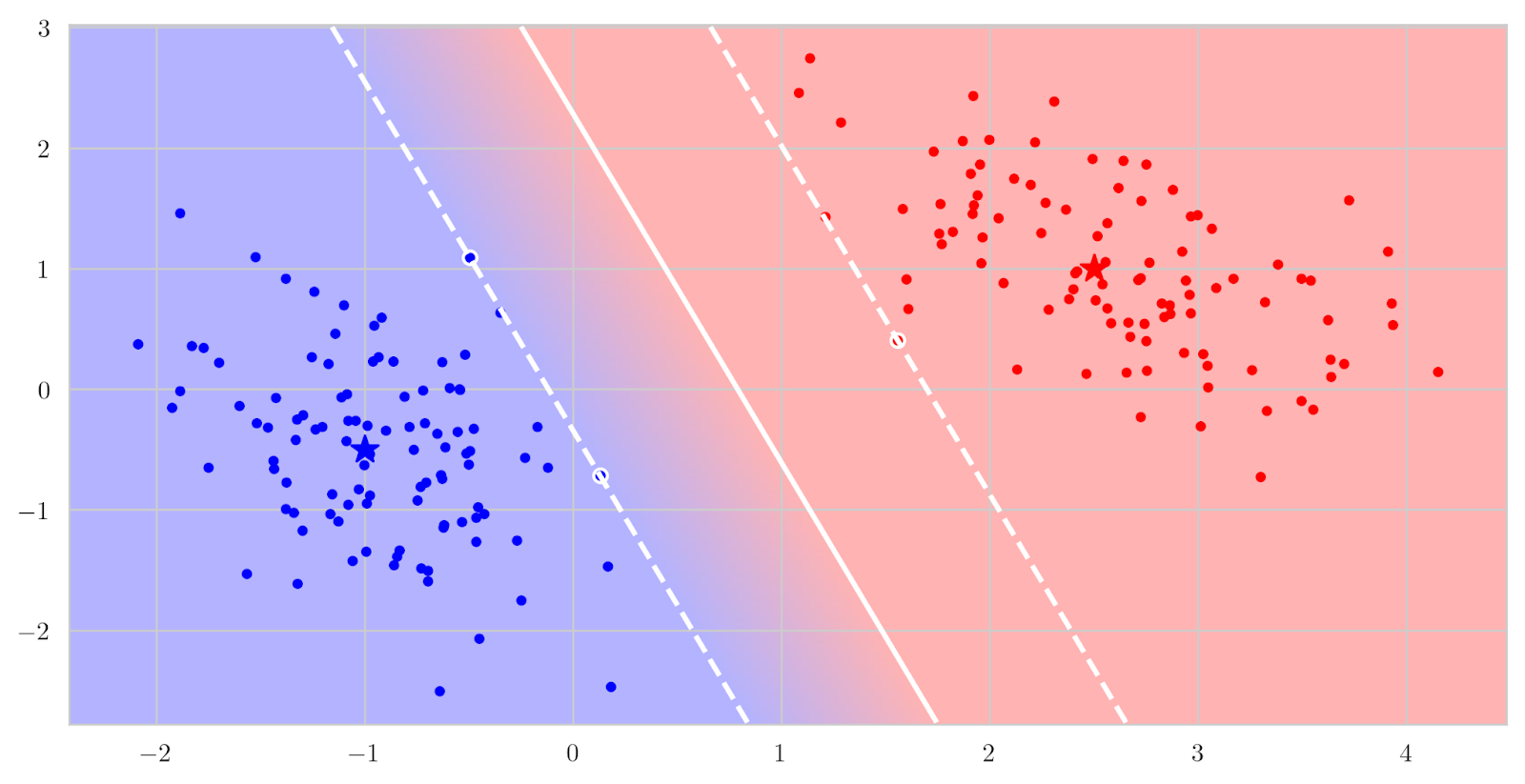
Suppose that you have a linear classifier, i.e., some great way to find a hyperplane that separates two (or more) sets of points, e.g., a support vector machine that finds the widest possible strip of empty space between two classes:
But in reality, it may happen that the classes are not linearly separable; for instance, what if the red points surround the blue points in a circle? In this case, there is no good linear decision surface, no hyperplane that works, and linear SVMs will fail too:
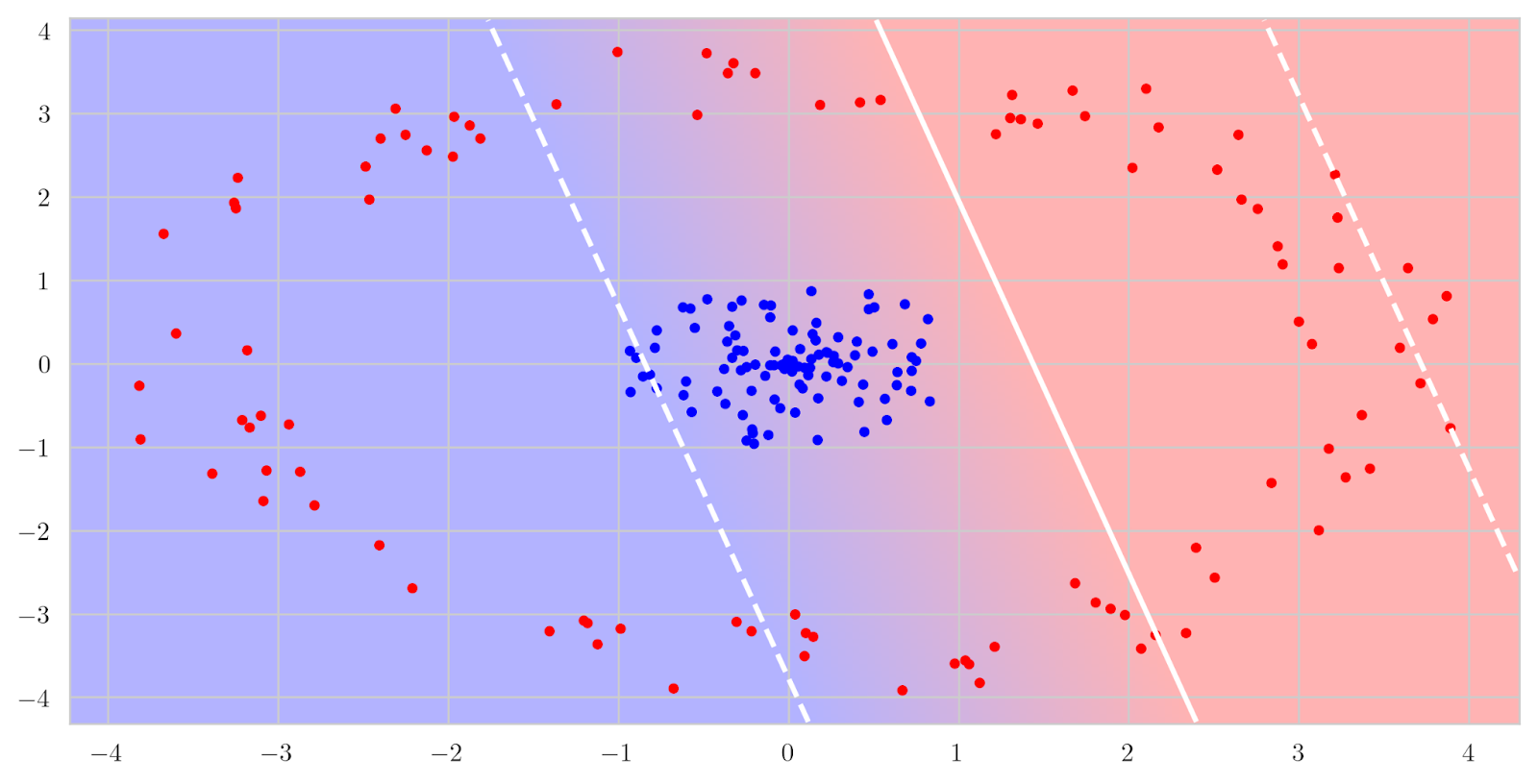
But it is also quite obvious what a good decision boundary would look like: it would be a quadratic surface. How can we fit a quadratic surface if we only have a linear classifier? Actually, conceptually it is quite easy: we extract quadratic features from the input vector and find the linear coefficients. In this case, if we need to separate two-dimensional points x = (x1, x2), a quadratic surface in the general case looks like
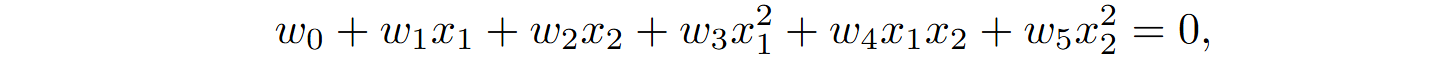
so we need to go from a two-dimensional vector to a five-dimensional one by extracting quadratic features:
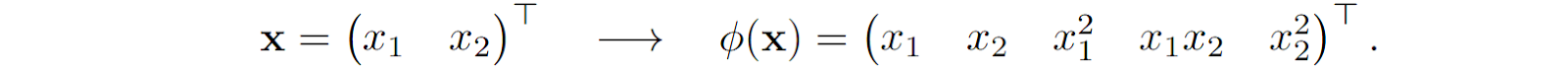
In the five-dimensional space, the same formula is now a linear surface, and we can use SVMs to find the best separating hyperplane in ℝ5 that will translate into the best separating quadratic surface in ℝ2:
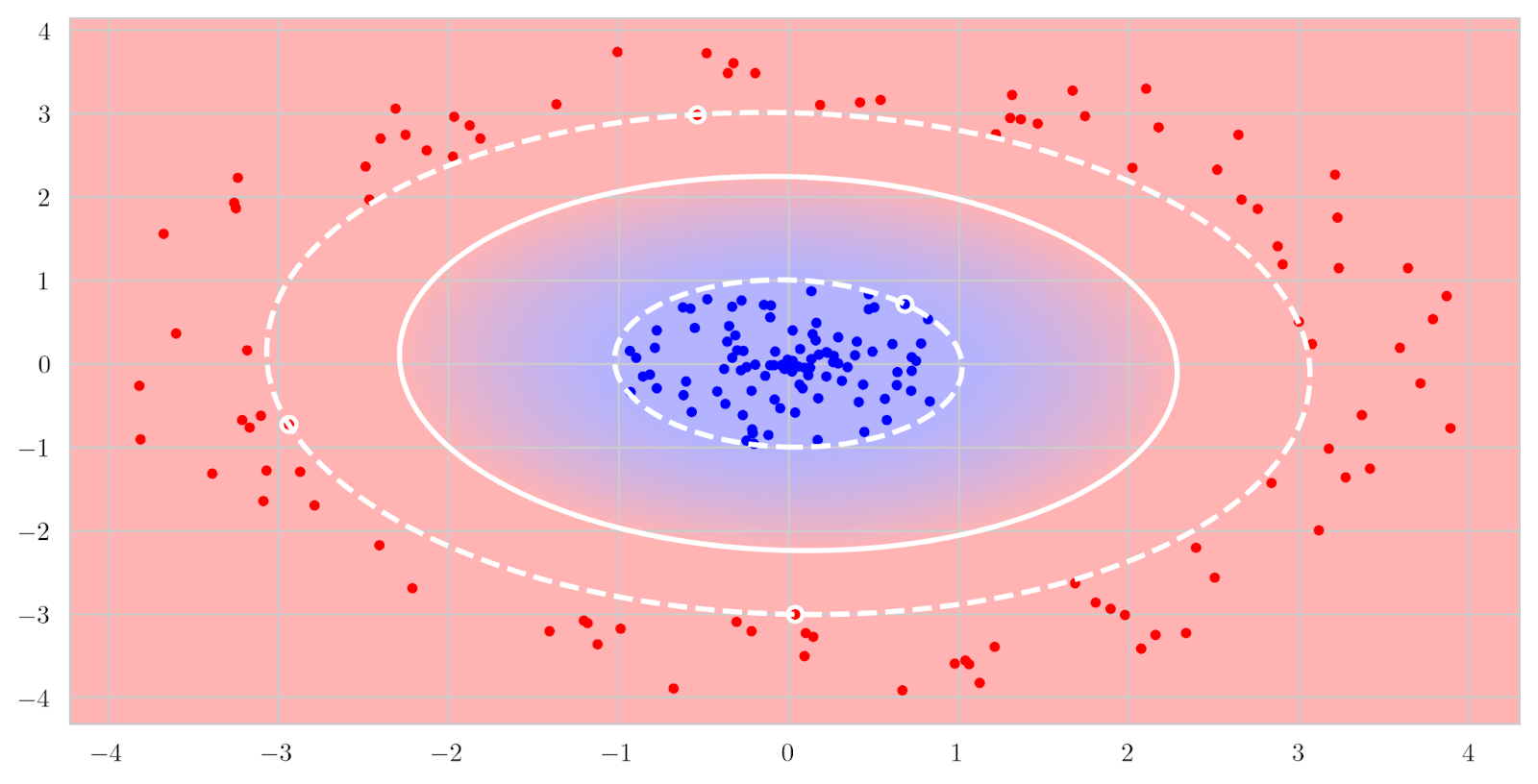
You can use any linear classifier here, and the only drawback is that we have had to move to a higher feature dimension. Unfortunately, this is a pretty severe problem: it may be okay to go from ℝ2 to ℝ5 but even if we only consider quadratic features as above it means that ℝd will turn into ℝd(d+1)/2, which is a much higher computational cost, and a higher degree polynomial will make things much worse.
This is where the kernel trick comes to the rescue: in SVMs and many other classifiers, you can rewrite the loss function in such a way that the only thing you have to be able to compute is the scalar product of two input vectors x and x’ (I will not go into the details of SVMs here, see, e.g., Cristianini, Shawe-Taylor, 2000). If this property holds, instead of directly going to the larger feature space we can look at what computing the scalar product means in that space and probably find a (nonlinear) function that will do the same thing in the smaller space. For quadratic features, if we change the feature extraction function to
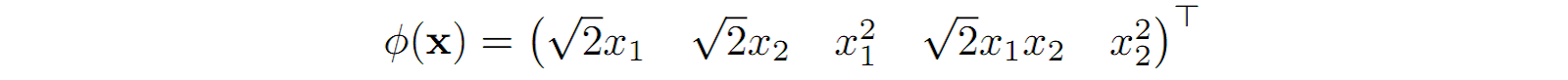
(this is a linear transformation that does not meaningfully change our classification task), we can rewrite the scalar product as
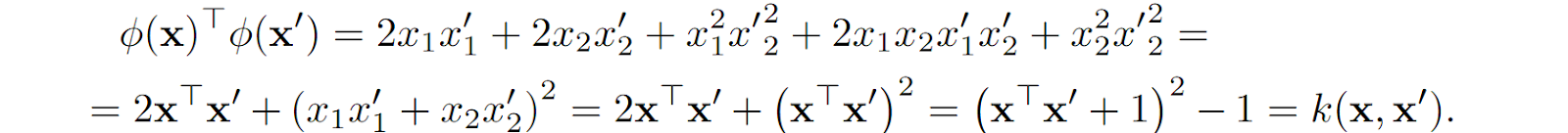
The result is called a kernel function k(x, x’), and we can now replace scalar products in the higher-dimensional space with nonlinear functions in the original space. And if your classifier depends only on the scalar products, the dimension of the feature space is not involved at all any longer; you can even go to infinite-dimensional functional spaces, or extract local features and have SVMs produce excellent decision surfaces that follow the data locally:
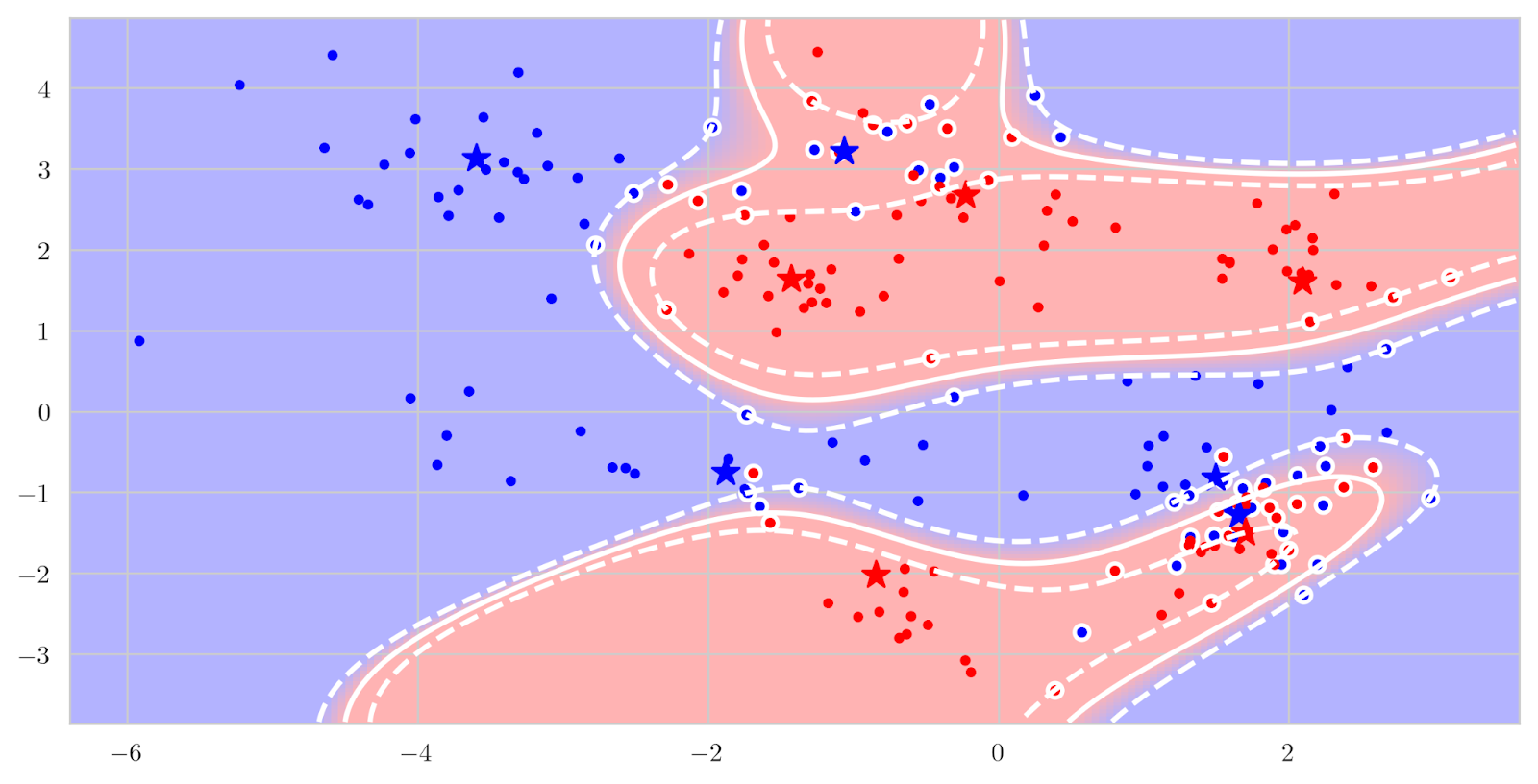
Well, linear attention is the same trick but in reverse: instead of using a nonlinear function to represent a high-dimensional dot product, let us use a feature extractor to approximate the nonlinear softmax kernel! We transform each key k and query q using a feature map ϕ, so that similarity between them can be computed as a dot product in feature space, ϕ(k)Tϕ(q); let us say that ϕ maps the query and key space ℝd to ℝn. So instead of computing each attention weight as the softmax
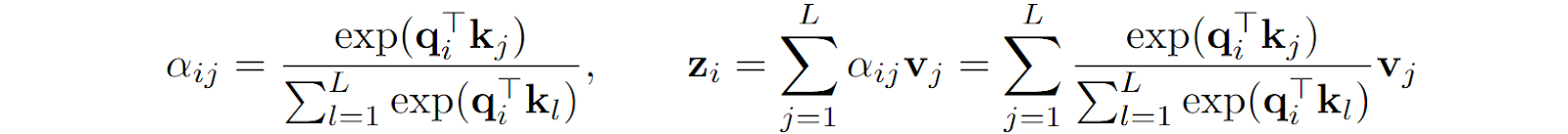
(I will omit the constant √d for simplicity; we can assume that it is incorporated into the query and key vectors), we use a feature map, also normalizing the result to a convex combination:
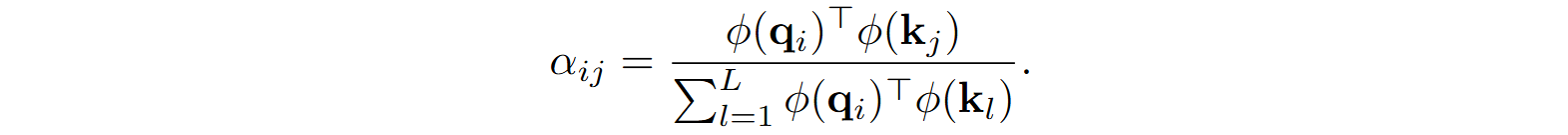
This is much more convenient computationally because now we can rearrange the terms in the overall formula for zi, and the quadratic complexity will disappear! Like this:
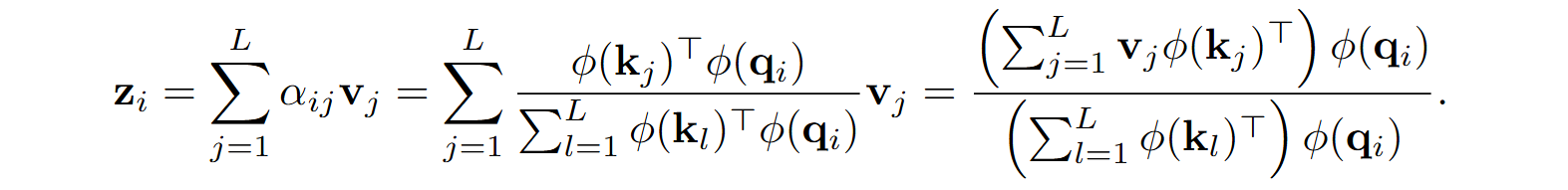
Now instead of computing the L⨉L matrix of attention weights we can first multiply ϕ(K) by V (getting the brackets in the numerator above), which is a multiplication of n⨉L and L⨉d’ matrices, and then reuse it for every query, multiplying the L⨉n matrix ϕ(Q) by the result:
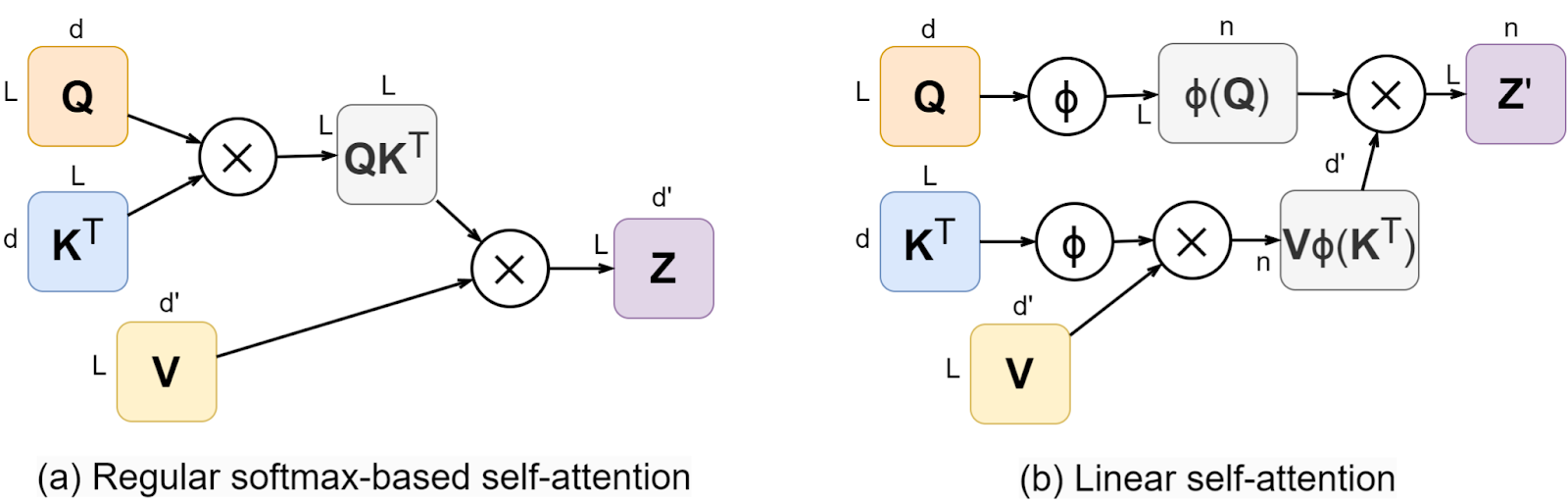
Note that the result has dimension n rather than d, and also note that I put Z’ as the output in the (b) part of the figure (on the top right) because it is only the numerator of the fraction above, but the denominator is also obviously not quadratic: we can first add up ϕ(kl) and then multiply by each query. Let us also simplify the formula above by denoting
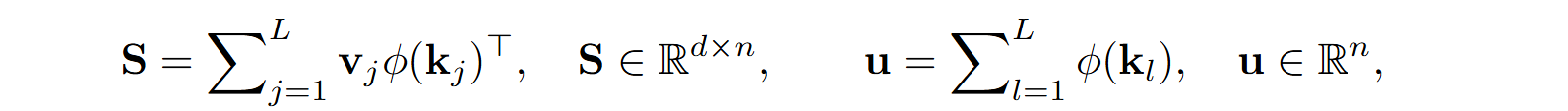
so we get a simple formula for linear attention as
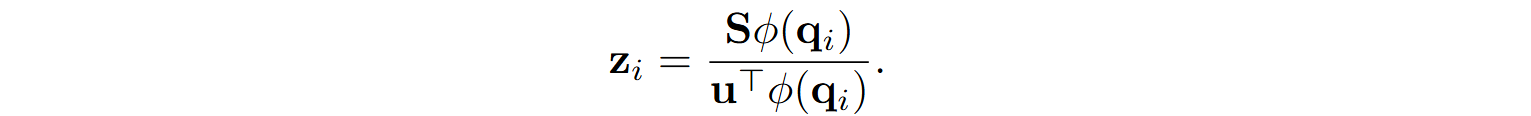
This is exactly the idea of linear attention as proposed by Katharopoulos et al. (2020). But there is one more important step.
We know that Transformers are often applied autoregressively. Any language model, e.g., from the GPT family (recall our post on Transformers), is an autoregressive model that applies self-attention to the same sequence gradually, step by step, and causally: an output at position t depends only on inputs in positions 1,…,t-1.
To train an autoregressive Transformer, you don’t have to rerun the whole model for every token, like you do for generation. Instead, autoregressive Transformers use causal self-attention, a special modification where the entire sequence is input at once, but the attention weights to future tokens are automatically set to zero. This means that we get the same self-attention formula but with sums only going up to the current t-th token:
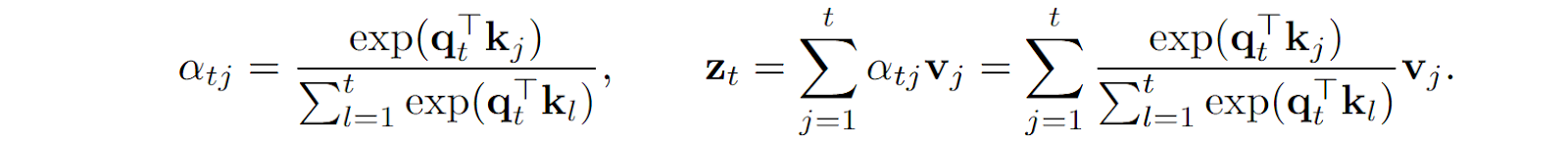
Passing to a scalar product with feature extractor ϕ as above, we get
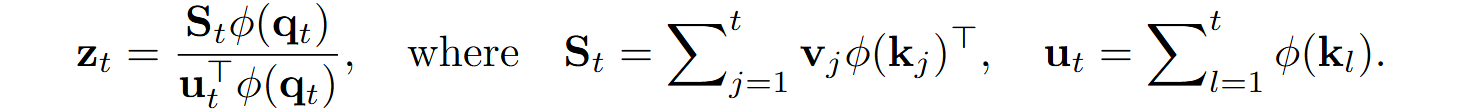
It is becoming more and more clear where this is going: since St and ut are just cumulative sums, we don’t have to recompute them from scratch on inference; instead, we can update them from previous values as
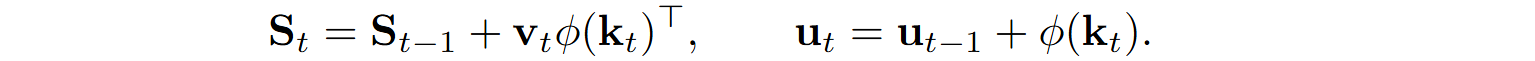
Katharopoulos et al. (2020) also show that the gradients can be computed incrementally from timestep to timestep; this is a straightforward calculation so I will not repeat it here. As a result, they come to the conclusion that their linear Transformer is… essentially a recurrent neural network (RNN)! This “RNN” has a hidden state that consists of two different components, a matrix state St and a normalizer state ut; we have derived the formulas for how to update this recurrence above, and we also know the formula for the output of this recurrent layer:
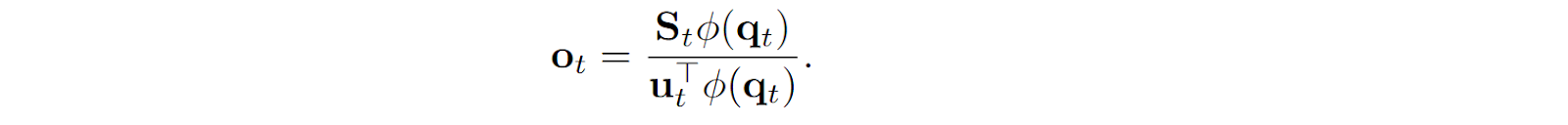
In practice, one often removes the normalizing denominator since it can lead to numerical instabilities (Schlag et al., 2021; Mao, 2022), and the feature extractor ϕ is commonly taken to be ϕ=id, so the formulas simplify to

But isn’t that a little too simple? Linear attention uses the kernel trick to approximate the softmax mechanism efficiently, enabling Transformers to handle longer sequences. However, this shift from quadratic to linear complexity raises questions about the fundamental role and meaning of attention: how should models store and retrieve relevant information efficiently? In the next section, we discuss associative memory, a classical concept in neural networks, which in this case turns out to be an important point of view on this question. In particular, it shares a similar goal of learning to store patterns and retrieving them based on input queries. By revisiting associative memory, we can better understand the underlying mechanisms of linear attention and their limitations.
We discuss several approaches in this section but mostly follow Schlag et al. (2021) who provide us with some key intuition about linear Transformers. They note that linear Transformers are almost entirely equivalent to an architecture called Fast Weight Programmers (FWPs), developed by Jurgen Schmidhuber (yes, this was his idea too!) in the early 1990s (Schmidhuber, 1992; 1993).
FWPs come from the basic intuition that the weights in standard neural networks remain fixed after training; activations change depending on the input, but the weights themselves are frozen. This is a bad thing for what is known as the binding problem (Greff et al., 2020): a neural network has no easy way to bind variables, define symbols, and thus construct compositional internal representations and perform symbolic reasoning that plays a key role in human cognition (Whitehead, 1927; Spelke, Kinzler, 2007; Johnson-Laird, 2010).
One possible solution for the binding problem would be to have two kinds of weights in a neural network: slow weights that are fixed after training as usual and fast weights that are context-dependent and can change on inference. As Greff et al. (2020) put it, “the slow net learns to program its fast net”. In an FWP (Schmidhuber, 1991; 1992), the slow network learns to adjust fast weights as follows: for a sequence of inputs xi, i=1,…,L,

where Wa and Wb are slow weights and Wi are fast weights. In essence, fast weights play the role of an RNN’s hidden state and the formulas above define the recurrence (Schmidhuber himself rephrased this idea in recurrent terms a year later, in 1993).But note the uncanny resemblance of this update rule and Transformer’s self-attention: Schmidhuber’s FWPs also make use of the outer produce abT to update the hidden state! FWPs create a short-term associative memory where keys are associated with values in a matrix form, the write operation is implemented by adding the outer product, and the readout is represented by matrix multiplication.
You can see how this resemblance becomes a formal equivalence when we move to linear attention: if we set the activation function σ above to identity, we get exactly the update rule and readout of simplified linear attention:
Normalization (the vector ut above) was absent from the FWPs of the 1990s but it also a straightforward idea in this formulation: whenever you have a “memory” that accumulated a big sum of values along the input sequence, it is natural to try and renormalize the sum to keep it at the same scale.
To make further improvements, Schlag et al. (2021) also go back to the original motivation for the whole thing: fit information into the hidden state matrix St. The relation to fast weight programmers also brings back the original goal of this transformation: we store vectors in the matrix S, and then retrieve this information via matrix multiplication. Let us discuss this in more detail.
The idea of storing information in this way is known as associative memory, a classical concept in artificial intelligence (see, e.g., Haykin, 2011) which is a natural generalization of, well, just storing things in memory:
Associative memory is another one of those ideas that were motivated by neurobiology and date back to early studies of the brain. In 1949, Donald Hebb introduced his famous learning principle, often summarized as “neurons that fire together, wire together” (Hebb, 1949); in other words, associations between neurons, reflected in synapse weights, grow stronger if neurons get activated at the same time. Unlike gradient descent, Hebbian learning is actually possible with biological neurons, and Hebb’s work in many ways remains relevant in neurobiology today (his theory also made provisions for, e.g., spike-timing-dependent plasticity that was not known in the 1940s).
It soon became clear that associative memory could be used as a kind of machine learning model. Early attempts at such models started in the 1950s (Taylor, 1956), but two ideas based on associative memory found wide success later:
Let us walk through an example of how associative memory works. We will work in 2D so that we can plot everything, so we begin with a 2×2 zero matrix A. Suppose that we want to store two vectors in that matrix,
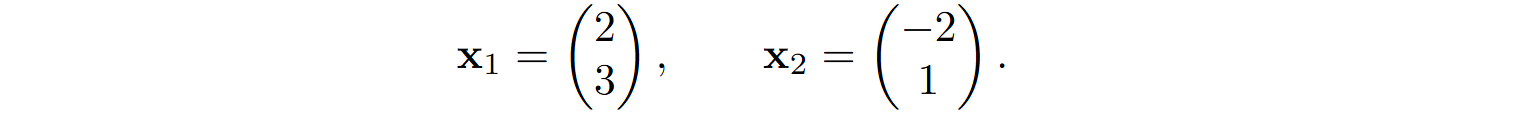
If we were just storing them in the matrix column by column, it would be equivalent to using keys aligned with coordinate axes:
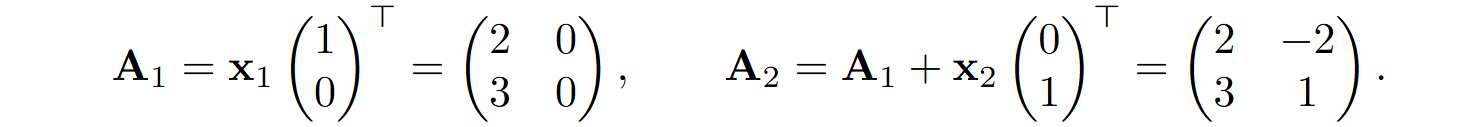
Reading from this memory is simply reading the columns, or, equivalently, multiplying by (1 0) and (0 1) key vectors. But we can take any other set of two orthogonal key vectors, say (let’s keep them at unit length to avoid renormalization):
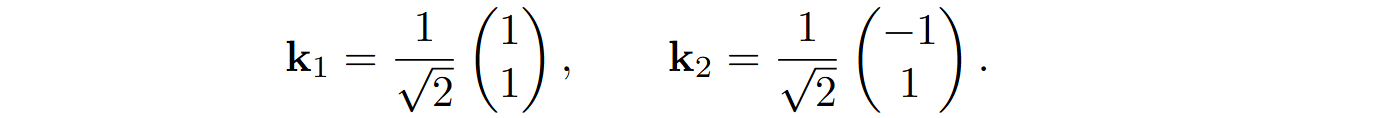
In this case, we get
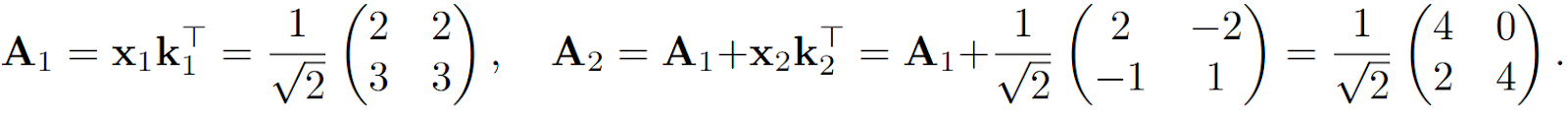
Reading from this matrix still works fine:
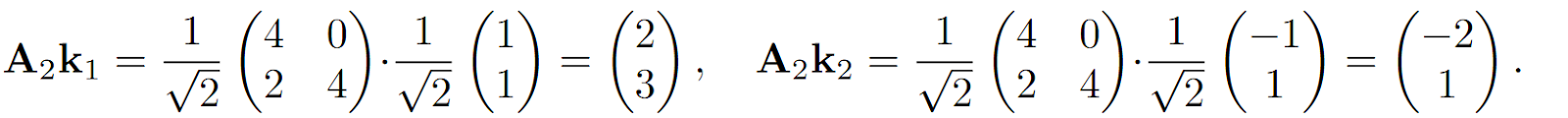
But if you try to add a third vector to the same associative memory with a third key, which is now inevitably non-orthogonal with the first two, say,
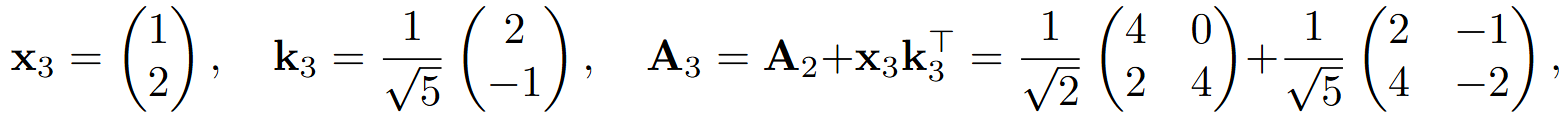
retrieval results will become corrupted, both for the original vectors and for the new vector x3:
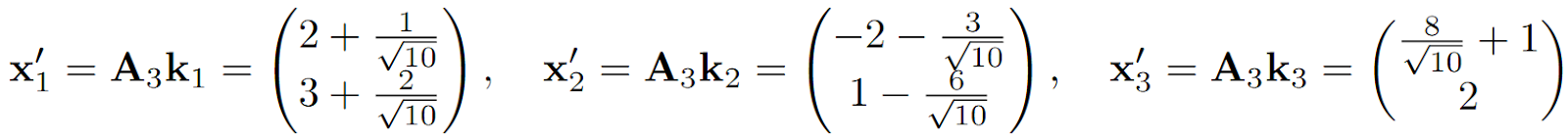
Geometrically this effect can be illustrated as below; we can find two orthogonal vectors for the first two keys (on the left in the figure) but the third one breaks perfect retrieval (retrieved vectors are shown with dashed lines on the right):
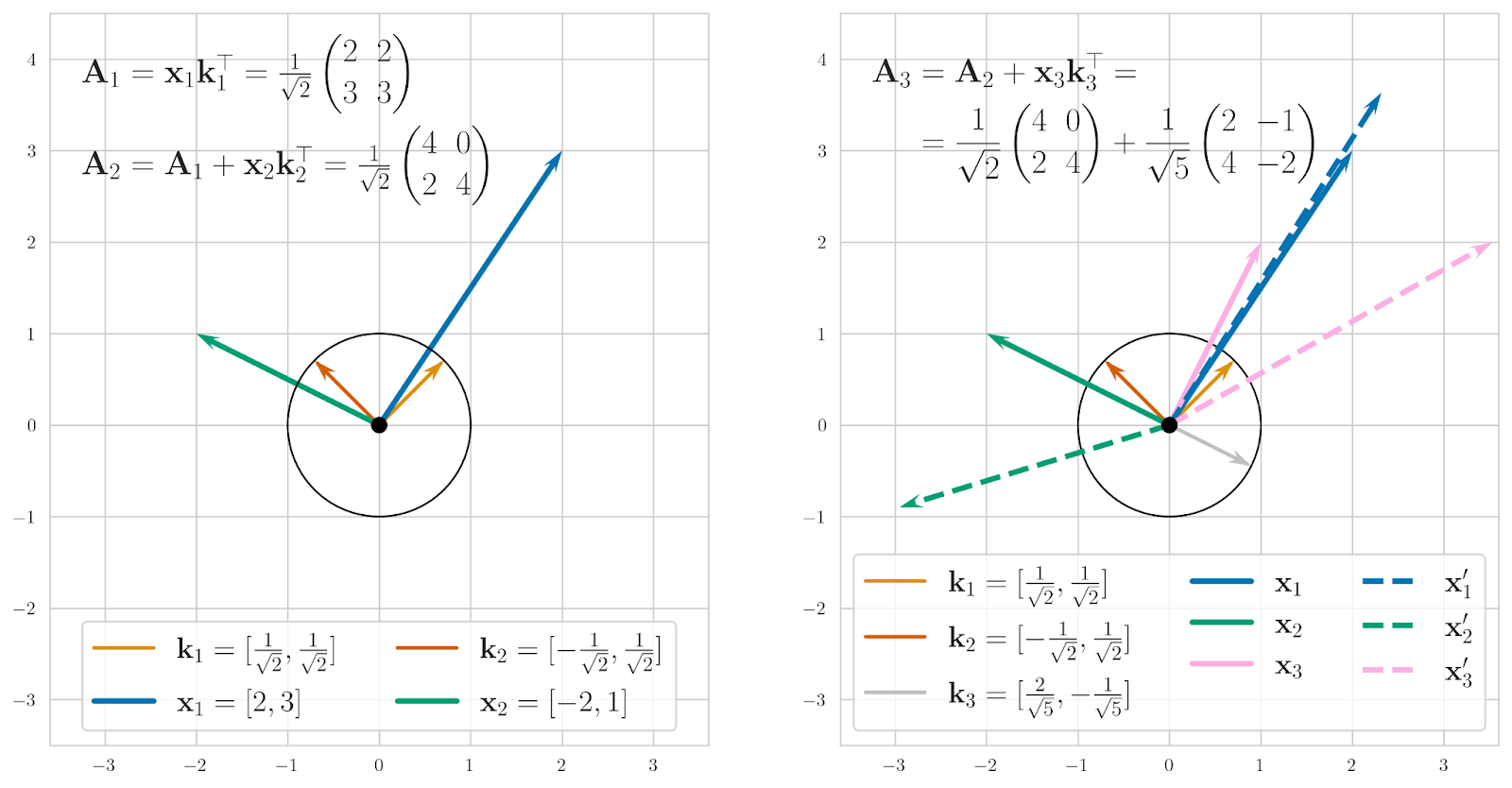
So far, it doesn’t sound like much of an improvement: we could just store vectors row by row and have the exact same number of them fit. The point of associative memory lies in its robustness to the orthogonality requirement: if the keys are nearly orthogonal you will retrieve vectors that are still quite similar to the originals, even if the keys are not orthogonal exactly. And this means that we can fit more keys than the matrix dimension, with imperfect but still reasonable recall!
This is hard to illustrate with a two-dimensional picture but in high dimensions you can use sparse keys that are all nearly orthogonal even though they intersect a little. For example, if d=100, and you use binary keys that all look like a vector with k=10 ones and 90 zeros (divided by √10, of course), two keys that have zero ones in common are perfectly orthogonal with zero dot product, but the keys that have only m=1 one in common have the dot product of 1/10, which may be sufficient for retrieval in practice.
Finding out how many such keys can exist for given d, k, and m is a well known problem from a completely separate field of study, called the theory of block designs, a part of the theory of error-correcting codes. This is essentially a coding question: how many codewords with at most a given intersection can you fit for a given dimension, given codeword weight (number of ones), and given intersection constraint? I will not go into error-correcting codes and refer to, e.g., (Assmus, Key, 1992; Huffman, Press, 2003), but the main relevant results here are the Hamming bound that is proven by counting and the more complicated Johnson bound. The Hamming bound says that without restrictions on the weight, for given d and m you can fit about
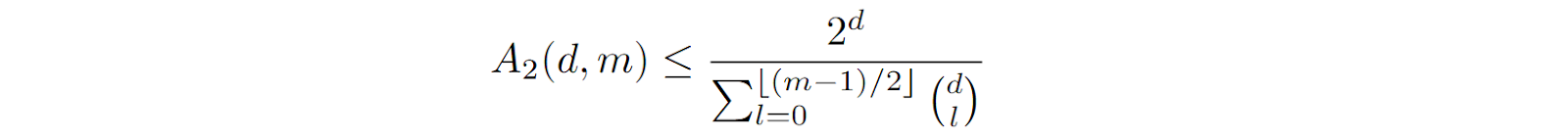
binary keys. We are interested in large values of m, where you can get a good approximation for the denominator via the entropy of the relative distance:
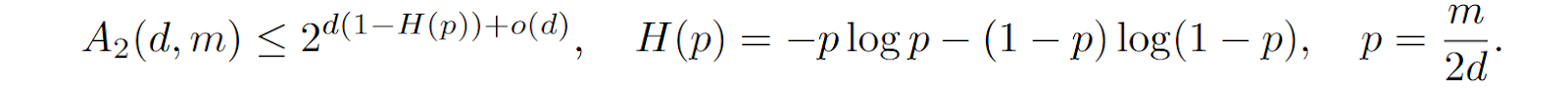
This means that even if you require small intersections, you can fit an exponential number of codewords, just with a smaller exponent. The Johnson bound deals with vectors of fixed weight, and we will not go there now, but the point stands: you can fit a lot of codewords with small intersections, asymptotically much more than d, and this gives us a way to store a lot of vectors in associative memory as long as we are okay with imperfect retrieval.
Now we have a much better intuition for what is going on in linear attention Transformers. But where will the improvements come from?
While linear Transformers are more efficient than classical self-attention and reduce its complexity from quadratic to linear, this efficiency comes at a cost. Linear attention approximations can struggle with tasks that require precise content-based reasoning or long-term memory, and further research is clearly needed.
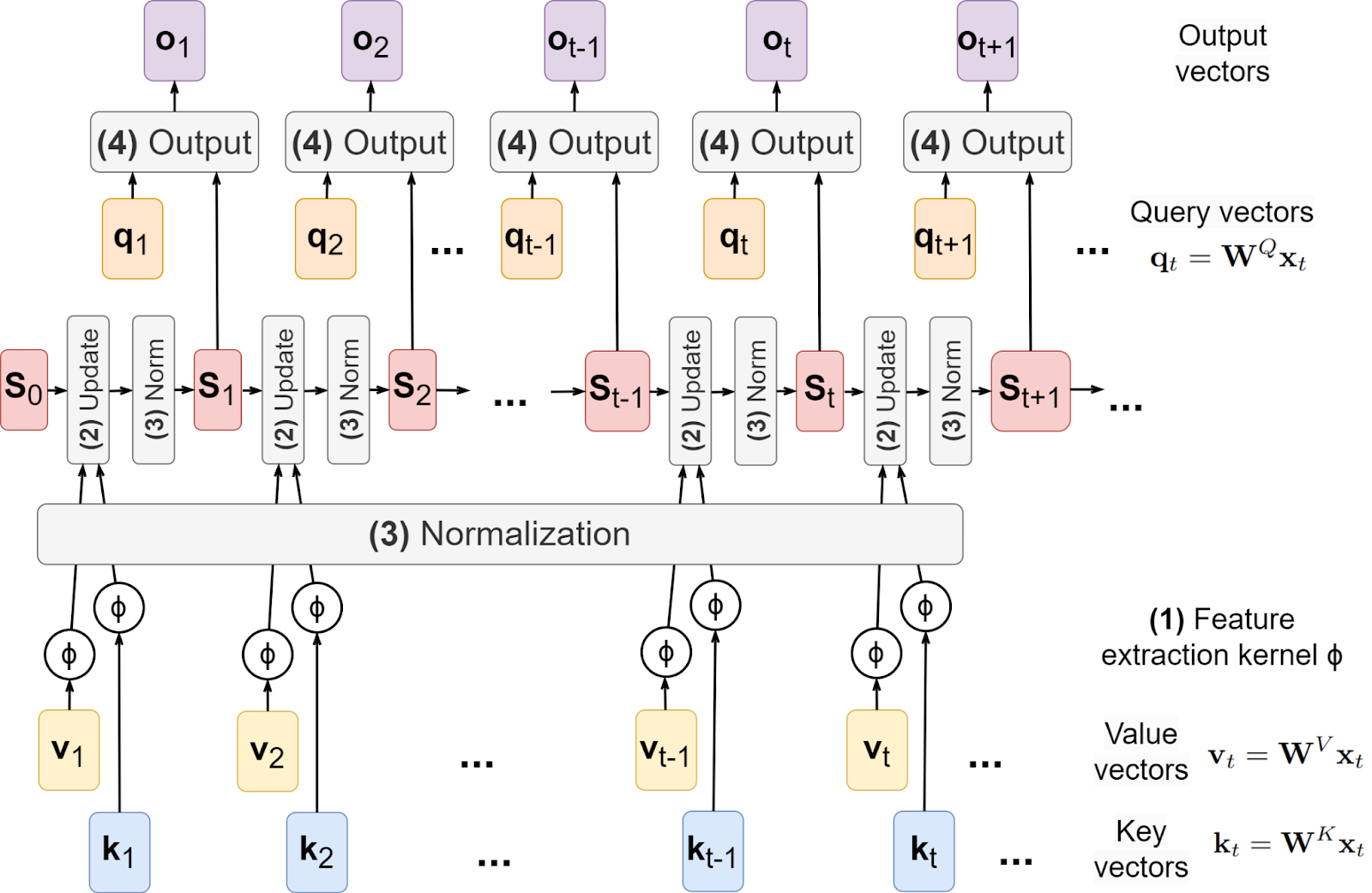
How can we improve upon the architecture above? We have already seen that the kernel ϕ can be different. But once you start thinking about updates to St as storing key-value pairs in memory, the update itself also becomes a promising point of possible new approaches: maybe summation is not the best way to store things in memory?
So at this point, we see that the linear self-attention structure breaks down into four decisions, each of which can suggest directions for improvement:
I have illustrated the general scheme below, showing where these different items go in the architecture. Let us now consider these directions one by one.
First, for the nonlinear transformation ϕ Katharopoulos et al. (2020) suggested to use either the identity function or the exponential linear unit ELU, a variation of ReLU with nonzero derivative everywhere (plus one to make ϕ(a) nonnegative):
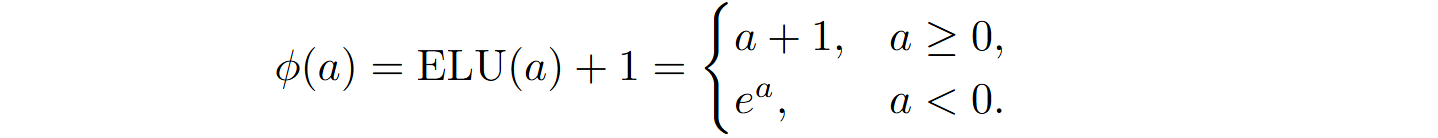
Here ϕ is basically an activation function, operating independently on every component of k and v. However, in the previous section we motivated the function ϕ as an approximation to the numerator of softmax, i.e., we would ideally want
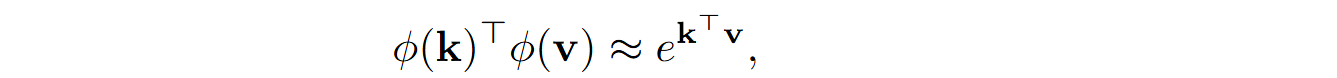
which is definitely not the case for ELU+1.
The Performer architecture (Choromanski et al., 2021) introduced a version of ϕ which is a much better approximation for softmax. They provide a detailed proof that we will not reproduce here, but in essence their approach, called FAVOR+ for Fast Attention Via positive Orthogonal Random features, uses random linear transformations in such a way that the expected result is indeed the softmax kernel shown above: they define
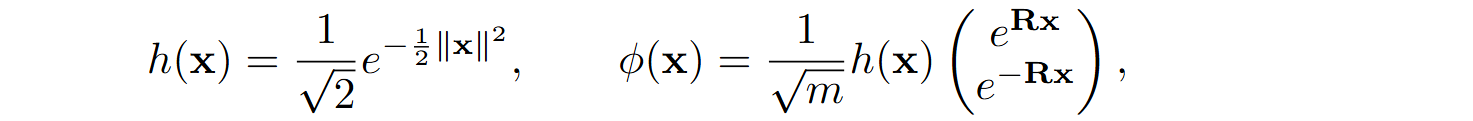
where R is an m⨉d random matrix whose every row is drawn from the standard Gaussian in dimension d, and prove that the expectation of ϕ(k)Tϕ(q) coincides with the softmax kernel exp(kTq), and that
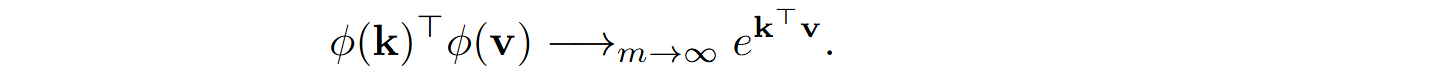
Schlag et al. (2021) introduce the so-called deterministic parameter-free projection (DPFP), an approach where components of ϕ are constructed to be orthogonal by design: if ϕj(x)>0 then ϕi(x)=0 for all i other than j. This can be achieved with ReLU activations if you just design them so that their nonnegative areas do not overlap. For example, ϕ can map ℝ2 to ℝ4 as follows:
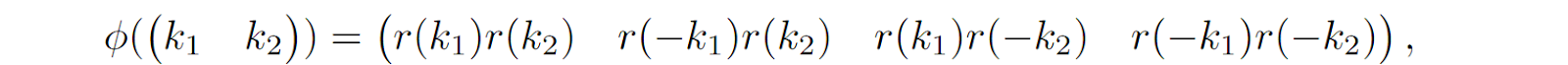
where r(a)=max(0, a) is the ReLU activation function. Note how regardless of the input vector k all components of ϕ(k) except one are zero because either r(a) or r(-a) is always zero. The authors generalize this approach to higher dimensions as well; note that ReLUs are also very computationally efficient, much more so than computing exponents.
Second, let’s turn to the memory update rule. As the number of vectors stored in associative memory increases over the matrix dimension d, the memory mechanism should ideally figure out which vectors to “overwrite”. This is especially important because in practice, you may get a new key-value pair that is similar to an already existing key that points to an already similar value, in which case you don’t really want to overwrite anything at all but rather update the value a little so that both keys will retrieve a good enough approximation of it.
Schlag et al. (2021) propose the following approach here: for a new key-value pair (k, v), retrieve v’ that is already stored in memory by the key k (you can always do retrieval in associative memory, if we are not yet at memory capacity it will just return zero) and store a convex combination of v’ and v. The coefficient of this combination, the “overwrite force” for this vector, can also be derived from the inputs. Formally, we define
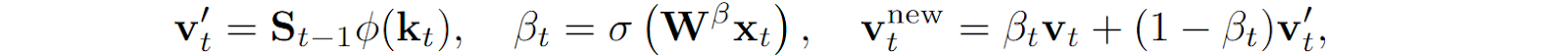
and then in the matrix state computation we erase v’ from memory and write in vnew, getting
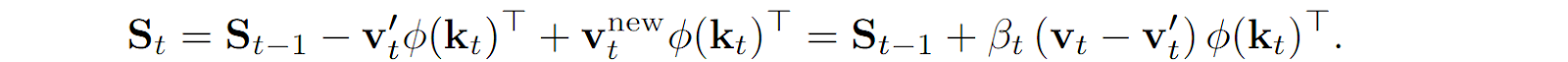
Third, for normalization you can use attention normalization as suggested by Katharopoulos et al. (2020) or, for instance, sum normalization where query and key vectors are divided by the sums of their own components. Normalization can be done only at the level of queries, keys, and values, or also at the output ot, and so on, and so forth.
The possibilities are endless, and indeed, one can think of a lot of different modifications for the above formulas. Some of them explore different feature functions, others change how combinations and moving averages are computed, yet others add various gates to the architecture up to the complexity of an entire LSTM (Peng et al., 2021; Beck et al., 2024). The summary table below is taken from a recent work by Yang et al. (2024), which in turn proposes yet another approach in this vein:

Naturally, I don’t want to go over the entire table here; we are already acquainted with several rows in this table enough that you can mostly understand the motivation behind the others. But there is one more important direction that leads to interesting new ideas and that has been growing in popularity lately, so I want to explore it in more detail.
While linear attention provides a scalable alternative to Transformer’s self-attention, it still struggles with tasks requiring explicit reasoning over long-term dependencies or fine-grained temporal dynamics. In this section, we discuss state space models that provide an alternative perspective: instead of focusing on approximating attention, they model sequences as evolving states governed by differential equations. This still allows the system to handle long-range dependencies while at the same time learning structured dynamics inspired by control theory.
To explain what is going on in Mamba, we need to take a step back yet again, this time to state space models. A state space model (SSM) is another way to process sequential input, very similar to RNNs in that an SSM also has a hidden state ht that is supposed to capture all relevant information about the current state of the system. But the state space model looks at system evolution from a continuous standpoint, considering the dynamical system

Here is an illustration:
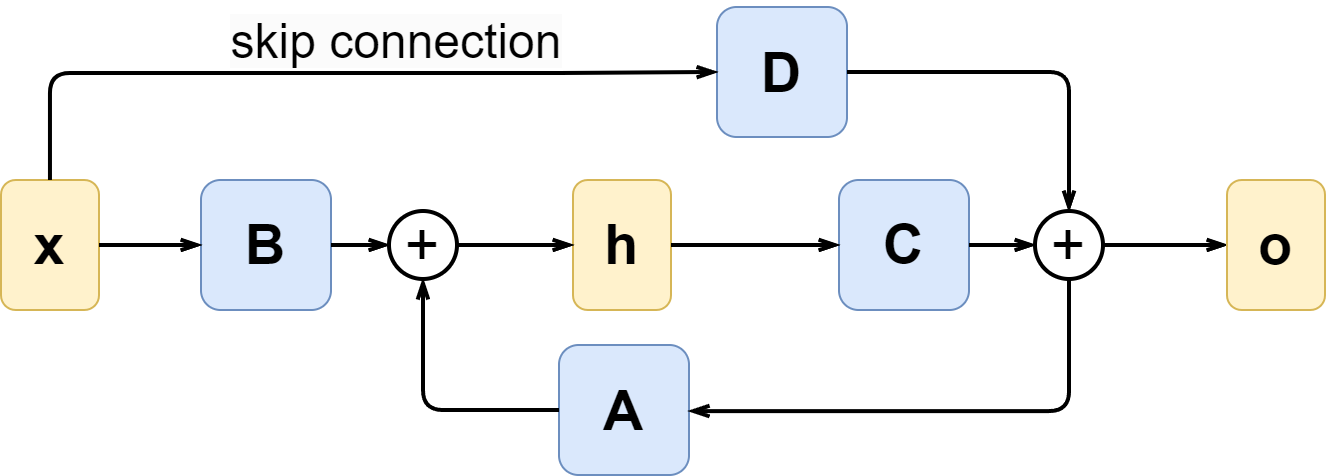
Note that the direct dependence of the output o(t) on the input x(t) can be thought of as a skip connection going around the dynamical system, so below we will assume that D=0.
This approach has its roots in control theory; the famous Kalman filter (Kalman, 1960) is a special case of SSMs, and classical control theory has a lot of results on such linear dynamical systems (Jazwinski, 1970; Kailath, 1980), spilling over into econometrics and generally time series analysis (Hamilton, 1994).
The equations above look just like a classical RNN; the main difference is that they are continuous, so we can hardly expect to be able to work with them unless we can discretize continuous signals and vice versa, turn discrete inputs (such as text) into continuous signals. In this approach, it is usually enough to consider the zero-hold model, where a discrete input is turned into a set of step functions with step size Δ, and a continuous signal is sampled according to the input timesteps. Discretization of dynamical systems proceeds via matrix exponentials that result from solving the differential equations above on an interval [t, t+Δt] where the input x(t) can be assumed constant, so the solution is
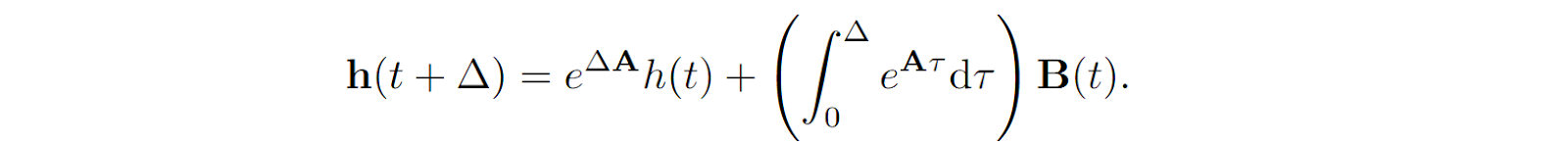
As a result, we can define discretized versions of the matrices A and B (see, e.g., Grootendorst, 2024 for a more detailed explanation) as
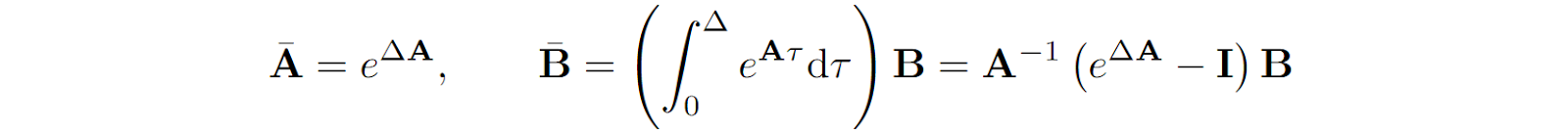
and treat this discretized version of an SSM as a linear RNN with update rule (omitting D as discussed above)
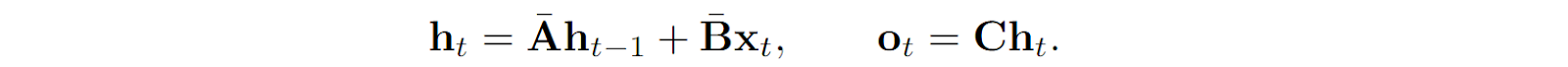
Note that this is not the only way to do discretization, for example, Gu et al., 2022 use a bilinear method where
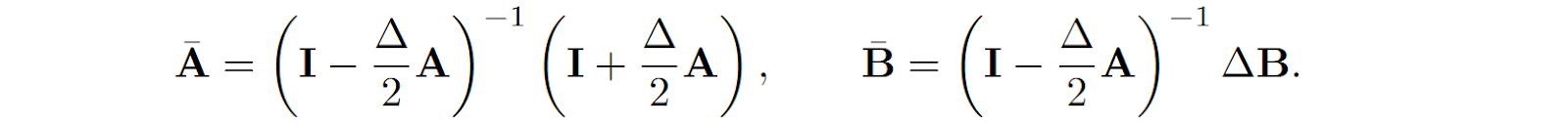
Moreover, doing everything via discretizations of continuous functions has other advantages; for example, we can seamlessly handle missing data by simply continuing the discretization over a longer time period (where we do not have new data).
Finally, we can also note that in this formulation, every output ot can be easily represented as a series depending on the inputs xi:
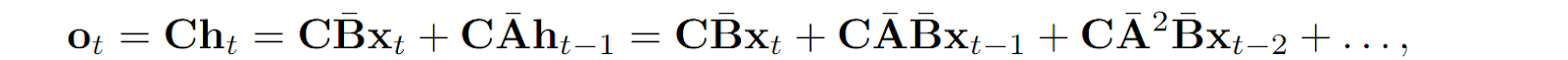
which can be thought of as a convolution operator: to get ot, we convolve the input series with the kernel
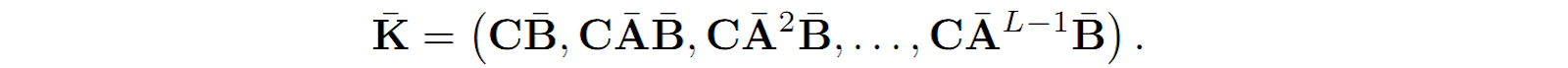
K is called the SSM convolution kernel, and if it is known, the SSM can be very efficiently computed in parallel during training, when we have the entire input sequence xt available, just like any autoregressive model. Computing K, however, is a nontrivial task that also requires new tricks.
But whatever the discretization formulas, the resulting RNN will not really work as intended. This is a classical approach that has been well-known for decades, and, of course, people have tried to apply it to machine learning. But they had always found this approach to lack long-term memory because of vanishing and/or exploding gradients due to all of this matrix multiplication, which is precisely the point of having a recurrent network in the first place.
To add long-term memory, we need one more technique developed by Gu et al. (2020): we need to replace the matrix A with the so-called “HiPPO matrix”, where HiPPO stands for high-order polynomial projection operators. The HiPPO approach begins with a different question: how do we compress the entire history of an input function f, namely f≤t=f(x)|x≤t, into a functional representation? The core idea is to approximate the function f≤t of by projecting it onto a space spanned by orthogonal polynomials. With this approach, HiPPO can handle long-range dependencies without needing explicit priors on the timescale, which is crucial for data with unknown or variable temporal scales.
Without going into too much mathematical details (for those, see the original paper), HiPPO operates as follows: for a function f where we are interested in operating on its current history f≤t=f(x)|x≤t,
Here is an illustration from the original paper that shows this sequence of steps:
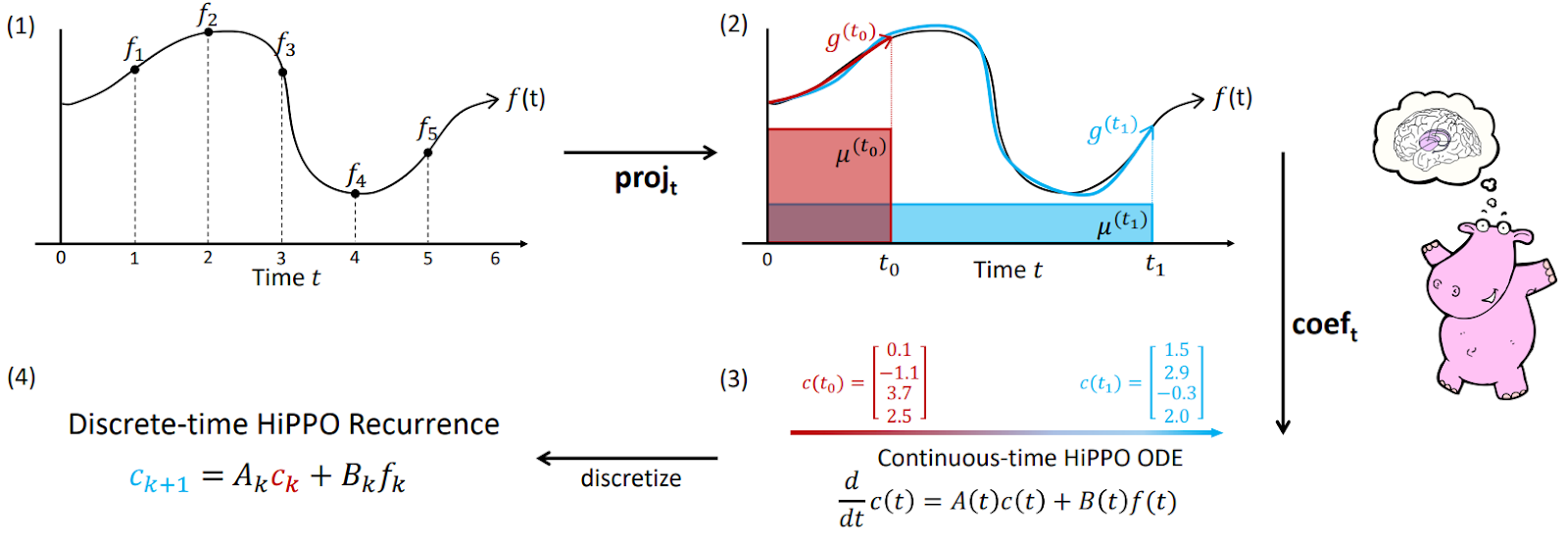
Gu et al. (2020) derive specific formulas for the HiPPO matrices. For their scaled Legendre measure (HiPPO-LegS) the matrix dynamics are
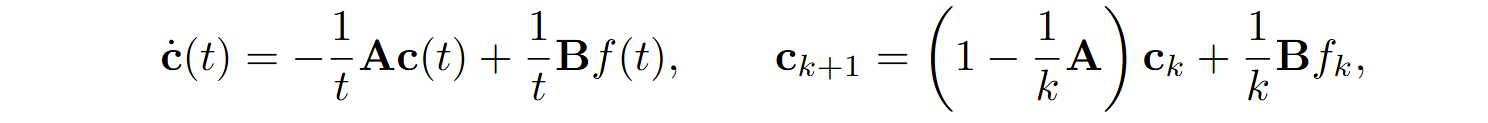
where A and B are constant:
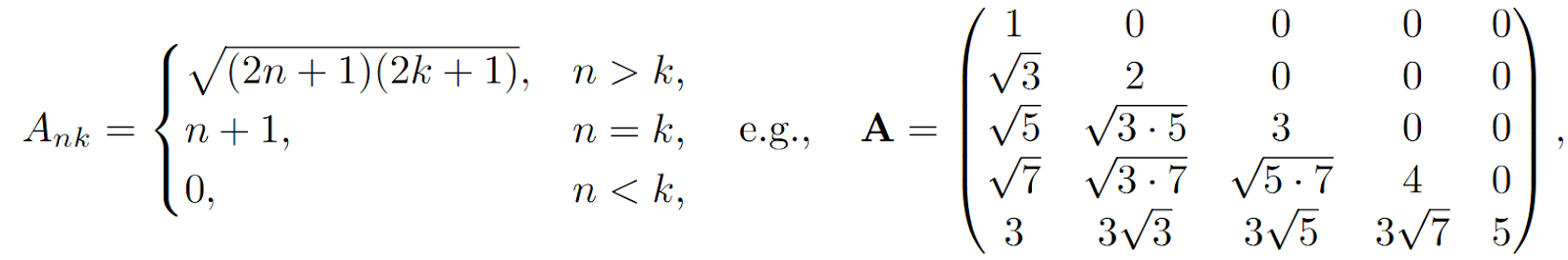
and Bn=(2n+1)1/2.
That was quite a lot of math that’s very different from what we are used to here—but bear with me, we are back to machine learning territory. At this point, we have a method that can take a time series as input and produce a good vector representation for its entire history; moreover, the method reduces to using a couple of matrices whose coefficients can be updated recursively with time too. This means that we can, for example, plug HiPPO into a regular RNN, adding another state ct and replacing the hidden state ht with a representation of its entire history; this has been done in the original paper on HiPPO as follows, for an arbitrary RNN update:
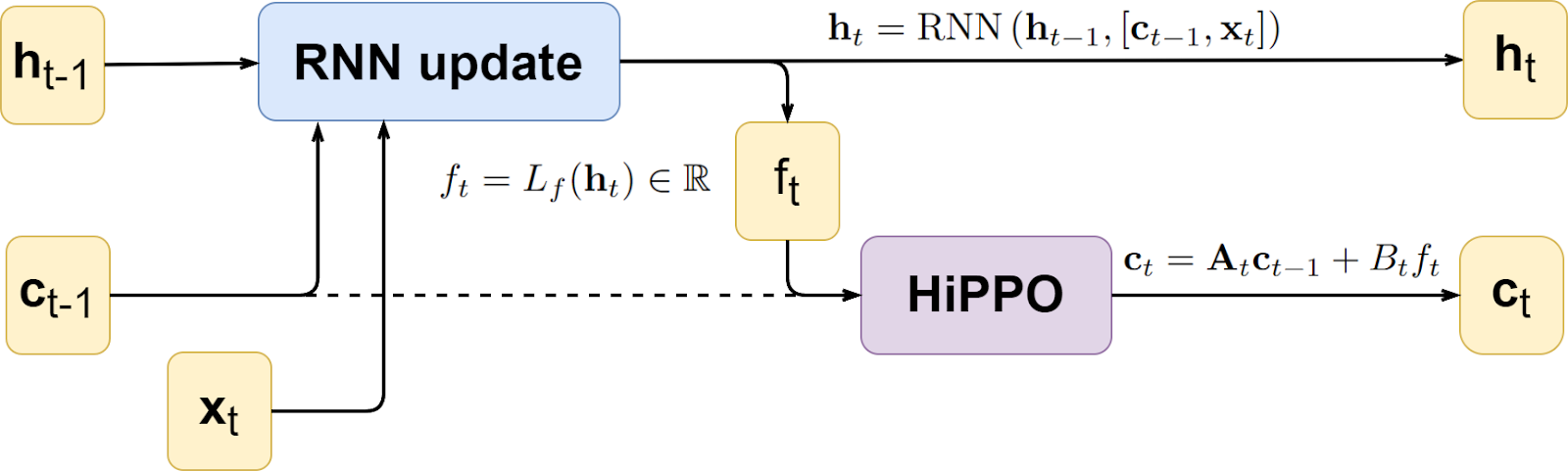
In SSMs, the HiPPO matrix is used to initialize the transition matrix A, significantly alleviating the problem of long-range dependencies. It may sound a little strange because as soon as we begin updating the weights, the matrix A loses its HiPPO properties: it no longer corresponds to the Legendre or Laguerre polynomials, or to any orthogonal basis in the functional space at all. However, experiments show that this initialization does help a lot with implementing long-term memory.
The second problem we need to solve is computational complexity: so far, SSMs require repeated multiplication by the discretized version of A, so the naive complexity is O(d2L), where d is the input vector dimension and L is the sequence length. The main contribution of the S4 model (structured state space sequence model) introduced by Gu et al. (2022) is a much faster way to compute all views of the SSM model, i.e., both recurrent matrices used at inference and convolutions used at training. The ideas of S4 would be way too mathy to put in this post; fortunately, I can refer to “The Annotated S4”, a detailed post by the S4 authors that shows all derivations and also provides the corresponding PyTorch code and illustrations. For now, let us just assume that all of the above can be done efficiently.
The next step was taken by Smith et al. (2022) who moved from single-input, single-output SSM layers to multi-input, multi-output layers, allowing xt and ot to become vectors; their model is known as S5 (simplified structured state space for sequence modeling).
With this, we finally come to Mamba (Gu, Dao, 2024), also known as S6 (S4 + selective scan). The main step forward in Mamba is recognizing that so far, the model dynamics have had to be constant: matrices A, B, C, and step size Δ can be trainable from mini-batch to mini-batch but they cannot depend on the input xt; otherwise, we wouldn’t be able to implement the convolutional kernel K which is key to efficient training. This significantly limits the expressive power of S4: its mechanism cannot do content-aware reasoning, it cannot choose which parts of xt are more important and filter out the rest, and so on.
Gu and Dao (2024) introduce the selective scan algorithm that lets B, C, and Δ (not A, though) depend on xt while still providing an efficient algorithm for training. In essence, they find a middle ground between the two extremes:
Again, the technical details of the algorithm are too involved for this post—it even makes use of hardware optimization, being specifically tailored for GPUs and TPUs. But the result is the Mamba block that can be stacked in a neural network. It includes the following selective state space model as a replacement for the attention mechanism:
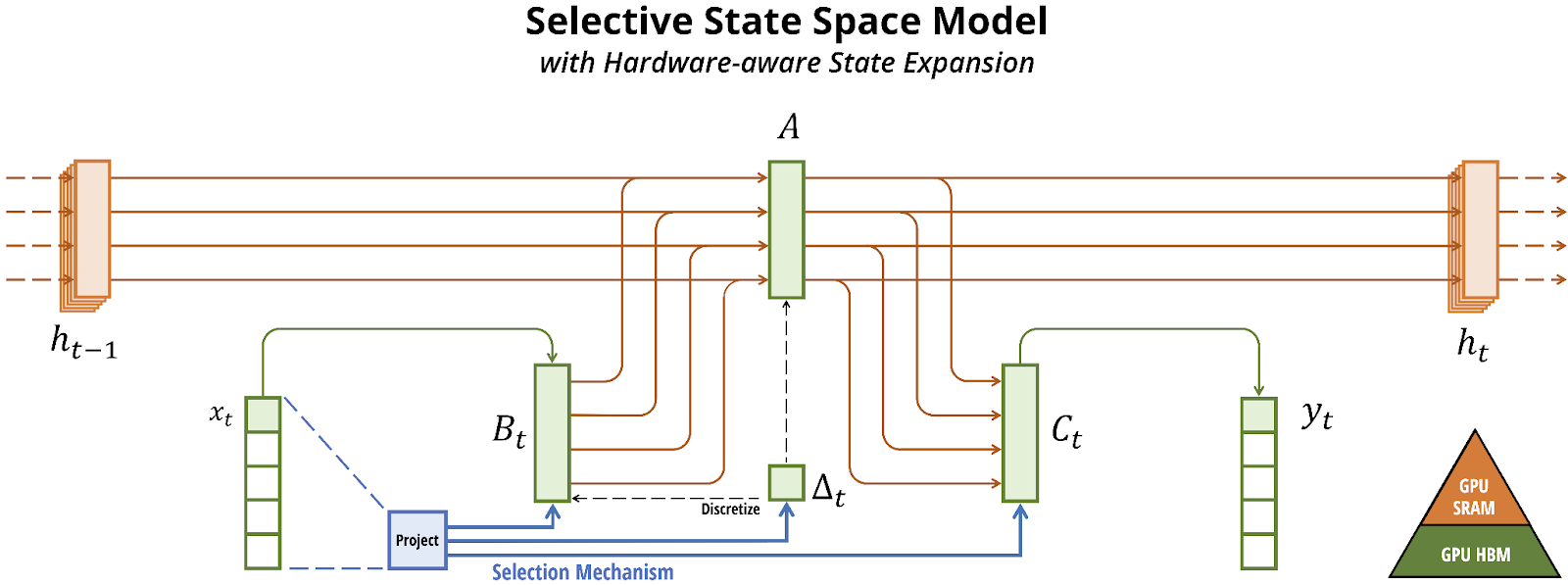
Mamba was big news. A viable alternative to Transformers that even outperformed existing open source language models with an equivalent number of parameters. So it is no wonder that researchers picked up this idea and ran with it, with a lot of papers already extending and improving upon the basic Mamba architecture.
For example (I’m only listing some of the most interesting ones):
As you can see, the ideas of Mamba have been actively developed by the deep learning community over the last year… actually, no, you don’t see the full extent of it yet. I introduced a hidden constraint here: the original Mamba paper was first published in December 2023, and all the papers cited in the list above are from January 2024! In only a month, Mamba already became a staple of deep learning, and by now, a survey by Qu et al. (2024, last revised in mid-October) has 244 citations—not all of them are Mamba-based models, of course, but it looks like over a hundred, if not more, are Mamba variations published in 2024.
This is the crazy research landscape we are living in now, and, of course, I cannot give a full survey here, so I will only highlight a direct continuation: Mamba 2 (Dao, Gu, 2024), developed by the authors of the original, dives further into the Mamba algorithm and makes it even more efficient with its state space duality (SSD) framework. It very much looks like Mamba-based models are reliably beating Transformers in many long-context tasks, combining the efficiency of linear attention with the structured adaptability of SSMs.
Linear attention and state space models like Mamba represent a new wave of more efficient models that alleviate the quadratic complexity problem of basic self-attention. These models revisit foundational ideas from RNNs and associative memory but also redefine how we think about integrating memory and content-aware reasoning into neural architectures. They are already pushing the boundaries of scalable and content-aware sequence modeling, and this research direction is far from completely explored.
In this post, we have discussed the basic ideas of linear attention; I have tried to explain the foundations of these models—the kernel trick, associative memory, state space models—that date back a long time. This is another case where recent results can be placed in the context of a machine learning timeline that dates back many decades; here is my take on the timeline of the main ideas we mentioned today:

Once these ideas get picked up in a new form, such as Mamba, progress starts anew, and these days it proceeds at a breakneck pace. I hope that this post gives a clear understanding that this is still very much a work in progress, and new results will probably augment these ideas in the nearest future. Existing results already suggest many exciting applications: not only improved language modeling but also applications to genomics, image processing, audio processing, and more have already been explored in Mamba-like models.
Moreover, we can already look ahead a little. State space models, kernel-based attention, and hardware-aware optimizations in Mamba hint at a future where memory-intensive applications such as long-context language modeling and large-scale genomic analysis are not only feasible but practical. In this future, neural networks may be able to dynamically tailor their computation to the input; perhaps we are witnessing the birth of a new paradigm for sequence modeling.
As research in Mamba and its successors continues, we are also likely to see further breakthroughs in one of the most important issues that still remains to be solved: how can neural networks manage and process memory? In my opinion, memory is still an unresolved challenge; increasing the context size is not the same as having a working memory, but the selective state space models developed in Mamba actually come much closer. I am very excited to see what the next step will be.
Sergey Nikolenko
Head of AI, Synthesis AI
