
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Today, we continue our discussion of generative AI, a direction that keeps transforming many different industries. Last time, we reviewed the difference between continuous and discrete latent spaces, and how the VQ-VAE architecture (based on variational autoencoders that we discussed before) manages to learn a discrete latent space, a codebook that Today, we will put this idea into further practice with our first real text-to-image model, OpenAI’s DALL-E.

In previous posts, we have discussed the main ideas that, taken together, have led to OpenAI’s DALL-E, the first text-image model that actually impressed everyone not only in the AI community but in the wider world. DALL-E put image generation by text prompts on the map of the world’s media, and I would say that the current hype wave of generative AI models for images started in earnest with DALL-E (although current models are, of course, much better than the original DALL-E). But what is it, exactly, and how does it work?
Let us begin with the general structure of DALL-E. We almost know all of the components from previous posts, so we can start with the big picture:
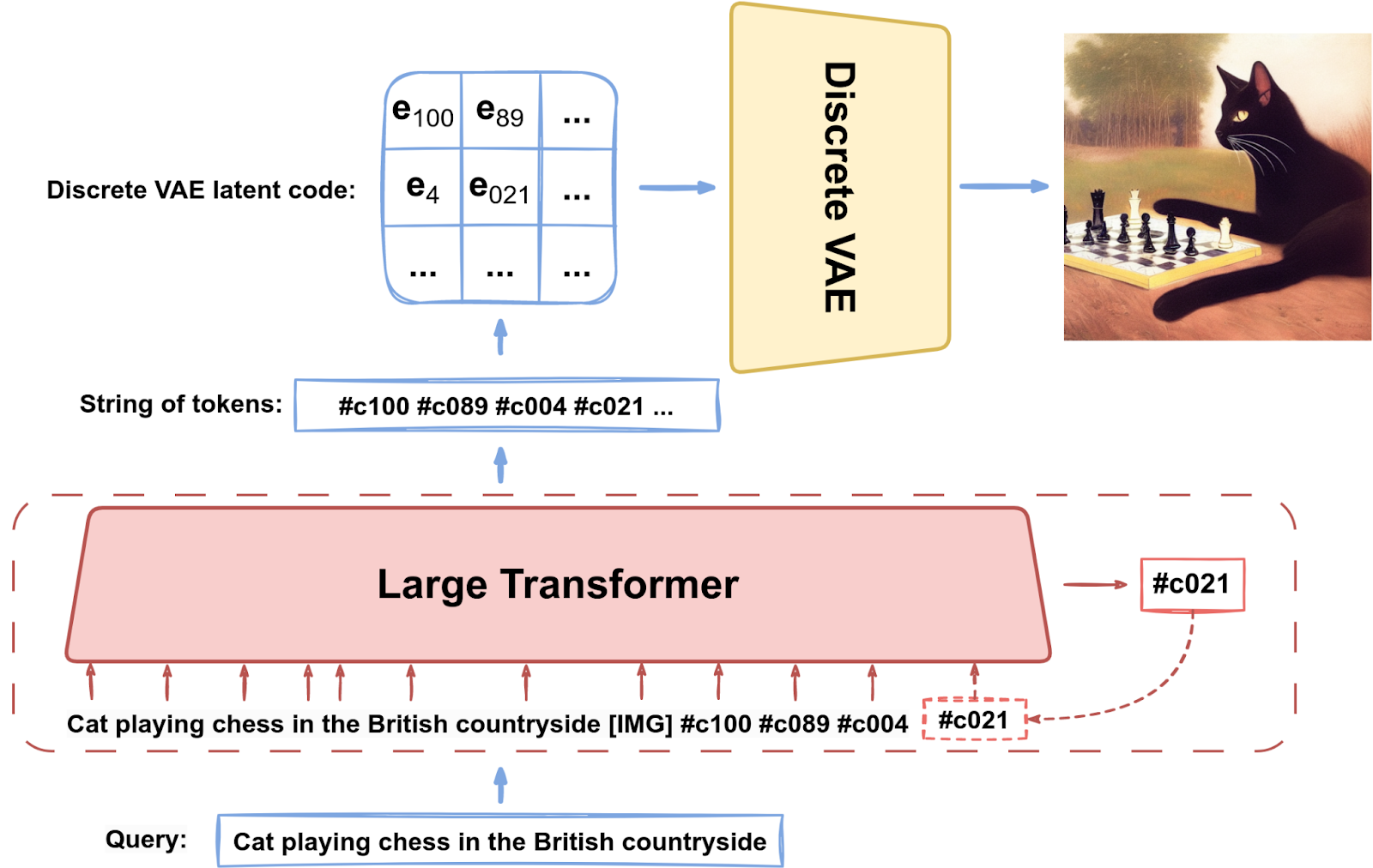
The main idea is to train a Transformer-based model to generate tokens that comprise the latent code of a discrete VAE such as the one we discussed in the previous post. Discrete latent spaces converge here with the Transformers’ main forte: learning to continue sequences of tokens.
We only need to train a GPT-like model to generate the latent code as a sequence of special tokens that would continue a text description: “Cat playing chess in the British countryside [IMG] #c100 #c089 #c004 …”. Then we can run it with a text query followed by the special token “[IMG]”, and supposedly it will produce a sequence of latent codes for the discrete VAE. Naturally, this will require us to retrain (or fine-tune) a text Transformer on (image, text) pairs encoded in this way.
Formally speaking, DALL-E is a generative model that needs to learn the joint distribution
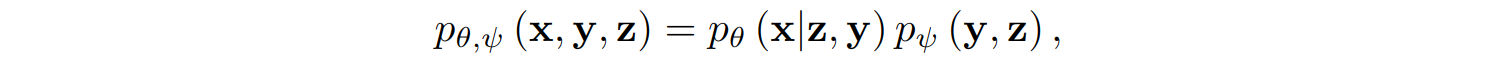
where x is an image, y is the corresponding text description, and z is the image’s latent code. The Transformer learns to generate z from y (actually, learns the entire p(y, z) since it inevitably becomes a generative model for text as well), and the result is used by the discrete VAE, so actually we assume that p(x | z, y) = p(x | z).
From the mathematical point of view, DALL-E actually optimizes a huge variational lower bound
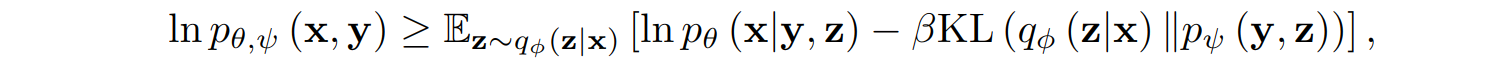
where the distributions in this formula correspond to different parts of the model:
We will not go into the details of variational inference and explain the inequality shown above in full; this is a very important topic in machine learning but we do not have the space to do it justice here. After the derivation, though, it all boils down to a very understandable iterative process:
At this point, we are done with the general structure of DALL-E. But, alas, to get the full picture we need to return to discrete variational autoencoders because DALL-E uses a slightly different breed of those than VQ-VAE and VQ-GAN we previously discussed.
We have seen two different discrete VAEs in the previous post: VQ-VAE that introduced the idea of discrete latent codes and VQ-GAN that added a patch-based discriminator to further improve things. But both of them had a middle part that feels pretty ad hoc to me, and hopefully to you as well by now: to move gradients through the discrete latent space they had to go around the discrete part with a copy-gradient operation.
Discrete VAE used in DALL-E takes the next step: instead of outputting a latent vector that is then “rounded” to a codebook vector, it outputs a whole probability distribution over the codebook, probabilities for a “die” that then can be rolled to determine the actual vector:
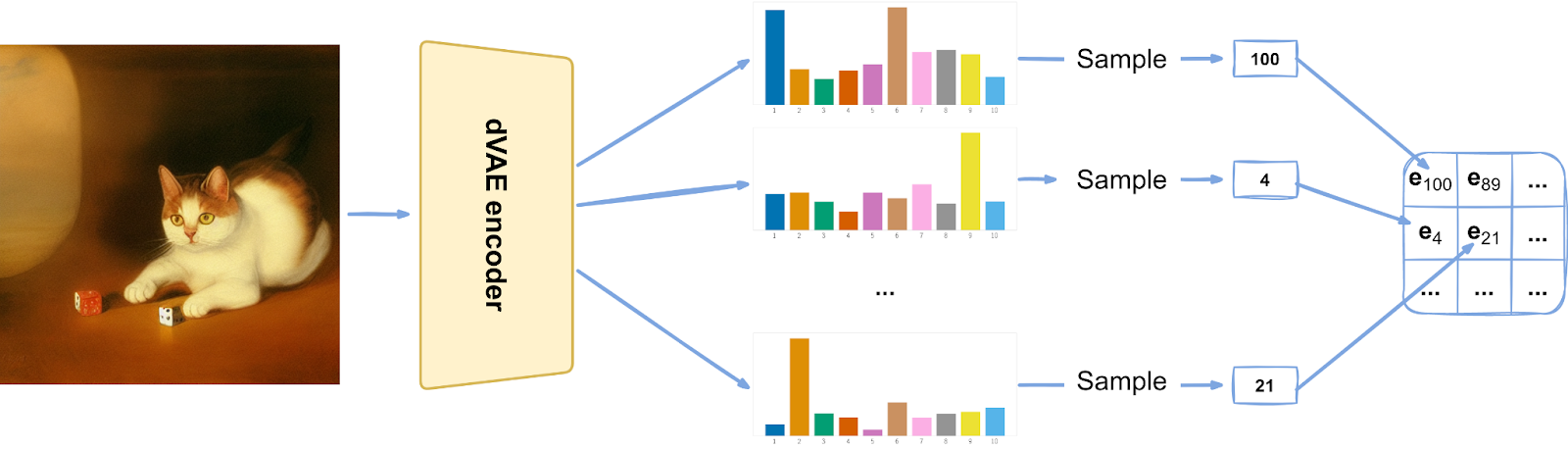
This is exactly parallel to the idea used in VAEs: we output a distribution in the latent space and thus obtain additional regularization and make the resulting model better.
So now instead of the VQ-VAE problem—how do we put gradients through taking nearest neighbors—we have a different problem: how do we put gradients through rolling a die? Fortunately, we already have a hint: we solved the exact same problem for Gaussians with the reparametrization trick in regular VAEs! The trick was to generate a random sample from a standard Gaussian distribution and then apply a deterministic (and differentiable) linear transformation to change it into a sample from the needed Gaussian.
The distribution is different now, but the trick is the same. We need to first sample from a fixed distribution and then apply a transformation to get the die roll with given probabilities. The fixed distribution in question is actually quite interesting: it is the Gumbel distribution whose density and cumulative distribution function are defined as

In statistics, the Gumbel distribution appears as the distribution of the maximum (or minimum) of several samples, but, to be honest, I have never encountered the Gumbel distribution in any practical context other than this reparametrization trick.
Anyway, the important part is that once you have sampled gi from the Gumbel distribution defined above, you can get a sample from a discrete distribution with probabilities πi (the result of a die roll) as
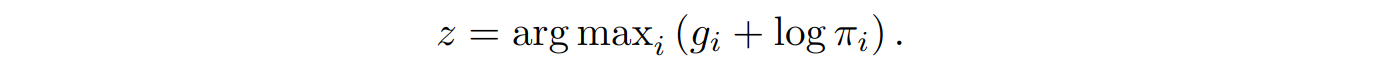
The proof of this fact, known as the Gumbel-Max trick, is a straightforward but somewhat tedious calculation, so I’ll skip it or, to put it in a slightly more stylish way, leave it as an exercise for the reader.
Once we have the Gumbel-Max trick, though, we are not quite done. We have gone from sampling to argmax, but it’s still not quite what we need. The argmax operation is also not good for passing gradients since it is piecewise constant; in fact, in VQ-VAE we had exactly the same problem, with argmin for nearest neighbors, and had to resort to copying the gradients.
This time, though, we don’t have to. Since the argmax here corresponds to die rolling, it makes perfect sense to relax it to softmax:
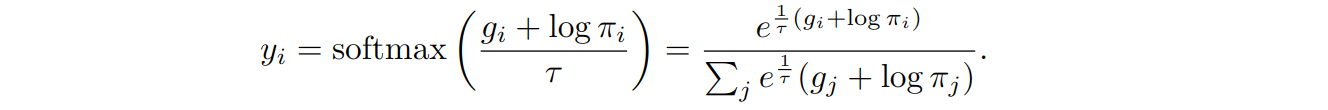
For τ→0 this tends to a discrete distribution with probabilities πi, and during training we can gradually reduce the temperature τ. Note that now the result is not a single codebook vector but a linear combination of codebook vectors with weights yi.
Overall, we have the following scheme in our discrete VAE:
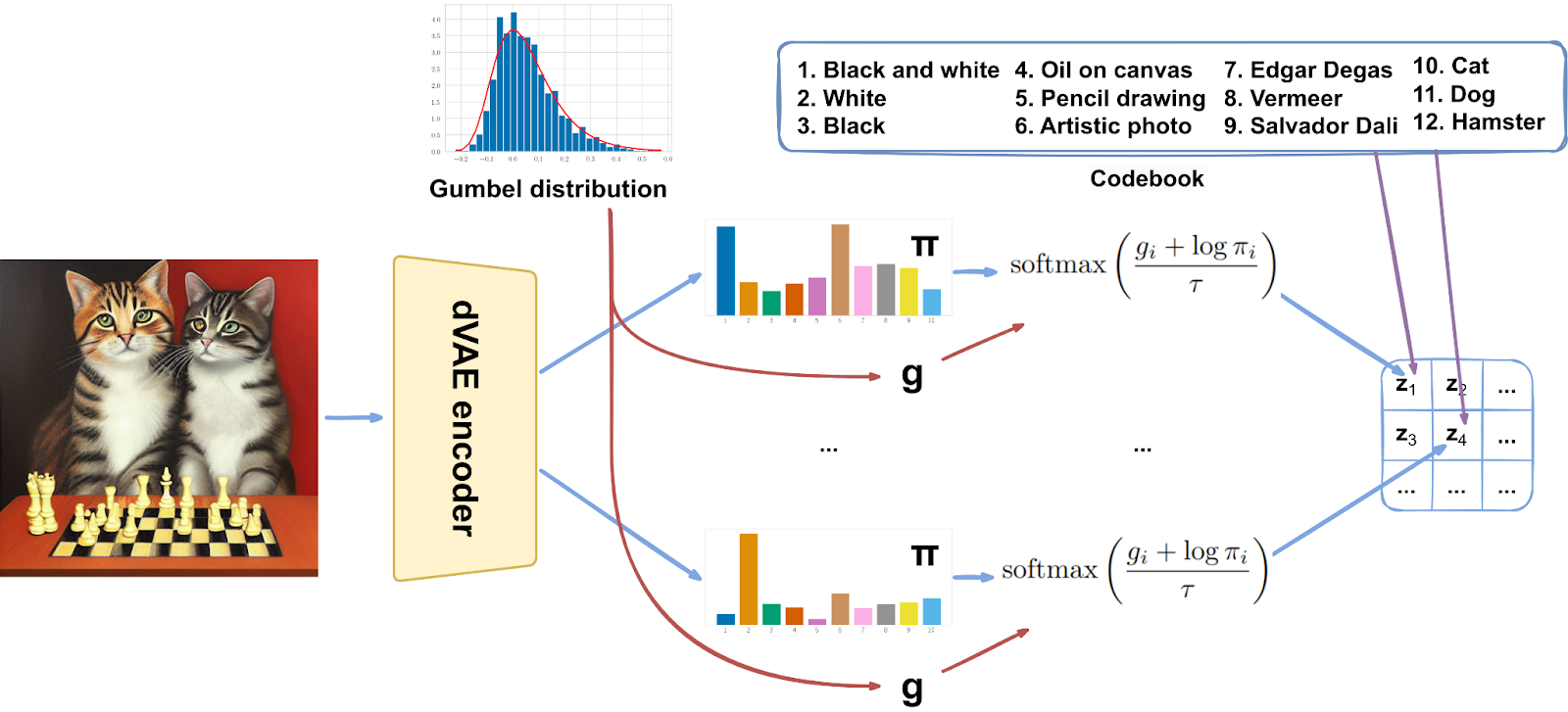
And with that, we are done with DALL-E! It remains to see how well it works.
DALL-E debuted at the very beginning of 2021. This was a perfect New Year’s present for all kinds of AI-related media because DALL-E was indeed a big step forward from what researchers had been able to do before. Images from the DALL-E OpenAI post and paper were hyped all across the Web; images like this one:

Or this one:

It already looked like these images could be useful in practice, and discussions about “replacing the illustrators” began. DALL-E was also able to use image prompts (parts of the resulting image that should be preserved) that could define the style and overall feel of the result.
DALL-E seemed to have a rather deep understanding of our reality that it could put into pictures. For example, the next illustration shows several image prompts and a text prompt that asks DALL-E to show how telephones looked at different stages of their development:

Although the quality of the images themselves may be underwhelming for those who have already seen Stable Diffusion and Midjourney, it was really head and shoulders above anything other available solutions could produce, and it was quite a shocking piece of news for many AI researchers, including yours truly.
It was clear that it would be only a matter of time before DALL-E would be scaled up to high-definition images (the original DALL-E produced 256×256 results) and made even more “understanding” of reality with larger Transformer-based text models. That is indeed what happened, and the world we live in today is being increasingly transformed by both large language models and large image generation models.
Still, many new ideas appeared along this way, and we cannot say that DALL-E 2 is just “DALL-E with more layers”. That’s why our series of posts is far from the end, and modern generative AI has a lot more to teach us.
Today, we have discussed DALL-E, a model released in January 2021. A mere two years have passed, but it looks like DALL-E is already hopelessly outdated. New models that visibly advance state of the art for image generation appear every few months, and the rate of this advancement does not seem to stagnate. Don’t worry though, the ideas behind DALL-E are still sound and useful, and this has been my primary ambition in this series: explain the ideas, the how rather than the what.
However, to get to the current state of the art we need more ideas. So next time, we will take a brief detour from generation and talk about models that produce multimodal latent spaces, such as OpenAI’s CLIP (Contrastive Language-Image Pre-Training) and its successors. They are extremely useful for, e.g., multimodal retrieval (searching for images and videos), but they also serve as the basis for further generative models. Until next time!
Sergey Nikolenko
Head of AI, Synthesis AI
