
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
As we discussed in part 1, the Metaverse has the potential to fundamentally alter just about every aspect of human existence. The way we work, play, interact with others, and more is going to move into a virtual reality sooner than many people imagine. With pixel-perfect labeling, synthetic data could be the key to unlocking the metaverse.
Three hurdles to overcome to enter the Metaverse
Synthetic data is fundamentally altering the way data scientists and machine learning practitioners build, train, and deploy the computer models that will bring about the Metaverse. The three primary challenges they are confronting today are simultaneous localization and mapping (SLAM), gaze estimation, and creating a realistic avatar within the Metaverse for each user.
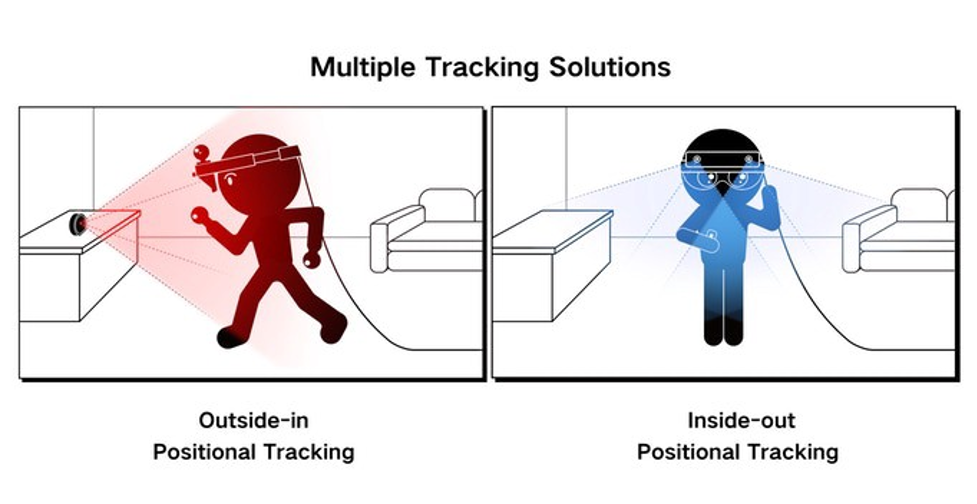
Virtual reality helmets and controllers need to be positioned in space very accurately, and this tracking is usually done with visual information from cameras, either installed separately in base stations or embedded into the helmet itself. This is even more difficult with augmented reality than virtual reality. The latter creates an entirely new world for the user, but software for the former needs to understand its position in the world plus have a detailed and accurate 3D map of the environment.
Fortunately, headset technology has recently undergone an important shift: earlier models tended to require base stations (“outside-in” tracking), but the latest helmets can localize controllers accurately with embedded cameras (“inside-out” tracking). The improved computer vision technology has made it possible to solve the SLAM problem without any special setup in the room.
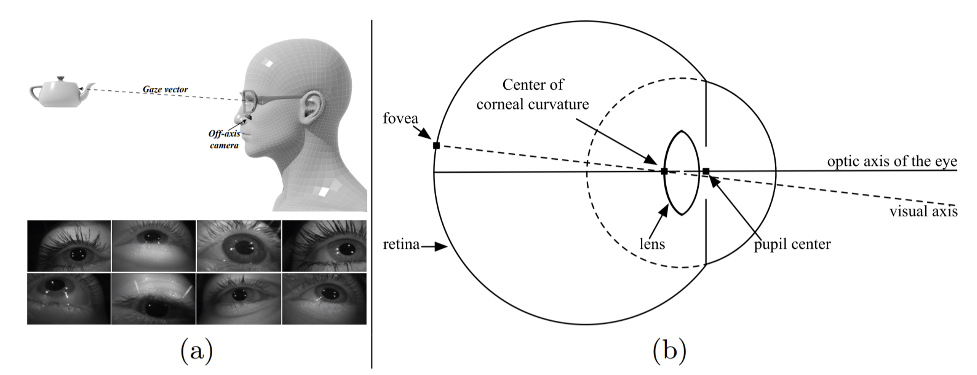
Gaze estimation, i.e. finding out where a person is looking by observing their face and eyes, is also a crucial problem for augmented and virtual reality. In particular, current virtual reality relies upon foveated rendering. This technique renders the image in the center of our field of view in high resolution and high detail, and becomes progressively worse on the periphery. This is, by the way, exactly how we ourselves see things; we see only a very small portion of the field of view clearly and in full detail, and peripheral vision is increasingly blurry as you move out.
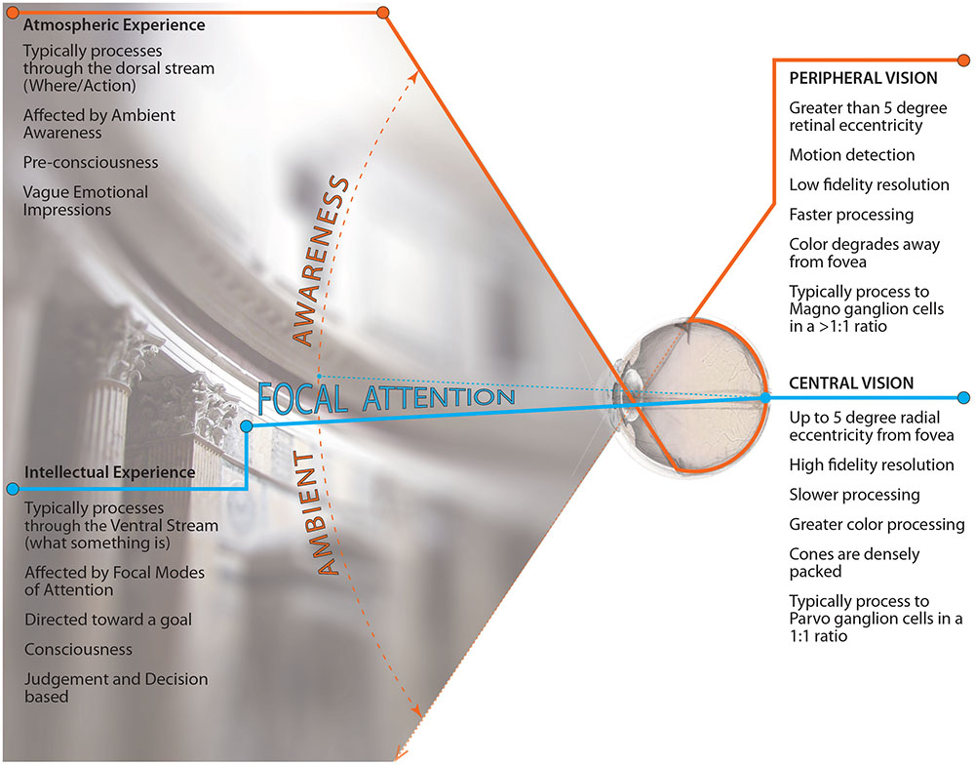
Foveated rendering is important for virtual reality because the field of view is an order of magnitude larger than flat screens. And, as it requires a high resolution to support the illusion of immersive virtual reality, rendering it all in this resolution would be far beyond consumer hardware.
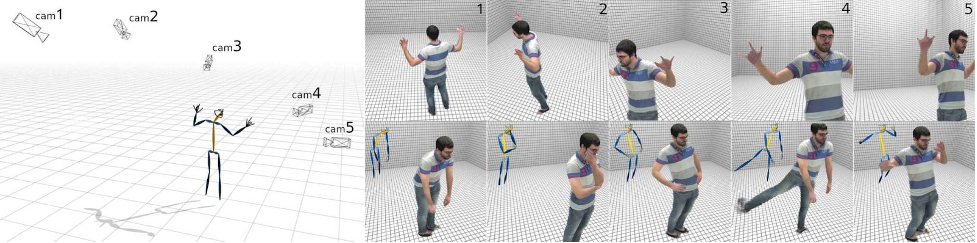
Third, when you enter virtual reality, you need an avatar to represent you. Current virtual reality applications usually provide stock avatars or forgo them entirely (many virtual reality games represent the player as just a head and a pair of hands), but an immersive virtual social experience requires photorealistic virtual avatars that represent real people and can capture their poses.
Because modern computer vision is requiring increasingly large datasets, manual labeling simply stops working at some point. At Synthesis AI, we are proposing a solution to this problem in the form of synthetic data: artificially generated images and/or 3D scenes that can be used to train machine learning models.
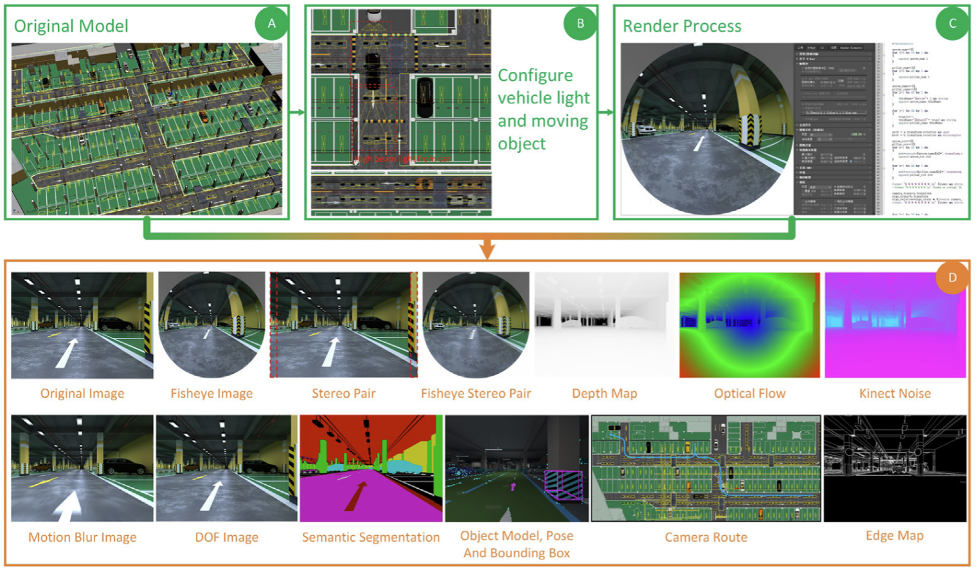
Simultaneous localization and mapping: SLAM is an example where synthetic data can be used in a straightforward way: construct a 3D scene and use it to render training set images with pixel-perfect labels of any kind you like. We have talked about simulated environments on this blog before, and SLAM is a practical problem where segmentation and depth estimation arise as important parts. Modern synthetic datasets provide a wide range of cameras and modalities.
Gaze estimation: Real data for gaze estimation is often hard to come by, and here synthetic data comes to the rescue. It is a great example of domain adaptation, the process of modifying the training data and/or machine learning models so that the model can work on data from a different domain. Gaze estimation works with relatively small input images, so this was an early success for GANs. It proved synthetic-to-real refinement, where synthetic images were made more realistic with specially trained generative models. Recent developments include a large real dataset, MagicEyes, that was created specifically for augmented reality applications.
Virtual avatars: Virtual avatars touch upon synthetic data from the opposite direction: now the question is about using machine learning to generate synthetic data. We talked about capturing the pose and/or emotions from a real human model, but there is actually a rising trend in machine learning models that are able to create realistic avatars from scratch.
Instagram is experiencing a new phenomenon: virtual influencers, accounts that have a personality but do not have a human actually realizing this personality. Lil Miquela, one of the most popular virtual influencers, is a virtual 16 year old girl who has more than 3 million followers. Synthesis AI’s datasets can create realistic digital humans, with complex pose estimation, gesture recognition, activity classification, and more.

From a research perspective, this requires state of the art generative models that are supplemented with synthetic data in the classical sense: you need to create a highly realistic 3D environment, place a high-quality human model inside, and then use a generative model (usually a style transfer model) to make the resulting image even more realistic. In this direction, we still have a long way to go before we can have fully photorealistic 3D avatars ready for the Metaverse. The field is developing very rapidly, however, and this long way may be traversed in much less time than we have ever expected.
