
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Today, I am proud to present our guest for the second interview, Dr. Andrew Rabinovich. Currently, Andrew is the CTO and co-founder of Headroom Inc., a startup devoted to producing AI-based solutions for online business meetings (taking notes, detecting and attracting attention, summarization, and so on). Dr. Rabinovich has produced many important advances in the field of computer vision (here is his Google Scholar account), but he is probably best known for his work as the Director of Deep Learning at Magic Leap, an augmented reality startup that raised more than $3B in investments.

Q1. Hello Andrew, and welcome! Let me begin with a general question that I will also expand upon later. You have a lot of experience in academia, with numerous papers published at top conferences and receiving hundreds of citations. At the same time, some of your top accomplishments are related to more “industrial” research work at startups such as Magic Leap.
What kind of work has been more fulfilling for you? And what, in your view, are the main differences in the process and/or results? On the surface, research work in both industry and academia is supposed to produce novel solutions that work well for the problem at hand; are there important differences here?
Hello Sergey, I am glad to be here and thank you for the invitation. What you guys, at Synthesis, are doing is extremely important for the computer vision field, and I am grateful that with these efforts the state of the art in Computer Vision, and AI in general, will improve for many years to come.
This is a very interesting question that dates back to my undergraduate days when I worked on medical image analysis and was interested in building image cytometers — automated microscopes with machine learning inference skills. While developing the cytometer, it quickly became apparent that the state of the art in computer vision (it was called image processing then) wasn’t quite up to par to solve the practical problems I was facing. This realization made me turn to more theoretical work and focus on developing core vision algorithms. A similar situation happened at Google, where I was really excited to work on algorithms for Google Goggles, the first AR app for Android and iPhone. Then existing, pre-deep learning approaches, weren’t satisfactory to develop product features we were interested in. Again, I turned to more academic research and was very fortunate to work on the development of modern deep networks, including the Inception architecture, which in turn we applied to visual search in Google Photos. You can probably guess where this is going, the same story repeated itself at Magic Leap. I quickly realized that to develop the vision of Mixed Reality, and to close the perceptual gap between real and virtual content, a lot of new fundamental research in computer vision and AI had to be done.
Overall, academic and applied research aren’t really separable in my mind. Computer vision and machine learning are not fundamental science disciplines, they don’t describe nature. These are engineering challenges that need to be addressed in the context of practical problems. Industrial research provides that context. If the context is chosen correctly, then solutions to specific engineering challenges generalize to other tasks.
Q2. Our blog is devoted to synthetic data, so here is the most expected question. During your work in Headroom, Magic Leap, and other startups, have you used synthetic data to solve computer vision problems? In what ways, and how much did it help (if you’re allowed to divulge this kind of information, of course)? Did it help for the augmented reality applications at Magic Leap?
I have been a proponent of synthetic data since my days at Google, where we heavily relied on data augmentation (synthetic data 0.1) to train deep models. At Magic Leap, we created a whole synthetic data group, with render farms and custom pipelines. At that time, synthetic data companies were quite rare, so we had to do most of it. The benefits of synthetic data ranged from hand and eye-tracking to 3D reconstruction and segmentation. At Headroom, we are collaborating with synthetic data providers across a number of problems.
Generally, there are really two fundamental issues with data for learning. First, obtaining data and labeling it can be quite expensive and laborious, whether it involves humans in the loop or not. Many companies today have established an efficient pipeline for ingesting data and providing annotations for it. The second problem, however, is far more critical. Relying on the human ability to annotate certain types of data is misleading. People can only provide relative and qualitative labels, such as drawing bounding boxes around objects or qualifying relative distances. If the task is much more specific, i.e. describe the illumination in the room, or how far away is the person from the car (in centimeters), these questions humans cannot with the required precision, and in the absence of specific sensors, synthetic data is the only path forward.
By construction, machine-generated data is auto labeled. The main drawback of synthetic data is that it may be sampled from a distribution that doesn’t represent the real world. Fortunately, that gap is quickly closing with realistic synthesis and domain adaptation approaches in AI.
Q3. One of your latest papers, “DELTAS: Depth Estimation by Learning Triangulation and Densification of Sparse Points”, seems to be making a very interesting point beyond its immediate results. It reconstructs 3D meshes of scenes from RGB images with an end-to-end network, never producing an intermediate depth map, like most other methods do:

This sounds very human-like to me: I can navigate complex 3D environments, and I have a pretty good grasp on relative depth (which object is closer than the other), but I definitely cannot produce an accurate depth map for my room. Moreover, this is in line with the general trend of deep learning that seems to me evident over at least the last decade: we have neural networks increasingly perform end-to-end training and learn to do various tasks directly, without predefined intermediate representations or side results. The tradeoff here is that usually end-to-end training for complex tasks requires far more data than more specialized training when you have, e.g., ground truth labeled depth maps.
Do you agree that this trend exists and if yes, where do you think it will take us in the near future, especially in the field of computer vision? Are there other important problems that can be overcome with such end-to-end architectures, and do we have enough data to do that? To make the question more open-ended, what other trends in computer vision do you see that you expect to carry over for the next couple of years (I think in deep learning it doesn’t make sense to predict beyond a couple of years anyway)?
End-to-end learning is a very attractive, almost romantic notion. The formulations are usually very elegant and simple. However, as you correctly point out, it requires a significantly larger amount of training data to account for all variations. That is why most problems aren’t solved end-to-end, as we aim to provide supervision along the way. With regards to 3D reconstruction, intermediate supervision with depth maps is problematic as well. Obtaining a large amount of depth data is not trivial.
As for the trends, I am not a big follower of them, as they are mostly set by the availability of datasets or funding. Over the last few years, I have focused on multi-task learning and believe that focus on this area of AI will lead to significant advances due to generalization during training and inductive bias during inference.
Looking forward, I believe developing AI approaches one modality at a time, when applied to the multimodal tasks that surround us, artificially complicates the problem. For example, the classical problem of video understanding is typically solved by isolating video from everything else. However, presence of text, available in the movie scripts or live transcription, and audio sources, make the problem much more tractable. Multimodal multitask learning is one of the areas in AI I am most excited about today.
Q4. Interestingly, another recent paper of yours, “MagicEyes: A Large Scale Eye Gaze Estimation Dataset for Mixed Reality”, goes in precisely the opposite direction. It makes the case that for eye gaze estimation, better results can be achieved by thinking about the 3D properties of the eye (position of the cornea center and pupil center in 3D) and including them in a multi-task architecture:
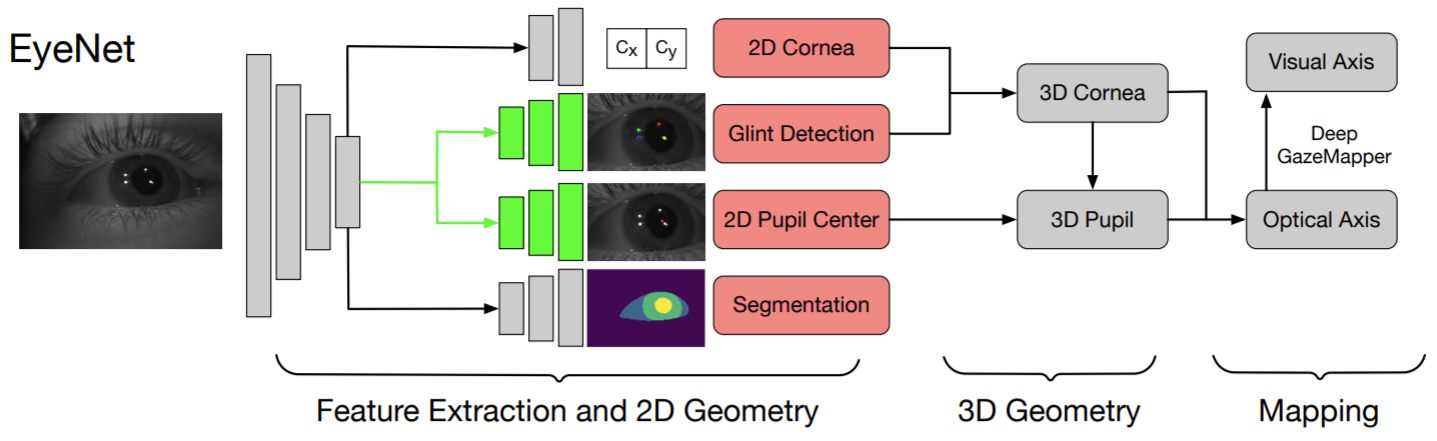
Eye gaze estimation is one of my favorite examples for synthetic data because it has everything: a “pure synthetic” solution-based (literally!) on nearest neighbors, GANs for synthetic-to-real refinement that improve the results, new synthetic datasets such as NVGaze… For the readers, here is our recent post about gaze estimation. But it looks like I will have to update my usual story: MagicEyes that you presented in this paper is a large-scale dataset with human-labeled real data, and it allows for better results.
Obviously, collecting this dataset took a lot of money and effort. This leads to two questions. Specifically, do you believe that synthetic data can still help improve eye gaze estimation further? The paper does not show experiments with training EyeNet on mixed real+synthetic datasets: do you think it would be worthwhile to try? And generally, in what other computer vision problems do you expect even larger manually labeled real datasets to appear in the near future, and how do you think it will affect applications of synthetic data in computer vision?
Eye-tracking is a very interesting example of a computer vision problem. There are decades of research from human vision and neuroscience about the function and anatomy of how we see. MagicEyes datasets aim to collect a variable set of data from a broad population of subjects to capture this natural variability. The learned representations from this data form a foundation of the distribution that we want to learn for a number of different tasks, ranging from blink detection to 3D gaze estimation. If MagicEyes was infinitely large, we’d be done. Labeling this kind of data is possible, even though slow and expensive. By supplementing MagicEyes with synthetic data, we get an opportunity to significantly reduce time and cost, and to increase the training data set size and heterogeneity of seen examples.
As for other vision problems, manual datasets for autonomous navigation, satellite imagery, and human interactions are being collected and annotated at scale. Solving these tasks with additional synthetic data will be extremely useful. In fact, we are starting to see synthetic data expertise (specific companies pick and choose their domains of excellence) being compartmentalized to indoor and outdoor environments, and to human vs. man-made objects.
Q5. And now let me go back to the industry-vs-academia question, from a different point of view. While preparing the previous two questions, I opened your Google Scholar profile and sorted the publications chronologically. Naturally, you never stopped producing top-notch academic output, but it turned out that it’s far easier to look for your recent papers at your DBLP profile because your Google Scholar profile has recently been literally dominated by patent applications. You’ve had dozens of those in the last couple of years!
Is that just a formal consequence of your work at MagicLeap and other startups or does it reflect a deeper position on how practical your work can soon become? Generally speaking, how ready do you think we (humanity) are for solving the basic high-level computer vision problems: 3D scene understanding, visual navigation in the real world, producing seamless augmented reality, and so on? Are we there yet, and if not quite, how long do you think it will take in each case?
Writing patents is standard practice in industrial research. I was fortunate enough to complement patent filings with the corresponding peer-reviewed publications. As we discussed earlier, I do believe that academic research in computer vision and machine learning precedes its applications. The current AI spring started in 2012, has opened a number of industrial research avenues that build upon theoretical results and will lead to innovative products for the next decade.
With regards to solving complex vision and learning tasks, I think we are still quite a bit away. Machines have become excellent at pattern matching. There are a large number of practical applications that are coming online: from autonomous driving to augmented reality. The limiting factors here are not just the algorithms, however, but rather sensors and data. In augmented reality, for example, the AI components are available, but the computation power, batteries, and displays are not there to deliver a compelling product.
Q6. Apart from your research work in academia and industry, you are also helping LDV Capital, one of the top VC funds for AI-related startups, as their Expert in Residence. This may sound like a stock question, but it would be very interesting to hear your personal take on this: how do you evaluate startups that come for your review? What are you looking for the most, and what are the most common mistakes startups make, in your personal experience? Maybe you can share some advice specific for vision-related startups, since it is your personal area of expertise, and LDV Capital seems to have this as an important focus area as well.
Traditional VC funding happens by following trends. A trend-setting VC firm invests in a particular sector, and the rest of the funds follow. A growing fear of missing out results in large amounts of capital being deployed. Once a new trend emerges, most VC firms happily switch context or diversify. When I look at start-up projects, whether my own or others, I always look for an end goal thesis, and decide if I agree with it. For example, a company X makes LiDAR sensors, LiDARs are a hot topic these days. To me, company X is interesting because I believe that without LiDAR, certain long-term goals aren’t possible to achieve, self-driving being one of them. If company X fits into the global scheme of things, it is meaningful and fundamental to market development, if it is one-off—create filters for your Instagram account,—not so much.
Then, there is the team. Regardless of prior focus, having pedigree, whether academic research, product development, or executive management, is a must. It is fairly simple to identify experts from dreamers.
Finally, there are many aspiring entrepreneurs who want to start companies for the sake of starting companies or because they have access to interesting technology. In that situation, product definition doesn’t come from a real need to improve an existing approach, but rather from an opportunistic perspective of “let’s invent a solution for a problem that doesn’t exist”. I think this is the curse of most tech startups.
Thank you very much for your answers, Andrew! We will come back with the next interview soon—stay tuned!
Sergey Nikolenko
Head of AI, Synthesis AI
