
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
We continue from last time, when we began a discussion of the origins and first applications of synthetic data: using simple artificial drawings for specific problems and using synthetically generated datasets to compare different computer vision algorithms. Today, we will learn how people made self-driving cars in the 1980s and see that as soon as computer vision started tackling real world problems with machine learning, it could not avoid synthetic data.

Self-driving cars are hot. By now, self-driving trucks and buses certified for closed environments such as production facilities or airports are already on the market, and many different companies are working towards putting self-driving passenger cars on the roads of our cities. This kind of progress always takes longer than expected, but by now I believe that we are truly on the verge of a breakthrough (or maybe the breakthrough has already happened and will soon appear on the market). In this post, however, I want to turn back to the history of the subject.
The idea of a self-driving vehicle is very old. A magic flying carpet appears in The Book of the Thousand Nights and One Night and is attributed to the court of King Solomon. Leonardo da Vinci left a sketch of a clockwork cart that would go through a preprogrammed route. And so on, and so forth: I will refer to an excellent article by Marc Weber and steal only two photographs from there. Back in 1939, General Motors had a huge pavillion at the New York World’s Fair; in an aptly named Futurama ride (did Matt Groening take inspiration from General Motors?), they showed their vision of the cities of the future. These cities included smart roads that would inform smart vehicles, and they would drive autonomously with no supervision from humans. Here is how General Motors envisaged the future back in 1939:

The reality still has not quite caught up with this vision, and the path to self-driving vehicles has been very slow. There were successful experiments with self-driving cars in the 1970s. in particular, in 1977 the Tsukuba Mechanical Engineering Laboratory in Japan developed a computer that would automatically steer a car based on visually distinguishable markers that city streets would have to be fitted with.
In the 1980s, a project funded by DARPA produced a car that could actually travel along real roads using computer vision. This was the famous ALV (Autonomous Land Vehicle) project, and its vision system was able to locate roads in the images from cameras, solve the inverse geometry problem and send the three-dimensional road centerpoints to the navigation system. Here is how it worked:
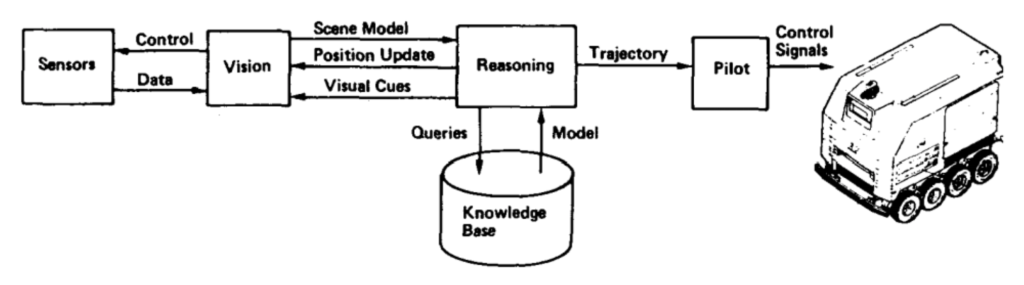
The vision system, called VITS (for Vision Task Sequencer) and summarized in a paper by Turk et al. (the figures above and below are taken from there), did not use machine learning in the current meaning of the word. Similar to other computer vision systems of those days, as we discussed in the previous post, it relied on specially developed segmentation, road boundary extraction, and inverse geometry algorithms. The pipeline looked like this:
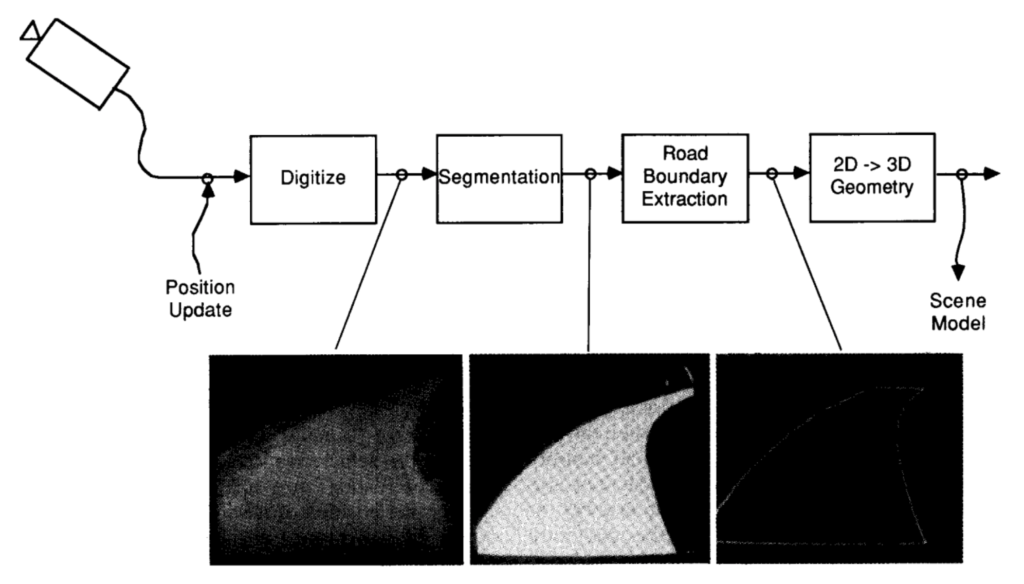
How well did it all work? The paper reports that the ALV “could travel a distance of 4.2 km at speeds up to 10 km/h, handle variations in road surface, and navigate a sharp, almost hairpin, curve”. Then obstacle avoidance was added to the navigation system, and Alvin (that was the nickname of the actual self-driving car produced by the ALV project) could steer clear of the obstacles on a road and speed up to 20 km/h on a clear road. Pretty impressive for the 1980s, but, of course, the real problems (such as passengers jumping in front of self-driving cars) did not even begin to be considered.
Alvin did not learn, did not need any data, and therefore no synthetic data. Why are we talking about these early days of self-driving at all?
Because this “no learning” stance changed very soon. In 1989, Dean A. Pomerleau published a paper on NIPS (this was the 2nd NIPS, a very different kind of conference than what it has blossomed into now) called ALVINN: An Autonomous Land Vehicle In a Neural Network. This was, as far as I know, one of the first attempts to produce computer vision systems for self-driving cars based on machine learning. And it had neural networks, too!
The basic architecture of ALVINN was as follows:
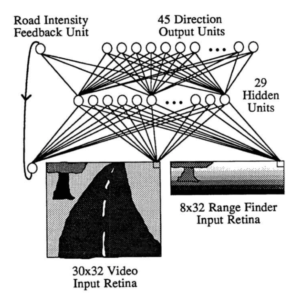
This means that the neural network had two kinds of input: 30 × 32 videos supplemented with 8 × 32 range finder data. The neural architecture was a classic two-layer feedforward network: input pixels go through a hidden layer and then on to the output units that try to tell what is the curvature of the turn ahead, so that the vehicle could stay on the road. There is also a special road intensity feedback unit that simply tells whether the road was lighter or darker than the background on the previous input image.
The next step was to train ALVINN. To train, the network needed a training set. Here is what Dean Pomerleau has to say about the training data collection:
Training on actual road images is logistically difficult, because in order to develop a general representation, the network must be presented with a large number of training exemplars depicting roads under a wide variety of conditions. Collection of such a data set would be difficult, and changes in parameters such as camera orientation would require collecting an entirely new set of road images…
This is exactly the kind of problems with labeling and dataset representativeness that we discussed for modern machine learning, only Pomerleau is talking about these problems in 1989, in the context of 30 × 32 pixel videos! And what is his solution? Let’s read on:
…To avoid these difficulties we have developed a simulated road generator which creates road images to be used as training exemplars for the network.
Bingo! As soon as researchers needed to solve a real-world computer vision problem with a neural network, synthetic data appeared. This was one of the earliest examples of automatically generated synthetic datasets used to train an actual computer vision system.
Actually, low resolution of the sensors in those days made it easier to use synthetic data. Here are two images used by ALVINN, a real one on the left and a simulated one on the right:

It doesn’t take much to achieve photorealism when the camera works like this, right?
The results were positive. On synthetic test sets, ALVINN could correctly (within two units) predict turn curvature approximately 90% of the time, on par with the best handcrafted algorithms of the time. In real world testing, ALVINN could drive a car along a 400 meter path at a speed of half a meter per second. Interestingly, the limiting factor here was the speed of processing for the computer systems. Pomerleau reports that ALV’s handcrafted algorithms could achieve a speed of 1 meter per second, but only on a much faster Warp computer, while ALVINN was working on the on-board Sun computer, and he expects “dramatic speedups” after switching to Warp.
I have to quote from Pomerleau’s conclusions again here — apologies for so many quotes, but this work really shines as a very early snapshot of everything that is so cool about synthetic data:
Once a realistic artificial road generator was developed, back-propagation produced in half an hour a relatively successful road following system. It took many months of algorithm development and parameter tuning by the vision and autonomous navigation groups at CMU to reach a similar level of performance using traditional image processing and pattern recognition techniques.
Pomerleau says this more as a praise for machine learning over handcrafted algorithm development, and that conclusion is correct as well. But it would take much more than half an hour if Pomerleau’s group had to label every single image from a real camera by hand. And of course, to train for different driving conditions they would need to collect a whole new dataset in the field, with a real car, rather than just tweak the parameters of the synthetic data generator. This quote is as much evidence for the advantages of synthetic data as for machine learning in general.
But what if all this was this just a blip in the history of self-driving car development? Is synthetic data still used for this purpose?
Of course, and much more intensely than in the 1980s. We will return to this in much more detail in this blog later; for now, let me just note that apart from training computer vision models for autonomous vehicles, synthetic data can also provide interactive simulated environments, where a driving agent can be trained by reinforcement learning (remember one of our previous posts), fine-tuning computer vision models and training the agent itself together, in an end-to-end fashion.
The datasets themselves have also traveled a long way since the 30 × 32 videos of ALVINN. Again, we will return to this later in much more detail, for now I will just give you a taste. Here is a sample image from Synscapes, a recently published dataset with an emphasis on photorealism:

I don’t think I would be of much use as a discriminator for images like this. The domain transfer problem, alas, still remains relevant… but that’s a topic for another day.
In this post, I have concentrated on a single specific application of synthetic data in computer vision: training self-driving cars. This was indeed one of the first fields where holistic approaches to training computer vision models from data proved their advantages over handcrafted algorithms. And as we have seen today, synthetic data was instrumental in this development and still remains crucial for autonomous vehicle models up to this day. Next time, we will move on to other robots.
Sergey Nikolenko
Head of AI, Synthesis AI
