
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Today, we continue our series on the data problem in machine learning. In the first post, we realized that we are already pushing the boundaries of possible labeled datasets. In the second post, we discussed one way to avoid huge labeling costs: using one-shot and zero-shot learning. Now we are in for a quick overview of the kind of machine learning that might go without data at all: reinforcement learning.

Interestingly, some kinds of machine learning do not require any external data at all, let alone labeled data. Usually the idea is that they are able to generate data for themselves.
The main field where this becomes possible is reinforcement learning (RL), where an agent learns to perform well in an interactive environment. An agent can perform actions and receive rewards for these actions from the environment. Usually, modern RL architectures consist of the feature extraction part that processes environment states into features and an RL agent that transforms features into actions and converts rewards from the environment into weight updates. Here is a flowchart from a recent survey of deep RL for video games (Shao et al., 2019):
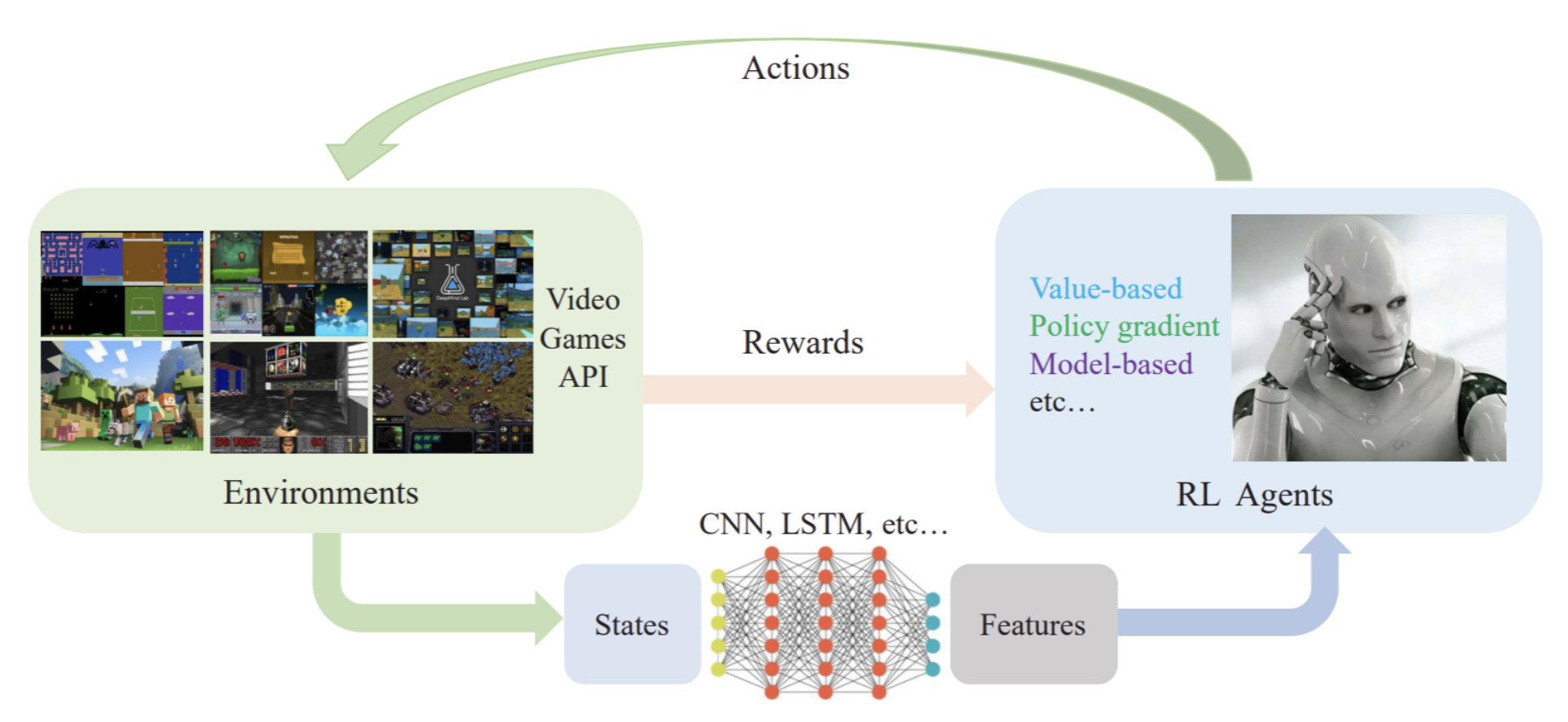
In the space of a short blog post it is, of course, impossible to do justice to a wide and interesting field such as reinforcement learning. So before we proceed to the main point of this post, let me only mention that for a long time, RL had been a very unusual field of machine learning in that the best introductory book in RL had been written twenty years ago. It was the famous book by Richard S. Sutton and Andrew G. Barto, Reinforcement Learning: An Introduction, first published in 1998. Naturally, it could not contain anything about the recent deep learning revolution that has transformed RL as well. Fortunately, very recently Sutton and Barto have published the second edition of their book. It’s still as well-written and accessible to beginners but now it contains the modern ideas as well; what’s more, it is available for free.
The poster child of modern data-free approaches to RL is AlphaZero by DeepMind (Silver et al., 2018). Their original breakthrough was AlphaGo (Silver et al., 2016), a model that beat Lee Sedol, one of the top human Go players. Long after DeepBlue beat Kasparov in chess, professional-level Go was remaining out of reach for computer programs, and AlphaGo’s success was unexpected even in 2016.
The match between Lee Sedol and AlphaGo became one of the most publicized events in AI and was widely considered as the “Sputnik moment” for Asia in AI, the moment when China, Japan, and Korea realized that deep learning is to be taken seriously. Lee Sedol (on the left below) could win one of the games, so although at the moment he was discouraged by losing to AlphaGo, I decided to illustrate this with what I believe to be the last serious game of Go won by humans against top computer players. When Ke Jie (on the right below), then #1 in the world Go rankings, played against an updated AlphaGo model two years later, he admitted that he did not stand a chance at any point:
But AlphaGo utilized a lot of labeled data: it had a pretraining step that used a large database of professional games. AlphaZero takes its name from the fact that it needs zero training data: it begins by knowing only the rules of the game and achieves top results through self-play, actually with a very simple loss function combined with tree search. AlphaZero beat AlphaGo (and its later version, AlphaGo Zero) in Go and one of the top chess engines, Stockfish, in chess.
The latest result by the DeepMind RL team, MuZero (Schrittweiser et al., 2019), is even more impressive. MuZero represents model-based RL, that is, it builds a model of the environment as it goes and does not know the rules of the game beforehand but has to learn them from scratch; e.g., in chess it cannot make illegal moves as actions but can consider them in tree search and has to learn that they are illegal by itself. With this additional complication, MuZero was able to achieve AlphaZero’s skill in chess and shogi and even outperform it in Go. Most importantly, the same model could also be applied to, e.g., computer games in Atari environments (a standard benchmark in reinforcement learning).
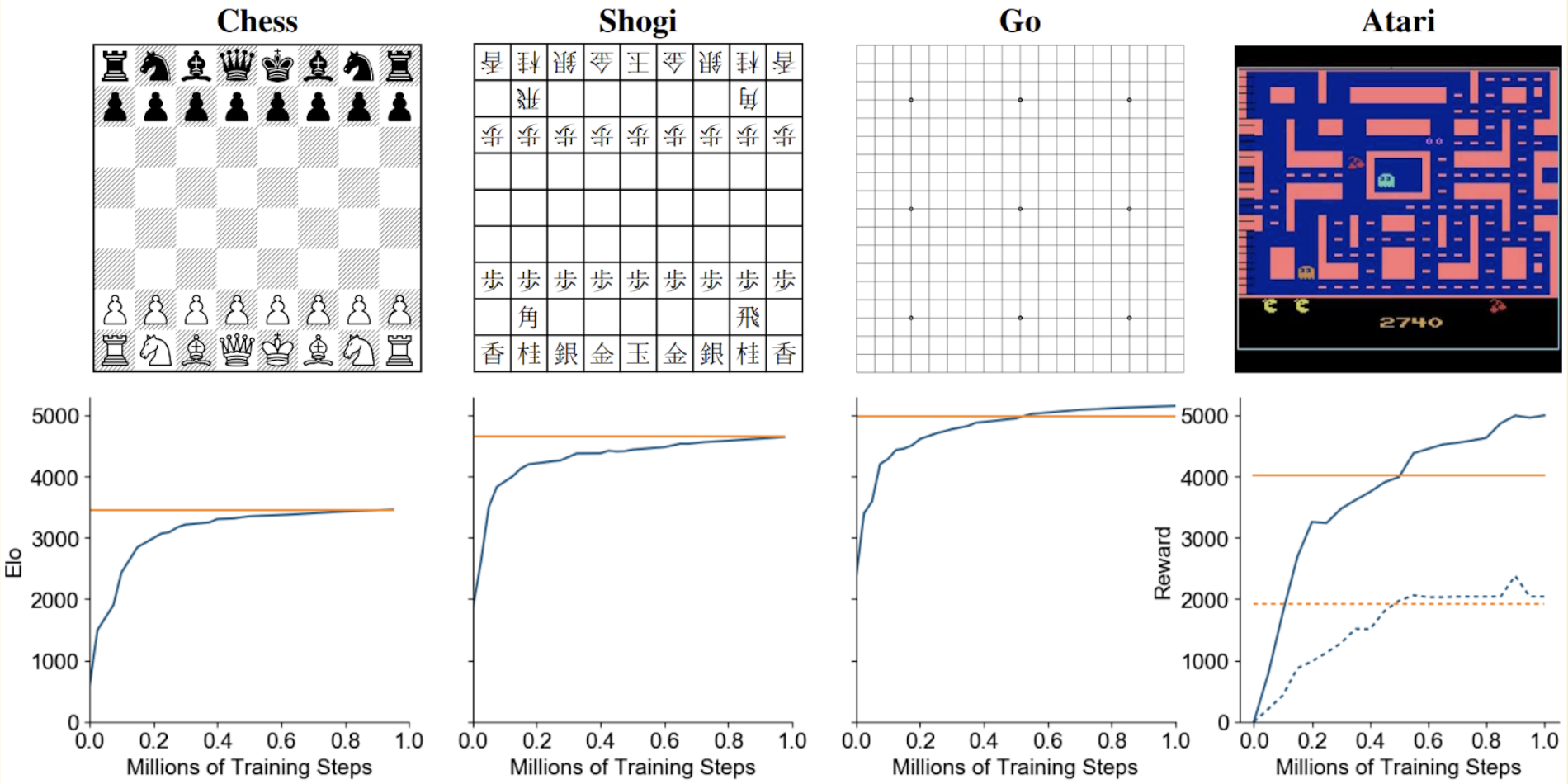
Source: https://arxiv.org/pdf/1911.08265.pdf
So what’s the catch? One problem is that not every problem can be formulated in terms of RL with no data required. You can learn to play games, i.e., self-contained finite structures where all rules are known in advance. But how do we learn, say, autonomous driving or walking, with a much wider variety of possible situations and individual components of these situations? One possible solution is to use synthetic virtual environments; let us proceed to a very interesting example of reinforcement learning for robotics.
One of the main fields of application for reinforcement learning is robotics: a field where machine learning models need to learn to perform in a real physical environment. From autonomous cars to industrial robotic arms, these environments are united by two properties.
Again, in this blog post we cannot hope to cover everything related to virtual environments for robotics; for a more detailed exposition see my recent survey (Nikolenko, 2019). I will only tell one story: the story of how a dexterous manipulation robot has learned to solve the Rubik’s cube.
The robot is a product of OpenAI, a famous company that drives research in many areas of machine learning, RL being a primary goal. In 2019, OpenAI has also produced OpenAI Five, a model that beat professionals in DotA 2, and earlier they had released OpenAI Gym, the main testing environment for reinforcement learning models.
Dactyl, the robot that we are talking about, is a longstanding project in OpenAI, initiated in 2016. The first big result came in 2018, when their robotic hand learned the basics of dexterous manipulation (OpenAI et al, 2018). In particular, they learned to take a block with letters and rotate it so that the target letter faces camera:

This was already a marvelous achievement. I will not go into the details of the robotic environment, the hand itself, or reinforcement learning algorithms that learned to do this. The main point for us is that they did not use any kind of domain adaptation techniques: they trained the robot entirely in a virtual environment and it worked almost seamlessly in real life.
To make it work, one has to apply domain randomization. The idea is to make synthetic data so varied that in order to succeed the model will have to be very robust. So robust that the distribution of environments where it works well will also cover the real world. The OpenAI team varied many parameters of the environment, including visual parameters such as and physical parameters such as size and weight of the cube, friction coefficients on the surfaces and in the robot’s joints, and so on. Here is a sample of their different visualizations:

With this kind of domain randomization, they were able to learn to rotate blocks. But they wanted to solve Rubik’s cube! The previous synthetic environment somehow did not lead to success on this task. There is a tradeoff in the use of synthetic data here: if the variance in environmental parameters is too big, so the environment is too different every time, it will be much harder for the algorithm to make any progress at all.
Therefore, in their next paper (Akkaya et al., 2019) the authors modified the synthetic environment and made it grow in complexity with time. That is, the parameters of synthetic data generation (size of the cube, friction forces and so on) are at first randomized within small ranges, and these ranges grow as training progresses:
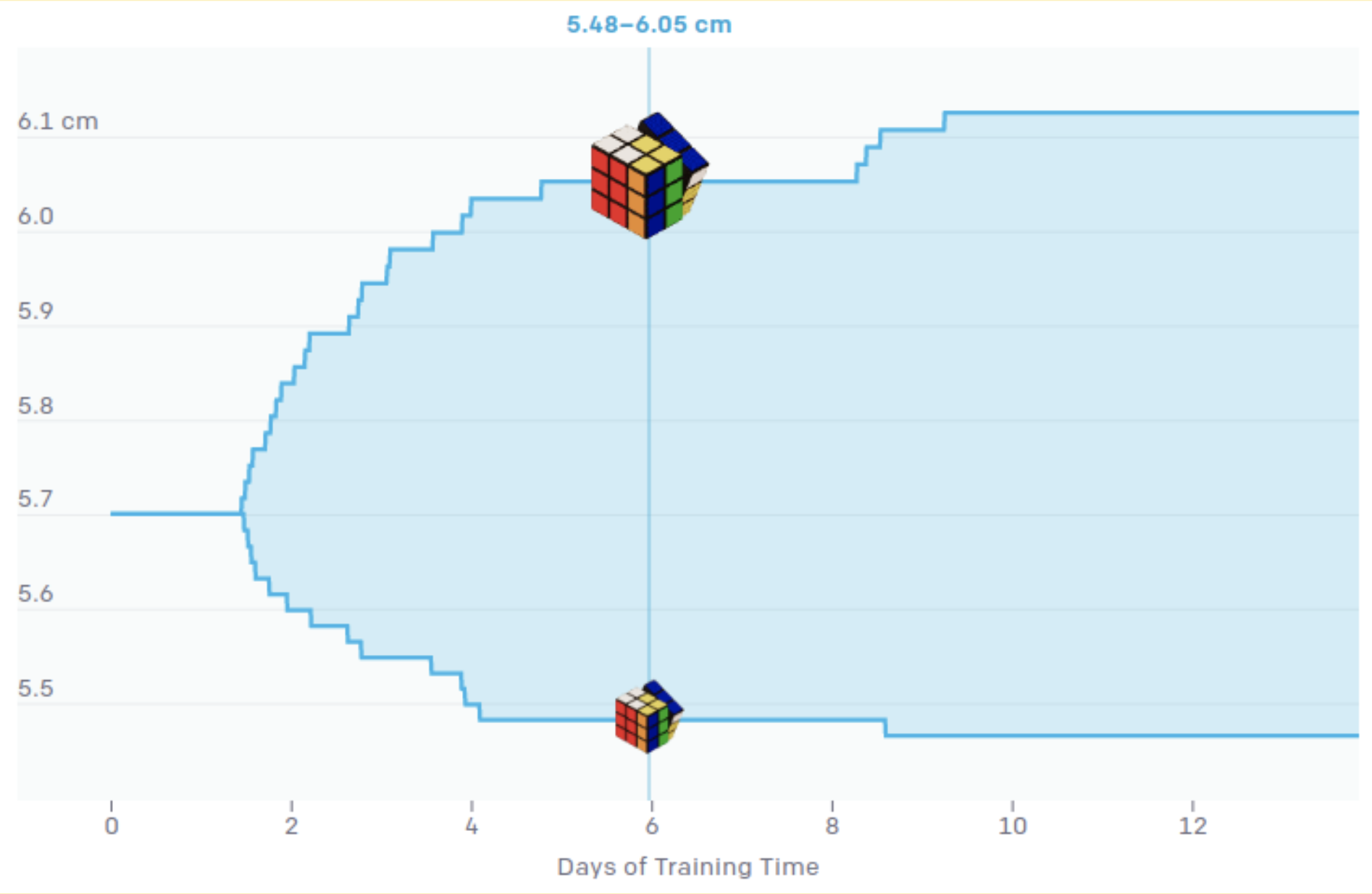
Source: https://openai.com/blog/solving-rubiks-cube/
This idea, which the OpenAI team called automatic domain randomization (ADR), is an example of the “closing the feedback loop” idea that we are pursuing here at Synthesis AI: make the results of the model trained on synthetic data drive the generation of new synthetic data. Note how even a small step in this direction—the feedback here is limited to overcoming a given threshold that triggers the next step in the curriculum of changing synthetic data parameters—significantly improves the results of the model. The resulting robotic hand is stable even to perturbations that had never been part of the synthetic environment; it is unfazed even by the notorious plush giraffe:

Source: https://openai.com/blog/solving-rubiks-cube/
So are we done with datasets in machine learning, then? Reinforcement learning seems to achieve excellent results and keeps beating state of the art with no labeled data at all or at the one-time expense of setting up the synthetic environment. Unfortunately, there is yet another catch here.
The problem, probably just as serious as the lack of labeled data, is the ever-growing amount of computation needed for further advances in reinforcement learning. To learn to play chess and Go, MuZero used 1000 third generation Google TPUs to simulate self-play games. This doesn’t tell us much by itself, but here is an interesting observation made by OpenAI (OpenAI blog, 2018; see also an addendum from November 2019). They noticed that before 2012, computational resources needed to train state of the art AI models grew basically according to Moore’s Law, doubling the computational requirements every two years. But with the advent of deep learning, in 2012-2019 computational resources for top AI training doubled on average every 3.4 months!
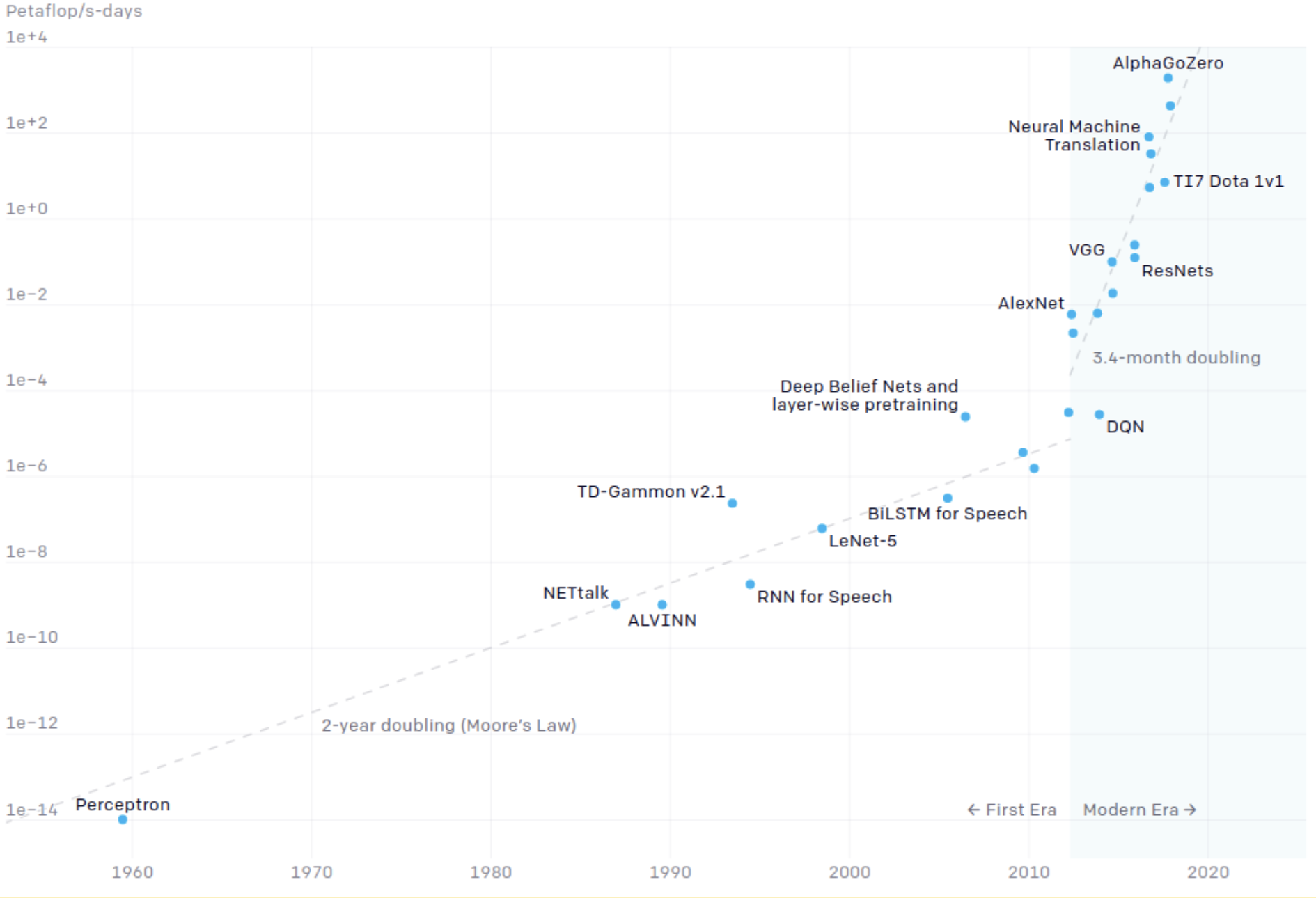
This is a huge rate of increase, and, obviously, it cannot continue forever, as the actual hardware computational power growth is only slowing down compared to Moore’s Law. The AlphaZero paper contains two experiments; the smaller one has been estimated to cost about $3 million to replicate on Google Cloud at 2019 prices, and the large experiment costs upwards of $30 million (Huang, 2019). While the cost of computation is dropping, it does so at a much slower rate than the increase of computation needed for AI.
Thus, one possible scenario for further AI development is that yes, indeed, this “brute force” approach might theoretically take us very far, maybe even to general artificial intelligence, but it would require more computational power than we actually have in our puny Solar System. Note that a similar thing, albeit on a smaller scale, happened with the second wave of hype for artificial neural networks: researchers in the late 1980s had a lot of great ideas about neural architectures (we had CNNs, RNNs, RL and much more), but neither the data nor the computational power was sufficient to make a breakthrough, and neural networks were relegated to “the second best way to do almost anything”.
Still, at present reinforcement learning represents another feasible way to trade labeled data for computation, as the example of AlphaGo blossoming into AlphaZero and MuZero clearly shows.
In this post, we have discussed a way to overcome the need for ever-increasing labeled datasets. In problems that can be solved by reinforcement learning, it often happens that the model either does not need labeled data at all or needs a one-time investment in a synthetic virtual environment. However, it turns out that successes in reinforcement learning come at a steep computational cost, perhaps too steep to continue even in the nearest future.
Next time, we will discuss another way to attack the data problem: using unlabeled datasets to inform machine learning models and help reduce the requirements for labeling. This will be the last preliminary post before we dive into the main topic of this blog and our company: synthetic data.
Sergey Nikolenko
Head of AI, Synthesis AI
