
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Today, we are kicking off the Synthesis AI blog. In these posts, we will speak mostly about our main focus, synthetic data, that is, artificially created data used to train machine learning models. But before we begin to dive into the details of synthetic data generation and use, I want to start with the problem setting. Why do we need synthetic data? What is the problem and are there other ways to solve it? This is exactly what we will discuss in the first series of posts.
Machine learning is hot, and it has been for quite some time. The field is growing exponentially fast, new models and new papers appear every week, if not every day. Since the deep learning revolution, for about a decade deep learning has been far outpacing other fields of computer science and arguably even science in general. Here is a nice illustration from Michael Castelle’s excellent post on deep learning:
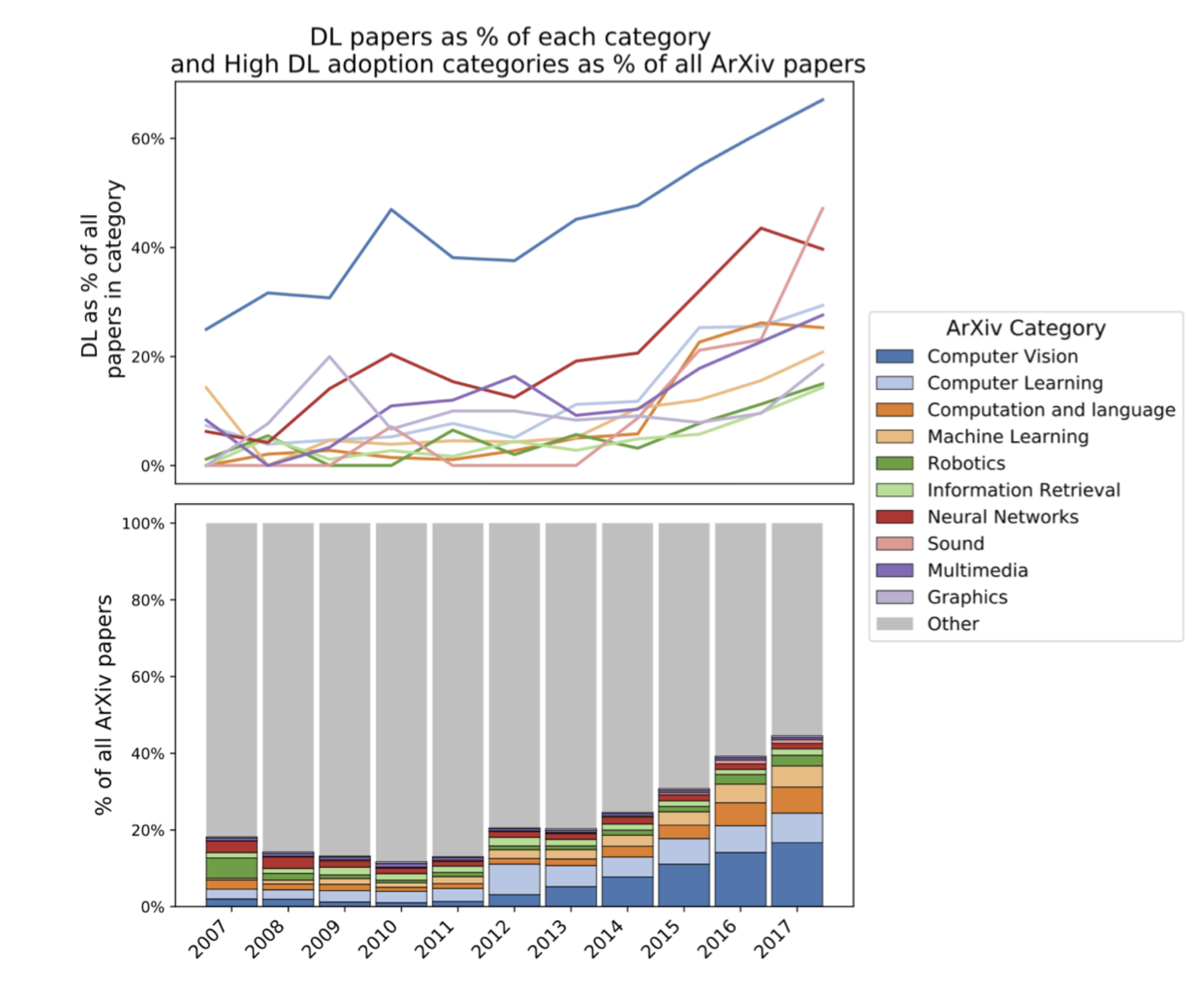
It shows how deep learning is taking up more and more of the papers published on arXiv (the most important repository of computer science research); the post was published in 2018, but trust me, the trend continues to this day.
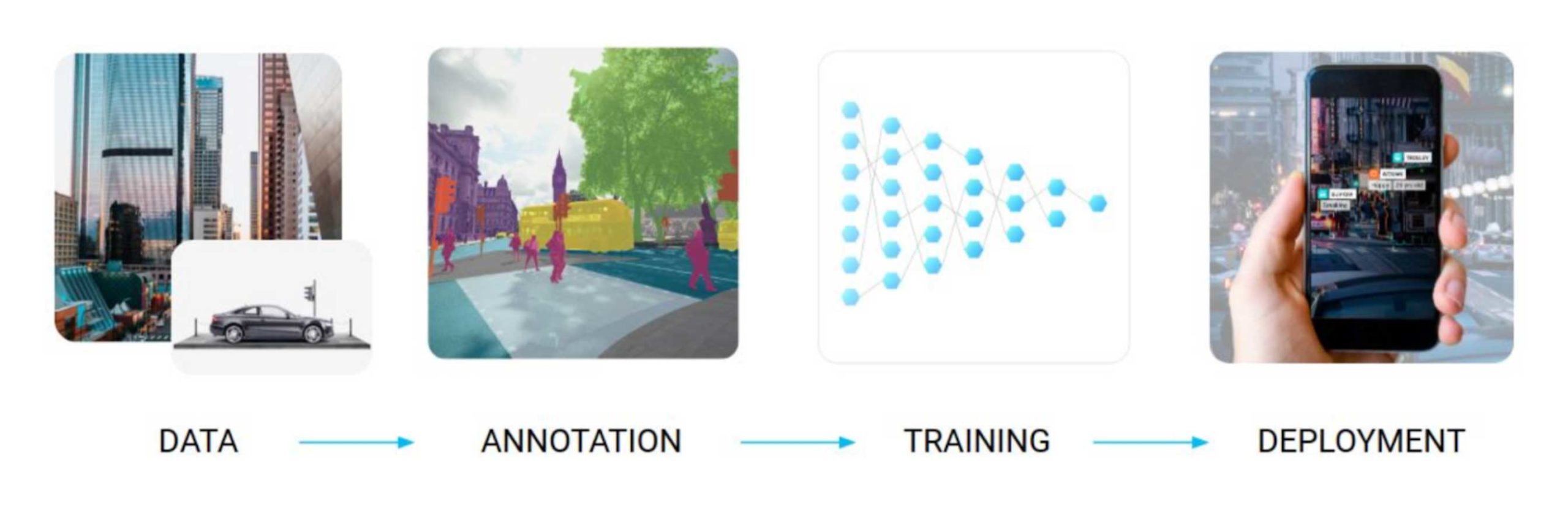
Still, the basic pipeline of using machine learning for a given problem remains mostly the same, as shown in the teaser picture for this post:
The vast majority of the thousands of papers published in machine learning deal with the “Training” phase: how can we change the network architecture to squeeze out better results on standard problems or solve completely new ones? Some deal with the “Deployment” phase, aiming to fit the model and run inference on smaller edge devices or monitor model performance in the wild.
Still, any machine learning practitioner will tell you that it is exactly the “Data” and (for some problems especially) “Annotation” phases that take upwards of 80% of any real data science project where standard open datasets are not enough. Will these 80% turn into 99% and become a real bottleneck? Or have they already done so? Let’s find out.
I don’t have to tell you how important data is for machine learning. Deep learning is especially data-hungry: usually you can achieve better results with “classical” machine learning techniques on a small dataset, but as the datasets grow, the flexibility of deep neural networks, with their millions of weights free to choose any kind of features to extract, starts showing. This was a big part of the deep learning revolution: even apart from all the new ideas, as the size of available datasets and the performance of available computational devices grew neural networks began to overcome the competition.
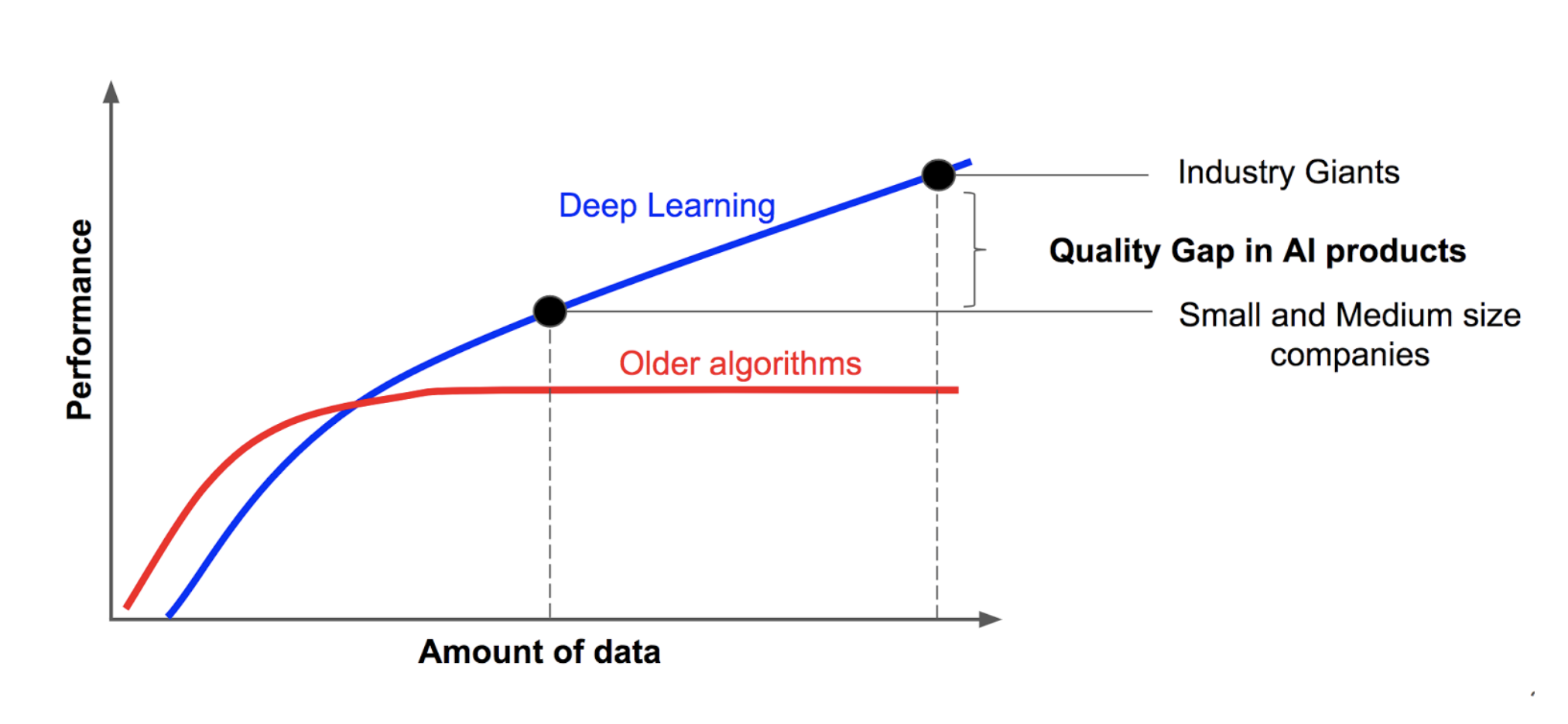
By now, large in-house datasets are a large part of the advantage that industry giants such as Google, Facebook, or Amazon have over smaller companies (image taken from here):
I will not tell you how to collect data: it is very problem-specific and individual for every problem domain. However, data collection is only the first step; after collection, there comes data labeling. This is, again, a big part of what separates industry giants from other companies. More than once, I had big companies tell me that they have plenty of data; and indeed, they had collected terabytes of important information… but the data was not properly curated, and most importantly, it was not labeled, which immediately made it orders of magnitude harder to put to good use.
Throughout this series, I will be mostly taking examples from computer vision. For computer vision problems, the labeling required is often very labor-intensive. Suppose that you want to teach a model to recognize and count retail items on a supermarket shelf, a natural and interesting idea for applying computer vision in retail; here at Synthesis AI, we have had plenty of experience with exactly this kind of projects.
Since each photo contains multiple objects of interest (actually, a lot, often in the hundreds), the basic computer vision problem here is object detection, i.e., drawing bounding boxes around the retail items. To train the model, you need a lot of photos with labeling like this:

If we also needed to do segmentation, i.e., distinguishing the silhouettes of items, we would need a lot of images with even more complex labeling, like this:

Imagine how much work it is to label a photo like this by hand! Naturally, people have developed tools to help partially automate the process. For example, a labeling tool will suggest a segmentation done by some general-purpose model, and you are only supposed to fix its mistakes. But it may still take minutes per photo, and the training set for a standard segmentation or object detection model should have thousands of such photos. This adds up to human-years and hundreds of thousands, if not millions, of dollars spent on labeling only.
There exist large open datasets for many different problems, segmentation and object detection included. But as soon as you need something beyond the classes and conditions that are already well covered in these datasets, you are out of luck; ImageNet does have cows, but not shot from above with a drone.
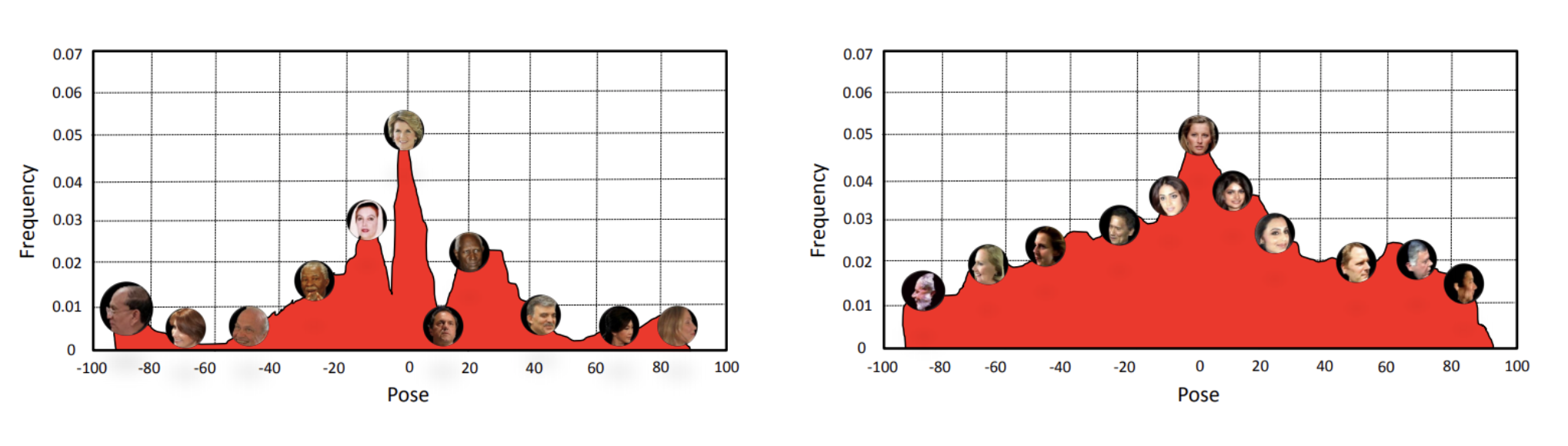
And even if the dataset appears to be tailor-made for your problem, it can contain dangerous biases. For example, suppose you want to recognize faces, a classic problem with large-scale datasets freely available. But if you want to recognize faces “in the wild”, you need a dataset that covers all sorts of rotations for the faces, while standard datasets mostly consist of frontal pictures. In the picture below, taken from (Zhao et al., 2017), on the left you see the distribution of face rotations in IJB-A (a standard open large-scale face recognition dataset), and the picture on the right shows how it probably should look if you really want your detection to be pose-invariant:
To sum up: current systems are data-intensive, data is expensive, and we are hitting the ceiling of where we can go with already available or easily collectible datasets, especially with complex labeling.
So what’s next? How can we solve the data problem? Is machine learning heading towards a brick wall? Hopefully not, but it will definitely take additional efforts. In this series of posts, we will find out what researchers are already doing. Here is a tentative plan for the next installments, laid out according to different approaches to the data problem:
Let’s summarize. We have seen that modern machine learning is demanding larger and larger datasets. Collecting and especially labeling all this data becomes a huge task that threatens future progress in our field. Therefore, researchers are trying to find ways around this problem; next time, we will start looking into these ways!
Sergey Nikolenko
Head of AI, Synthesis AI
