
Do Androids Dream? World Models in Modern AI
One of the most striking AI advances this spring...
In the previous post, we posed what we consider the main problem of modern machine learning: increasing appetite for data that cannot be realistically satisfied if current trends persist. This means that current trends will not persist — but what is going to replace them? How can we build machine learning systems at ever increasing scale without increasing the need for huge hand-labeled datasets? Today, we consider one possible answer to this question: one-shot and zero-shot learning.

Image source: https://www.behance.net/gallery/6016079/ZERO-TO-HERO
Consider a face recognition system. For simplicity, let’s assume that our system is a face classifier so that we do not need to worry about object detection, bounding box proposals and all that: the face is already pre-cut from a photo, and all we have to do is recognize the person behind that face.
A regular image classifier consists of a feature extraction network followed by a classification model; in deep learning, the latter is usually very simple, and feature extraction is the interesting part. Like this (image source):
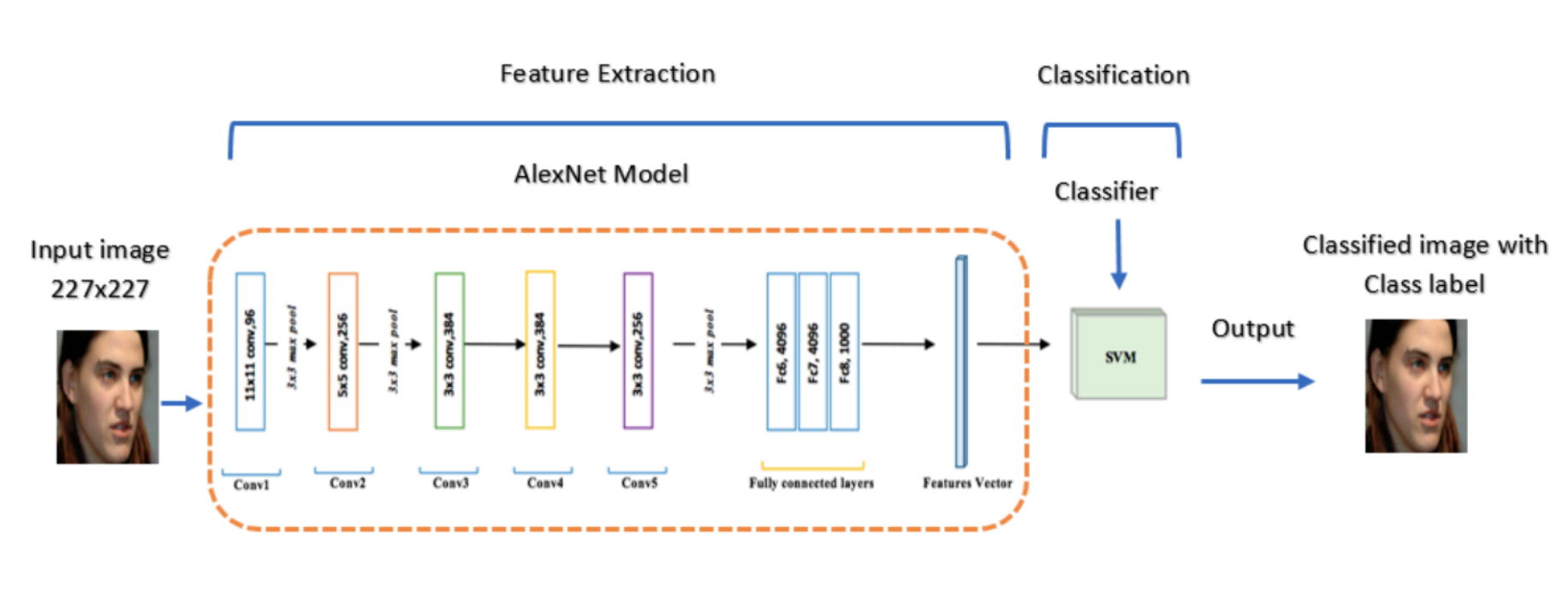
So now we train this classifier on our large labeled dataset of faces, and it works great. But wait: where do the labeled samples come from? Sure, we can assume that a large labeled dataset of some human faces is available, but a face recognition system needs to do more: while it’s okay to require a large dataset for pretraining, a live model needs to be able to recognize new faces.
How is this use case supposed to work? Isn’t the whole premise of training machine learning models that you need a lot of labeled data for each class of objects you want to recognize? But if so, how can a face recognition system hope to recognize a new face when it usually has at most a couple of shots for each new person?
The answer is that face recognition systems are a bit different from regular image classifiers. Any machine learning system working with unstructured data (such as photos) is basically divided into two parts: feature extraction, the part that converts an image into a (much smaller) set of numbers, often called an embedding or a latent code, and a model that uses extracted features to actually solve the problem. Deep learning is so cool because neural networks can learn to be much better at feature extraction than anything handcrafted that we had been able to come up with. In the AlexNet-based classifier shown above, the hard part was the AlexNet model that extracts features, and the classifier can be any old model, usually simple logistic regression.
To get a one-shot learning system, we need to use the embeddings in a different way. In particular, modern face recognition systems learn face embeddings with a different “head” of the network and different error functions. For example, FaceNet (Schroff et al., 2015) learns with a modification of the Siamese network approach, where the target is not a class label but rather the distances or similarities between face embeddings. The goal is to learn embeddings in such a way that embeddings of the same face will be close together while embeddings of different faces will be clearly separated, far from each other (image source):
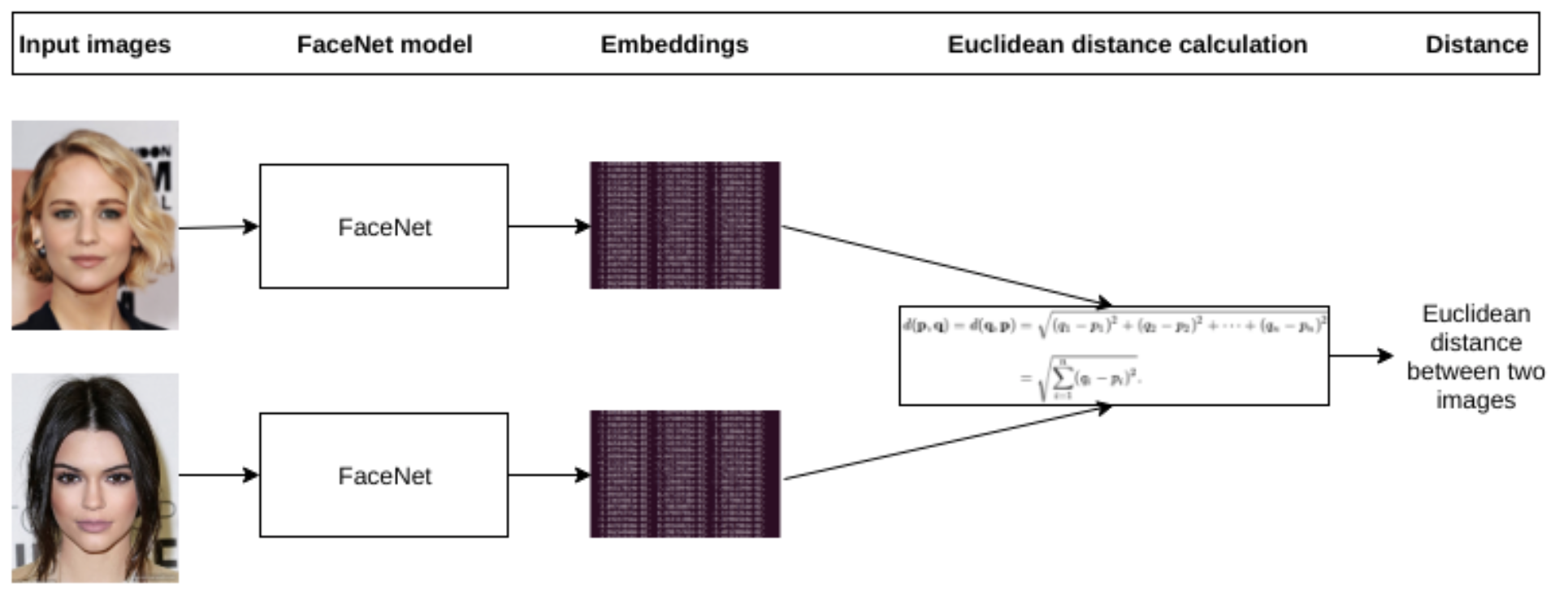
The “FaceNet model” in the picture does feature extraction. Then to compute the error function you compute the distance between two embedding vectors. If the two input faces belong to the same person, you want the embedding vectors to be close together, and if they are different people, you want to push the embeddings together. There is still some way to go from this basic idea before we have a usable error function, but this will suffice for a short explanation. Here is how FaceNet works as a result; in the picture below, the numbers between photos of faces correspond to the distances between their embedding vectors (source):

Note that the distances between two photos of the same guy are consistently smaller than distances between photos of different people, even though in terms of pixels, composition, background, lighting, and basically everything else except for human identity the pictures in the columns are much more similar than pictures in the rows.
Now, after you have trained a model with these distance-based metrics in mind, you can use the embeddings to do one-shot learning itself. Assuming that a new face’s embedding will have the same basic properties, we can simply compute the embedding for a new person (with just a single photo as input!) and then do classification by looking for nearest neighbors in the space of embeddings.
We have seen a simplified but relatively realistic picture of how one-shot learning systems work. But one can go even further: what if there is no data at all available for a new class? This is known as zero-shot learning.
The problem sounds impossible, and it really is: if all you know are images from “class 1” and “class 2”, and then you are asked to distinguish between “class 3” and “class 4”, no amount of machine learning can help you. But real life does not work this way: we usually have some background knowledge about the new classes even if we don’t have any images. For example, when we are asked to recognize a “Yorkshire terrier”, we know that it’s a kind of dog, and maybe we even have its verbal description, e.g., from Wikipedia. With this information, we can try to learn a joint embedding space for both class names and images, and then use the same nearest neighbors approach but look for the nearest label embedding rather than other images (which we have none for a new class). Here is how Socher et al. (2013) illustrate this approach:
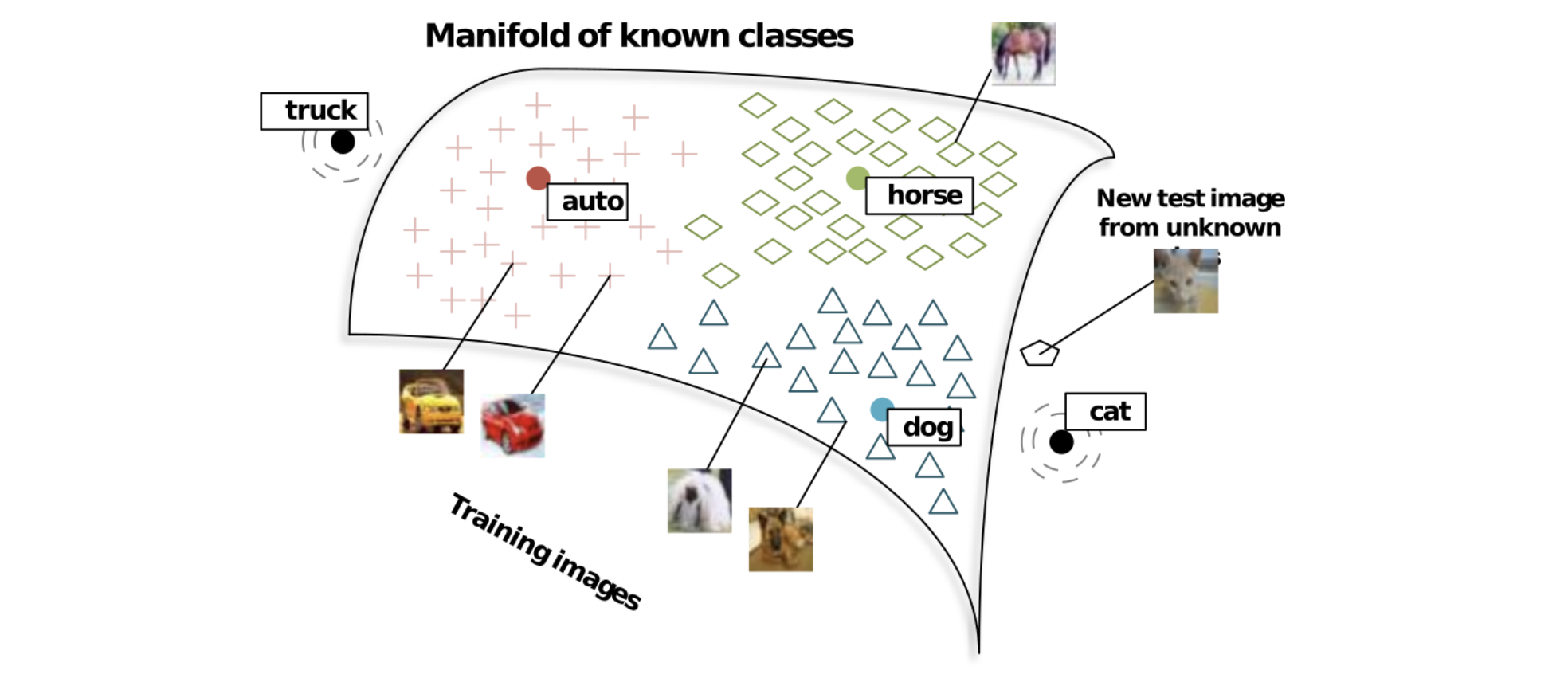
Naturally, this won’t give you the same kind of accuracy as training on a large labeled set of images, but systems like this are increasingly successful.
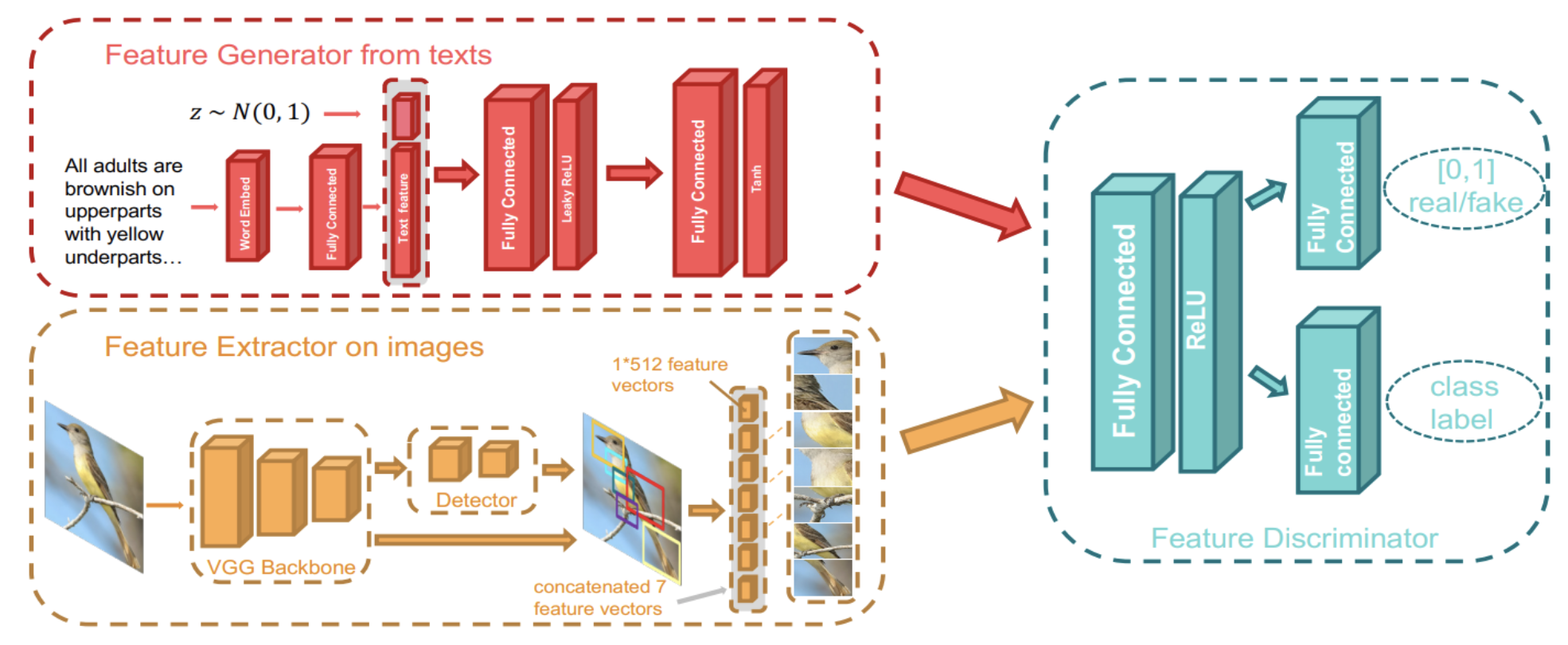
Many zero-shot learning models use generative models and adversarial architectures. One of my favorite examples is a (more) recent paper by Zhu et al. (2018) that uses a generative adversarial network (GAN) to “hallucinate” images of new classes by their textual descriptions and then extracts features from these hallucinated images:
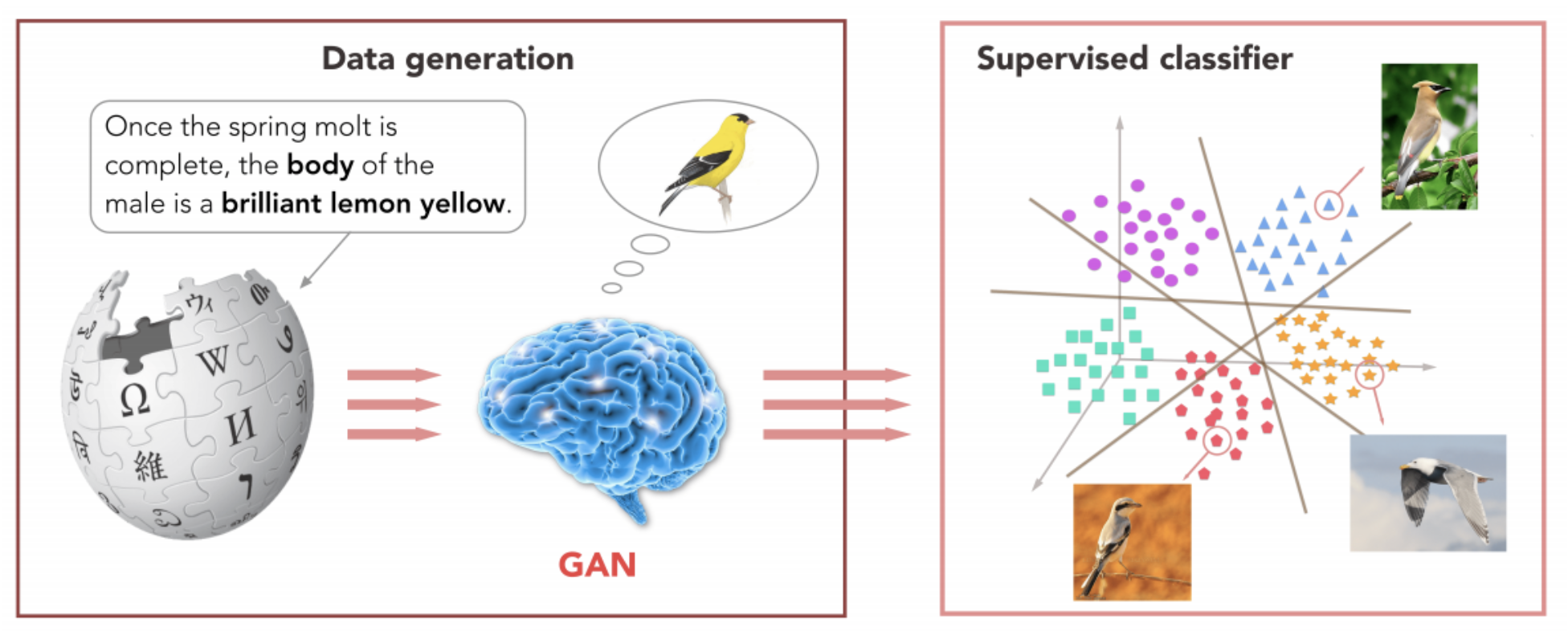
The interesting part here is that they do not need to solve the extremely complex and fragile problem of generating high-resolution images of birds that only the very best of GANs can do (such as, e.g., BigGAN and its successors). They train a GAN to generate not images but rather feature vectors, those very same joint embeddings, and this is, of course, a much easier problem. Zhu et al. use a standard VGG architecture to extract features from images and train a conditional GAN to generate such feature vectors given a latent vector of textual features extracted from the description:
As a result, you can do extremely cool things like zero-shot retrieval: doing an image search against a database without any images corresponding to your query. Given the name of a bird, the system queries Wikipedia, extracts a textual description, uses the conditional GAN to generate a few vectors of visual features for the corresponding bird, and then looks for its nearest neighbors in the latent space among the images in the database. The results are not perfect but still very impressive:
Note, however, that one- and zero-shot learning still require large labeled datasets. The difference is that we don’t need a lot of images for new classes any more. But the feature extraction network has to be trained on similar labeled classes: a zero-shot approach won’t work if you train it on birds and then try to look for a description of a chair. Until we have an uber-network trained on every kind of images possible (and believe me, we still have quite a way to go before Skynet enslaves the human race), this is still a data-intensive approach, although restrictions on what kind of data to use are relaxed.
In this post, we have seen how one-shot and zero-shot learning can help by drastically reducing the need for labeled datasets in the context of:
But we have also seen that all of these approaches still need a large dataset to begin with. For exampe, a one-shot learning model for human faces needs to have a large labeled dataset of human faces to work, and only then we can add new people with a single photo. A zero-shot model that can hallucinate pictures of birds based on textual descriptions needs a lot of descriptions paired with images before it is able to do its zero-shot magic.
This is, of course, natural. Moreover, it is quite possible that at some point of AI development we will already have enough labeled data to cover entire fields such as computer vision or sound processing, extending their capabilities with one-shot and zero-shot architectures. But while we are not at that point yet, and there is no saying whether we can reach it in the near future, we need to consider other methods for alleviating the data problem. In the next installment of this series, we will see how unlabeled data can be used in this regard.
Sergey Nikolenko
Head of AI, Synthesis AI
