
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Although deep learning is a very new branch of computer science, foundations of neural networks have been in place since the 1950s: we have been training directed graphs composed of artificial neurons (perceptrons), and each individual neuron has always looked like a linear combination of inputs followed by a nonlinear function like ReLU. In April 2024, a new paradigm emerged: Kolmogorov-Arnold networks (KAN) work on a different theoretical basis and promise not only a better fit for the data but also much improved interpretability and an ability to cross over to symbolic discoveries. In this post, we discuss this paradigm, what the main differences are, and where KAN can get us right now.
One surprising feature of artificial neural networks is that they basically have not changed since 1943, when Warren McCulloch and Walter Pitts published their seminal paper, “A logical calculus of the ideas immanent in nervous activity”. Already in this paper, before even the Turing test, let alone the Dartmouth seminar (1956) and the first machine learning models, neurons were modeled as linear combinations of inputs with nonlinear activation functions:

This is indeed a very reasonable approximation to what real neurons do, if you try to measure the frequency of spikes as a function of the neuron’s inputs. The function h has to be nonlinear if you want to have a network of neurons, because otherwise the whole network would be a composition of linear functions, so it would be just equivalent to a single neuron.
In the early days of artificial intelligence, the nonlinearity h was usually the threshold function (Heaviside step function for the mathematically inclined): 1 if the input exceeds some threshold a and 0 otherwise. Later, researchers realized that you can’t really train a deep network with threshold activation functions: their derivatives are zero almost everywhere, and gradient descent does not work, so they switched to sigmoidal functions such as the logistic sigmoid and the hyperbolic tangent, which in essence represent “soft” differentiable versions of the threshold. Later yet, ReLU showed that just a little bit of nonlinearity suffices, and by now we also have functions found by automated search such as the Swish (Ramachandran et al., 2017) or its generalization, the ACON family (Ma et al., 2020).
I will not go into more details here. The important thing for us now is that throughout the entire history of neural networks, only the exact form of the nonlinearity has changed. The basic construction of neural networks has remained the same: it is a huge composition of neurons, and each neuron is a linear combination of inputs followed by a nonlinearity. There exist other types of nodes in the computation graph—for example, the batch normalization layer also has trainable weights but it is a different function—but the vast majority of neurons in any modern network look like the picture above. For example, the self-attention layer in a Transformer, which we have discussed previously, does quite a few interesting things with queries, keys, and values, but these vectors are still linear combinations of input embeddings with trainable coefficients.
This idea is known as connectionism: a large network of small simple units can represent very complex things in combination. Philosophically speaking, connectionism makes claims about cognitive processes, saying that our mental phenomena also can arise from a large composition of simple individual neurons. Here, connectionism has been historically at odds with computationalism, which says that the mind works by conducting formal operations on symbols, like an abstract computer (a Turing machine of sorts). There is no direct contradiction between the two—formal operations can be implemented on a large network of units—but there was still an interesting debate left: how would a connectionist theory of mind explain the logical properties of human cognition such as systematic relations in language cognition or compositionality of mental representations? There exist interesting answers to this question, and I will leave a couple of links to book overviews for the interested reader (Bechtel, Abrahamsen, 2002; Marcus, 2003; Maurer, 2021).
We will return to connectionism vs. computationalism later, but, fortunately, we do not have to dive deep into the philosophical or neurobiological aspects of this debate. All that matters to us, lowly computer scientists, are the mathematical and algorithmic sides of the question: what kinds of functions can one represent with compositions of simple ones, which “simple” functions are needed exactly, and how can we find them and the necessary composition?
Neural networks work because even while each neuron is a very simple construction, their compositions can approximate any (continuous) function, with any given precision. Results of this class are known as universal approximation theorems. Specifically for neural networks, several such results were obtained in the late 1980s. In 1988, George Cybenko proved that neural networks with a single hidden layer and sigmoidal activations can approximate any continuous function (Cybenko, 1988). Concurrently with him, Hornik et al. (1989) developed a more general treatment, showing that feedforward networks with one hidden layer can approximate any real-valued continuous function over a compact set, even extending the result to measurable functions. This result was shown for “squashing” activation functions, that is, sigmoids—non-decreasing functions that go from 0 on the left to 1 on the right—but later Hornik (1991) extended it to other classes of activation functions.
Note that these are classical existence results that give a nice reassurance that approximations exist for but do not actually guarantee that you can find it in reasonable time. Moreover, they do not constrain the size of the approximating neural network, and indeed, to approximate a complicated function with a network with a single hidden layer you might need exponentially many neurons.
There exists an entire research direction proving extensions of these results to neural networks with various numbers of neurons, to deeper networks, bounding the approximation errors and so on, with many interesting and beautiful mathematical results. For example:
But for today’s topic, instead of going further to recent results and considering the state of the art in universal approximation, we need to take a step back into the 1950s.
Andrey Kolmogorov was one of the most prolific mathematicians of all time, a rival of Euler and Gauss. He introduced the modern axiomatics of probability theory, generalized the law of large numbers, introduced a new notion of an algorithm and founded the theory of Kolmogorov complexity, created chaos theory in the famous Kolmogorov–Arnold–Moser (KAM) theorem, and much more. He revolutionized Soviet mathematical education, establishing some of the best mathematical schools in the world. While sometimes he had to do some questionable things (e.g., participated in the campaign against his former teacher Nikolai Luzin in the 1930s), he actually managed to navigate the Soviet ideological landscape perfectly, never losing his integrity and protecting other people whenever he could (see “The Kolmogorov Option” by Scott Aaronson).
Vladimir Arnold was a pupil of Kolmogorov and a brilliant mathematician in his own right. Compared to Kolmogorov, Arnold gravitated more towards the continuous side of mathematics related to physics, including dynamical systems, stability theory and the above-mentioned KAM theorem, catastrophe theory, fluid dynamics, and much more; in “pure” mathematics Arnold worked in algebraic geometry and topology, also always trying to connect pure mathematics with real world applications. Like his teacher, Arnold was a key figure in Soviet mathematical education, authoring many textbooks and popular texts. He was very annoyed by the formal style of mathematical education originating in the writings of the Bourbaki group, and always advocated for an education that would provide a deeper understanding of the studied phenomena and connect the dots in different fields whenever possible.
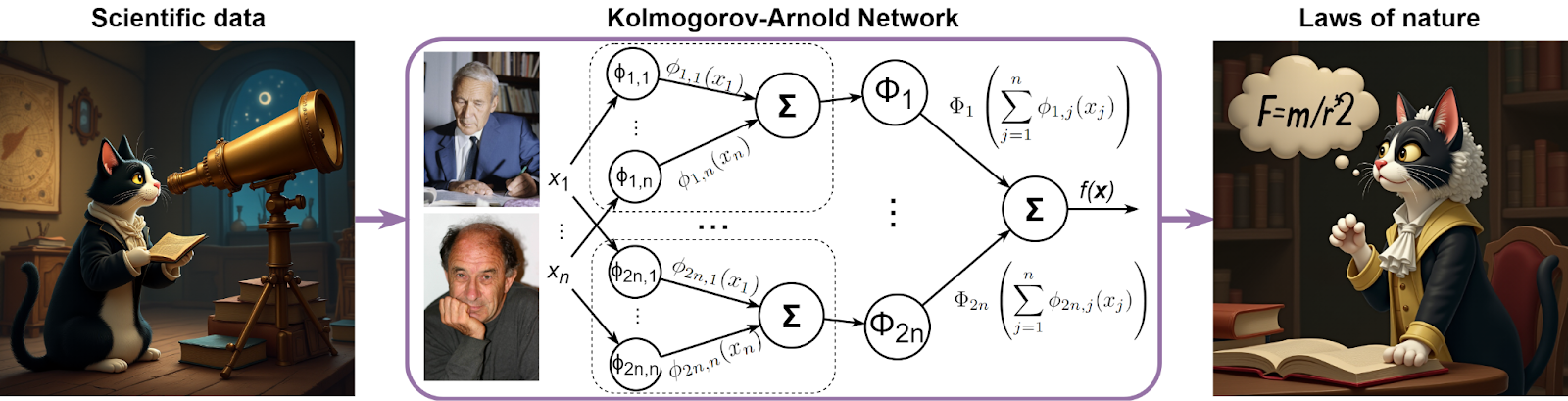
Kolmogorov and Arnold collaborated a lot, especially in the early stages of Arnold’s career when he was Kolmogorov’s student. The theorem we are interested in was published in 1957, when Arnold was only 20 years old. It says that any continuous function f of n variables can be represented as the following composition:

Here Φi and ɸi,j are arbitrary functions of a single variable, and the theorem says that this is enough: to represent any continuous function, you only need to use sums of univariate functions in a two-layered composition:
This means that if you need to represent a multivariate function of high input dimension, which is what any machine learning model is doing, it would be sufficient to find several functions of one variable. The only multivariate function you need is the sum, the rest can be pushed to univariate components.
If you think about it in terms of learning the functions, it means that the Kolmogorov–Arnold theorem gives a way around the curse of dimensionality, the reason why machine learning is hard and often counterintuitive. In low dimensions, every machine learning problem is easy: you can take any integral numerically, nearest neighbors are indeed close by and relevant, you can cover a reasonably sized part of the space with samples from the uniform or normal distribution—everything works great. In high dimensions, volumes grow exponentially, nearest neighbors grow apart, and integrals become impossible to find with any reasonable accuracy; this is exactly the reason why machine learning needs strong assumptions and complicated methods such as MCMC sampling. The term dates back to Richard Bellman (1957) who noted that dynamic programming also becomes very computationally hard in high dimensions; for a more detailed discussion of the curse of dimensionality, see, e.g., Marimont and Shapiro (1979) and Beyer et al. (1999).
Moreover, the theorem also gives you the exact number of functions in each sum: the summation limits n and 2n refer to the same n which is the dimension of x. Compare this to exponential bounds on the number of neurons with sigmoidal activations that we mentioned earlier, and the Kolmogorov–Arnold theorem begins to sound quite tempting to use in machine learning, right? Unfortunately, the theorem itself does not give you any idea of how to find the functions Φi and ɸi,j; we will discuss this problem in the next section.
I will close this section with another interesting mathematical tidbit. As you have probably heard, in 1900 David Hilbert, a great mathematician and a founder of mathematical logic, compiled a list of 23 so-called Hilbert’s problems. They were unsolved problems that Hilbert believed to be important for the development of mathematics, and his intuition was completely right: although some problems turned out to be either relatively easy or too vague to judge, many of them led to the development of entire new fields of mathematics. One of the still standing Hilbert’s problems, proving Riemann’s hypothesis, also made the list of the Millenium Prize Problems by the Clay Mathematics Institute, an update on Hilbert’s idea for the new century.
As it turns out, the Kolmogorov–Arnold representation theorem arguably solves one of Hilbert’s problems, namely the thirteenth problem. It was already known to Hilbert that any seventh-degree equation can be reduced to the form
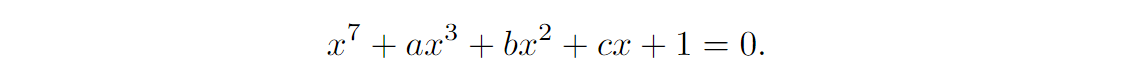
It seemed to be impossible to reduce this equation further, so it was a tempting hypothesis for Hilbert that the seventh-degree equation gives you an irreducible algebraic function, in the sense that you cannot reduce it to a superposition of functions of fewer variables. The Hilbert’s Thirteenth Problem is thus as follows:
Consider a seventh-degree equation in the reduced form as above. Its solution is a function of three variables: the coefficients a, b, and c. Can it be expressed as a composition of a finite number of two-variable functions?
This problem was originally posed for algebraic functions, i.e., functions that can be defined as a root of a polynomial equation, but later Hilbert asked a version of this problem about arbitrary continuous functions. Kolmogorov and Arnold were actually working on this problem, and they solved it in several steps, gradually reducing the number of variables required for elementary functions: first Kolmogorov showed that any continuous function can be represented as a composition of function of three variables, then his student Arnold reduced it to two (already solving Hilbert’s problem), and then came their main theorem.
For the continuous version of Hilbert’s Thirteenth, the Kolmogorov–Arnold representation theorem is actually an overkill: it turns out that we only need arbitrary continuous functions of one variable and addition, which is technically a two-variable function. Note, however, that the algebraic version still remains unsolved: Arnold himself returned to it later with Goro Shimura (in the proceedings of a 1976 symposium on the legacy of Hilbert’s problems), but the efforts of mathematicians have not been successful so far (Vitushkin, 2004).
As we have seen above, the Kolmogorov–Arnold representation theorem is purely existential; the original result does not give you a good way to find the univariate functions. There have been several attempts to give a constructive proof that would provide an algorithm for finding these functions (Sprecher, 1965; Sprecher, 1972; Braun, Griebel, 2009), but these attempts were hardly practical from a machine learning standpoint.
Moreover, there have been negative results showing that univariate functions in the theorem can be very complex, even fractal, and learning them can be very hard; one of these results even says “Kolmogorov’s theorem is irrelevant” right in the title (Girosi, Poggio, 1989). So how could the KAN approach find univariate functions in the Kolmogorov-Arnold representation efficiently?
There have been earlier approaches to build neural networks based on the Kolmogorov–Arnold representation theorem. Hecht-Nielsen (1987) and Lin and Unbehauen (1993) noted that the theorem, specifically in its constructive form by Sprecher (1965), leads to natural constructions of three-layer neural networks; see also (Sprecher, Draghici, 2002). Köppen (2002) developed an algorithm for learning the Sprecher representation.
However, these algorithms remained impractical for two reasons: first, because learning the univariate functions was still too hard, and second, because the shallow three-layer architecture required special algorithms to train and could not be trained by simple gradient descent. Let us begin with the first constraint.
To make univariate functions easier to learn, various approaches to making the Kolmogorov–Arnold representation theorem practical centered on splines. Splines (Bartels et al., 1995; Shumaker, 2015) are piecewise polynomial functions used to approximate or interpolate other functions. The key idea is that instead of using a single complex function to fit all data across the entire domain, a spline breaks the domain into smaller intervals and fits a much simpler function (usually a low-degree polynomial) to each interval. These polynomial pieces are smoothly connected at certain points called knots.
If we use splines for univariate polynomial regression, formally it means that we consider the interval [a, b] where the data points lie and break it down with intermediate points ti, the knots, getting k intervals:


The task is to find a polynomial pi of degree d on each interval, pi: [ti, ti+1] →ℝ, so that:
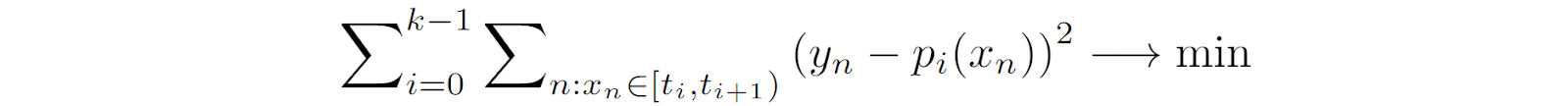
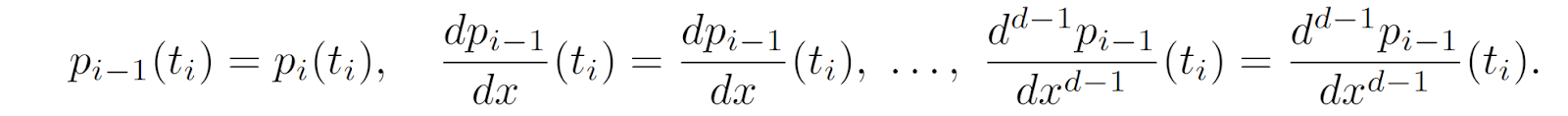
The main difference between splines and just piecewise interpolation lies in this last condition: splines impose additional constraints to make the connections continuous and even smooth. For example, if I plot three segments of data and try to learn quadratic or cubic regression on each, the results will follow the data but it will be three independent discontinuous curves (thin curves in the plot below). A spline regression would make the curves meet each other in the knots, and, moreover, meet each other smoothly, with matching derivatives (thick curves in the plots below):
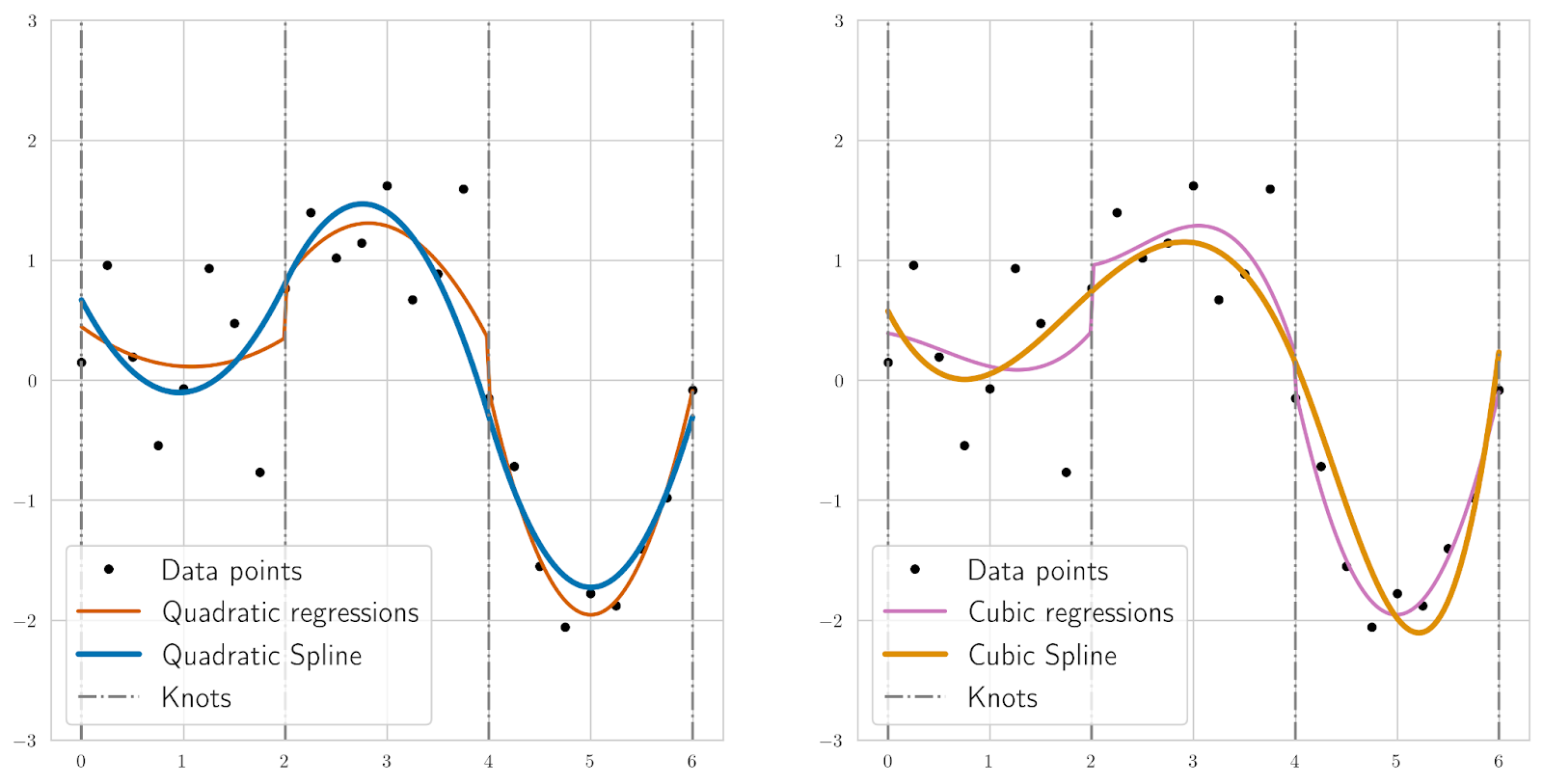
There is a rich field of applied mathematics on splines; they are often used for interpolation, i.e., to make a smooth curve that goes near all given points rather than approximating a least squares polynomial regression. The splines shown above are actually learned linear combinations of B-splines, i.e., polynomials that can serve as basis functions for splines of a given degree; there exist algorithms to compute B-splines for a given degree and knot points (Gordon, Riesenfeld, 1974; de Boor, 1977; Lee, 1982); these algorithms, in particular the de Boor–Cox iteration (de Boor, 1972; Cox, 1972), are relatively efficient but become computationally hard for large numbers of knots, and we will return to this discussion later. This is also adjacent to the discussion of Bezier curves that are a special case of B-splines. I will not go into more details about splines and will refer to the numerous existing books and material on the subject (Bartels et al., 1995; Gallier, 1999; Shumaker, 2015; Hovey, 2022).
Splines provide a natural algorithm to learn smooth functions in a very expressive way; by changing the degree and number of knots we can freely change the number of parameters in a polynomial spline, from a piecewise linear function up to literally an interpolation polynomial for the data points. However, splines become much harder to use in high dimensions, so it would not be a good idea to replace regression models with splines. But the Kolmogorov-Arnold theorem removes the need for high dimensions altogether! Therefore, it is no wonder that splines caught the attention of researchers looking for efficient univariate functions to use in the Kolmogorov-Arnold representation.
Leni et al. (2013) developed what was called a Kolmogorov spline network. Fakhoury et al. (2022) presented ExSpliNet, a neural network architecture based on B-splines. An even more interesting direction would be to change activation functions into learnable splines: after all, ReLU is just a linear spline with two components. Campolucci et al. (1996) and Guarneri et al. (1999) explored this idea back in the 1990s, and they were already building upon Jerome Friedman’s adaptive spline networks (Friedman, 1991). More recently, this approach has been developed by Scardapane et al. (2018) and Bohra et al. (2020).
But somehow, these ideas have not made any splash in the deep learning world before very recently. Kolmogorov–Arnold networks also use learnable activation functions based on splines. What is the difference here, what are the new ideas, and why have KAN attracted significant attention in 2024?
The first KAN paper (Liu et al., 2024) begins with a natural question: “are multilayer perceptrons the best nonlinear regressors we can build?” They begin by comparing the Kolmogorov–Arnold representation with usual multilayer perceptrons and note that they can make the former deeper and/or wider than the theorem suggests, which may help make individual univariate functions simpler. Here is the teaser image by Liu et al. (2024) that makes this comparison:
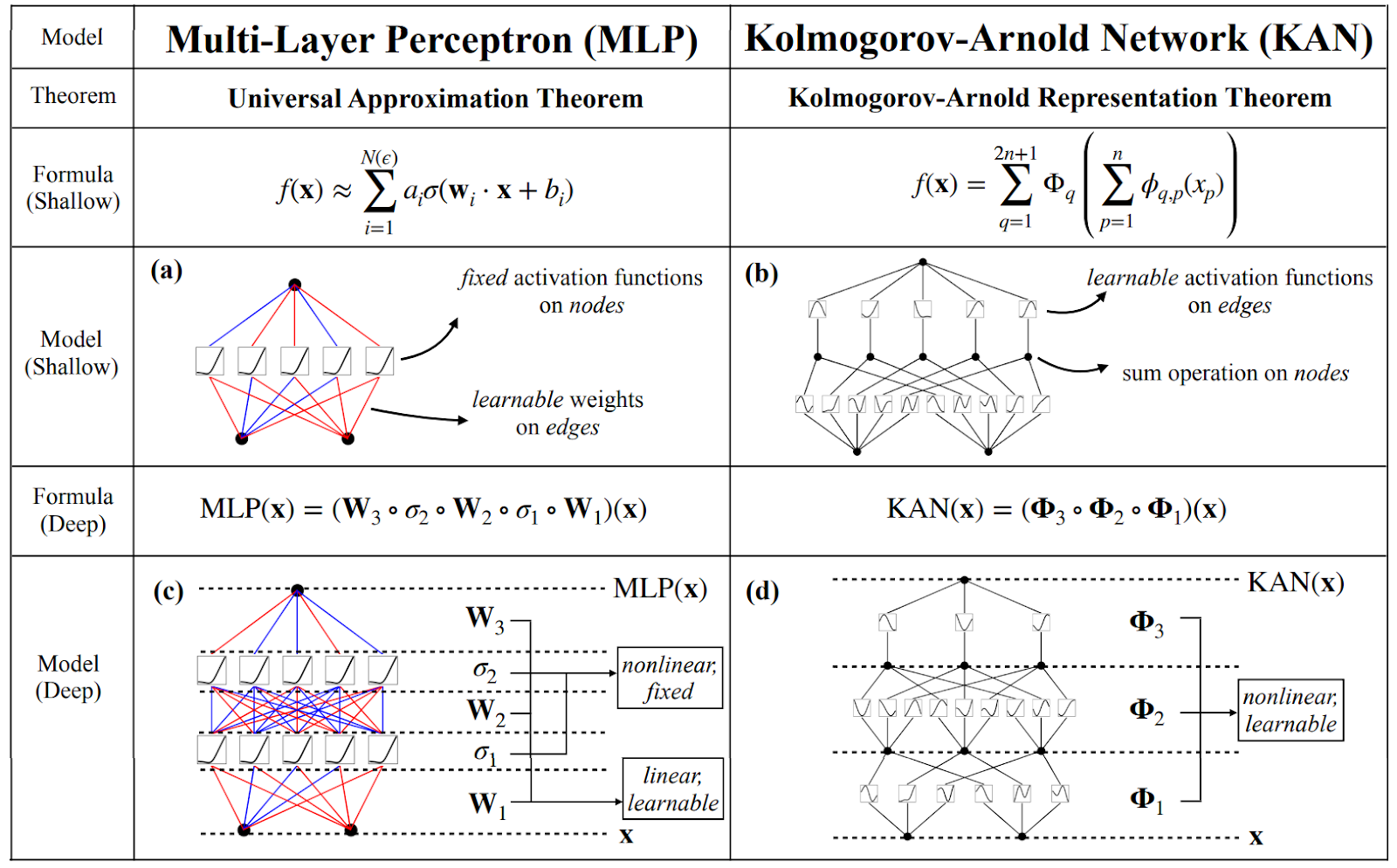
They define a “KAN layer” with n inputs and m outputs as an n⨉m matrix Φ of one-dimensional functions with trainable parameters: the m-th output is the sum of the results of the n functions in the corresponding row. The original Kolmogorov–Arnold representation consists of two such layers: first, n inputs turn into 2n+1 outputs via ɸi,j functions, and then Φi combine 2n intermediate values into a single output. When you look at the representation like this, it becomes clear how to stack more such layers, making a deeper KAN that represents a composition of such matrices of functions:
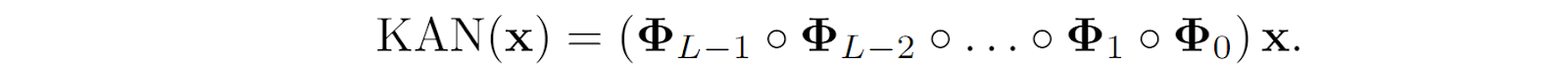
This is a very general representation; for example, a feedforward neural network (a multilayer perceptron) can also be represented as a KAN with linear functions (weight matrices) interleaved with activation functions (applied componentwise, so in the notation above it would be a diagonal matrix of functions):
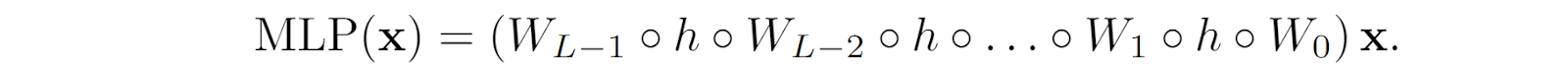
On each KAN layer, every transformation function ɸ is introduced by Liu et al. (2024) as a weighted sum of a basis function b and a spline function s,
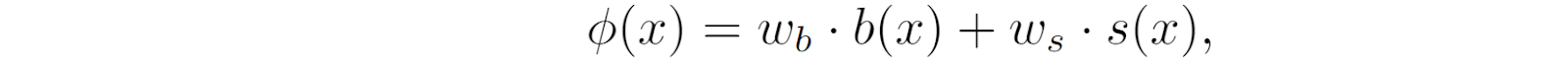
where b is the sigmoid linear unit (SiLU) activation function and s is a B-spline:
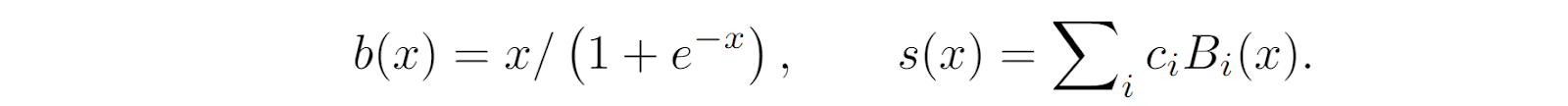
As a result, every KAN layer has O(n2(G+k)) parameters, where n is the number of inputs and outputs, k is the degree of the spline, and G is the number of knots. Liu et al. (2024) discuss a lot of design choices and other aspects of KANs but at this point, let us proceed to an example, which I adapted from this tutorial.
Let us begin with a nontrivial function that we want to approximate by a KAN; let’s take one of the functions used in the original paper:
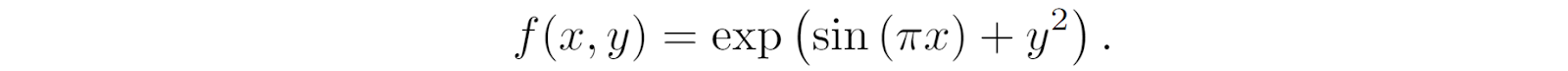
To get a feeling for what this function looks like, the figure below shows the heatmap for f(x, y) and several one-dimensional slices of this function in both directions:
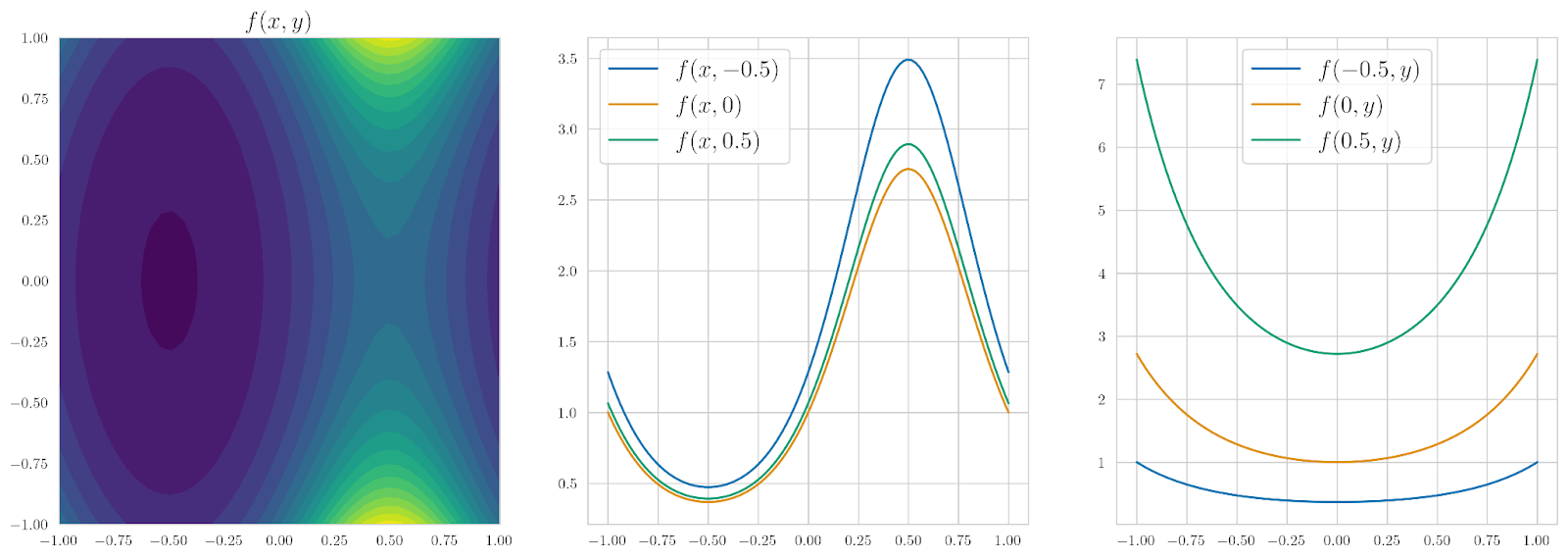
To train a KAN for this function, first we need to set up its structure; let’s mimic the structure of the function and set up a [2, 2, 1] KAN, i.e., a composition of the form
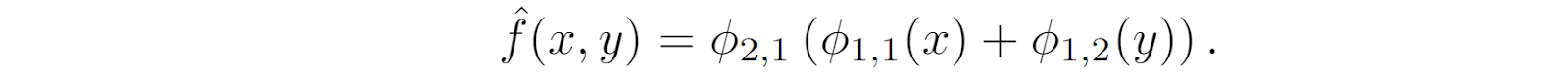
After training, we get a rather small loss on the test set (produced by the same function), and the following learned functions:
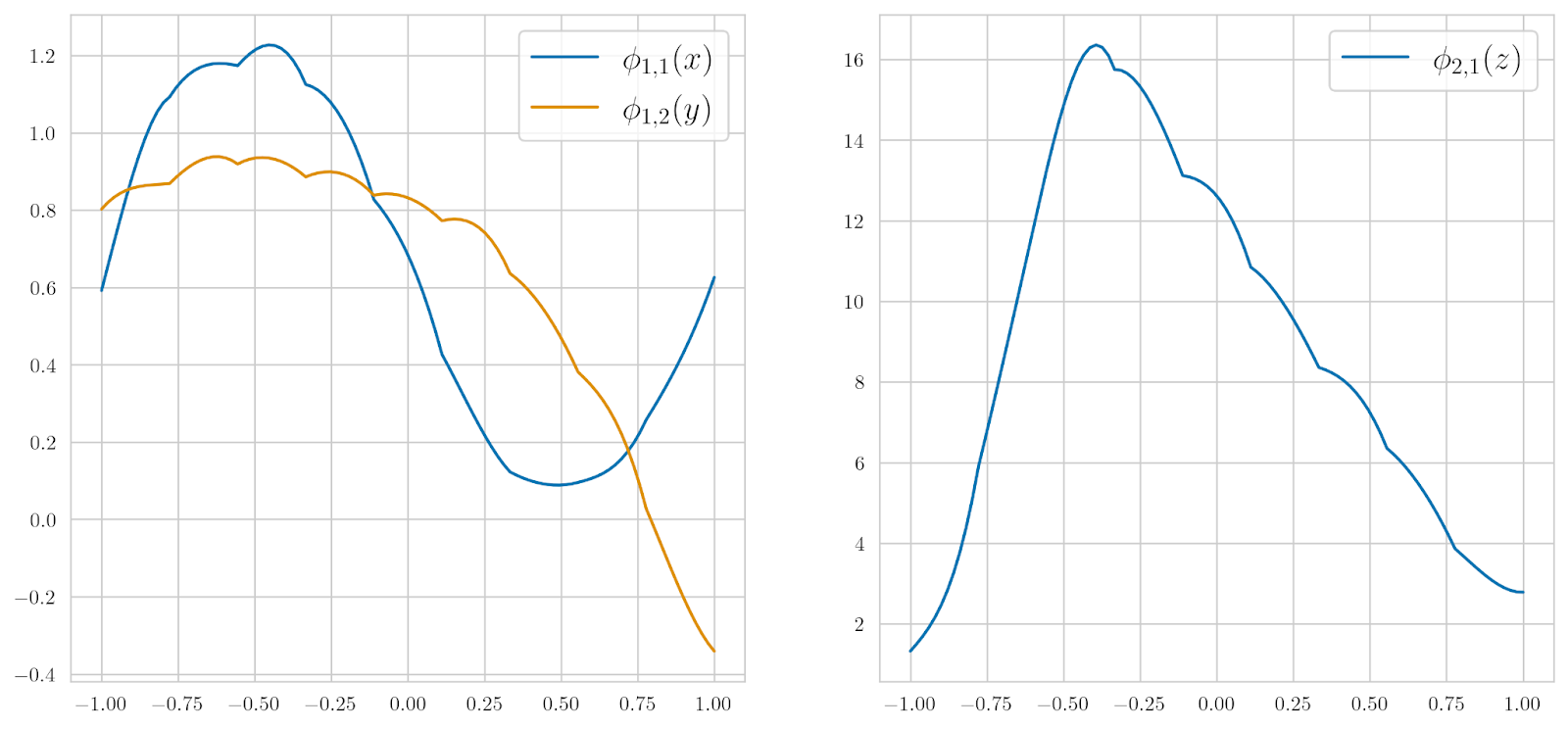
As you can see, ɸ1,1 indeed resembles a sinusoidal function, and ɸ1,2 looks suspiciously quadratic. Even at this point, we see that KAN not only can train good approximations to complicated functions but can also provide readily interpretable results: we can simply look at what kinds of functions have been trained inside the composition and have a pretty good idea of what kinds of features are being extracted.
But we can do even better. Suppose that by looking on these plots, we have noticed that ɸ1,2 is very similar to the quadratic function y2 (actually, -y2 in this case, but the minus sign is best left for the linear combination). KAN allows us to substitute our guess symbolically into ɸ1,2, fixing it to be ɸ1,2 (y)=y2 and training the rest of the functions. If we do that, we get a much better test set error, ɸ2,1 will still look sinusoidal, and, most importantly, the resulting ɸ2,1 will look much more like the exponent that it is in the original:
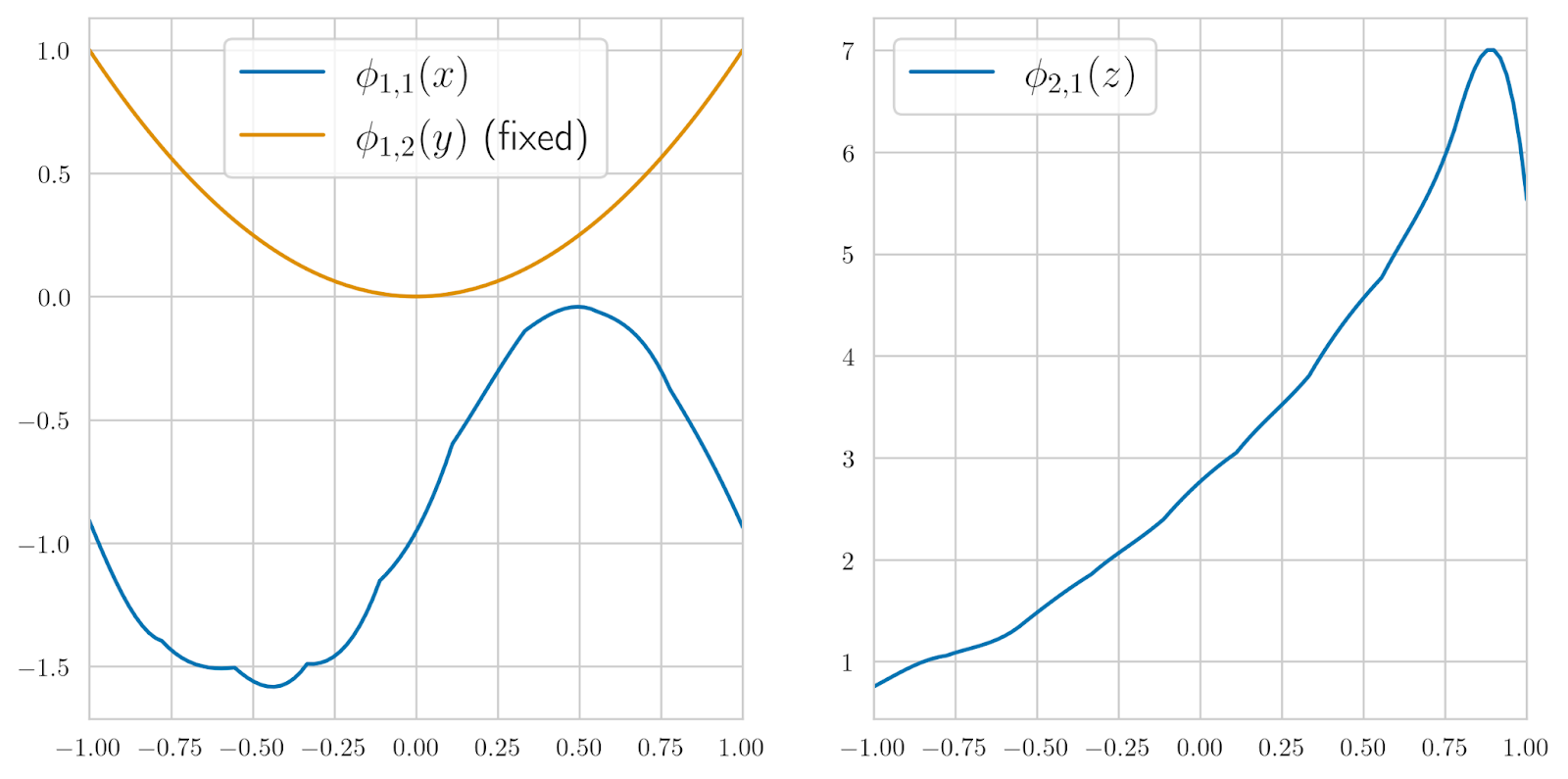
So by now, we can also correctly infer the other functions in the composition. Doing this kind of symbolic reasoning requires an iterative process of looking at the functions and substituting some of them symbolically, but it still beats trying to analyze a multilayer perceptron by a very large margin. In practice, we will not know the correct form of the KAN composition but one can start with a larger KAN and reduce it, looking at what happens with the approximation error.
Liu et al. (2024) suggested that this could be helpful for deriving complex dependencies in physics or applied math, when you need to explain experimental data with a formula; they show several interesting examples related to learning symbolic formulas for quantum physics (to be honest, I am very, very far from an expert on quantum physics so I will not attempt to explain the physics part here). They called KAN “a language model for AI + Science” and even provided a decision tree for choosing between KANs and regular MLPs in applications:

In other words, KANs were suggested as helper models for semi-automated learning in science and generally situations when you would like to obtain a symbolic formula as a result.
The original paper by Liu et al. (2024) was posted on arXiv on April 30, 2024. It was immediately noticed and received some coverage but the initial impression was that KAN applications are very limited due to their high computational complexity. The problem is that in order to construct B-splines of degree 3 that KANs are based on, you have to run the above-mentioned de Boor–Cox iteration that becomes a significant computational bottleneck for KAN, especially rescaling the spline grids.
In less than two weeks, on May 10, 2024, Ziyao Li uploaded a three-page preprint to arXiv where he introduced FastKAN, a method that achieves equivalent results while having about 3x faster forward propagation. His idea is that B-splines are basically equivalent to Gaussian radial basis functions (RBF), a traditional way to extract local features in machine learning. Training a one-dimensional linear regression with RBF means that you are learning the weights a linear combination of features each of which depends on the distance between x and its center μi, with Gaussian RBFs having exponential decay around μi similar to the normal distribution:

Li (May 2024) showed that you can replace B-splines with Gaussian RBF functions and achieve significant performance improvements with basically no difference in the results. With this simple alteration, KANs suddenly became much more practical—another wonderful example of low-hanging fruit that one can find in deep learning even now (although nowadays you really have to be quick about it).
But that’s not the end of the story, of course. Another two weeks later, on June 4, 2024, Qiu et al. published a more detailed arXiv preprint that tried to alleviate the very same restriction. They replaced the B-spline basis functions with a new function composed of ReLU activations, specifically
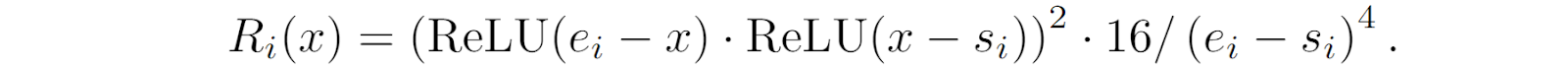
Here ei and si are trainable parameters, which makes Ri a rather diverse family of functions, and ReLU(x)=max(x, 0) is the regular ReLU activation function; here is an illustration by Qiu et al. (2024):

The main advantage of these basis functions is that they can be expressed via matrix operations such as matrix addition, dot products, and ReLU activation. This makes them much faster in practice than KANs based on B-splines; the authors report 5-20x improvements in training speed while also significantly improving the fitting accuracy.
So one month after the original paper on KANs, we already had two much more efficient versions that could be scaled further than a regular KAN and applied much wider. These were the papers that started the hype. Half a year later, where are we with KANs now?
In any field of science, you expect that a new idea that can open up a new field of study will be gradually developed afterwards; at first, the authors of the model will try to milk it for new results, then other researchers will see the potential and join in, and if the idea is good, ultimately a subfield will arise. The main difference between mostly any other field of science and deep learning is that while in “regular” computer science this process would take at least a few years, in deep learning it has already happened in several months. The original paper by Liu et al. (2024), posted on arXiv in April 2024, by mid-October has already over 250 citations (Google Scholar), and a curated list of links about KANs notes over a hundred interesting papers and resources that directly continue this research. So while in June 2024 a comprehensive survey of KANs was possible (Hou, Zhang, 2024), now, just half a year after the original publication, it is already basically futile to try and review everything people have done in this direction; below, I will survey a few papers that look most interesting to me.
Let us begin with improved architectures; I will note two works in more detail and give a brief survey of several others.
Bodner et al. (June 2024) were the first to introduce Convolutional KANs, an architecture that combines the KAN approach with convolutional networks. But here I want to highlight the work by Yu et al. (October 2024) who introduce a special kind of Chebyshev polynomial-based KAN convolutions (see also Sidharth, Gokul, May 2024), which is a reformulation of KANs designed to extract features from patches of the input tensor, just like a CNN:

Then Yu et al. start off with traditional convolutional architectures and add layers of these new convolutions with residual connections around classical CNN layers such as ResNet (left) or DenseNet (right):
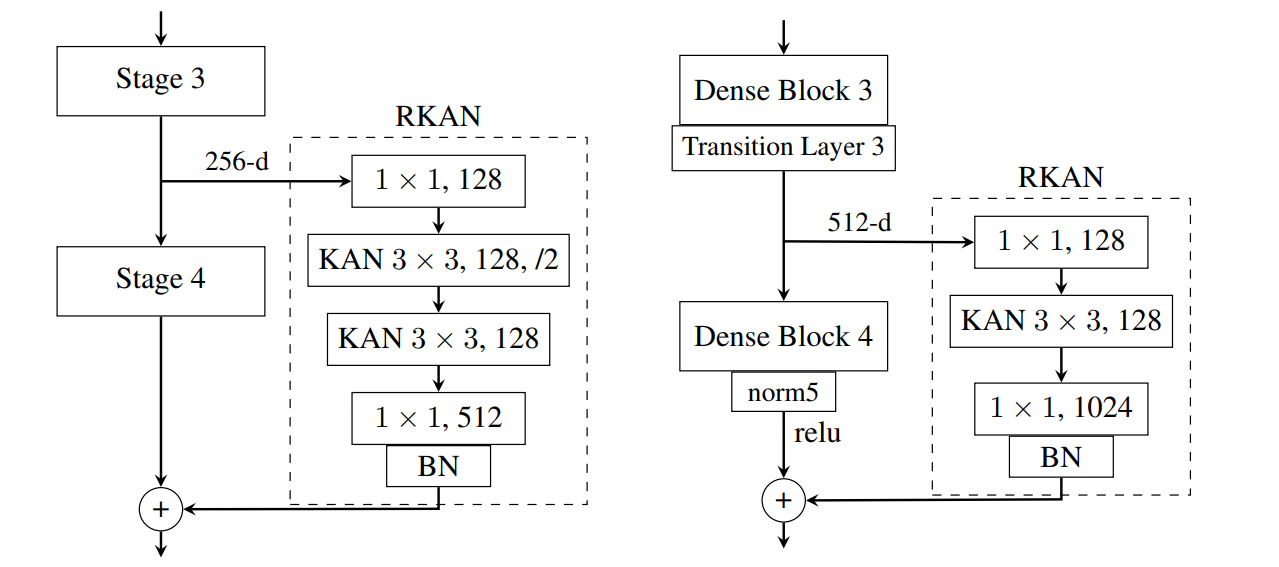
The resulting architectures, called Residual KAN (RKAN), shows performance improvements on classical datasets; the authors especially note that RKAN’s performance benefits grow with the complexity of the dataset and model size, suggesting that such feature extraction units can be beneficially added to many different architectures.
Yang and Wang (September 2024) present the Kolmogorov–Arnold Transformer (KAT), a model that replaces MLP layers in transformers with Kolmogorov-Arnold Network (KAN) layers. Their main applications lie in computer vision tasks, so their teaser image shows ImageNet accuracy and compares KAT with ViT-like models:
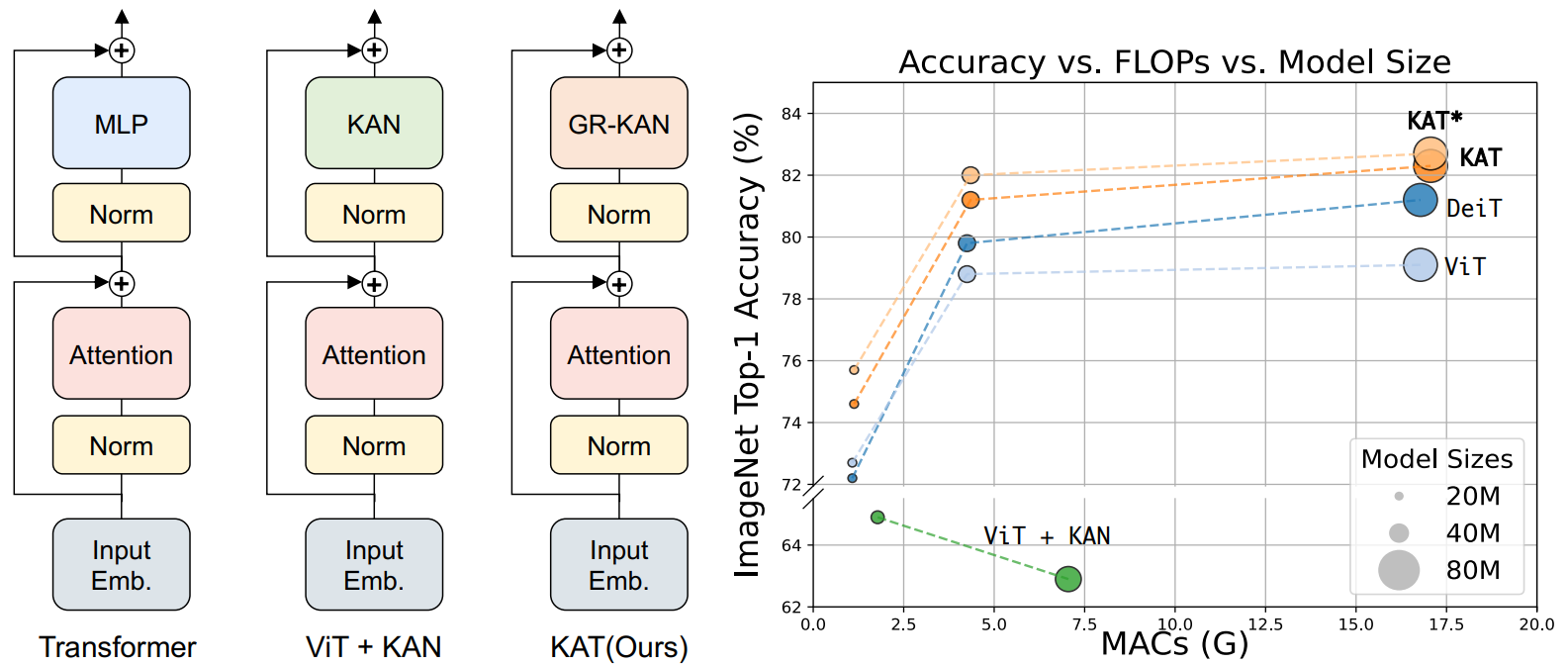
The idea is that while KANs are known for their parameter efficiency and can learn powerful and concise representations, it is challenging to integrate KANs into large-scale models such as the Transformer. The paper lists three core problems:
To address these issues, KAT introduces respectively three key innovations:
As a result, KAT can successfully integrate KANs into Transformers and achieves several state of the art results in vision tasks, including image recognition, object detection, and semantic segmentation, where KAT outperforms traditional Transformers with MLP layers. For example, on the ImageNet-1K dataset the KAT model exceeded the accuracy of a ViT model of the same size by 3.1%, which is no small feat given that the overall accuracy is already at 82%. Performance improved even further when KAT was initialized with pretrained ViT weights.
Among other news in KANs, let us note the following:
However, various KAN-based architectures are just a means to an end; what have the ends been, i.e., how have KANs been used in practice?
We have noted above that the original KAN were developed in part with scientific applications in mind: KANs can yield symbolic results and explain their predictions with compact and readily interpretable formulas.
The next step in this direction was taken by the KAN 2.0 approach developed by Liu et al. (August 2024). The goal of KAN 2.0 is to create a two-way synergy between KANs and scientific knowledge, both embedding prior scientific knowledge into KANs and extracting new scientific insights from them:
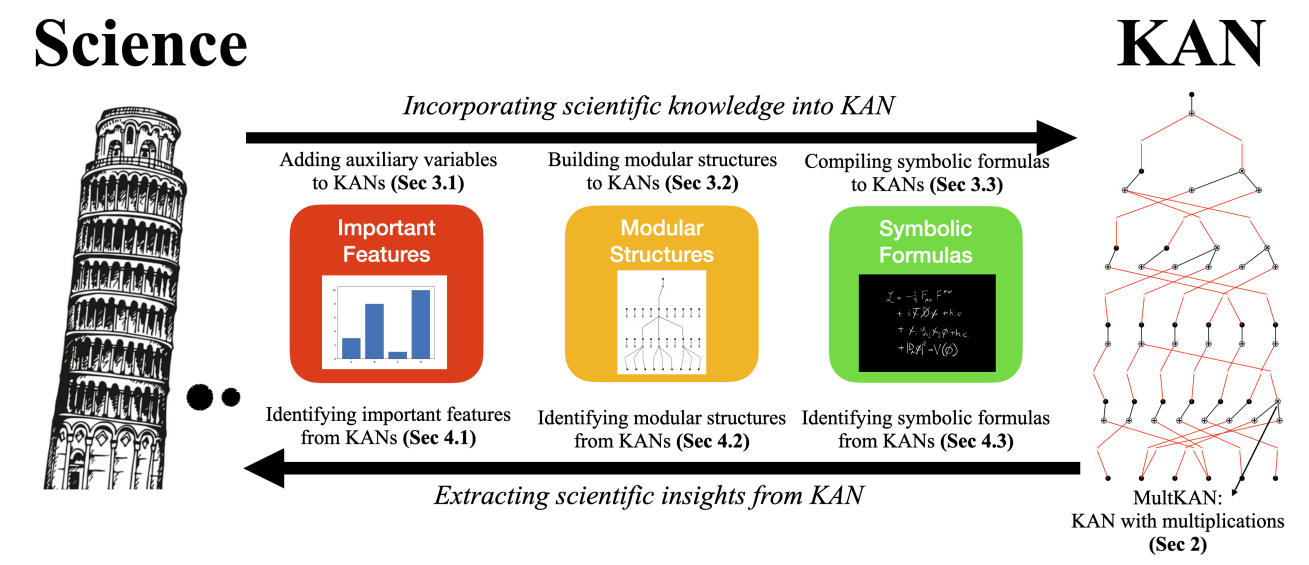
Architecturally, the authors make several interesting contributions:
As a result, Liu et al. (2024) show how KANs can be applied to discover and interpret physical laws, including:
This still looks like the most direct practical application of KANs: their direct relation to symbolic formulas, with easy conversions back and forth, may lead to important discoveries.
However, this is not the only application. Models that I mentioned in the previous section all come with convincing practical results where KAN-based architectures outperform similar architectures without KANs. Let me note a few more interesting papers that introduce new applications of KANs:
As you can see, most of these applications still center on using KANs for science, inferring mathematical dependencies from data in various domains; time will tell if preliminary promising results in other directions such as image processing convert to practical models.
I originally thought this post would be relatively short; Kolmogorov–Arnold networks seemed like an interesting idea that would make for a good case study of “something completely different” in the field of deep learning that might or might not lead to good results in the future. However, as I fell deeper and deeper into the rabbit hole of KANs, they seemed more and more promising, so this post had gradually turned into a full-sized review.
I cannot but imagine how interesting it would be to pair KANs with an advanced LLM that might try to automatically notice what functions are being learned. An LLM will tirelessly try different approaches in what seems to be a perfect match for their capacity for creative data analysis without too much intermediate logical reasoning. The o1 family of models already looks like a very promising candidate for this LLM (see my post on o1-preview), and the models will only get better from here.
But Kolmogorov–Arnold networks still do make for an excellent case study. Based on an idea that had been around forever, KANs were introduced at the end of April 2024. It is October now, and KANs have already blossomed into a well-developed research direction, with dozens of papers introducing new directions and applications. In this post, I have tried to give a brief overview of this direction, and I believe it is an interesting one, but my main point is that this is but one of many possible ideas worth exploring. I am sure that deep learning has many more such ideas in store, waiting for researchers to discover them; good luck!
Sergey Nikolenko
Head of AI, Synthesis AI
