
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
This is the last post in my mini-series on object detection with synthetic data. Over the first four posts, we introduced the problem, discussed some classical synthetic datasets for object detection, talked about some early works that have still relevant conclusions and continued with a case study on retail and food object detection. Today we consider two papers from 2019 that still represent the state of the art in object detection with synthetic data and are often used as generic references to the main tradeoffs inherent in using synthetic data. We will see and discuss those tradeoffs too. Is synthetic data ready for production and how does it compare with real in object detection? Let’s find out. (header image source)

The first paper saved me the trouble of thinking of a pithy title. Aptly named “An Annotation Saved is an Annotation Earned: Using Fully Synthetic Training for Object Instance Detections”, this work by Hinterstoisser et al. comes from the Google Cloud AI team. Similar to our last post, Hinterstoisser et al. consider multiple detection of small common objects, most of which are packs of food items and medicine. Here is a sample of their synthetic objects:

But the interesting thing about this paper is that they claim to achieve excellent results without any real data at all, by training on a purely synthetic dataset. Here are some sample results on a real evaluation data for a Faster R-CNN model with Inception ResNet backbone (this is a bog-standard and very common two-stage object detector) trained on a purely synthetic training set:

Looks great, right? So how did Hinterstoisser et al. achieve such wonderful results?
Their first contribution is an interesting take on domain randomization for background images. I remind that domain randomization is the process of doing “smart augmentations” with synthetic images so that they are as random as possible, in the hopes to cover as much of the data distribution as possible. Generally, the more diverse and cluttered the backgrounds are, the better. So Hinterstoisser et al. try to get the clutter up to eleven by the following procedure:
As a result of this approach, Hinterstoisser et al. don’t have to have any background images or scenes at all: the background is fully composed of distractor objects. And they indeed get pretty cluttered images; here is the pipeline together with a couple of samples:

But that’s only part of it. Another part is how to generate the foreground layer, with objects that you actually want to recognize. Here, the contribution of Hinterstoisser et al. is that instead of placing 3D models in random poses or in poses corresponding to the background surfaces, as researchers had done before, they introduce a deterministic curriculum (schedule) for introducing foreground objects:
Here is a sample illustration:
As a result, this purely synthetic approach outperforms a 2000-image real training set. Hinterstoisser et al. even estimate the costs: they report that it had taken them about 200 hours to acquire and label the real training set. This should be compared with… a mere 5 hours needed for 3D scanning of the objects: once you have the pipeline ready, that is all you need to do to add new objects or retrain in a different setting. Here are the main results:
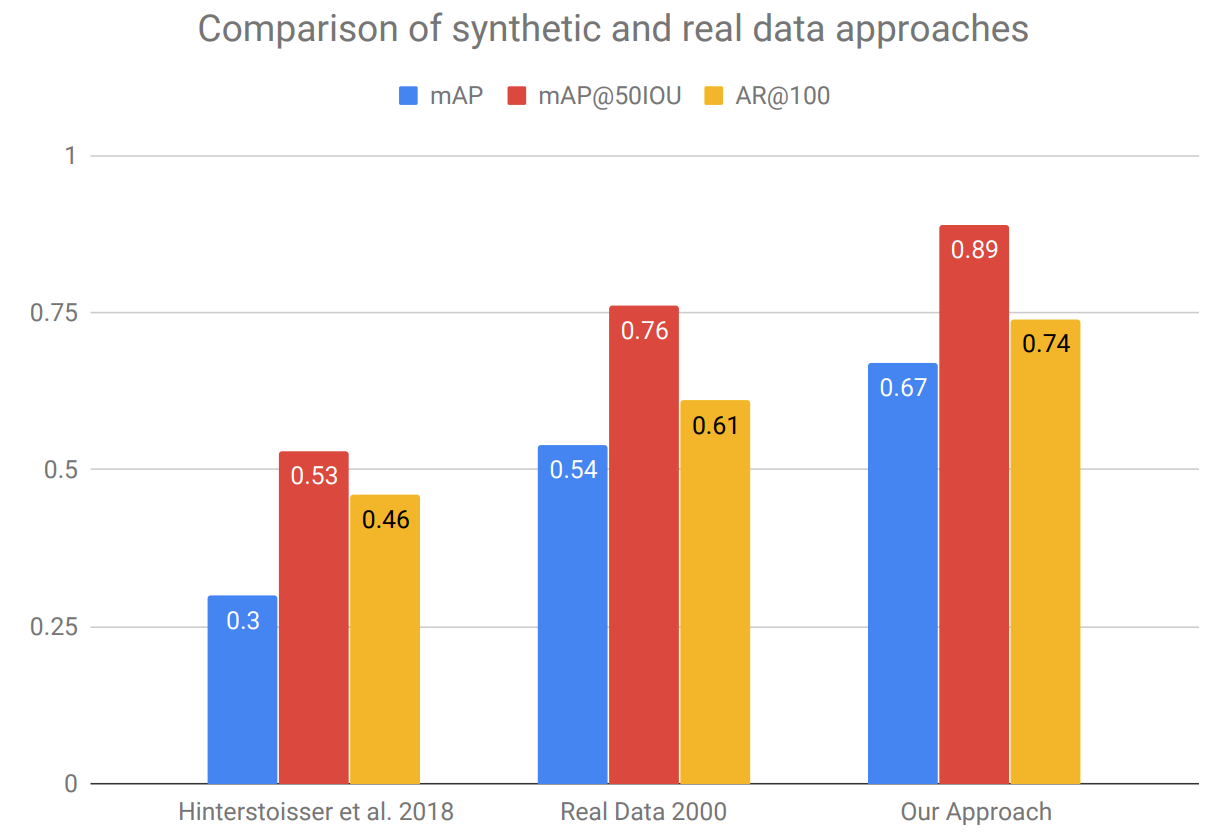
But even more interesting are the ablation studies that the authors provide. They analyze which of their ideas contributed the most to their results. Interestingly (and a bit surprisingly), the largest effect is achieved by their curriculum strategy. Here it is compared to purely random pose sampling for foreground objects:
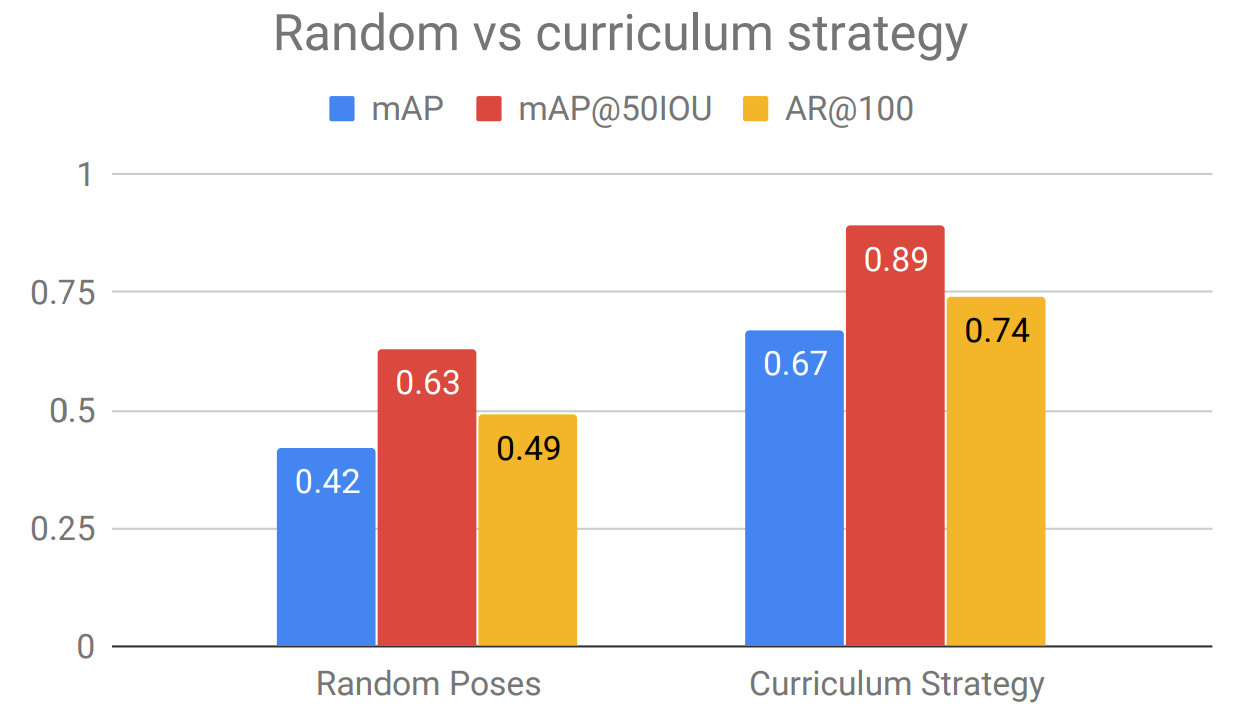
Another interesting conclusion is that the purely synthetic cluttered background actually performs much better than a seemingly more realistic alternative strategy: take real world background images and augment them with synthetic distractor objects (there is no doubt that distractor objects are useful anyway). Surprisingly, the purely synthetic background composed entirely of objects wins quite convincingly:
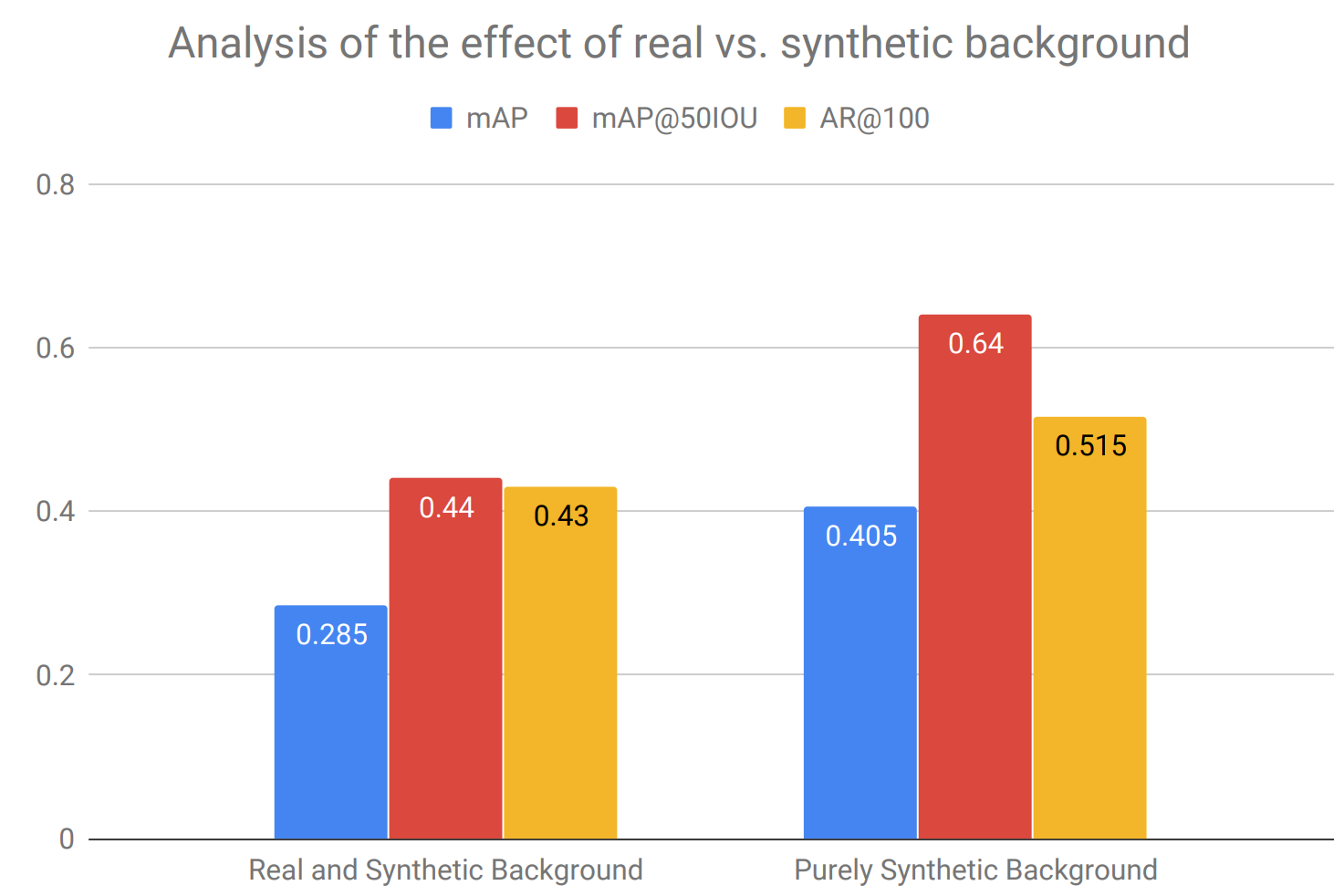
With these results, Hinterstoisser et al. have the potential to redefine how we see and use synthetic data for object detection; the conclusions most probably also extend to segmentation and possibly other computer vision problems. In essence, they show that synthetic data can be much better than real for object detection if done right. And by “done right” I mean virtually every single element of their pipeline; here is the ablation study:
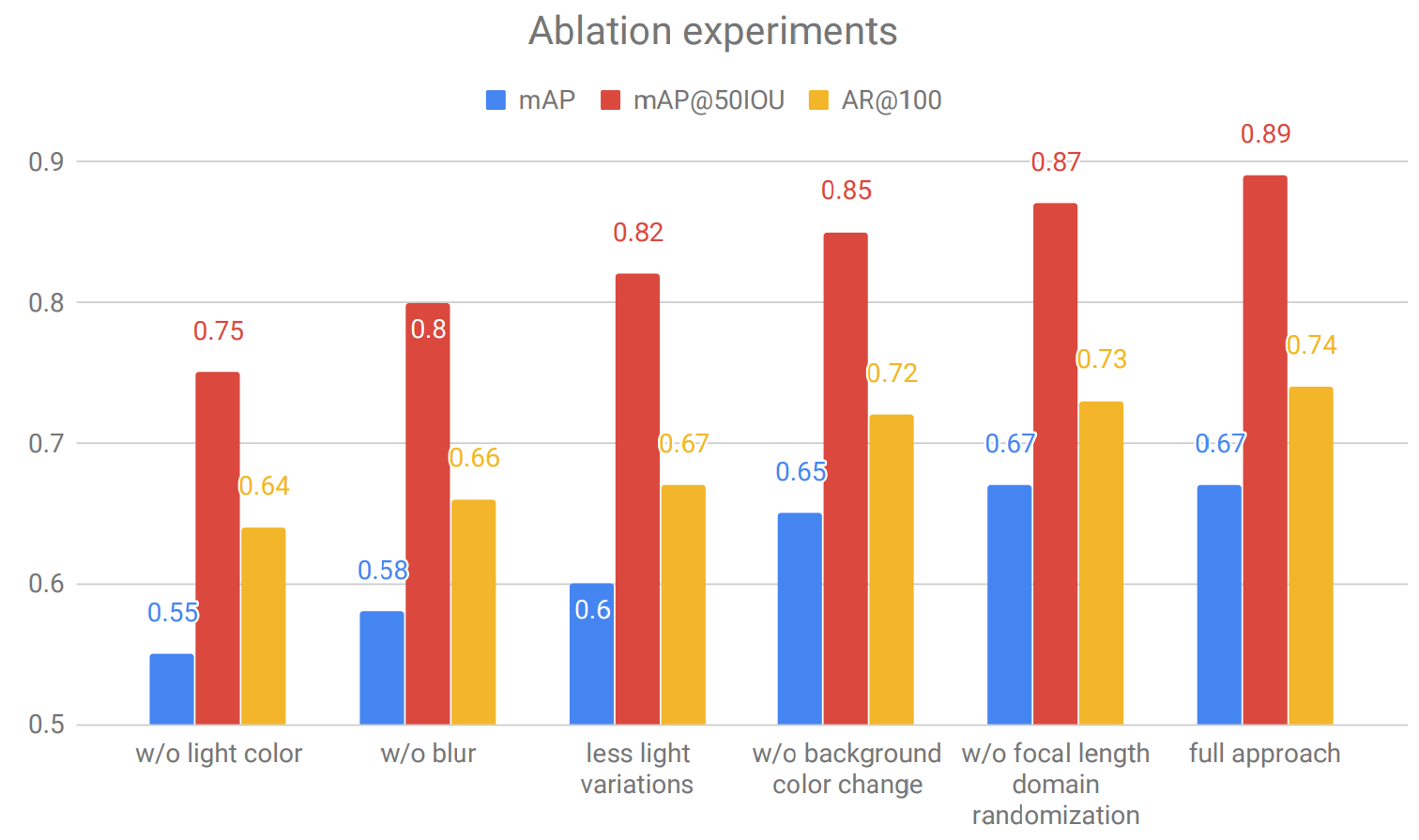
There are more plots like this in the paper, but it is time to get to our second course.
Guess I got lucky with the titles today. The last paper in our object detection series, “How much real data do we actually need: Analyzing object detection performance using synthetic and real data” by Nowruzi et al., concentrates on a different problem, recognizing objects in urban outdoor environments with an obvious intent towards autonomous driving. However, the conclusions it draws appear to be applicable well beyond this specific case, and this paper has become the go-to source among experts in synthetic data.
The difference of this work from other sources is that instead of investigating different approaches to dataset generation within a single general framework, it considers various existing synthetic and real datasets, puts them in comparable conditions, and draws conclusions regarding how best to use synthetic data for object detection.
Here are the sample pictures from the datasets used in the paper:

Nowruzi et al. consider three real datasets:
and three synthetic:
To put all datasets on equal footing, the authors use only 15000 images from each (since the smallest dataset has 15K images), resize all images to 640×370 pixels, and remove annotations for objects that become too small under these conditions (less than 4% of the image height). The object detection model is also very standard: it is an SSD detector with MobileNet backbone, probably chosen for computationally efficiency of both training and evaluation. The interesting part, of course, are the results.
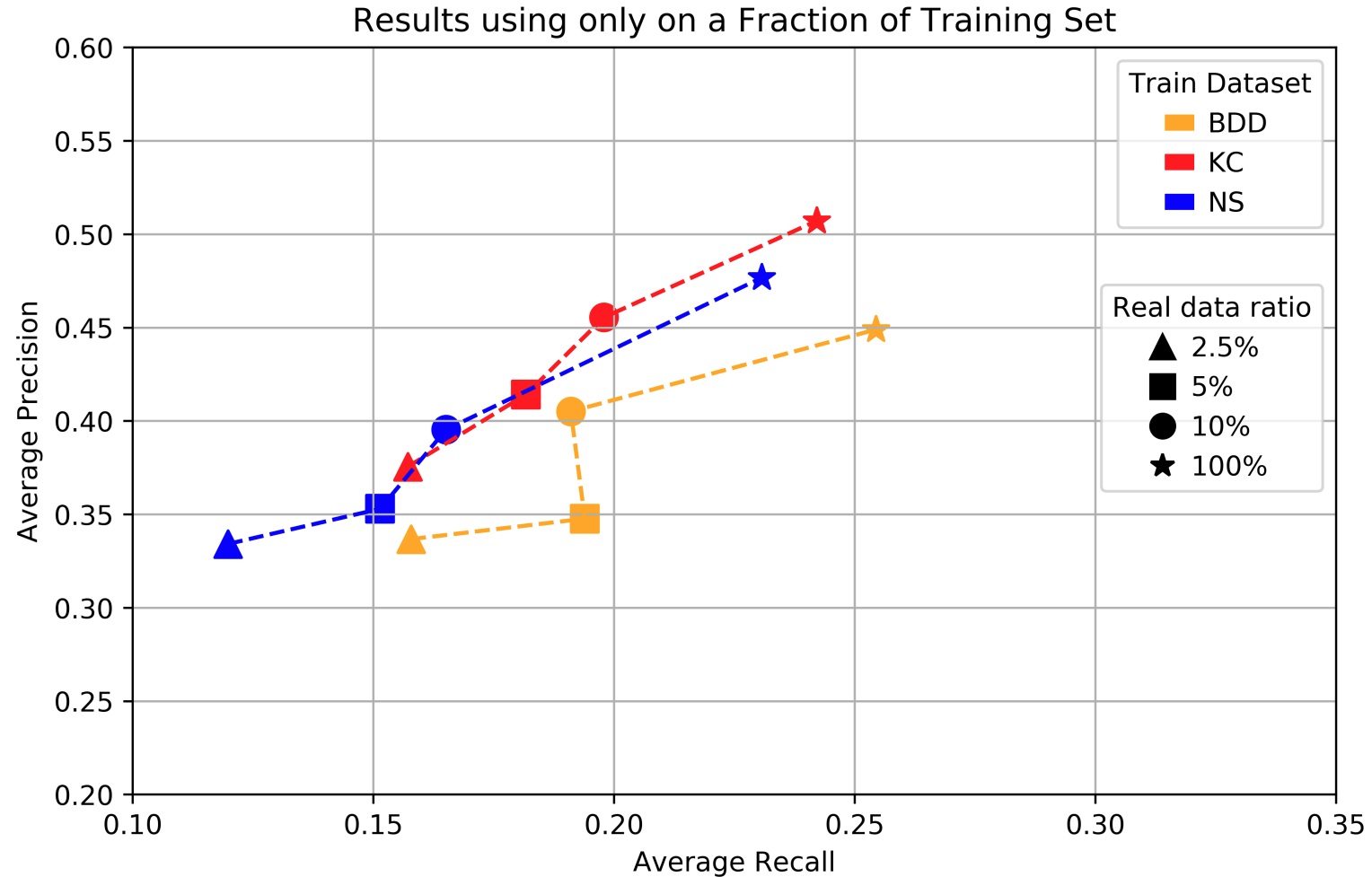
First, as you would expect, adding more data helps. Training on smaller portions of each dataset significantly impedes the results, as the plot below shows. Note that Nowruzi et al. use both color and shape of the markers to signify two different dimensions of the parameters, and the axes of the picture are performance indicators (average precision and recall), so top right is the best corner and bottom left is the worst; this will be used throughout all plots below:
The next set of results is about transfer learning: how well can object detection models perform on one dataset when trained on another? Let’s see the plot and then discuss:
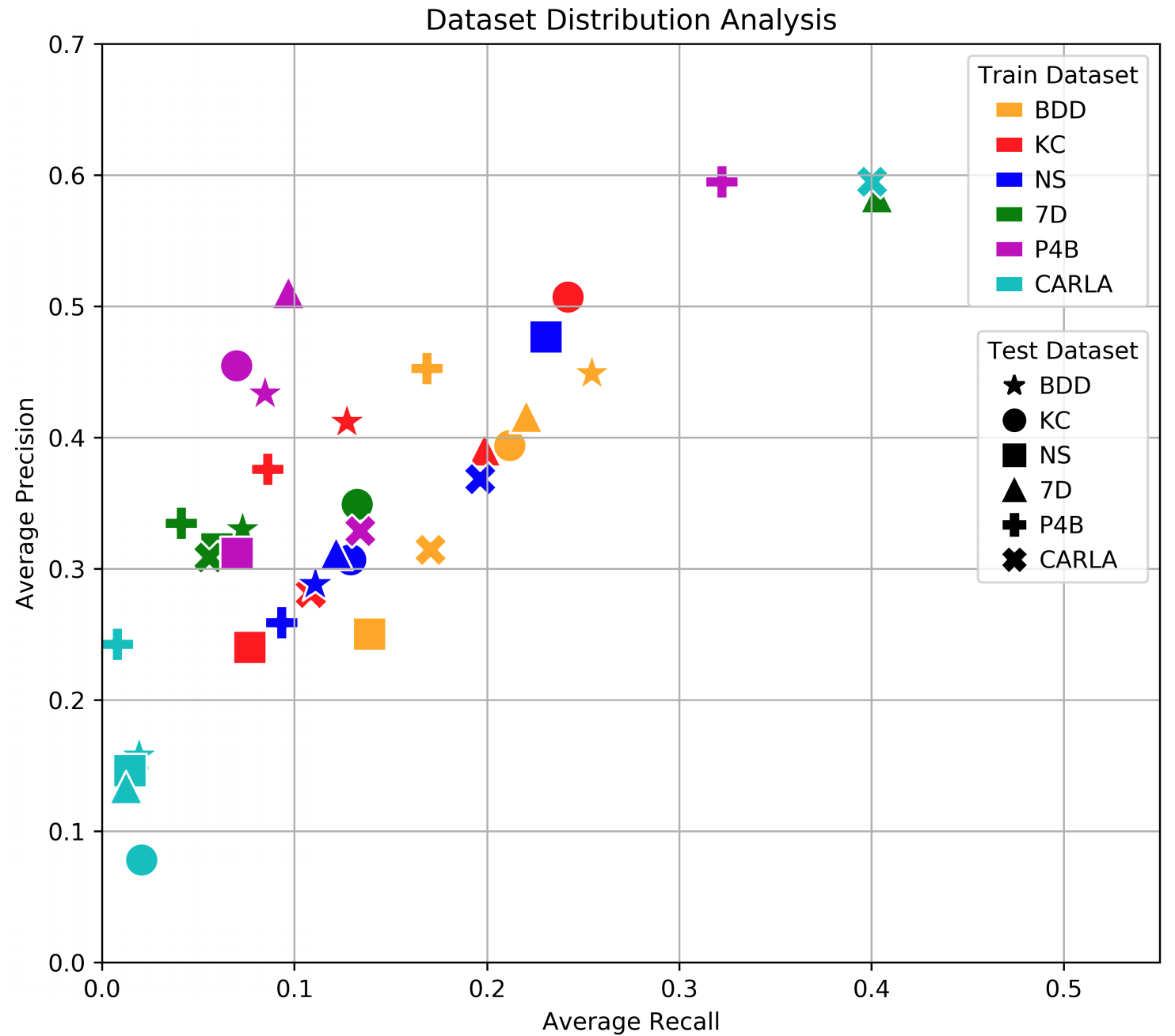
There are several effects to be seen here:
The real datasets are still a little better (see, e.g., how well BDD transfers to everything except NuScenes). But note that Nowruzi et al. have removed one of the main advantages of synthetic data by equalizing the size of real and synthetic datasets, so I would say that synthetic data performs quite well here.
But the real positive results come later. Nowruzi et al. compare two different approaches to using hybrid datasets, where synthetic data is combined with real.
First, synthetic-real data mixing, where a small(er) amount of real data is added to a full-scale synthetic dataset. A sample plot below shows the effect for training on the BDD dataset; the dashed line repeats the plot for training on purely real data that we have already seen above:
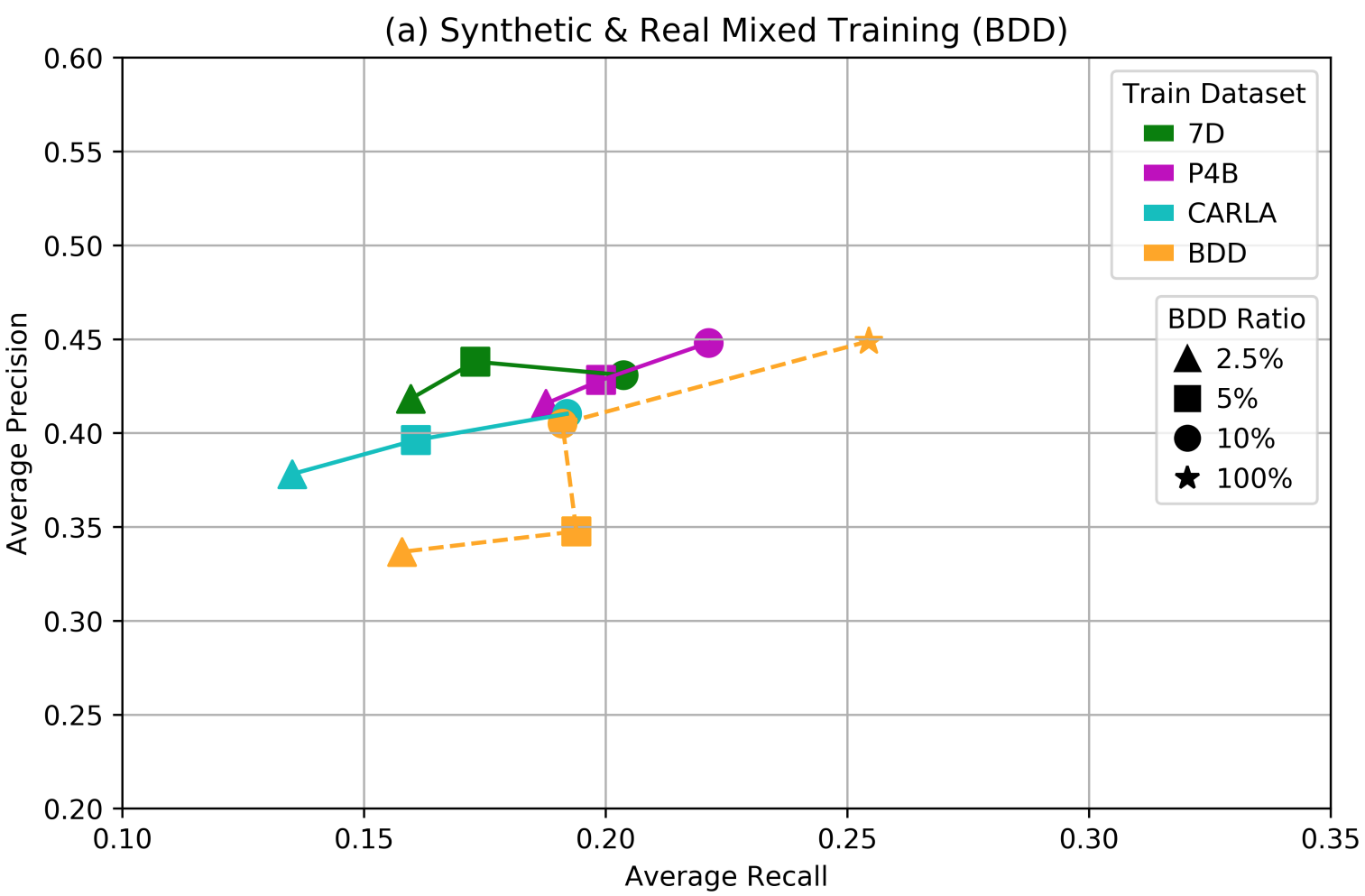
You can see that training on synthetic data indeed helps save on annotations substantially: e.g., using only 2.5% of the real BDD dataset and a synthetic P4B dataset yields virtually the same results as using 10% of the real BDD while using 4 times less real data. Naturally, 100% of real data is still better, and probably always will be.
But the really interesting stuff begins with the second approach: fine-tuning on real data. The difference is that now we fully train on a synthetic dataset and then fine-tune on (small portions of) real datasets, so training on synthetic and real data is fully separated. This is actually more convenient in practice: you can have a huge synthetic dataset and train on it once, and then adapt the resulting model to various real conditions by fine-tuning which is computationally much easier. Here are the results in the same setting (subsets of BDD):
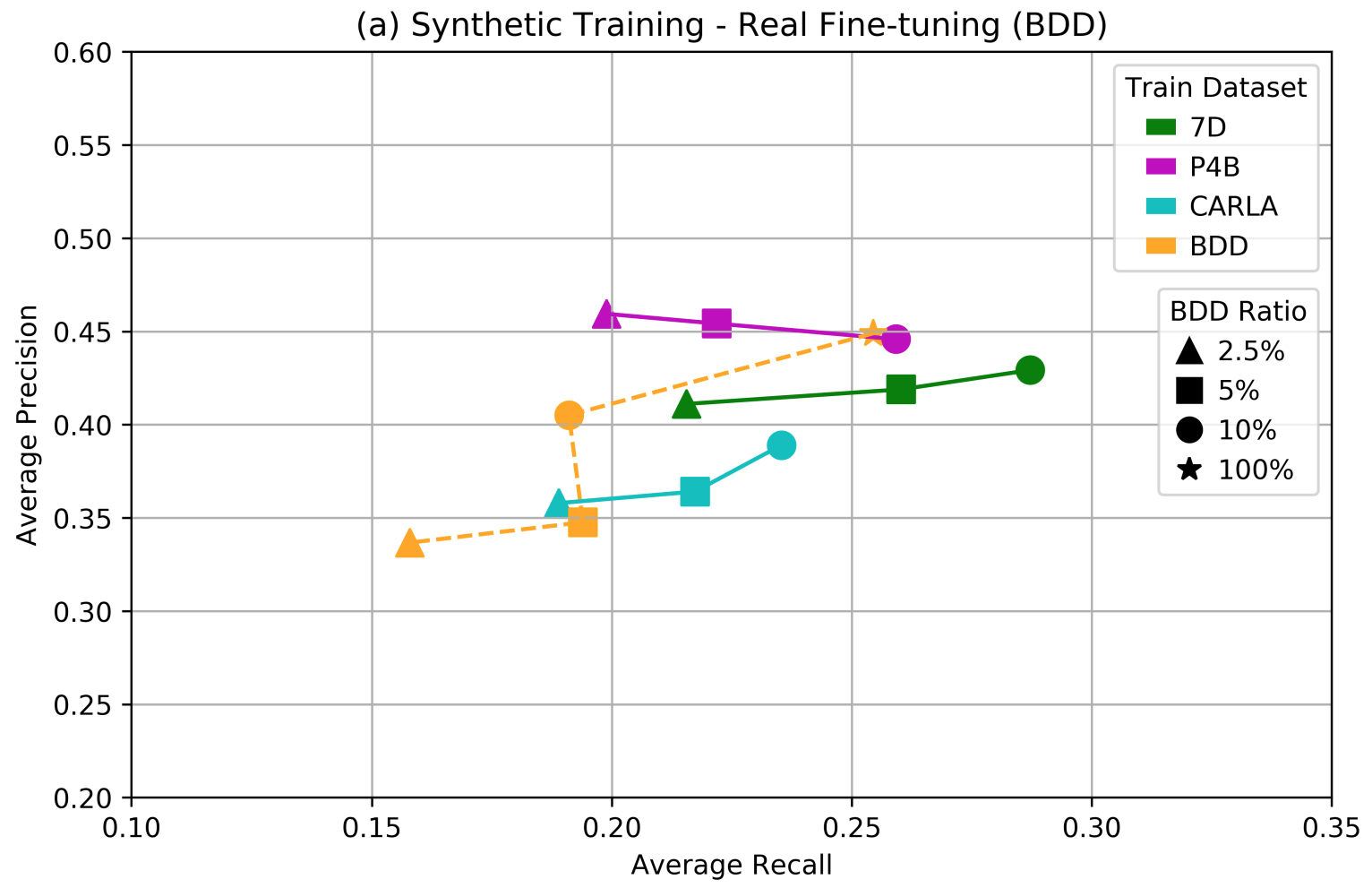
The dashed line is exactly the same as above, but note how every other result has improved! And this is not an isolated result; here is a comparison on the NuScenes dataset:
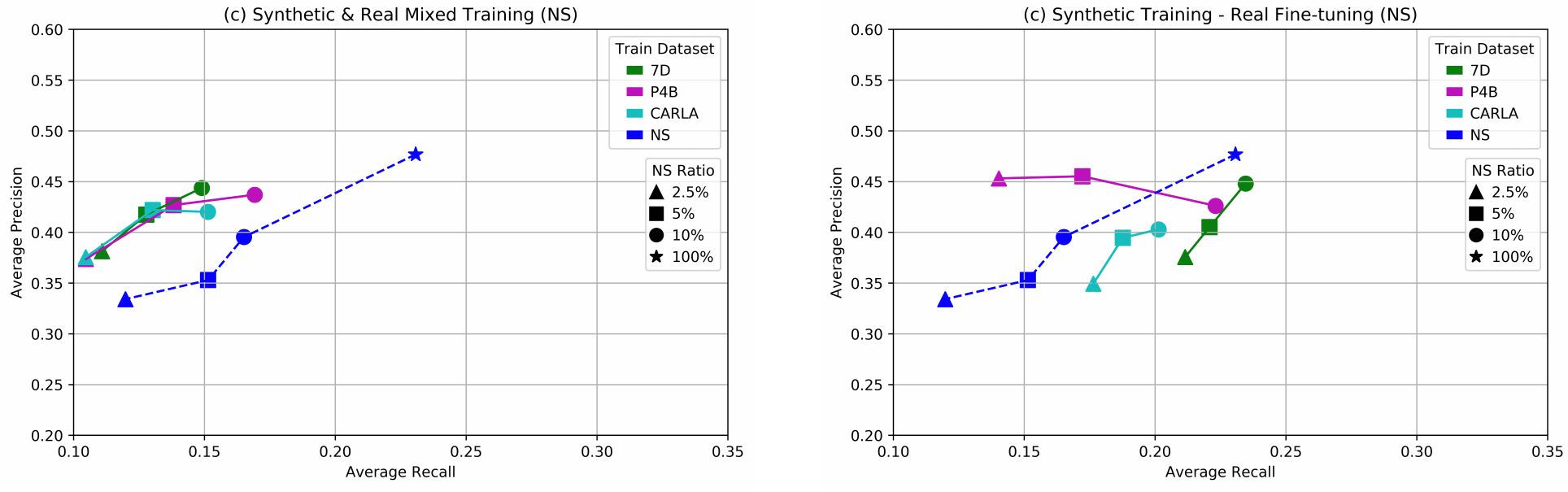
The paper has more plots, but the conclusion is already unmistakable: fine-tuning on real data performs much better than just mixing in data. This is the main result of Nowruzi et al., and in my opinion it also fits well with the previous paper, so let’s finish with a common conclusion.
Today, we have seen two influential recent papers that both try to improve object detection with the help of synthetic data. There is a common theme that I see in both papers: they show how important are the exact curricula for training and the smallest details of how synthetic data is generated and presented to the network. Before reading these papers, I would never guess that simply changing the strategy of how to randomize the poses and scales of synthetic objects can improve the results by 0.2-0.3 in mean average precision (that’s a huge difference!).
All this suggests that there is still much left to learn in the field of synthetic data, even for a relatively straightforward problem such as object detection. Using synthetic data is not quite as simple as throwing as much random stuff at the network as possible. This is a good thing, of course: harder problems with uncertain results also mean greater opportunities for research and for deeper understanding of how neural networks work and how computer vision can be ultimately solved. Here at Synthesis AI, we work to achieve better understanding of synthetic data, not only for object detection but for many other deep learning applications as well. And the results we have discussed today suggest that while synthetic data is already working well for us, there is still a fascinating and fruitful road ahead.
With this, I conclude the mini-series on object detection. After a short break, we will return with something completely different. Stay tuned!
Sergey Nikolenko
Head of AI, Synthesis AI
