
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
In the last post, we started talking about object detection. We discussed what the problem is, saw the three main general-purpose real-world datasets for object detection, and began talking about synthetic data. Today, we continue the series with a brief overview of the most important synthetic datasets for object detection. Last time, I made an example of an autonomous driving dataset, but this is a topic of its own, and so are, say, synthetic images of people and human faces. Today, we will concentrate on general-purpose and household object datasets.

The notion of synthetic data has been a staple of computer vision for a long time. Earlier on this blog, we talked about synthetic data in the very first computer vision models. But the first synthetic datasets all dealt with low-level computer vision problems such as, e.g., optical flow estimation, which are not our subject today. Large-scale public datasets for high-level computer vision problems with common everyday objects and scenes started to appear only in the mid-2010s.
The first efforts related to recognizing everyday objects such as retail items, food, or furniture, mostly drew upon the same database for 3D models. Developed by Chang et al., ShapeNet indexes more than three million models, with 220000 of them classified into 3135 categories that match WordNet synsets. Apart from class labels, ShapeNet also includes geometric, functional, and physical annotations, including planes of symmetry, part hierarchies, weight and materials, and more. Researchers often used the clean and manually verified ShapeNetCore subset that covers 55 common object categories with about 51000 unique 3D models; see, e.g., a large-scale effort in 3D shape reconstruction by Yi et al. (2017).
To be honest, ShapeNet looks more like 3D modeling from the 1990s than a five-year-old effort. Here are some sample shapes:
But to some extent, this was intentional: works based on ShapeNet tried to prove that you can use even relatively crude models to teach neural networks to recognize objects. Rougher models are also easier to process. Since ShapeNet provides not only RGB images with ground truth bounding boxes and segmentation but also full 3D models, it has been widely used for projects on 3D shape reconstruction and completion and 3D scene understanding; maybe we will come back to these projects in a later post.
This emphasis on 3D shape reconstruction carried over to one of the next iterations of ShapeNet, called PartNet (Mo et al., 2018). The creators of this dataset took ShapeNet models and provided an even more detailed kind of labeling for them. For instance, when you look at an office chair, you not only see a generic “chair” objects but can also distinguish the seat, back, armrests, and many other component parts of the chair. PartNet provides several layers of granularity for the parts of individual objects:
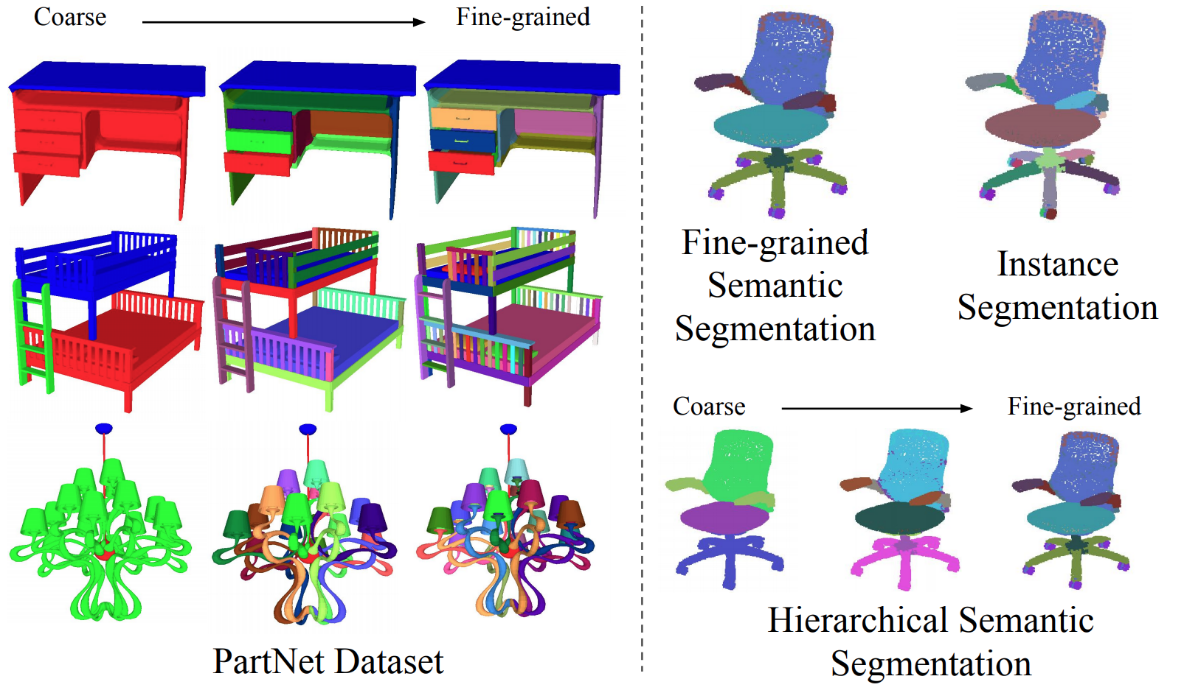
They have done it on scale: according to Mo et al., PartNet contains 573,585 fine-grained annotations of object parts for 26,671 shapes that belong to 24 different object categories. The categories themselves are all common household objects but pretty diverse:
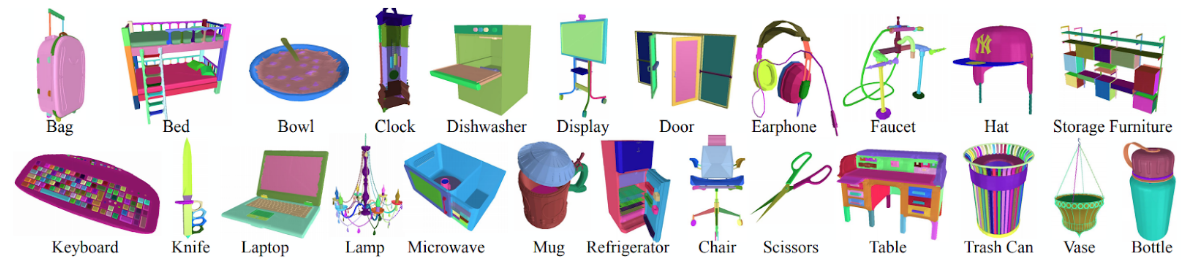
To the best of our knowledge, PartNet remains the best dataset that you can use if you need a well-detailed chair with detailed parts annotation. It has been used in dozens of papers on object understanding, and the only thing that prevents it from having a wider impact on, say, indoor navigation is the relatively small selection of object categories. We hope that further efforts will be made to expand the diversity of object categories in PartNet or similar datasets.
At about the same time, researchers from Yale, Carnegie Mellon, and Berkeley got together to produce another popular dataset of 3D shapes (Calli et al., 2015). True patriots of their respective alma maters, they named it the Yale-CMU-Berkeley (YCB) Object and Model set, and it was oriented towards applications in robotics. YCB collected not only the 3D shapes of objects but also their physical properties: dimension in real millimeters, mass, and frictional properties. The dataset was intended to help robotics researchers establish common benchmarks for object manipulation that could be used in silico, without expensive real experiments. Here is a sample of YCB data that would make Andy Warhol proud:

To sum up, by now we have large-scale datasets of common objects in the form of 3D shapes. These datasets have hundreds of thousand shapes and can produce potentially infinite datasets. This does not, however, quite scale to the entire computer vision problem: even the largest existing datasets have quite restricted sets of object categories. We will see a wider variety in specific applications such as indoor or outdoor navigation.
Now let’s see what we can do with those shapes!
Once you have these basic objects, it’s time to put them into context. If you recall, last time we spoke about real-world object detection datasets, and I said (but not yet explained) that the problem becomes much harder if the same picture contains objects on different scales (small and large in terms of the proportion of the picture) and if the objects are embedded into a rich context (complex background). Naturally, if you have a synthetic chair centered on a white background, like in the images above, you won’t get a hard object detection problem, and a network trained on this kind of dataset won’t get you very far in real object detection.
So what do we do? On the surface, it looks like we might have to bite the bullet and start developing complex backgrounds that capture realistic 3D scenes. People actually do it in, say, creating simulations and datasets for training self-driving cars, and it is an entirely reasonable investment of time and effort.
But in object detection, sometimes even much simpler things can work well. Some of the hardest problems in object detection come from the complex interactions between objects: partial occlusions, different scales caused by different distances to the camera, and so on. So why don’t we use a more or less generic scene and just put the objects there at random, striving to achieve a cluttered and complicated scene but with little regard to physical plausibility?
This plays into the narrative of domain randomization, a general term that means randomizing the parameters of synthetic scenes in order to capture as wide a variety of synthetic data as possible. The idea is that if the network learns to do its job on an extremely wide and varied distribution of data, it will hopefully do the job well on real data as well, even if individual samples of this synthetic data are very far from realistic. Starting from the paper by Tobin et al. (2017), domain randomization has been instrumental in synthetic data research, and we will definitely discuss it in more detail later.
When you put this idea into practice, you get datasets like Flying Chairs and Falling Things. Flying Chairs (Dosovitskiy et al., 2015) and Flying Chairs 3D (Mayer et al., 2015) were more oriented towards low-level problems such as optical flow estimation, so maybe I’ll talk about them in another post when it comes to that. The datasets look like this, by the way, so “flying chairs” is an apt name:



The Falling Things Dataset (FAT), developed by NVIDIA researchers Tremblay et al. (2018), contains about 61500 images of 21 household objects taken from the YCB dataset and placed into virtual environments under a wide variety of lighting conditions, with 3D poses, pixel-perfect segmentation, depth images, and 2D/3D bounding box coordinates for each object. The virtual environments are realistic enough, but the scenes are purely random, with a lot of occlusions and objects just flying in the air in all directions. Here is a sample, complete with segmentation and depth maps:



You can download the dataset by a link posted here; note that it is 42GB in size, although there are only 21 objects considered there. This is a common theme as well: as synthetic datasets grow in scale, it becomes less and less practical to render them in full glory and shoot the pictures back and forth over a network. Procedural generation is increasingly used to avoid this and render images only on a per-need basis.
By this time, you probably wonder just how much effort has to go into creating a synthetic dataset of your own. If you need a truly large-scale dataset, it may be a lot, and so far there is no way to save on the actual design of 3D models. But, as it always happens in our industry, people are working hard to commoditize the things that all these projects have in common, in this case the randomization of scenes, object placement, lighting, and other parameters, as well as procedural generation of these randomized scenes.
One recent example is NVIDIA’s Dataset Synthesizer (NDDS), a plugin for Unreal Engine 4 that allows computer vision researchers to easily turn 3D models and textures into prepared synthetic datasets. NDDS can produce RGB images, segmentation maps, depth maps and bounding boxes, and if the 3D models contain keypoints for the objects, then these keypoints and object poses can be exported too. What’s even more important, NDDS has automated tools for scene randomization: you can randomize lighting conditions, camera location, poses, textures, and more. Basically, NDDS makes it easy to create your own dataset similar to, say, Falling Things, and the result can look something like this:

NVIDIA researchers are already using NDDS to produce synthetic datasets for computer vision; this is an important area of research for NVIDIA today. For example, SIDOD (Synthetic Image Dataset for 3D Object Pose Recognition with Distractors) by Jalal et al.; the image above is actually taken from their paper. SIDOD is relatively small by today’s standards, only 144K stereo image pairs, but it is one of the first datasets to combine all types of outputs with flying distractors. I will borrow a comparison table from the paper by Jalal et al. where you can see some of the datasets we discussed today:
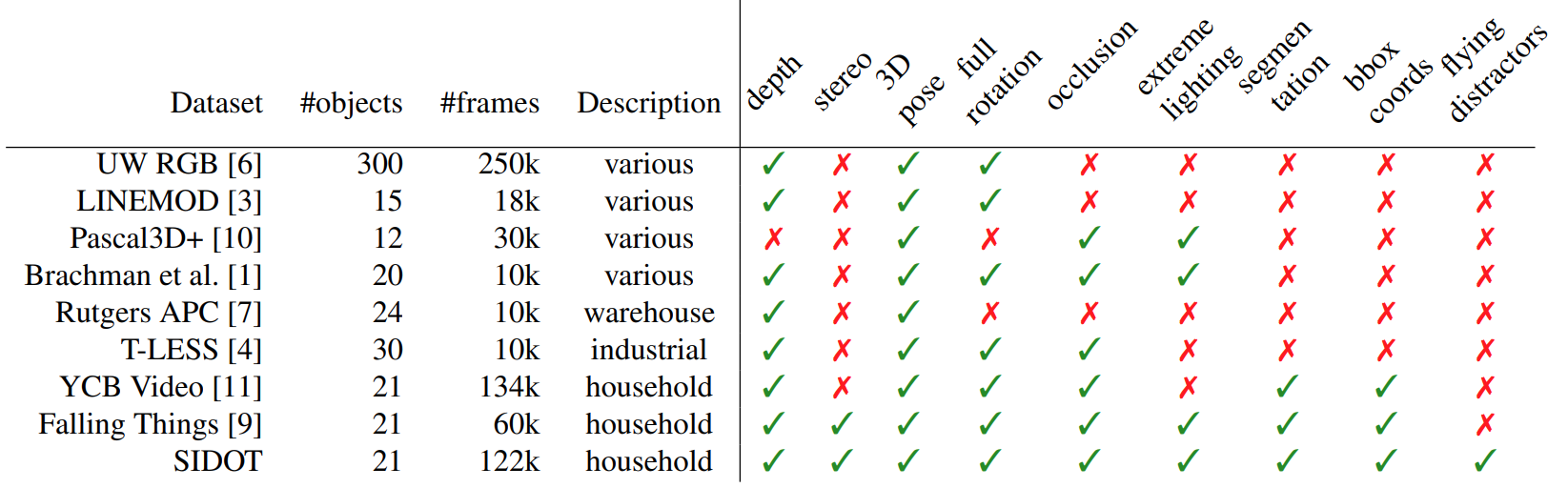
But even with this said, I still have to emphasize that for many real-life problems, you will definitely need professional help with the preparation of 3D models and construction of 3D scenes for them: even the power of domain randomization and random backgrounds could be much improved if you take pains to create a more proper context.
For the last two blog posts, we have been talking about object detection, but so far it has been purely from the point of view of the data. In the first post, we saw the object detection problem and real-world datasets for it, and today we have discussed some important synthetic datasets for this problem. But we are yet to talk about the actual solutions for object detection: okay, I got the data, but what do I actually do to solve the problem? Next time, I intend to start talking about just that.
Sergey Nikolenko
Head of AI, Synthesis AI
