
Do Androids Dream? World Models in Modern AI
One of the most striking AI advances this spring...
We continue the series on synthetic data for object detection. Last time, we stopped in 2016, with some early works on synthetic data for deep learning that still have implications relevant today. This time, we look at a couple of more recent papers devoted to multiple object detection for food and small vendor items. As we will see today, such objects are a natural application for synthetic data, and we’ll see how this application has evolved in the last few years.

Before I proceed to the papers, let me briefly explain why this specific application—recognizing multiple objects on supermarket shelves or in a fridge—sounds like such a perfect fit for synthetic data. There are several reasons, and each of them is quite general and might apply to your own application as well.
First, the backgrounds and scene compositions are quite standardized (the insides of a fridge, a supermarket shelf) so it shouldn’t take too much effort to simulate them realistically. If you look at the datasets for such applications, you will see that they often get by with really simplistic backgrounds. Here are some samples from the dataset from our first paper today, available from Param Rajpura’s github repository:

A couple of surface textures, maybe a glossy surface for the glass shelves, and off you go. This has changed a lot since 2017, and we’ll talk about it below, but it’s still not as hard as making realistic humans.
Second, while simple, the scenes and backgrounds are definitely not what you see in ImageNet and other standard datasets. You can find a lot of pics of people enjoying outdoor picnics and 120 different breeds of dogs in ImageNet but not so many insides of a refrigerator or supermarket shelves with labeled objects. Thus, we cannot reuse pretrained models that easily.
Third, guess why such scenes are not very popular in standard object detection datasets? Because they are obscenely hard to label by hand! A supermarket shelf can have hundreds of objects that are densely packed, often overlap, and thus would require full minutes of tedious work per image. Here are some sample images from a 2019 paper by Goldman et al. that presents a real dataset of such images called SKU-110K (we won’t consider it in detail because it has nothing to do with synthetic data):

Fourth, aren’t we done now that we have a large-scale real dataset? Not really because new objects arrive very often. A system for a supermarket (or the fridge, it’s the same kind of objects) has to easily support the introduction of new object classes because new products or, even more often, new packaging for old products are introduced continuously. Thousands of new objects appear in a supermarket near you over a year, sometimes hundreds of new objects at once (think Christmas packaging). When you have a real dataset, adding new images takes a lot of work: it is not enough to just have a few photos of the new object, you also need to have it on the shelves, surrounded by old and new objects, in different combinations… this gets really hard really quick. In a synthetic dataset, you just add a new 3D model and then you are free to create any number of scenes in any combinations you like.
Finally, while you need a lot of objects in this application and a lot of 3D models for the synthetic dataset, most objects are relatively easy to model. They are Tetra Pak cartons, standardized bottles, paper boxes… Among the thousands of items in a supermarket, there are relatively few different packages, most of them are standard items with different labels. So once you have a 3D model for, say, a pint bottle, most beers will be covered by swapping a couple of textures, and the bottle itself is far from a hard object to model (compare with, say, a human face or a car).
With all that said, object detection for small retail items does sound like a perfect fit for synthetic data. Let’s find out what people have been doing in this direction.
Our first paper today, the earliest I could find on deep learning with synthetic data for this application, is “Object Detection Using Deep CNNs Trained on Synthetic Images” by Rajpura et al. (2017). They concentrate on recognizing objects inside a refrigerator, and we have already seen some samples of their synthetic data above. They actually didn’t even bother with 3D modeling and just took standard bottles and packs from the ShapeNet repository that we discussed earlier.

They used Blender (often the tool of choice for synthetic data since it’s quite standard and free to use) to create simple scenes of the inside of a fridge and placed objects with different textures there:

As for their approach to object detection, we are still not quite in state of the art territory so I won’t dwell on it too much. In short, Rajpura et al. used a fully convolutional version of GoogLeNet that generates a coverage map and a separate bbox predictor trained on its results:
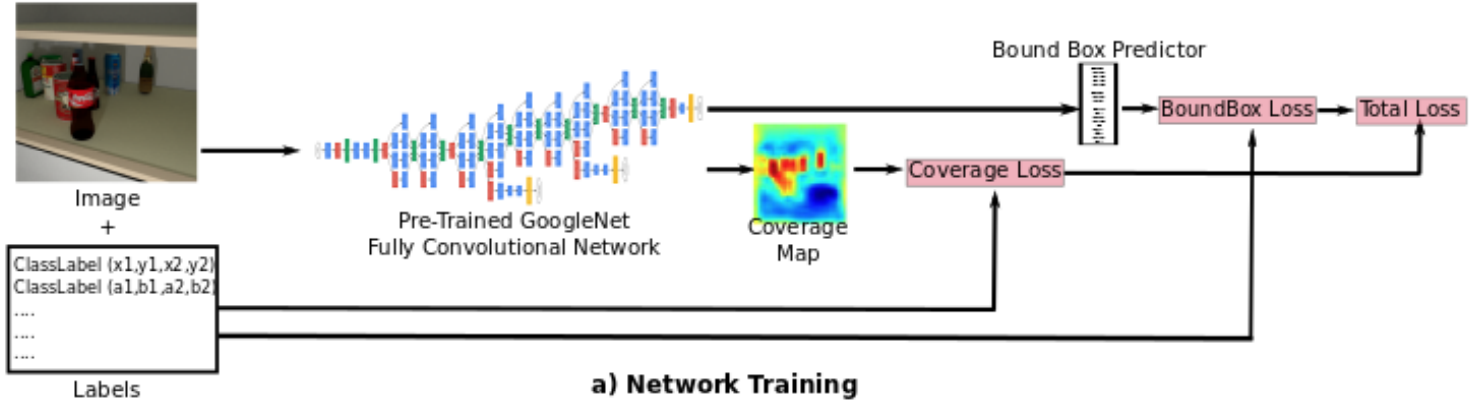
What were the results and conclusions? Well, first of all, Rajpura et al. saw significantly improved performance for hybrid datasets. Here is a plot from their paper that shows how 10% of real data and 90% of synthetic far outperformed “pure” datasets:
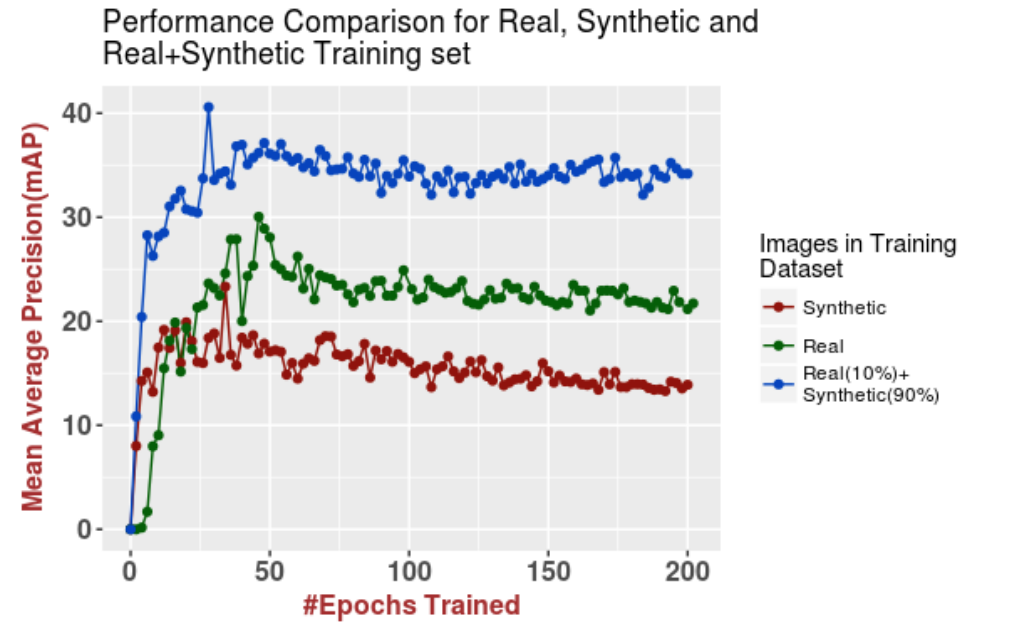
This result, however, should be taken with a grain of salt because, first, they only had 400 real images (remember how hard it is to label such images manually), and second, the scale of synthetic data was also not so large (3600 synthetic images).
Another interesting conclusion, however, is that adding more synthetic images can actually hurt. Here is a plot that shows how performance begins to decline after 4000 synthetic images:
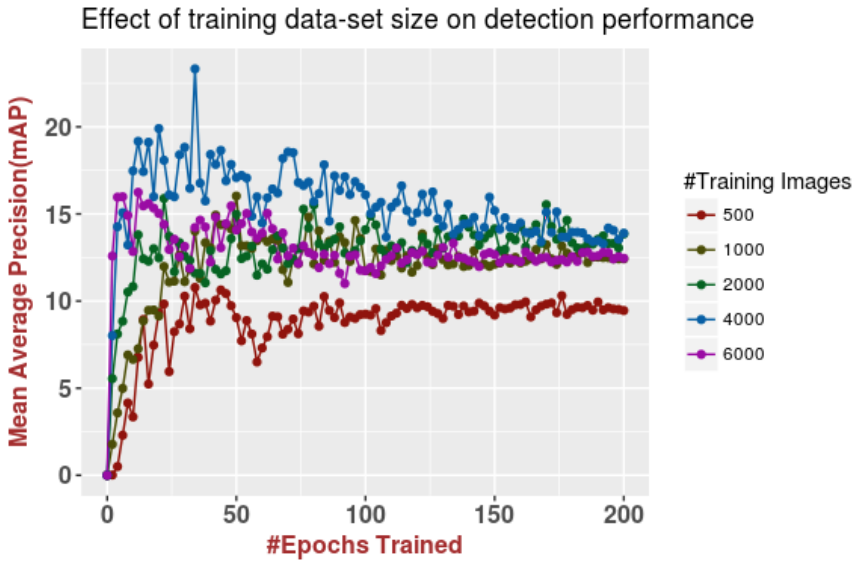
This is probably due to overfitting to synthetic data, and it remains an important problem even today. If you add a lot of synthetic images, the networks may begin to overfit to peculiarities of specifically synthetic images. More generally, synthetic data is different from real, and hence there is always an inherent domain transfer problem involved when you try to apply networks trained on synthetic data to real test sets (which you always ultimately want to do). This is a huge subject, though, and we will definitely come back to domain adaptation for synthetic-to-real transfer later on this blog. For now, let us press on with the fridges.
Or, actually, vending machines. Let us make a jump to 2019 and consider the work by Wang et al. titled “Synthetic Data Generation and Adaption for Object Detection in Smart Vending Machines”. The premise looks very similar: vending machines have small food items placed there, and the system needs to find out which items are still there judging by a camera located inside the vending machine. Here is the general pipeline as outlined in the paper:
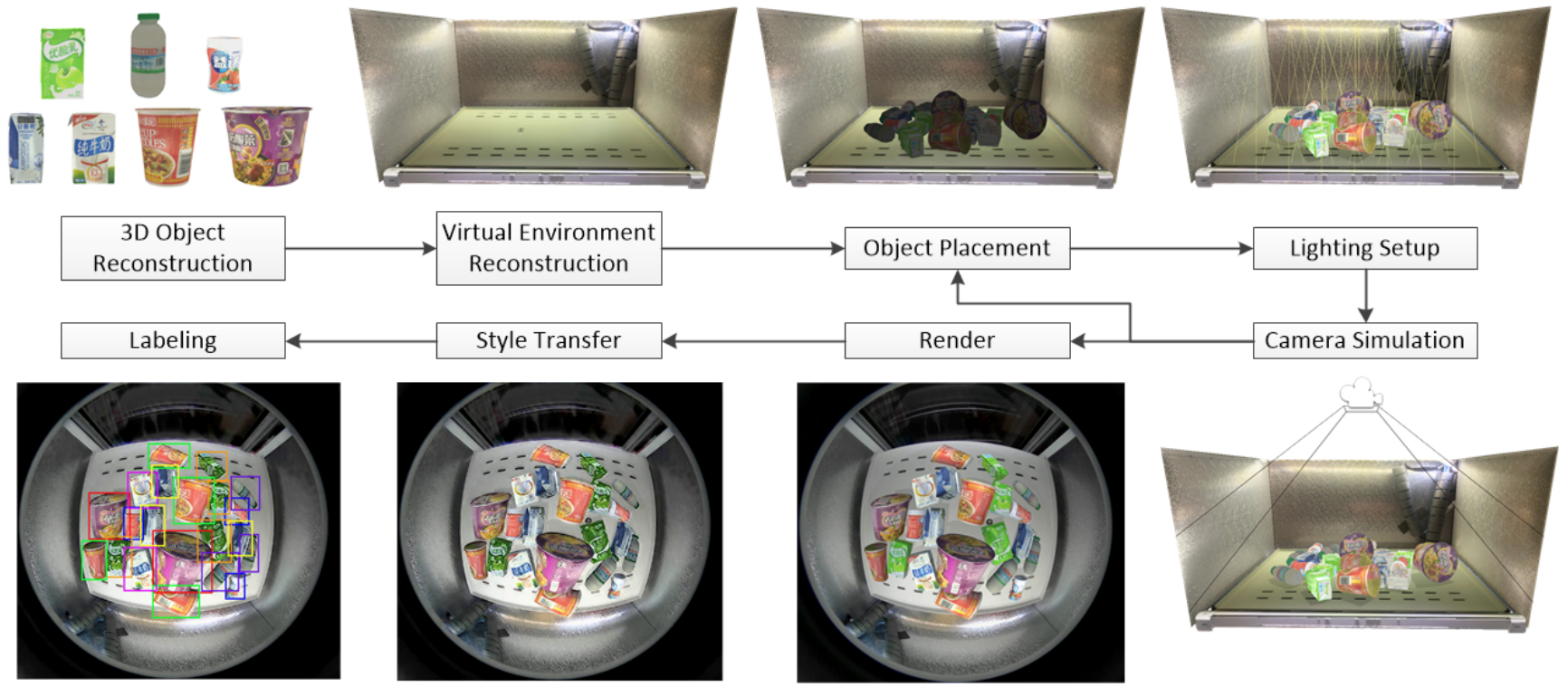
On the surface it’s exactly the same thing as Rajpura et al. in terms of computer vision, but there are several interesting points that highlight how synthetic data had progressed over these two years. Let’s take them in order.
First, data generation. In 2017, researchers took ready-made simple ShapeNet objects. In 2019, 3D shapes of the vending machine objects are being scanned from real objects by high-quality commercial 3D scanners, in this case one from Shining 3D. What’s more, 3D scanners still have a really hard time with specular or transparent materials. For specular materials, Wang et al. use a whole other complex neural architecture (an adversarial one, actually) to transform the specular material into a diffuse one based on multiple RGB images and then restore the material during rendering (they use Unity3D for that). The specular-to-diffuse translation is based on a paper by Wu et al. (2018); here is an illustration of its possible input and output:

As for transparent materials, even in 2019 Wang et al. give up, saying that “although this could be alleviated by introducing some manual works, it is beyond the scope of this paper” and simply avoiding transparent objects in their work. This is, by the way, where Synthesis AI could step up: check out ClearGrasp, a result of our collaboration with Google Robotics.
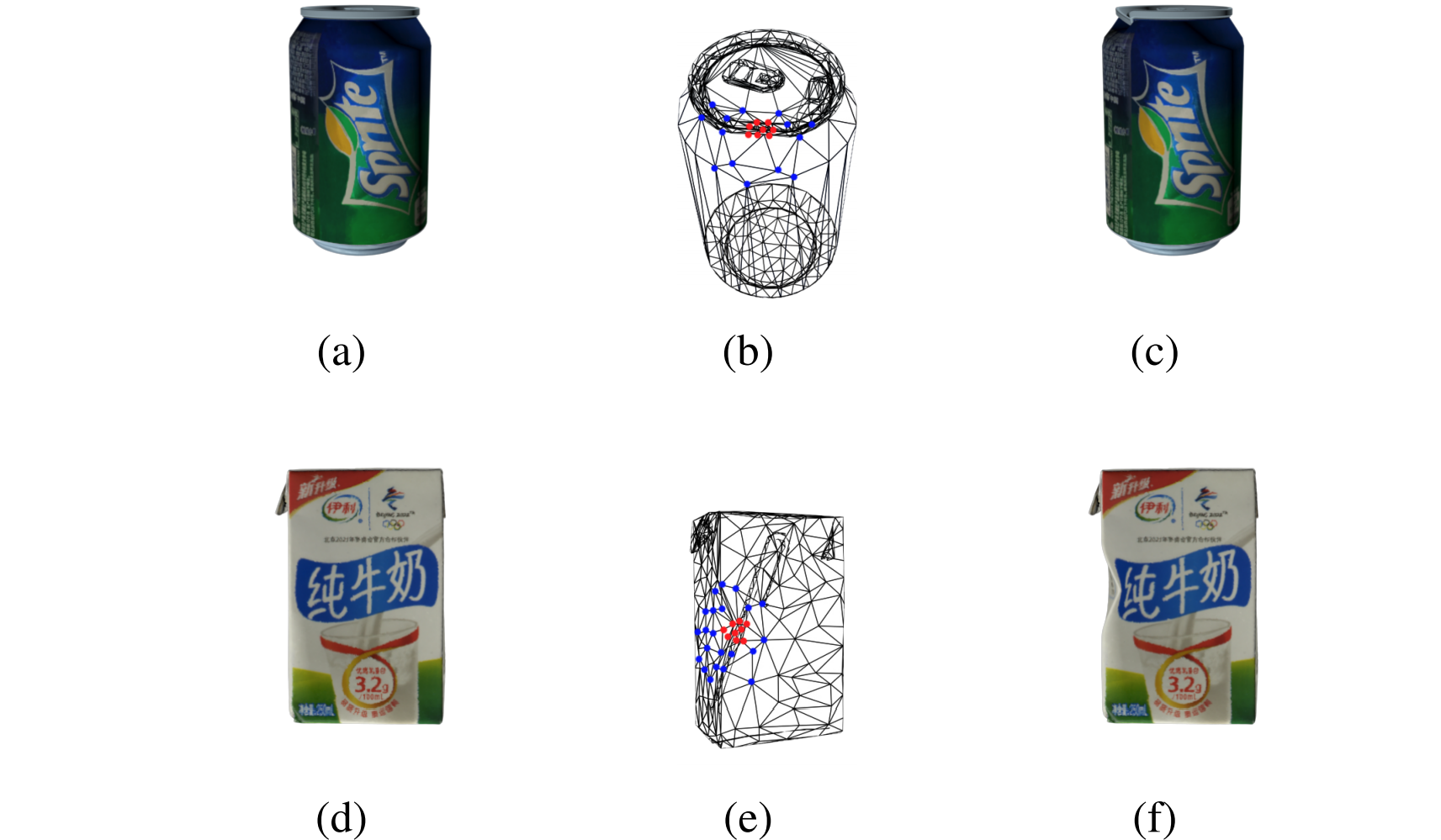
Second, Wang et al. introduce and apply a separate model for the deformation of resulting object meshes. Cans and packs may warp or bulge in a vending machine, and their synthetic data generation pipeline adds random deformations, complete with a (more or less) realistic energy-based model with rigidity parameters based on a previous work by Wang et al. (2012). The results look quite convincing:
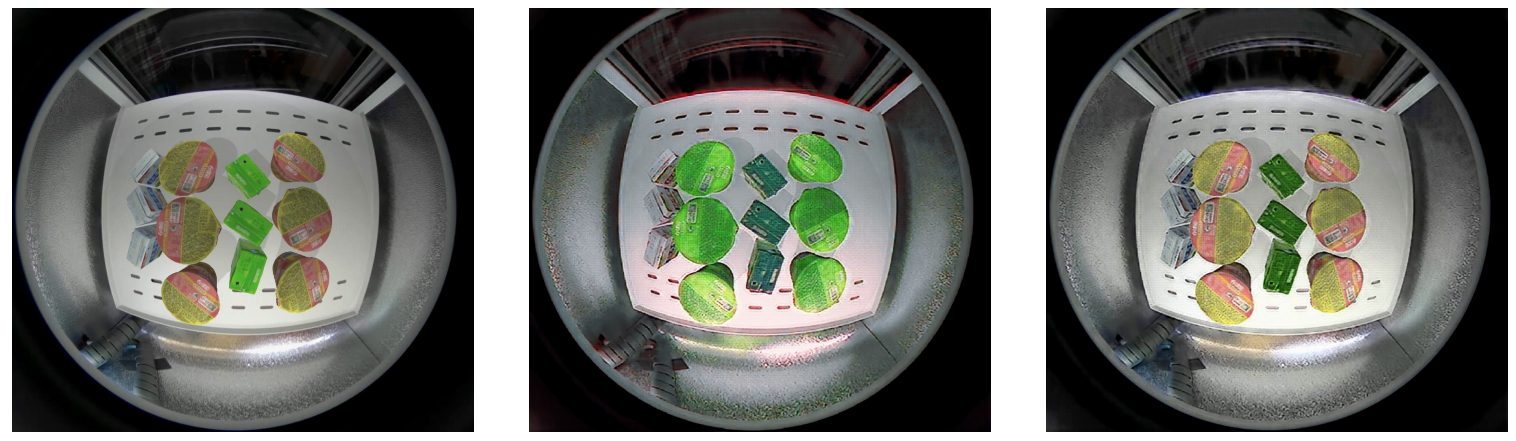
Third, the camera. Due to physical constraints, vending machines use fisheye cameras to be able to cover the entire area where objects are located. Here is the vending machine from Wang et al. and sample images from the cameras on every shelf:

3D rendering engines usually support only the pinhole camera model, so, again, Wang et al. use a separate state of the art camera model by Kannala and Brandt, calibrating it on a real fisheye camera and then introducing some random variation and noise.
Fourth, the synthetic-to-real image transfer, i.e., improving the resulting synthetic images so that they look more realistic. Wang et al. use a variation of style transfer based on CycleGAN. I will not go into the details here because this direction of research definitely deserves a separate blog post (or ten), and we will cover it later. For now, let me just say that it does help in this case; below, original synthetic images are on the left and the results of transfer are on the right:

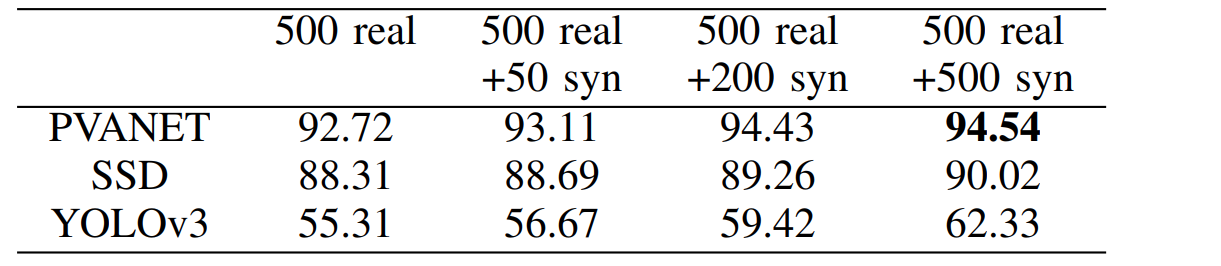
Fifth, the object detection pipeline. Wang et al. compare several state of the art object detection methods, including PVANET by Kim et al. (2016), SSD by Liu et al. (2016), and YOLOv3 by Redmon and Farnadi (2018). Unlike all the works we have seen above, these are architectures that remain quite relevant up to this day (with some new versions released, as usual), and, again, each of them would warrant a whole separate post, so for now I will just skip to the results.
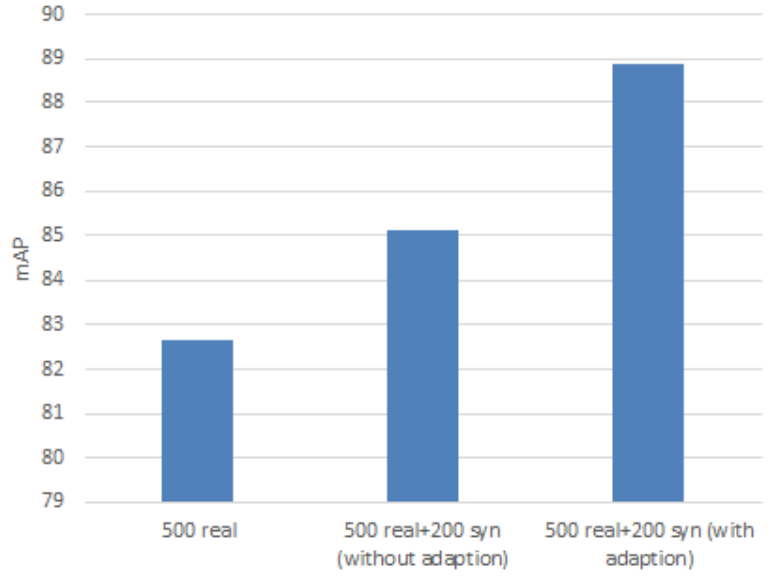
Interestingly, while the absolute numbers and quality of the results have increased substantially since 2017, the general takeaways remain the same. It still helps to have a hybrid dataset with both real and synthetic data (note also that the dataset is again rather small; this time it’s because the models are good enough to achieve saturation in this constrained setting after this kind of data and more synthetic data probably doesn’t help):
The results on a real test set are also quite convincing. Here are some samples for PVANET:

SSD:

and YOLOv3:

Interestingly, PVANET yields the best results, which is contrary to many other object detection applications (YOLOv3 should be best overall in this comparison):
This leads to our last takeaway point for today: in a specific application, it is best to redo the comparisons at least among the current state of the art architectures. It doesn’t add all that much to the cost of the project: in this case, Wang et al. definitely spent much, much more time preparing and adapting synthetic data than testing two additional architectures. But it can yield somewhat unexpected results (one can explain why PVANET has won in this case, but honestly, this would be a post-hoc explanation, you really just don’t know a priori who’s going to win) and let you choose what’s best for your own project.
Today, we have considered a sample application of synthetic data for object detection: recognizing multiple objects in small constrained spaces such as a refrigerator or a vending machine. We have seen why this is a perfect fit for synthetic data, and have used it as an example to showcase some of the progress that synthetic data has enjoyed over the past couple of years. But that’s not all: in the next post, we will consider some very recent works that study synthetic data for object detection in depth, uncovering the tradeoffs inherent in the process. Until next time!
Sergey Nikolenko
Head of AI, Synthesis AI
