
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
We have been talking about the history of synthetic data for quite some time, but it’s time to get back to 2020! I’m preparing a new series, but in the meantime, today we discuss a paper called “Learning From Context-Agnostic Synthetic Data” by MIT researchers Charles Jin and Martin Rinard, recently released on arXiv (it’s less than a month old). They present a new way to train on synthetic data based on few-shot learning, claiming to need very few synthetic examples; in essence, their paper extends the cut-n-paste approach to generating synthetic datasets. Let’s find out more and, pardon the pun, give their results some context.

On this blog, there is no need to discuss in detail what synthetic data is all about; let me just link to my first post about the data problem in machine learning and to my recent survey of the field. Synthetic data is trying to solve this problem by presenting a potentially endless source of synthetic images after a one-time investment of resources to create the virtual objects/environments.
However, this presents the obvious problem: you need to train on synthetic images but then apply the results on real photographs. This is an instance of the domain shift problem that sometimes appears in other fields as well (for instance, the “food” class looks very different in, say, the U.S. and Kenya). Here is an illustration of the domain shift problem for synthetic data from (Sankaranarayanan et al., 2018):
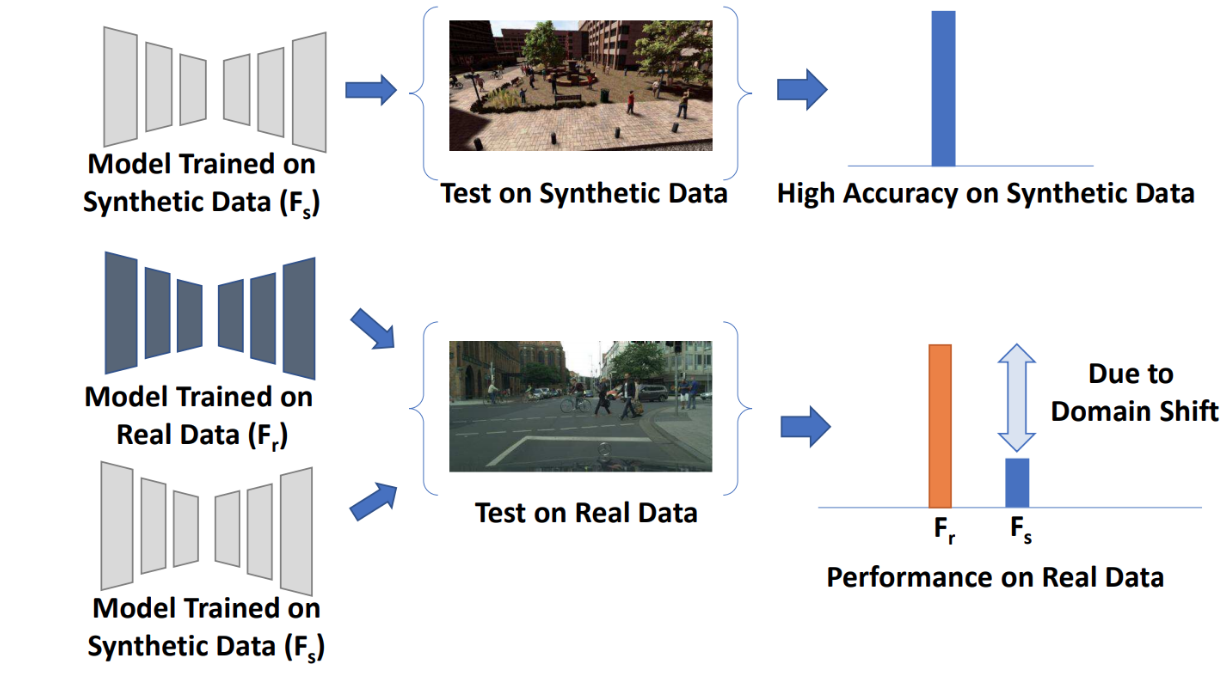
Domain adaptation is a set of techniques designed to make a model trained on one domain of data, the source domain, work well on a different, target domain. This is a natural fit for synthetic data: in almost all applications, we would like to train the model in the source domain of synthetic data but then apply the results in the target domain of real data. By now, domain adaptation is a large field of machine learning, with many interesting models that either make input images more realistic (this is usually called refinement) or change the training process in such a way that the model does not differentiate between synthetic and real domains.
We will definitely have many more posts that deal with domain adaptation in this blog. Today’s paper, however, is basically a modification of one of the most simple and straightforward approaches to generating synthetic datasets. Let us first discuss this idea in general and then get back to Jin and Rinard.
Existing synthetic datasets also often exploit this idea of separating the object from the background. Usually it appears in the form of placing synthetic objects on real backgrounds. One usually has a virtually endless source of real backgrounds that are perfect for learning in every way but do not contain the necessary objects, so the idea is to paste synthetic objects in the most realistic way possible.
In some problems, it is relatively straightforward. For example, one dataset mentioned in the paper by Jin and Rinard, SynSign by Moiseev et al. (2013), uses this trick to produce synthetic photographs of traffic signs. They cut out augmented (distorted) synthetic images of traffic signs and put them against real backgrounds:

This is easy enough to do for traffic signs:
Modern synthetic data research can successfully apply the same trick to much more complex situations. For example, the Augmented Autonomous Driving Simulation (AADS) dataset (Li et al., 2019) helps train self-driving cars by blending synthetic cars against real-world backgrounds:
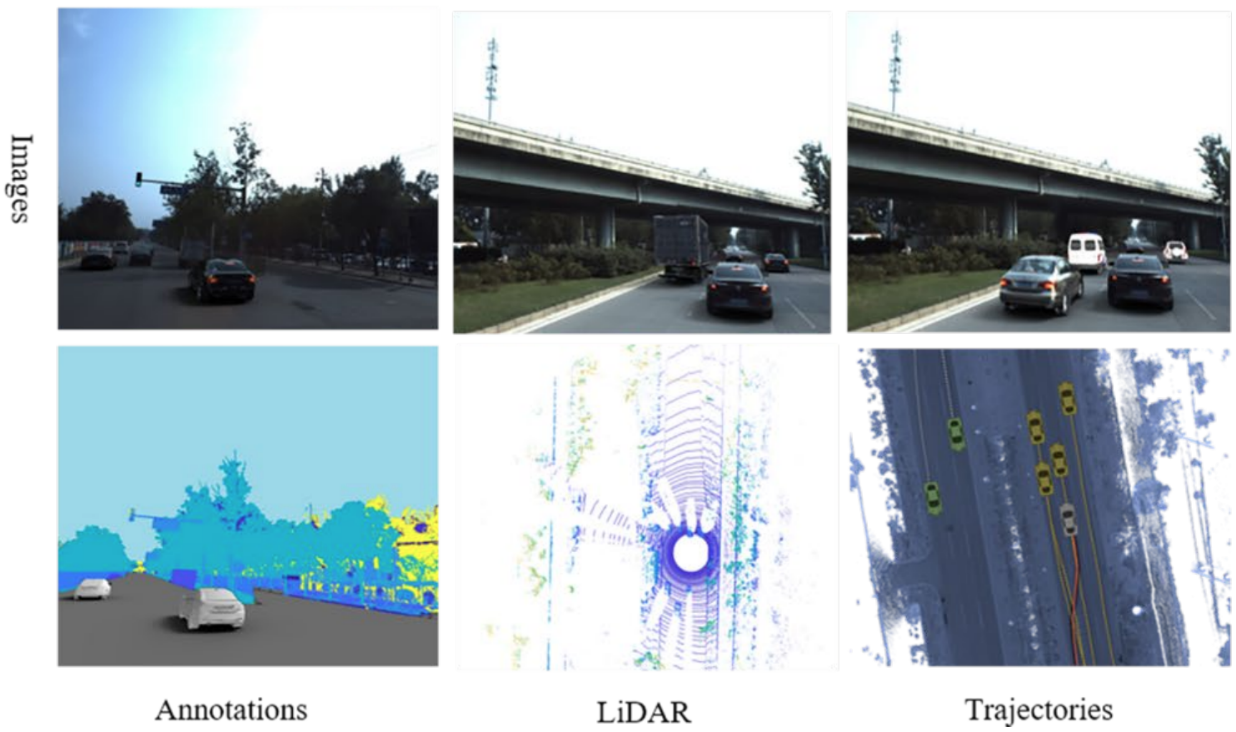
I doubt you can even differentiate images in the top row from real photos of cars in context, especially given the relatively low resolution of this picture.
AADS has a much more complex pipeline than just “cut-n-paste”, and I hope to talk to you about it in detail in a later post. But the basic point still stands: in many problems, 3D models of the objects of interest are far easier than 3D models of the entire environment, but at the same time there is a source of real-world backgrounds, and you can try to paste virtual objects onto them in a smart way to make realistic synthetic datasets.
Jin and Rinard take this approach to the next level. Basically, their paper still presents the same basic pipeline:
The devil, however, is in the details; a few tricks take this simple approach to provide some of the very best results available in domain adaptation and few-shot learning.
First, the sampling. One common pitfall of computer vision is that when you have relatively few examples of a class, they cannot come in a wide variety of backgrounds. Hence, in a process akin to overfitting the networks might start learning the characteristic features of the backgrounds rather than the objects in this class.
What is the easiest way out of this? How can we tell the classifier that it’s the object that’s important and not the background? With synthetic images, it’s easy: let’s place several different objects on the same background! Then, since the labels are different, the classifier will be forced to learn that backgrounds are not important and it is the objects that differentiate between classes.
Therefore, Jin and Rinard take care to introduce balanced sampling of objects and backgrounds. The basic procedure samples a random biregular graph so that every object is placed on an equal number of backgrounds and vice versa, every background is used with the same number of objects.
But that’s not all. The second idea used in this paper stems from the obvious fact that the classifier must learn to distinguish between different objects. Therefore, it would be beneficial for training to concentrate on the hard cases where the classifier might confuse two objects.
In the paper, this idea comes in two flavors. First, specifically for images Jin and Rinard suggest to superimpose one object on top of another, so that the previous object provides a maximally confusing context for the next one. A picture would be worth a thousand words here but, alas, the paper does not have any. But their second way to use the same idea is even more interesting.
To give context to the idea of robustness training, I need to take a step back. You might remember how a few years ago, adversarial examples were all the rage. Remember this famous picture from Goodfellow et al. (2014)?

What this means is that due to the simplified structure of neural networks (they are “too linear”, so to speak), you can find a direction in the image space such that even a small step in this direction (note the 0.007 coefficient in the linear combination) can lead to big changes in classifier predictions. How do we find this direction? Easy: just take a gradient of the loss function with respect to the input (rather than the weights, as in training) and go either where the correct class’ probability is reduced the most or where the probability of the class you want to get is increased the most. This is actually explained below the picture.
Since 2013-2014, when adversarial examples first appeared, this field has come a long way. By now, there are a lot of different sorts of adversarial attacks, including attacks that work in the physical world (Kurakin et al., 2016): you can print out an adversarial image, take a photo, and it is still misclassified! The attacks also cause defenses to appear; naturally, attacks have the first move but usually you can defend against a given attack. A recent survey by Xu et al. (2019) lists about 150 references, and the field is growing.
One of the easiest ways to defend against the attack above is to introduce changes into the training process. These gradients with respect to the input can be computed during training as well, so during training you can have access to adversarial examples. Hence, you can
This is exactly the idea of robustness training that Jin and Rinard suggest for synthetic images. You have a synthetic image that might look a little unrealistic and might not be hard enough to confuse even an imperfect classifier. What do you do? You can try to make it harder for the classifier by turning it into an adversarial example.
With all these ideas combined, Jin and Rinard obtain a relatively simple pipeline that is able to achieve state-of-the-art results by training with only a single synthetic image of each object class. Note that there is no fancy domain adaptation here: all ideas can be thought of as smart augmentations.
Today, after a few posts on the history of synthetic data we are taking a break from long series. Here I have reviewed a recent paper from arXiv and discussed its ideas. This paper touches on many different ideas from different parts of machine learning. As we review additional papers in this series, we hope to highlight interesting research and add some new ideas of our own to the mix.
Next time, we will have some more ideas to discuss. Until then!
Sergey Nikolenko
Head of AI, Synthesis AI
