
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
In the first three posts of this series, we have seen several ways to overcome the data problem in machine learning: first we posed the problem, then discussed one-shot and zero shot learning, and in the third post presented the reinforcement learning way of using no data at all. In this final installment, we discuss the third direction that modern machine learning takes to help with the lack of labeled data: how can we use unlabeled data to help inform machine learning models?

Source: https://www.kickstarter.com/projects/1323560215/unlabeled-the-blind-beer-tasting-game/posts/2076400
For many problems, obtaining labeled data is expensive but unlabeled data, especially data that is not directly related to the problem, is plentiful. Consider the computer vision problems we talked about above: it’s very expensive to get a large dataset of labeled images of faces, but it’s much less expensive to get a large dataset of unlabeled such images, and it’s almost trivial to just get a lot of images with and without faces.
But can they help? Basic intuition tells that it may not be easy but should be possible. After all, we humans learn from all sorts of random images and get an intuition about the world around us that generalizes exceedingly well. Armed with this intuition, we can do one-shot and zero-shot learning with no problem. And the images were never actually labeled, our learning can hardly be called supervised.
In machine learning, the intuition is similar. Suppose you want to teach a model to tell cats and dogs apart on one-megapixel photos. Mathematically speaking, each photo is a vector of about 3 million real values (RGB values for every pixel; they are in fact discretized but we will forgo this part), and our problem is to construct a decision surface in the space R3,000,000 (sounds formidable, right?). Obviously, random points in this space will look like white noise on the image; “real photos”, i.e., photos that we can recognize as something from the world around us, form a very low-dimensional, at least compared to 3 million, manifold in this space (I am using the word “manifold” informally, but it probably really is an open subset: if you take a realistic photo and change one pixel or change every pixel by a very small value, the photo will remain realistic). Something like the picture we already saw in the first installment of this series:
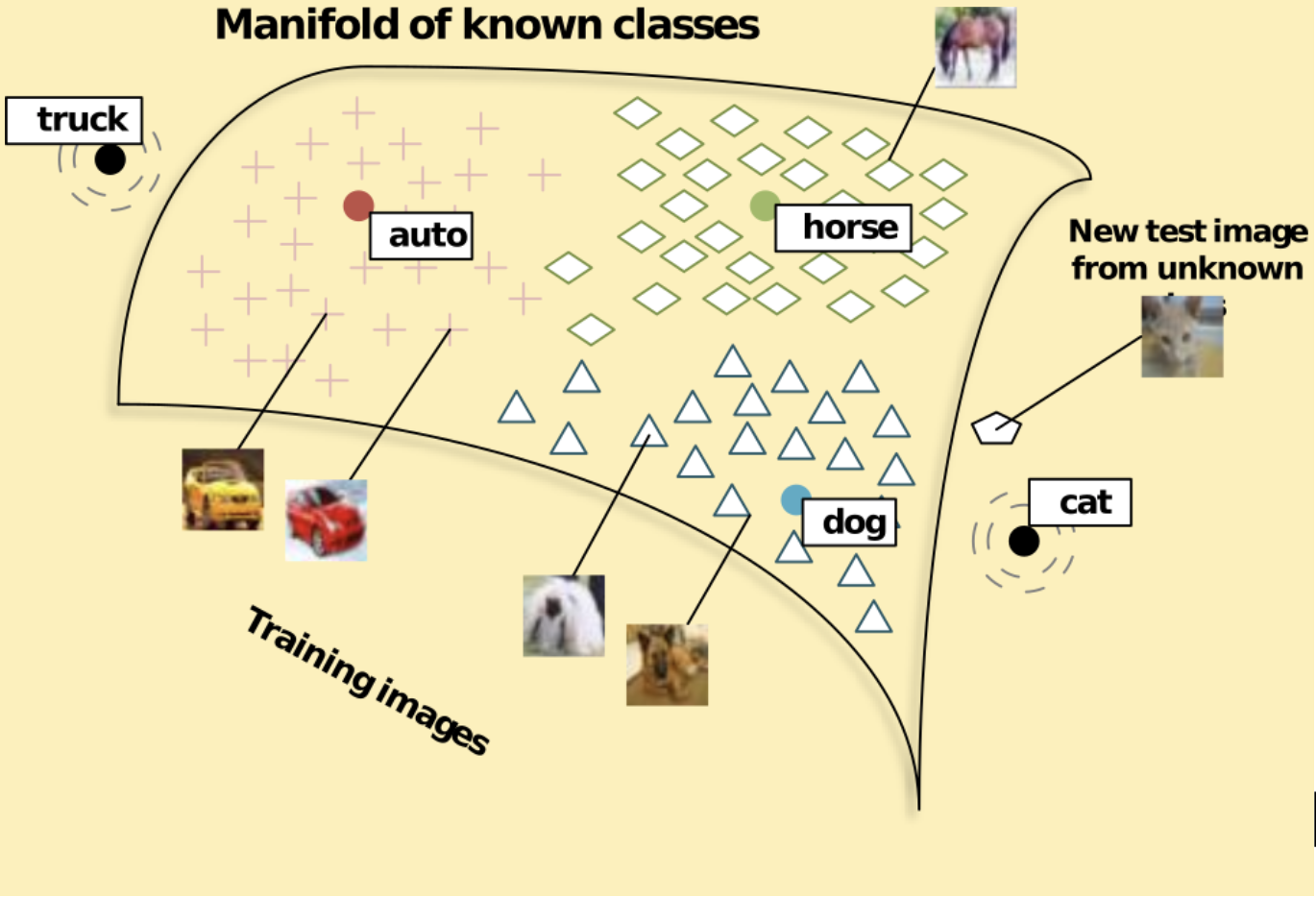
Source: https://nlp.stanford.edu/~socherr/SocherGanjooManningNg_NIPS2013.pdf
It is now not surprising that the main problem a machine learning model faces in real life computer vision is not to separate cats from dogs given a good parametrization of this extremely complicated manifold but to learn the parametrization (i.e., parameter structure) itself. And to learn this manifold, unlabeled data is just as useful as labeled data: we are trying to understand what the world looks like in general before we label and separate individual objects.
Although it’s still a far cry from human abilities (see this recent treatise by Francois Chollet for a realistic breakdown of where we stand in terms of general AI), there are several approaches being developed in machine learning to make use of all this extra unlabeled data lying around. Let us consider some of them.
The first way is to use unlabeled data to produce new labeled data. The idea is similar to the EM algorithm: let’s assign labels to images where we don’t have them with imperfect models trained on what labeled data we have. Although we won’t be as sure that the labels are correct, they will still help, and we will revisit and correct them on later iterations. In a recent paper (Xie et al., 2019), researchers from Google Brain and Carnegie Mellon University applied the following algorithm:
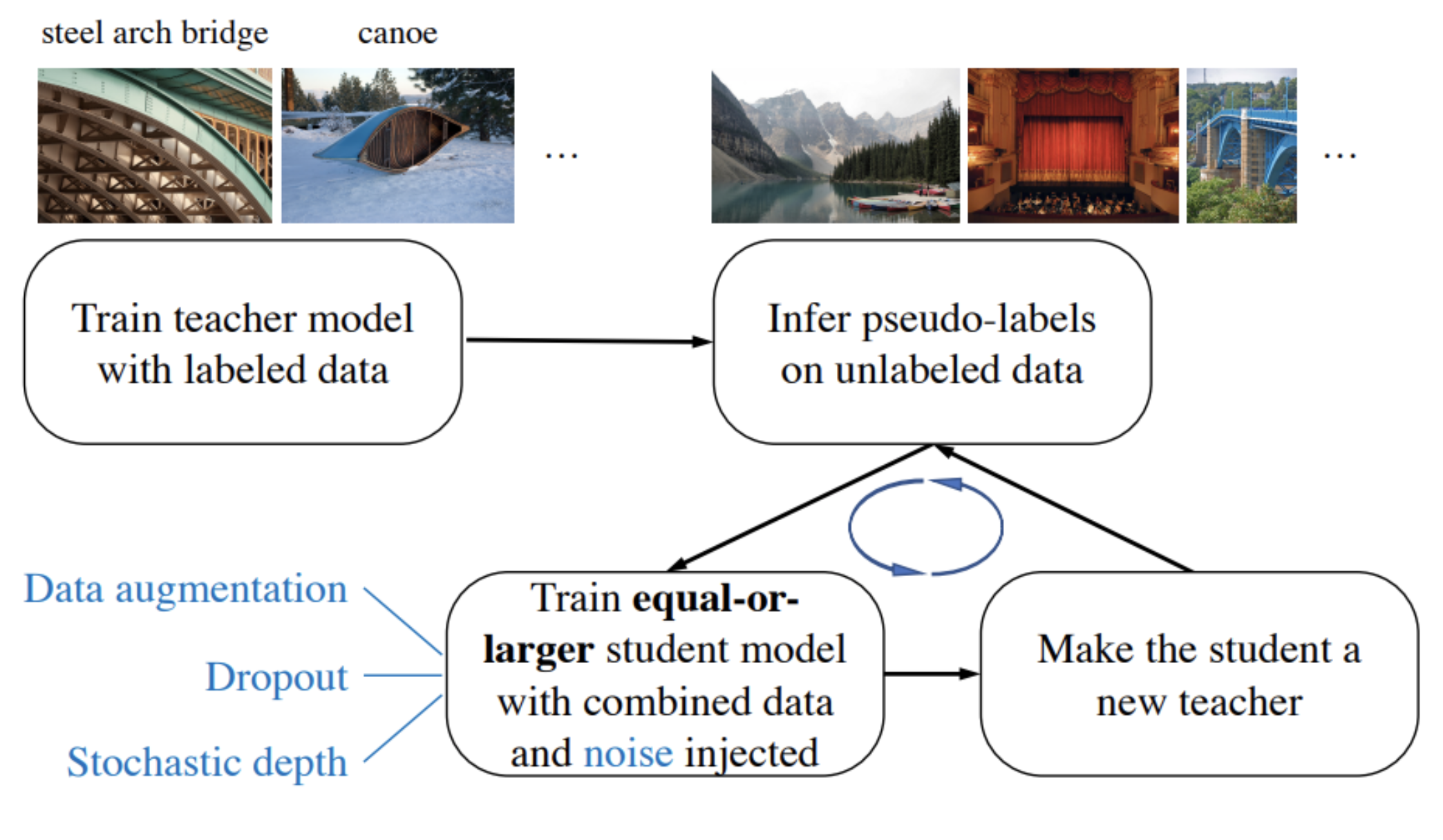
While this is a rather standard approach, used many times before in semi-supervised learning, by smartly adding noise to the student model Xie et al. managed to improve state of the art results on ImageNet, the most standard and beaten-down large-scale image classification dataset.

For this, however, they needed a separate dataset with 300 million unlabeled images and a lot of computational power (3.5 days on a 2048-core Google TPU, on the same scale as needed to train AlphaZero to beat everybody in Go and chess; last time we discussed how these experiments have been estimated to cost about $35 million to replicate).
Cut-and-Paste Models for Unsupervised Segmentation
Another interesting example of replacing labeled data with (lots of) unlabeled comes from a very standard computer vision problem: segmentation. It is indeed very hard to produce labeled data for training segmentation models (we discussed this in the first post of the series)… but do we have to? If we go back to segmentation models from classical computer vision, they don’t require any labeled data: they cluster pixels according to their features (color and perhaps features of neighboring pixels) or run an algorithm to cut the graph of pixels into segments with minimal possible cost. Modern deep learning models work much better, of course, but it looks like recent advances make it possible to train deep learning models to do segmentation without labeled data as well.
Approaches such as W-Net (Xia, Kulis, 2017) use unsupervised autoencoder-style training to extract features from pixels and then segment them with a classical algorithm. Approaches such as invariant information clustering (Ji et al., 2019) develop image clustering approaches and then apply them to each pixel in a convolution-based way, thus transforming image clustering into segmentation.
One of the most intriguing lines of work that results in unsupervised clustering uses GANs for image manipulation. The “cut-and-paste” approach (Remez et al., 2018) works in an adversarial way:
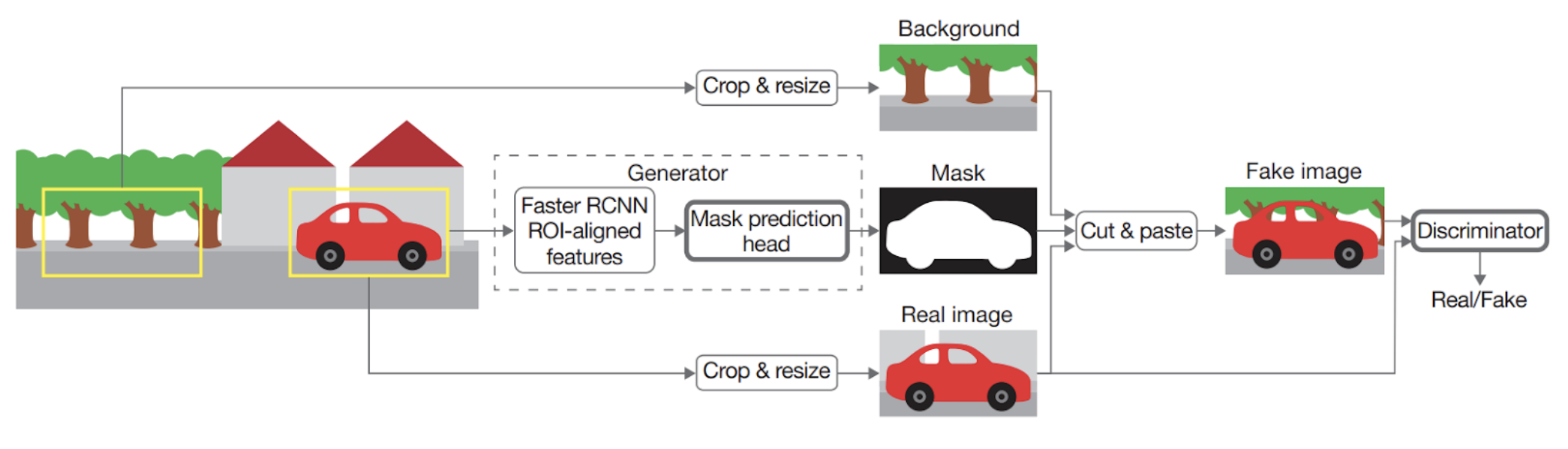
The idea is that good segmentation masks will make for realistic pasted images, and in order to convince the discriminator the mask generator will have to learn to produce high-quality segmentation masks. Here is an illustration:

A bad mask (a) produces a very unconvincing resulting image (b), while a good segmentation mask (c) makes for a pasted image (d) which is much harder to distinguish from a real image (e).
The same effect appeared in a paper where I participated recently. The SEIGAN (Segment-Enhance-Inpaint GAN) model (Ostyakov et al., 2019) has been designed for compositional image generation, learning to transfer objects from one image to another in a convincing way. Similar to the cut-and-paste approach above, as a side effect of the SEIGAN model we obtained high-quality unsupervised segmentation! I won’t go into details, but here is an illustration of the SEIGAN pipeline:
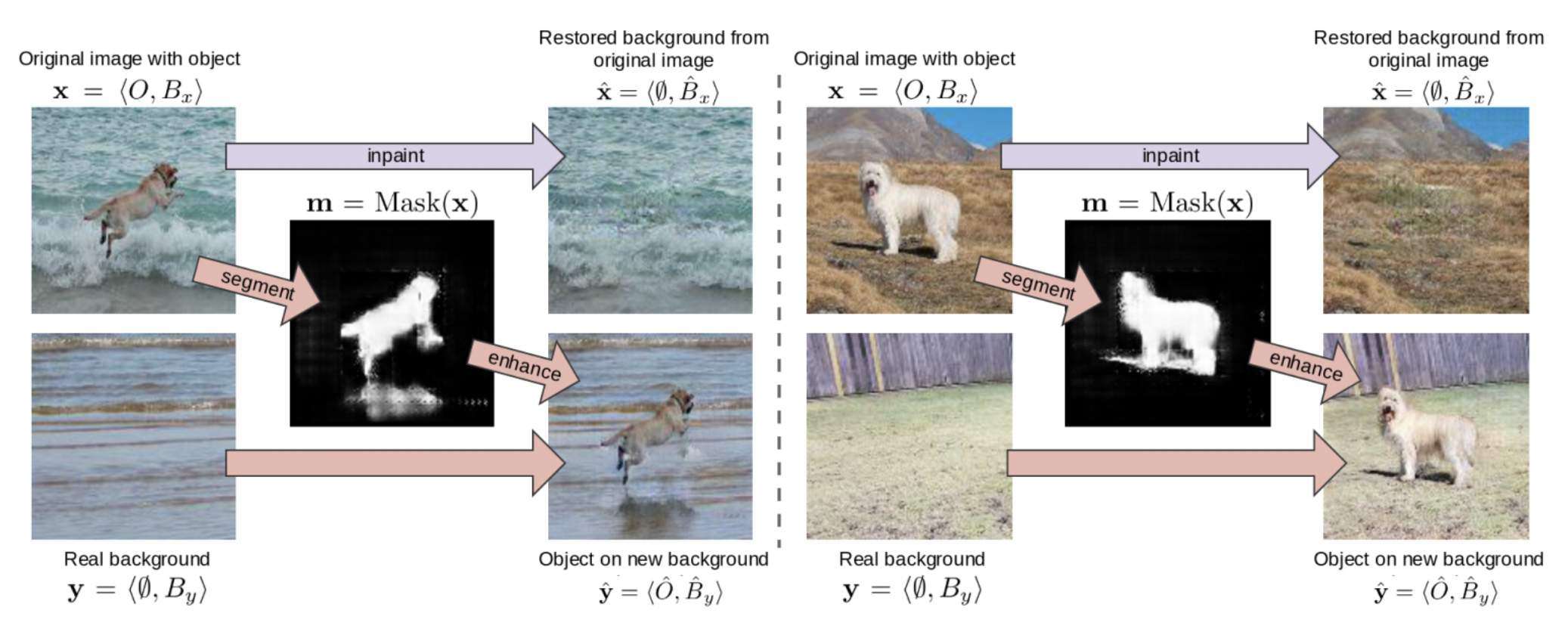
In this pipeline, segmentation is needed to cut out the object that we’d like to transfer. The network never receives any correct segmentation masks for training. It learns in a GAN-based way, by training to fool discriminators that try to tell images with transferred objects apart from real images (I simplify a bit, actually there are plenty of loss functions in SEIGAN in addition to the adversarial loss, but still no supervision), so segmentation comes for free, as a “natural” way to cut out objects. Perhaps that’s not unlike how we learned to do segmentation when we were infants.
Semi-supervised teacher-student training and unsupervised segmentation via cut-and-paste are just two directions out of many that are currently being developed. In these works, researchers are exploring various ways to trade the need for labeled datasets for extra unlabeled data, extra unrelated data, or extra computation, all of which is becoming more and more readily available. I am sure we will hear much more about “unsupervised X” in the future, where X might take the most unexpected values.
It is time to sum up the series. Faced with the lack of labeled data in many applications, machine learning researchers have been looking for ways to solve problems without sufficiently large labeled datasets available. We have discussed three basic ideas that have already blossomed into full-scale research directions:
As you might have guessed from the name of the company, Synthesis AI presents a different way to tackle the data problem: synthetic data. In this approach, models are trained on automatically generated data, where labels usually come for free after a one-time upfront investment of labor into creating the synthetic simulation. We specialize in creating synthetic environments and objects, producing synthetic labeled datasets for various problems, and solving the domain transfer and domain adaptation problems, where models trained on synthetic data need to be transferred to operate on real photos.
Next time, we will speak more about synthetic data in modern machine learning. Stay tuned!
Sergey Nikolenko
Head of AI, Synthesis AI
