
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
CVPR 2022, the largest and most prestigious conference in computer vision and one of the most important ML venues in general, has just finished in New Orleans. With over 2000 accepted papers, reviewing the contributions of this year’s CVPR appears to be a truly gargantuan task. Over the next series of blog posts, we will attempt to go over the most interesting papers directly related to our main topic: synthetic data. Today, I present the first but definitely not the last installment devoted to papers from CVPR 2022.

As always, CVPR is large, and it contains multitudes, but this year one of the main topics is neural radiance fields (NeRF). These models seem to be the new GANs today, or, better to say, new visual Transformers that were in turn the new GANs a couple of years ago. We view image synthesis, especially controlled synthesis with 3D information, as a key idea that can propel synthetic data forward, so I plan to devote several upcoming posts to recent NeRF advancements.
But in this series, let me begin with more straightforward applications of synthetic data that have found their way into the CVPR program this year. On the list today we have several new synthetic datasets, usually related to specific use cases of synthetic data; many of them touch upon problems that we have already discussed on this blog but some introduce entirely new avenues for research.
Synthetic data is a well-established field, and this blog has already documented many of its achievements. By now, it is not enough to just generate a new synthetic dataset to get to a top conference like CVPR (to be honest, it was never enough): you need some twist on the tried-and-true formula of “make or obtain 3D CG models, render images, train CV models, profit”. In this section, let us see what new twists CVPR 2022 has brought.
And one more thing before we begin: we have recently made public a new database that will gradually collect all things related to synthetic data. It is called OpenSynthetics, and it already has quite a lot of content on synthetic datasets, papers, and code repositories related to synthetic data. So in these review posts, I will also give links to the corresponding OpenSynthetics pages.
It had always been common wisdom that GANs, despite their excellent image generation quality and usefulness for synthetic-to-real refinement, cannot really help with data generation from scratch: there was no way to generate labeled data and no easy way to label generated images. Basically, ever since ProGAN and BigGAN (OpenSynthetics; both released in 2018) you could use GANs to generate new realistic images with sufficient quality, but you would still have to label them afterward as if they were just new images. And this has always meant that GANs are useless for synthetic data generation: we have never lacked new images of ImageNet categories, the bottleneck has always been in the labeling.
Well, it looks like there is a way to generate labeled data now! This research direction, driven by NVIDIA researchers, bore its first fruit last year when Zhang et al. presented DatasetGAN on CVPR 2021. Their pipeline works as follows: use StyleGAN to generate several images (say, cars), hand-annotate a few of them for your task (say, segmentation of various car parts), and train a very small model (style interpreter) to produce similar segmentation masks from StyleGAN features. At the cost of labeling a few images (literally, a few: DatasetGAN required 16 labeled heads or about 1000 polygons), you can use StyleGAN to generate as many labeled images as you wish, with the usual excellent StyleGAN quality:

On this year’s CVPR, Li et al. continued this line of research and introduced BigDatasetGAN based on BigGAN instead of StyleGAN. The difference is that BigGAN is better suited for generating a wide variety of different image categories, so now you can hand-label 8000 images, 8 for each category, and have a single model able to produce 1000 ImageNet1K categories that come pre-labeled for segmentation:

The authors report results improved over supervised pretraining for standard segmentation models.
Does this mean that synthetic data is soon to be absorbed into deep generative models? Time will tell, but I am not sure: generative models are still hard to train, and this approach requires an operational large-scale GAN with the desired categories before we go into labeling. Moreover, DatasetGANs deal only with segmentation so far, and I have my reservations about more complex labeling such as depth. Still, this is an exciting development that shows the power of modern generative models, and its results provide a set of completely new tools for the arsenal of synthetic data generation.
ABO stands for Amazon Berkeley Objects (OpenSynthetics), a new indoor environment and object dataset presented in the work by Collins et al., who are, you guessed it, researchers from UC Berkeley and Amazon. ABO answers the same need as the classical but sadly unavailable SunCG dataset, ShapeNet, or Facebook AI Habitat: it provides a large-scale catalogue of 3D models of indoor household objects—chairs, shoes, coat hangers, rugs, tables, and so on—that can be placed in a variety of indoor environments with available renderings.
Since Amazon is… well, Amazon, ABO is based on product listings: the dataset contains nearly 150K listings of 576 product types with hi-res photos and over 8000 turntable “360° view” images. It also includes nearly 8000 handmade high-quality 3D models of various objects. Moreover, and this is unique to ABO, the objects come with attributes that identify their material, which is useful for physically-based rendering:

The authors show that training on ABO leads to better results than training on ShapeNet for state-of-the-art 3D reconstruction models. They also introduce a new task that has been enabled by their work, material estimation, and present novel network architectures for this task. In general, this is an impressive effort, and I hope that it will enable many new works in 3D scene understanding, indoor navigation, and related fields:

While ABO provides some information about the material of the object, it is far from exhaustive. Stanford researchers Gao et al. attempt a far more ambitious task in their new ObjectFolder 2.0 dataset (OpenSynthetics): they aim to model complete multisensory profiles of real objects. This means that they aim to capture not only the 3D shape and material of an object (and therefore its texture) but also other sensory modalities including audio (how a cup clinks when you touch it with a spoon) and feeling to the touch. This information can be later used for problems such as contact localization (where exactly have I touched this object?) that are both difficult and important in robotics:

Since all of these modalities are location-dependent, they cannot all be explicitly stored in the dataset. The authors use implicit neural representations, that is, each object is defined by a few neural networks (multilayer perceptrons) that are trained to convert coordinates into whatever is necessary; VisionNet models the neural scattering function, AudioNet models the location-specific part of the audio response from applying a unit force to this location, while TouchNet predicts the deformation map and tactile image (geometry of the contact surface):

ObjectFolder 2.0 contains these representations for 1000 household objects such as cups, chairs, pans, vases, and so on.
Gao et al. test their dataset with three downstream tasks that require multimodal sim2real object transfer: object scale estimation based on vision and audio, contact localization based on audio and tactile response, and shape reconstruction based on visual and tactile data. They report improved performance across all tasks, and this dataset indeed looks like a possible next step for object manipulation in robotics.
Pose estimation is a classical computer vision problem; as in all problems related to the understanding of the 3D world from 2D images, synthetic data comes to mind naturally: it is impossible to do exact manual labeling for pose estimation, and even inexact human labeling is very copious. This goes double for more detailed tasks such as hand pose estimation, so it is no wonder that there exist synthetic datasets for this problem; in particular, here at Synthesis AI we have a variety of hand gestures as part of our HumanAPI.
In “ArtiBoost: Boosting Articulated 3D Hand-Object Pose Estimation via Online Exploration and Synthesis” (OpenSynthetics), Li et al. make the next step: they consider not just hand gestures but hands holding various objects in different positions. The authors consider the “composited hand-object configuration and viewpoint space” (CCV space) where you can vary object types, composite hand-object poses, and camera viewpoints:
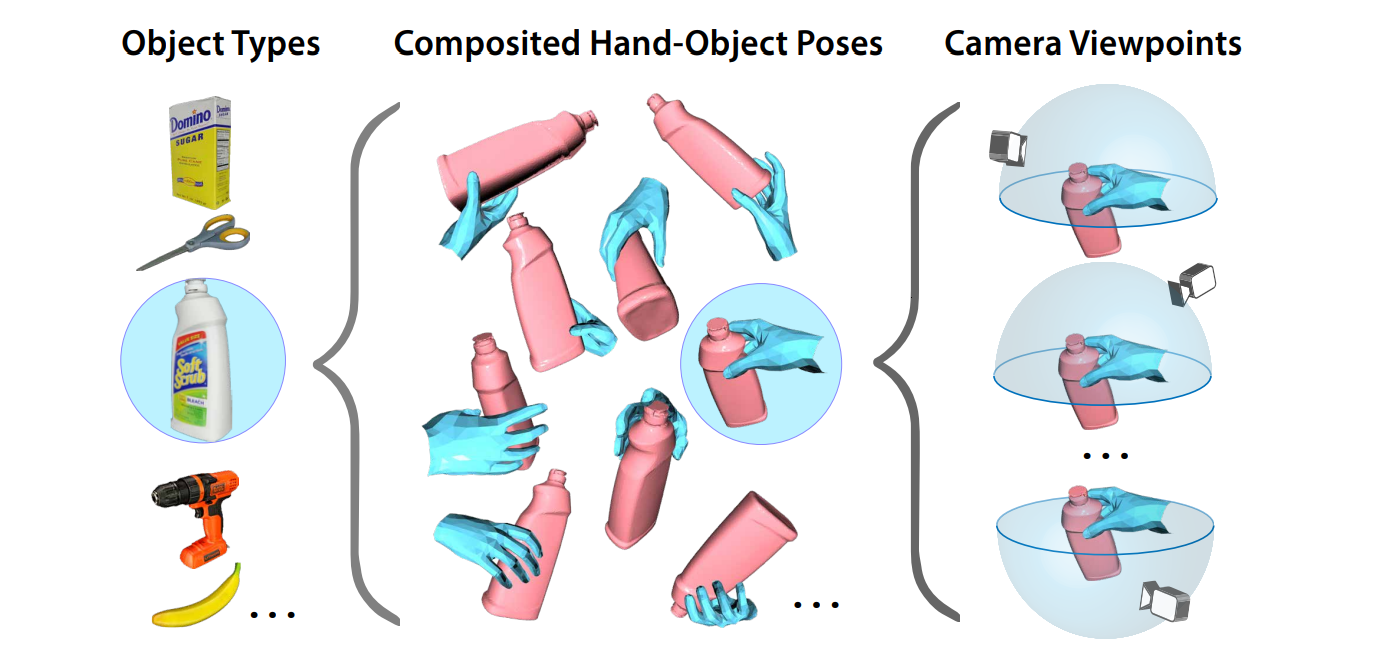
Then they apply a newly developed grasp synthesis method (that I will not go into), obtain renderings of a synthetic hand grasping the object, and use these images for training.
What is most interesting for me in this work is that it is an example of the “closing the loop” idea that we have been proposing for quite some time ago here at Synthesis AI; in particular, pardon the self-promotion, I discussed it as an important idea for the future of synthetic data in Chapter 12 of my book.
In this case, Li et al. do not merely sample the CCV space and create a randomly generated dataset of synthetic hands with objects. They assign weights to different objects, poses, and viewpoints, and update these weights with feedback obtained from the trained model, trying to skew the sampling towards hard examples, a technique known in other contexts as “hard negative mining”. It is great to see that “closing the loop” is gaining traction, and I am certain it can help in other problems as well.
And now let us, pardon the pun, shift to data about the outdoors. We begin with autonomous driving. The work “SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation” (OpenSynthetics), coming from ETH Zurich researchers Sun et al., is a pure synthetic dataset presentation for SHIFT, a synthetic driving dataset—but SHIFT is far from a “regular” synthetic dataset with some labeled images! The problem that Sun et al. recognize here is that autonomous driving requires the system to adapt to constantly changing conditions: if you are driving and it starts raining, the view around you changes significantly and maybe quite quickly, and the computer vision system has to keep working fine.
To help cope with that, SHIFT contains explicit “domain shifts” across several different domains such as weather conditions, time of day, surroundings, and so on:

So far this is quite standard fare for autonomous driving simulators. What’s more, SHIFT provides continuous shifts across domains whenever possible. You can have day gradually turning into night or rain starting on a sunny day:

Naturally, each frame is annotated in the usual modalities, with object bounding boxes, segmentation maps, depth maps, optical flow, and LiDAR point clouds.
Based on SHIFT, the authors investigate how various object detection and segmentation models cope with these domain shifts. They demonstrate that conclusions about robustness to domain shift that can be made on synthetic data also transfer to real datasets. I think that’s an important validation for synthetic data in general: it turns out that synthetic data can help evaluate machine learning models in ways that real data may fail to provide.
In another classical synthetic data paper, EPFL researchers Yan et al. present TOPO-DataGen (OpenSynthetics), an automated synthetic data generation system that utilizes available geographic data such as LiDAR point clouds, orthophotographs, or digital terrain models to create synthetic scenes of various parts of the world, complete with the usual synthetic modalities such as depth maps, normals, segmentation maps, and so on:

Generated images look very impressive and highly realistic, which is made slightly easier by the fact that they are aerial images taken from far away. Based on TOPO-DataGen, Yan et al. develop a new CrossLoc model for absolute localization (i.e., estimating the 6D camera pose in space) that works with several input modalities. They also show some impressive demos of trajectory reconstruction from aerial images based on CrossLoc. In general, while synthetic satellite and aerial images have already been generated, I believe this is the first attempt to bring together the different modalities that are actually often available in current practice.
Finally, a very specific but fun use case: simulating snowfall. Autonomous driving should work under all realistic weather conditions, including heavy snow. But snow presents two problems that are especially bad for LiDARs: first, the ground becomes wet, which changes its reflective properties, and second, the particles of snow in the air also interact with the laser beam, leading to absorption and backscattering that attenuate and introduce a lot of noise into the LiDAR signal.
Hahner et al. present a snowfall simulation system able to augment synthetic LiDAR datasets (in this case, STF by Bijelic et al. that itself introduced a fog simulation system) with special models for wet ground reflection and the influence of scattering particles. As a result, 3D object detection models trained with this augmentation perform much better; in the illustration below, note that the rightmost results contain no spurious objects, and predicted bounding boxes (black) match the ground truth (green) very well:
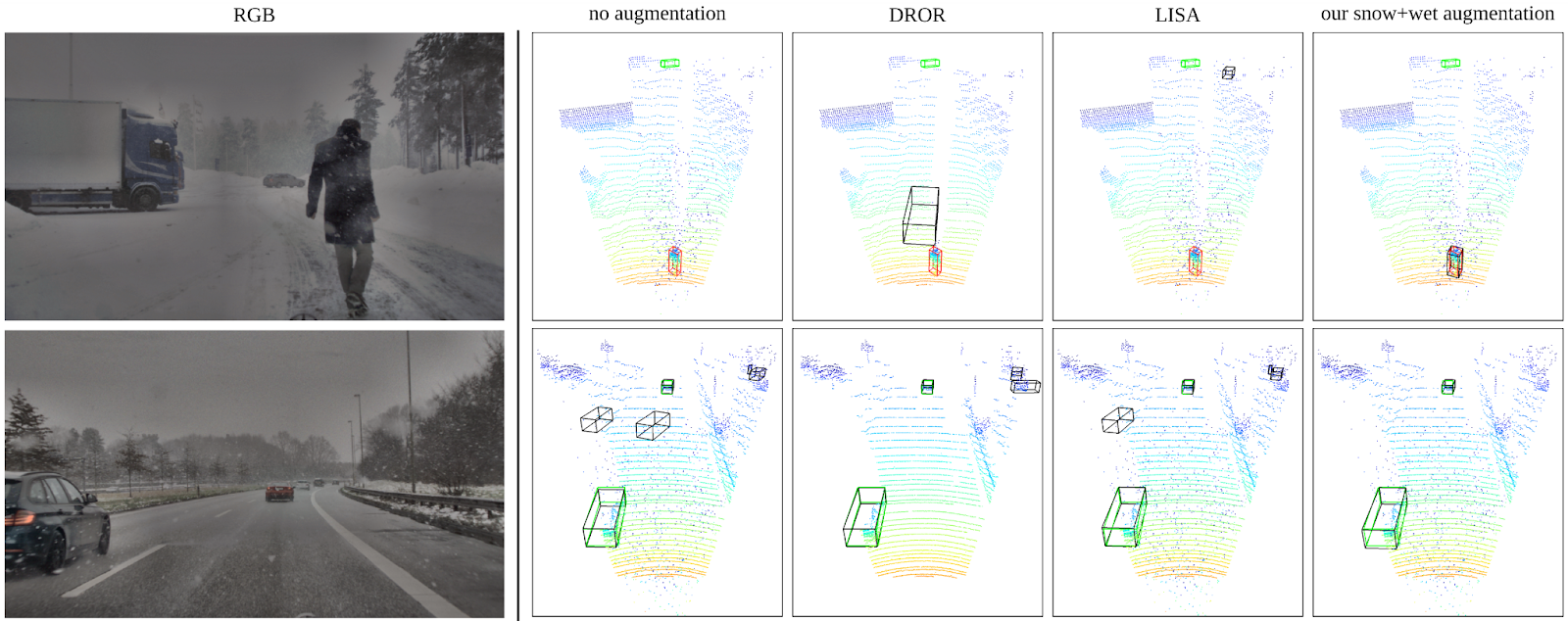
Today, we have begun our long journey through CVPR 2022. We have looked at papers that introduce new synthetic datasets, usually going far beyond simple generation of labeled images and sometimes defining completely new tasks. Next time, we will talk about papers that present specific use cases for synthetic data, that is, validate the use of synthetic data in practical computer vision tasks. Admittedly, it’s a blurry line with this first installment, but this post is getting quite long as it is. Until next time, stay tuned to the Synthesis AI blog, and check out OpenSynthetics!
Sergey Nikolenko
Head of AI, Synthesis AI
