
AI Safety IV: Sparks of Misalignment
This is the last, fourth post in our series...
Some of the most widely publicized results in machine learning in recent years have been related to image generation. You’ve heard of DALL-E a year ago, and now you’ve heard of DALL-E 2, Midjourney, and Stable Diffusion, right? With this post, I’m starting a new series where I will explain the inner workings of these models, what their differences are and how they fit into the general scheme of deep generative models. Today, we begin with a general overview.

Generative AI models are a staple of machine learning. One of the first functional machine learning models, the naive Bayes classifier developed in the 1960s, was an early form of generative AI: you can write new text with a trained naive Bayes model, it just won’t make any sense (since naive Bayes makes the bag-of-words assumption, the text will be just random words sampled in a way consistent with the desired topic).
Generating images, however, is more difficult than generating text. Just like text, an image is a high-dimensional object: a 1Mpix color photo is defined by about 3 million numbers! Unlike text, however, making extremely strong assumptions such as the bag-of-words model doesn’t make a lot of sense. In the world of images, “words” are pixels, and while naive Bayes is a pretty good text classifier, individual pixels are too simple to be useful even for classification, let alone generation.
The first generative models that worked for images were autoregressive: you generate the next pixel conditioned on the already generated previous pixels. PixelCNN and PixelRNN were state-of-the-art models for their time (2016), and it might be that with modern architectures, such models could produce state-of-the-art results even today. The problem, however, is that you would have to run the model a million times to get an image with a million pixels, and there is no way to parallelize this process because you need to know the value of pixel number k-1 before you can generate pixel number k. This would be way too slow for high-definition images, so we will not return to purely autoregressive models in this survey.
Next, we need to distinguish between pure image generation and conditional generation: is it enough to just get a “person who does not exist” or do you want to control the scene with some kind of a description? Significant progress in the former problem was done in 2017-2018 by NVIDIA researchers who specialized in generative adversarial networks (GANs); their ProGAN (progressively growing GAN) model was the first to do high-definition generation (drawing human faces with up to 1024×1024 pixels) with few artifacts that had previously plagued generative models. Later, the same team switched to conditional generation and started working on the StyleGAN family of models, where you can mix and match different levels of features from different images, e.g., take coarse features such as the shape of a face from one person and fine features such as skin texture from another.
However, it would be even more interesting—and more difficult—if you could just write a prompt for the model and immediately get a picture of the result. This requires multimodal modeling: you have to somehow transform both text and images into the same space, or at least learn how to translate them into one another.
The first model to claim it has achieved this holy grail with sufficiently good quality was DALL-E from OpenAI. It featured a variational autoencoder with a discrete latent space (like a “language” with discrete “words” that the decoder can turn into images) and a Transformer that made it possible to encode text prompts into this latent space. Later, however, new models have been developed that surpassed DALL-E, including DALL-E 2, Midjourney, and Stable Diffusion. In the next sections, we will discuss these ideas in more detail, although I will reserve the technical discussions for later posts.
One of the most important ideas in deep learning is the autoencoder, an encoder-decoder architecture that is tasked to reconstruct the original image:

The idea here is that the latent code is usually much smaller than the input and output: the task is to compress millions of pixels down to several hundred or a couple of thousand numbers in such a way that decompression is possible.
It is very tempting to transform an autoencoder into a generative model: it looks like we can sample the latent codes and get new “reconstructions” that could look like new images. Unfortunately, that’s not quite as easy as it seems: even in the lower-dimensional space, the latent codes of “real images” still occupy a rather complicated subset (submanifold), and it would be very difficult to sample from it directly.
There are several different ways to go about this problem and turn an autoencoder into a proper generative model. One approach is the adversarial autoencoder: let’s turn this into a GAN by adding a discriminator that distinguishes between “real” latent codes sampled from some standard distribution and “fake” latent codes generated by the encoder from actual images:

Another approach is taken by variational autoencoders (VAE): let’s make the encoder generate not a single latent code but a whole distribution of latent codes. That is, the encoder produces parameters of this distribution, then a latent code is sampled from it, and then the decoder has to reconstruct the original from any sampled latent code, not only from the exact point the encoder has produced:

This is just a basic idea, it needs a lot of mathematical machinery to actually work, and I hope to explain this machinery in one of the upcoming posts. But if we do make it work, it helps create a nice generative model without the hassle of adversarial training. Variational autoencoders are an important class of generative models, and DALL-E uses one of them to generate images. To be more precise, it uses a variation of VAE that has discrete latent codes, but this explanation definitely can wait until next time.
The next step in getting a text-to-image model is to add text into the mix. This is exactly what Transformers are great at, and what we need is to train one to generate these discrete latent codes. So the original DALL-E worked as a (discrete) variational autoencoder with a Transformer generating codes for it:
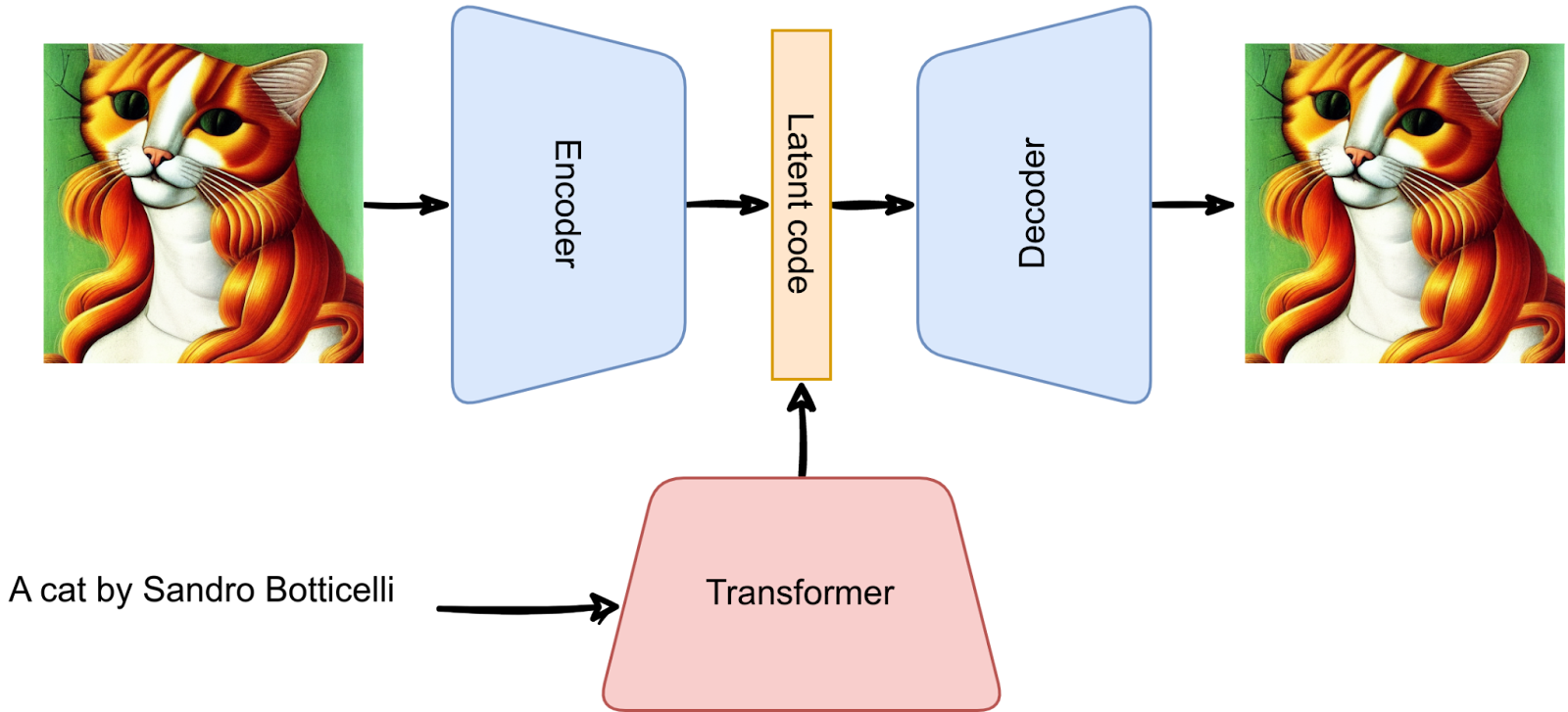
After training, you can use the Transformer to generate new latent codes and get new pictures via the decoder:
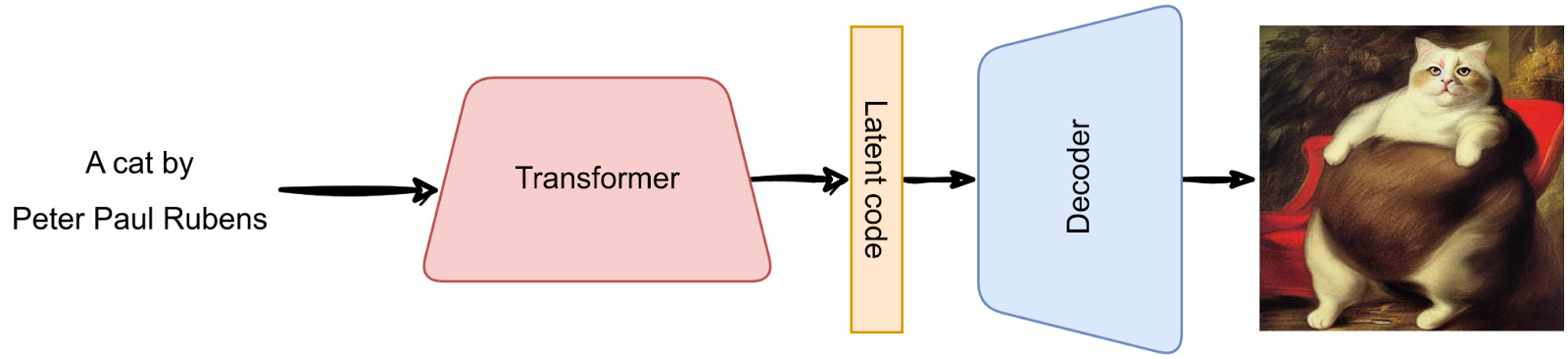
There are a lot more tricks the authors of DALL-E had to invent to train a huge model able to produce 512×512 images from detailed text prompts but this is the basic idea.
Another important idea that modern generative models have learned to use very well comes from diffusion-based models. Diffusion is the process of adding noise to something, for instance to an image. If you start with a crisp image and keep adding simple noise, say Gaussian, after a while you will have nothing like the original, and if you continue the process long enough you will get something that’s basically indistinguishable from random noise:

The idea of diffusion-based models is to try and invert this process. Adding noise is very easy, and the conditional distributions on every step are simple. Inverting it, i.e., gradual denoising of the image, is a much more difficult task, but it turns out that we can approximate the inverse, learning a conditional denoising distribution that is close to the true one:

Then we can string together this chain of approximations and, hopefully, get a model that is able to regenerate crisp images from random noise:

Again, a full description of what is going on here is quite involved, and I hope to get a chance to explain it in more detail later. But at this point, the only thing that remains is to be able to convert text descriptions into these “random noise” vectors.
This conversion can be done with an encoder-decoder architecture (recall the previous section) that projects both texts and images into the same latent space. One of the best such models, CLIP, was developed by OpenAI in 2021, and was used as the basis for DALL-E 2; I will not go into detail about its internal structure in this post and leave it for later.
So overall, we have the following structure:
Here is this structure illustrated by DALL-E 2 authors Ramesh et al. (2022):

Another large-scale diffusion-based model, Stable Diffusion, was developed by Rombach et al. (2022). It is a different variation of the same idea: it first trains an autoencoder to map the pixel space into a latent space where imperceptible details are abstracted away, and the image is compressed down to a smaller vector, and then performs conditional diffusion in this latent space to account for the text prompt and other conditions.
I will not go into further detail right now, but here is a general illustration of the approach by Rombach et al.; it mostly concentrates on what’s happening in the latent space because the autoencoder is almost standard by now; note that the conditions are accounted for with Transformer-like encoder-decoder attention modules:

Unlike DALL-E 2 and Midjourney (there is not even a paper written about Midjourney, let alone source code, so I cannot go into detail about how it works), Stable Diffusion comes with a GitHub repository where you can get the code and, most importantly, trained model weights to use. You can set it up on your home desktop PC (you don’t even need a high-end GPU, although you do need a reasonable one). All generated images used in this post have been produced with Stable Diffusion, and I’m very grateful to its authors for making this great tool available to everybody.
So where does this leave us? Does it mean that you can now generate synthetic data at will with very little cost by simply writing a good text prompt, so synthetic data as we understand it, produced by rendering 3D scenes, is useless?
Far from it. Images generated even by state-of-the-art models do not come with perfect labeling, and generative models for 3D objects are still very far from production quality. If anything, synthetic data comes in more demand now because researchers need more and more data to train these large-scale models, and at the same time they are developing new ways to do domain adaptation and make synthetic data increasingly useful for this process.
However, this does not mean that state-of-the-art generative models cannot play an important role for synthetic data. One problem where we believe more research is needed is texture generation: while we cannot generate high-definition realistic 3D models, we can probably generate 2D textures for them, but this requires a separate model and training set because textures look nothing like photos or renders. Another idea would be to adapt generative models to modify synthetic images, either making them look more realistic (synthetic-to-real refinement) or simply making more involved augmentation-like transformations.
In any case, we are living in exciting times with regard to generative models in machine learning. We will discuss these ideas in more detail in subsequent posts, and let’s see what else the nearest future will bring!
Sergey Nikolenko
Head of AI, Synthesis AI
