In the previous two blog posts, we have discussed the origins and first applications of synthetic data. The first part showed how early computer vision used simple line drawings for scene understanding algorithms and how synthetic datasets were necessary as test sets to compare different computer vision algorithms. In the second part, we saw how self-driving cars were made in the 1980s and how the very first application of machine learning in computer vision for autonomous vehicles, the ALVINN system, was trained on synthetic data. Today, we begin the discussion of early robotics and the corresponding synthetic simulators… but this first part will be a bit more philosophical than usual.

Robotics is not quite as old as artificial intelligence: the challenge of building an actual physical entity that could operate in the real world was too big a hurdle for the first few years of AI. However, robotics was recognized as one of the major problems in AI very early on, and as soon as it became possible people started to build real world robots. Here is one of the earliest attempts at a robot equipped with a vision system, the Stanford Cart built in the 1970s (pictures taken from a later review paper by Hans Moravec):

The Cart had an onboard TV system, and a computer program tried to drive the Cart through obstacle courses based on the images broadcast by this system. Based on several images taken from different camera positions (a kind of “super-stereo” vision), its vision algorithm tried to find interest points (features), detect obstacles and avoid or go around them. It was extremely successful for such an early system, although the performance was less than stellar: the Cart moved in short lurches, about 1 meter, every 10-15 minutes. Still, in these lurches the Cart could successfully avoid real life obstacles.
As we discussed last time, before the 1990s computer vision was very seldom based on learning of any kind: researchers tried to devise algorithms, and data was only needed to test and compare them. This fully goes for robotics: early robots such as the Cart had hardcoded algorithms for vision, pathfinding, and everything else.
However, experiments with the Cart and similar robots taught researchers that it is far too costly and often plain impossible to validate their ideas in the real world. Most researchers decided that they want to first test the algorithms in computer simulations and only then proceed to the real world. There are two main reasons for this:
Hence, robotics moved to the «simulate first, build second» principle which it abides to this day.
Let’s have a look at a sample early simulator for a rover robot that was supposed to map the space around it. Benjamin Kuipers and Yung-Tai Byun developed an approach to robot exploration and mapping based on a semantic hierarchy of spatial representations (Kuipers and Byun, 1988; 1991). This means that their robot is supposed to gradually work its way up from the control level, where it finds distinctive places and paths, through the topological level, where it creates a topological network description of the environment, and finally to the geometric level, where the topology is converted to a geometric map by incorporating local information about the distances and global metric relationships between the places. The exploration paths could look something like this (all pictures taken from the AAAI paper):
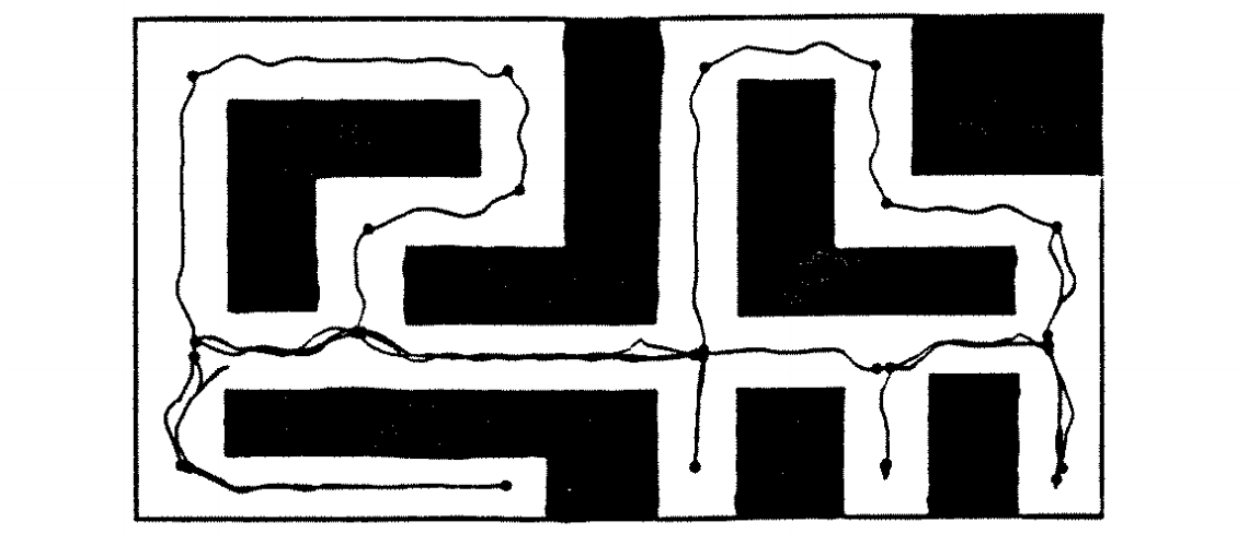
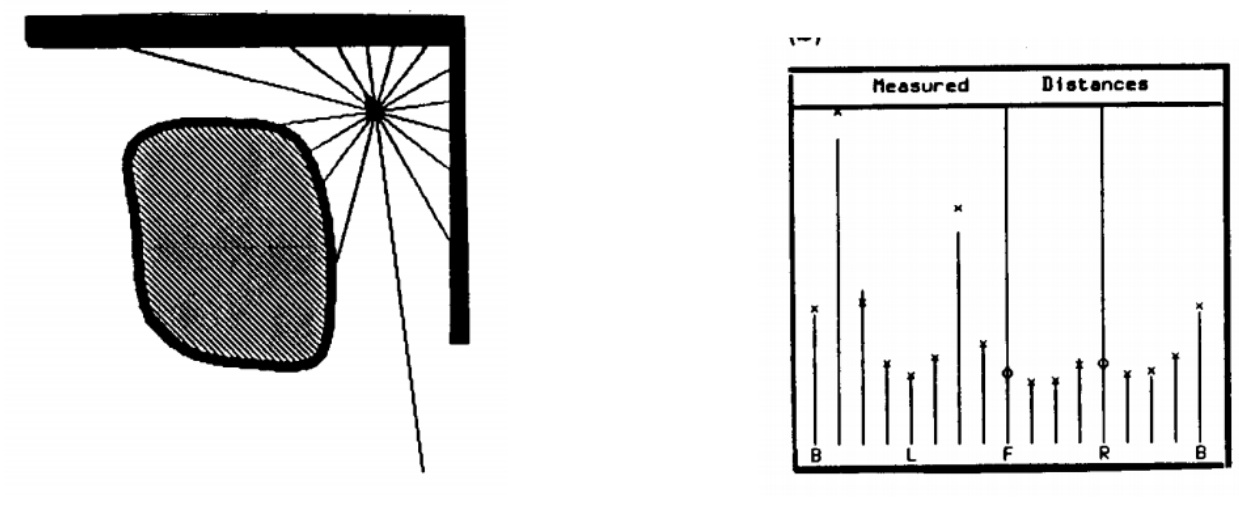
The method itself was a seminal work, but it’s not our subject right now and I will not go into any more details about it. But note their approach to implementing and testing the method: Kuipers and Byun programmed (in Common Lisp, by the way) a two-dimensional simulated environment called the NX Robot Simulator. The virtual robot in this environment has access to sixteen sonar-type distance sensors and a compass, and moves by two tractor-type chains. The interesting part of this simulation is that Kuipers and Byun took special care to implement error models for the sonars that actually reflect real life errors.
Here is a sample picture from their simulation; on the left you see a robot shooting sonar rays in 16 directions, and the histogram on the right shows the sensor readings (with vertical lines) and true distances (with X and O markers). Note how the O markers represent a systematic error due to specular reflection, much more serious than the deviations of X markers that comes from normal random error:
They made it into a software product with a GUI interface, which was much harder to do in the 1980s than it is now. Here is a sample screenshot:
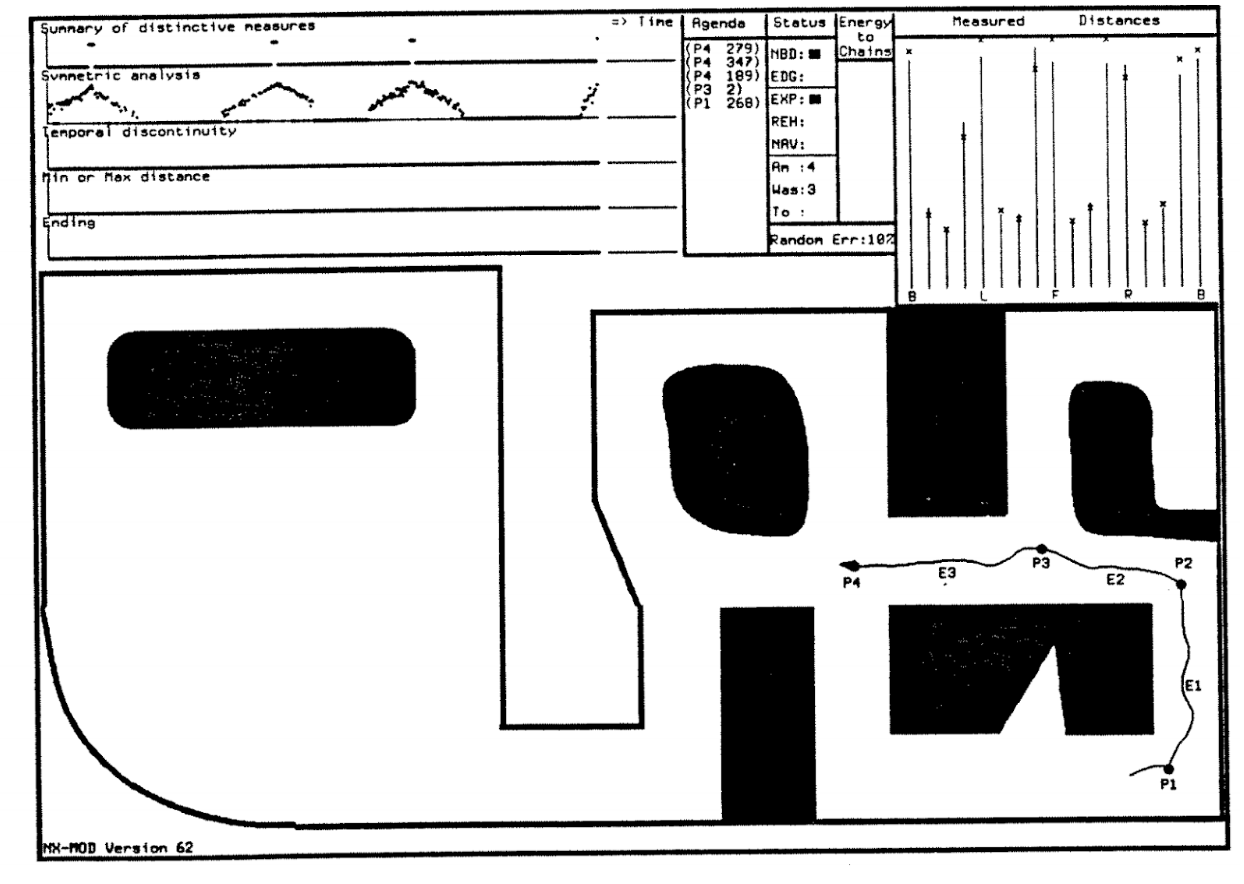
The algorithms worked fine in a simulation, and the simulation was so realistic that it actually allowed to transfer the results to the real world. In a later work, Kuipers et al. (1993) report on their experiments with two physical mobile robots, Spot and Rover, that quite successfully implemented their algorithms on two different sensorimotor systems.
Despite these successes, not everybody believed in computer simulations for robotics. In the same book as (Kuipers et al., 1993), another chapter by Rodney Brooks and Maja Mataric, aptly titled Real Robots, Real Learning Problems, had an entire section devoted to warning researchers in robotics from relying on simulations too much. Brooks and Mataric put it as follows:
Simulations are doomed to succeed. Even despite best intentions there is a temptation to fix problems by tweaking the details of a simulation rather than the control program or the learning algorithm. Another common pitfall is the use of global information that could not possibly be available to a real robot. Further, it is often difficult to separate the issues which are intrinsic to the simulation environment from those which are based in the actual learning problem.
Basically, they warned that computer vision had not been solved yet, and while a simulation might provide the robot with information such as «there is food ahead», in reality such high-level information would never be available. This, of course, remains true to this day, and modern robotic vision systems make use of all modern advances in object detection, segmentation, and other high-level computer vision tasks (where synthetic data also helps a lot, by the way, but this will be the subject of later posts).
All this looks like some very basic points that are undoubtedly true, and they sound more as a part of the problem setting than true criticism. However, Rodney Brooks also presents a much more interesting criticism which is not so much against synthetic data and simulations as against the entire computer vision program for robotics; while this is an aside for this blog series, this is an interesting aside, and I want to elaborate on it.
I will present Brooks’ ideas based on two of his papers, Intelligence Without Representation and Intelligence Without Reason. In the former, Brooks argues that abstract representation of the real world, which was a key feature of contemporary AI solutions, is a dangerous weapon that can lead to self-delusion. He says that real life intelligence has not evolved as a machine for solving well-defined abstract problems such as chess playing or theorem proving: intelligence in animals and humans is inseparable from perception and mobility. This was mostly a criticism of early approaches to AI that indeed concentrated on abstractions such as block worlds or knowledge engineering.
In Intelligence Without Reason, Brooks goes further to argue that abstraction and knowledge are basically unavailable to systems that have to operate in the real world, that is, to robotic systems. For example, he mentions vision algorithms based on line drawings that we discussed a couple of blog posts ago, and admits that although some early successes in line detection had dated back to the 1960s, even in the early 1990s we did not have a reliable way to convert real life images to line drawings. «Try it! You’ll be amazed at how bad it is,» Brooks comments, and this comment is not so far from the truth even today.
Brooks presents four key ideas that he believes to be crucial for AI:
As for simulations, Brooks concludes that they are examples of precisely the kind of abstractions that may lead to overly optimistic interpretations of results, and argues for complete integrated intelligent mobile robots.
Interestingly, this resonates with the words of Hans Moravec that he wrote in his 1990 paper about the Stanford Cart robot that I began with:
My conclusion is that solving the day to day problems of developing a mobile organism steers one in the direction of general intelligence, while working on the problems of a fixed entity is more likely to result in very specialized solutions
Brooks put his ideas in practice, leading a long-term effort to create mobile autonomous robots in the MIT AI lab. Here are Allen, Herbert, Tom, and Jerry that were designed to interact with the world rather than plan and carry out plans:

This work soon ran into technological obstacles: the hardware was just not up to the task in the late 1980s. But Brooks’ ideas live on: Intelligence Without Representation has more than 2000 citations and is still being cited in 2020, in fields ranging from robotics to cognitive sciences, nanotechnology, and even law (AI-related legislature is a hot topic, and I may return to it on this blog someday).
So are simulations useful for robotics? Of course, and increasingly so! While I believe that there is a lot of truth to the criticism shown in the previous section, in my opinion in most applications it boils down to the following: when your robot works in a simulation, it does not yet mean that it will work in real life. This is, of course, true.
On the other hand, if your robot does not work even in a simulation, it is definitely too early to start building real systems. Moreover, modern developments in robotics such as the success of reinforcement learning seem to have a strange relationship with Brooks’ ideas. On the one hand, this is definitely a step in the direction of creating end-to-end systems that are behaviour-oriented rather than composed of clear-cut predesigned functional units. On the other hand, in the modern state of reinforcement learning it is entirely hopeless to suggest that systems could be trained in real life: they absolutely need simulations because they require millions of training episodes.
In the next posts, we will consider other early robotic simulations and how their ideas still live on in modern synthetic environments for robotics.
Sergey Nikolenko
Head of AI, Synthesis AI
