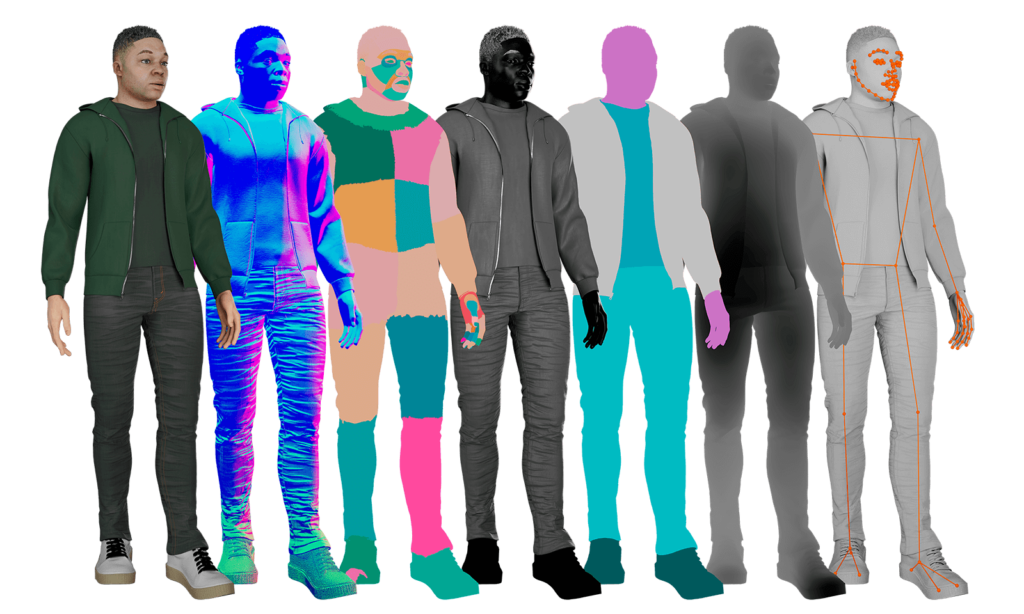By creating digital doubles of complex computer vision product systems, you can perform design trade-off studies in a virtual environment. Optimize camera configurations and understand performance before building hardware.
Simulate edge cases and rare events
Capturing real data of edge cases and rare events is prohibitively expensive and often impossible. Synthetic data can be used to augment real data to ensure coverage of critical use cases that impact system performance and safety.
Reduce bias & preserve privacy
Real-world data contains many biases. Biases related to demographics have significant ethical and legal implications. Synthetic data enables companies to build diverse and balanced human datasets to mitigate bias in a privacy-compliant manner.
Pixel-perfect 3D labels
Spatial computing, autonomy, AR/VR, and robotic applications require detailed knowledge of the 3D world. With synthetic data, developers now have access to pixel-perfect annotations of depth, surface normals, 3D landmarks, and more to build better models.
“…our field must tap into rich sources of synthetic and real data. Sergey Nikolenko’s book lucidly surveys the state of the art in the former, and I consider it required reading for any researcher using deep learning based methods.”
— SERGE BELONGIE
Department of Computer Science at the University of Copenhagen (DIKU) and Director, Pioneer Centre for Artificial Intelligence